Poskytovatel služby Azure Storage (Azure Functions)
Tento dokument popisuje charakteristiky Durable Functions poskytovatele služby Azure Storage se zaměřením na aspekty výkonu a škálovatelnosti. Výchozím poskytovatelem je poskytovatel Azure Storage. Ukládá stavy instancí a fronty v účtu Azure Storage (Classic).
Poznámka
Další informace o podporovaných poskytovatelích úložiště pro Durable Functions a jejich porovnání najdete v dokumentaci k poskytovatelům Durable Functions úložiště.
Ve poskytovateli Azure Storage se veškeré spouštění funkcí řídí frontami služby Azure Storage. Orchestrace a stav a historie entit se ukládají do tabulek Azure. Objekty blob Azure a zapůjčení objektů blob se používají k distribuci instancí a entit orchestrace mezi několik instancí aplikací (označovaných také jako pracovní procesy nebo jednoduše virtuální počítače). Tato část obsahuje podrobnější informace o různých artefaktech služby Azure Storage a o tom, jak ovlivňují výkon a škálovatelnost.
Reprezentace úložiště
Centrum úloh trvale zachovává všechny stavy instancí a všechny zprávy. Rychlý přehled toho, jak se používají ke sledování průběhu orchestrace, najdete v příkladu spuštění centra úloh.
Poskytovatel služby Azure Storage představuje centrum úloh v úložišti pomocí následujících komponent:
- Mezi dvěma a třemi tabulkami Azure. K reprezentaci historie a stavů instancí se používají dvě tabulky. Pokud je správce oddílů tabulky povolený, pak je zavedena třetí tabulka pro ukládání informací o oddílu.
- Jedna fronta Azure ukládá zprávy o aktivitách.
- V jedné nebo několika frontách Azure se ukládají zprávy instance. Každá z těchto tzv . řídicích front představuje oddíl , kterému je přiřazena podmnožina všech zpráv instance na základě hodnoty hash ID instance.
- Několik dalších kontejnerů objektů blob, které se používají pro zapůjčení objektů blob nebo velkých zpráv.
Například centrum úloh s názvem s PartitionCount = 4 názvem xyz obsahuje následující fronty a tabulky:

Dále podrobněji popíšeme tyto komponenty a roli, kterou hrají.
Tabulka historie
Tabulka Historie je tabulka Azure Storage, která obsahuje události historie pro všechny instance orchestrace v centru úloh. Název této tabulky je ve formátu TaskHubNameHistory. Při spuštění instancí se do této tabulky přidají nové řádky. Klíč oddílu této tabulky je odvozen z ID instance orchestrace. ID instancí jsou ve výchozím nastavení náhodná, což zajišťuje optimální distribuci interních oddílů ve službě Azure Storage. Klíč řádku pro tuto tabulku je pořadové číslo, které se používá k řazení událostí historie.
Když je potřeba spustit instanci orchestrace, načtou se odpovídající řádky tabulky Historie do paměti pomocí dotazu na rozsah v rámci jednoho oddílu tabulky. Tyto události historie se pak přehrají do kódu funkce orchestratoru, aby se vrátil do stavu, ve kterém byl dříve kontrolní bod. Použití historie spouštění k opětovnému sestavení stavu tímto způsobem je ovlivněno vzorem Event Sourcing.
Tip
Data orchestrace uložená v tabulce Historie zahrnují výstupní datové části z funkcí aktivity a dílčího orchestrátoru. Datové části z externích událostí jsou také uložené v tabulce Historie. Vzhledem k tomu, že se úplná historie načítá do paměti při každém spuštění orchestrátoru, může dostatečně velká historie způsobit značné zatížení paměti na daném virtuálním počítači. Délku a velikost historie orchestrace je možné snížit rozdělením velkých orchestrací do několika dílčích orchestrací nebo zmenšením velikosti výstupů vrácených funkcemi aktivity a dílčího orchestrátoru, které volá. Případně můžete snížit využití paměti snížením omezení souběžnosti jednotlivých virtuálních počítačů, abyste omezili, kolik orchestrací se současně načítá do paměti.
Tabulka Instances
Tabulka Instance obsahuje stavy všech instancí orchestrace a entit v centru úloh. Při vytváření instancí se do této tabulky přidají nové řádky. Klíč oddílu této tabulky je ID instance orchestrace nebo klíč entity a klíč řádku je prázdný řetězec. Pro každou instanci orchestrace nebo entity existuje jeden řádek.
Tato tabulka slouží k uspokojení požadavků na dotazy instancí z kódu i volání http rozhraní API dotazu na stav . Nakonec se udržuje v souladu s obsahem výše uvedené tabulky Historie . Použití samostatné tabulky Azure Storage k efektivnímu uspokojování operací dotazů na instance tímto způsobem je ovlivněno modelem Command and Query Responsibility Segregation (CQRS).
Tip
Dělení tabulky Instances umožňuje ukládat miliony instancí orchestrace bez znatelného dopadu na výkon nebo škálování za běhu. Počet instancí však může mít významný vliv na výkon dotazů s více instancemi . Pokud chcete řídit množství dat uložených v těchto tabulkách, zvažte pravidelné vymazání dat starých instancí.
Tabulka oddílů
Poznámka
Tato tabulka je v centru úloh zobrazena pouze v případě, že Table Partition Manager je povolená. Pokud ho chcete použít, nakonfigurujte useTablePartitionManagement nastavení v souboru host.json vaší aplikace.
Tabulka Oddíly ukládá stav oddílů pro aplikaci Durable Functions a slouží k distribuci oddílů mezi pracovní procesy vaší aplikace. Každý oddíl má jeden řádek.
Fronty
Funkce Orchestrator, entity a aktivity se aktivují interními frontami v centru úloh aplikace funkcí. Použití front tímto způsobem poskytuje spolehlivé záruky doručení zpráv "alespoň jednou". V Durable Functions existují dva typy front: řídicí fronta a fronta pracovních položek.
Fronta pracovních položek
V Durable Functions je jedna fronta pracovních položek pro každé centrum úloh. Jedná se o základní frontu a chová se podobně jako jakákoli jiná queueTrigger fronta v Azure Functions. Tato fronta se používá k aktivaci bezstavových funkcí aktivit tím, že najednou vypouští jednu zprávu. Každá z těchto zpráv obsahuje vstupy funkce aktivity a další metadata, například funkci, která se má spustit. Když Durable Functions aplikace škáluje na více virtuálních počítačů, všechny tyto virtuální počítače soupeří o získání úkolů z fronty pracovních položek.
Řídicí fronty
V Durable Functions je na jedno centrum úloh několik front řízení. Řídicí fronta je sofistikovanější než jednodušší fronta pracovních položek. Řídicí fronty se používají k aktivaci stavových funkcí orchestrátoru a entity. Vzhledem k tomu, že instance orchestrátoru a funkce entit jsou stavové jednoúčelové objekty, je důležité, aby každá orchestrace nebo entita byla zpracována vždy jenom jedním pracovním procesem. K dosažení tohoto omezení je každá instance orchestrace nebo entita přiřazena k jedné řídicí frontě. Tyto řídicí fronty jsou vyrovnány zatížení mezi pracovními procesy, aby se zajistilo, že každá fronta bude zpracovávat vždy jenom jeden pracovní proces. Další podrobnosti o tomto chování najdete v následujících částech.
Řídicí fronty obsahují různé typy zpráv životního cyklu orchestrace. Mezi příklady patří řídicí zprávy orchestrátoru, zprávy odpovědí na funkci aktivity a zprávy časovače. Z řídicí fronty se v jednom hlasování zruší až 32 zpráv. Tyto zprávy obsahují data datové části a metadata včetně instance orchestrace, pro kterou jsou určeny. Pokud je pro stejnou instanci orchestrace určeno více zpráv s vyřazeným z fronty, budou zpracovány jako dávka.
Zprávy řídicí fronty se neustále dotazují pomocí vlákna na pozadí. Velikost dávky každého dotazování front se řídí controlQueueBatchSize nastavením v souboru host.json a má výchozí hodnotu 32 (maximální hodnota podporovaná službou Azure Queues). Maximální počet předem načtených zpráv řídicí fronty, které jsou uloženy do vyrovnávací paměti, se řídí controlQueueBufferThreshold nastavením v souboru host.json. Výchozí hodnota pro controlQueueBufferThreshold se liší v závislosti na různých faktorech, včetně typu plánu hostování. Další informace o těchto nastaveních najdete v dokumentaci ke schématu host.json .
Tip
Zvýšení hodnoty pro controlQueueBufferThreshold umožňuje jedné orchestraci nebo entitě rychleji zpracovávat události. Zvýšení této hodnoty však může také vést k vyššímu využití paměti. Vyšší využití paměti je částečně způsobeno stažením více zpráv z fronty a částečně načtením více historie orchestrace do paměti. Snížení hodnoty pro controlQueueBufferThreshold proto může být efektivním způsobem, jak snížit využití paměti.
Dotazování fronty
Rozšíření trvalých úloh implementuje algoritmus náhodného exponenciálního zpětného odsunutí, aby se snížil vliv dotazování nečinných front na náklady na transakce úložiště. Když se zpráva najde, modul runtime okamžitě vyhledá jinou zprávu. Když se žádná zpráva nenajde, počká určitou dobu, než to zkusí znovu. Po následných neúspěšných pokusech o získání zprávy fronty se čekací doba dál prodlužuje, dokud nedosáhne maximální doby čekání, která je ve výchozím nastavení 30 sekund.
Maximální zpoždění dotazování je možné konfigurovat prostřednictvím maxQueuePollingInterval vlastnosti v souboru host.json. Nastavení této vlastnosti na vyšší hodnotu může mít za následek vyšší latenci zpracování zpráv. Vyšší latence by se očekávala až po období nečinnosti. Nastavení této vlastnosti na nižší hodnotu může mít za následek vyšší náklady na úložiště kvůli zvýšeným transakcím úložiště.
Poznámka
Při spuštění v plánech Azure Functions Consumption a Premium bude kontroler škálování Azure Functions dotazovat každý ovládací prvek a frontu pracovních položek každých 10 sekund. Toto další dotazování je nezbytné k určení, kdy aktivovat instance aplikace funkcí, a rozhodování o škálování. V době psaní je tento 10sekundový interval konstantní a nelze ho nakonfigurovat.
Zpoždění zahájení orchestrace
Instance orchestrací se spouští vložením ExecutionStarted zprávy do jedné z řídicích front centra úloh. Za určitých podmínek můžete zaznamenat vícesekundové zpoždění mezi naplánovaným spuštěním orchestrace a jejím spuštěním. Během tohoto časového intervalu zůstane instance orchestrace ve Pending stavu. Toto zpoždění může mít dvě možné příčiny:
Fronty ovládacích prvků s backlogem: Pokud řídicí fronta pro tuto instanci obsahuje velký počet zpráv, může chvíli trvat, než
ExecutionStartedse zpráva přijme a zpracuje modulem runtime. K backlogům zpráv může dojít, když orchestrace zpracovávají velké množství událostí současně. Události, které přejdou do řídicí fronty, zahrnují události zahájení orchestrace, dokončení aktivit, trvalé časovače, ukončení a externí události. Pokud k tomuto zpoždění dochází za normálních okolností, zvažte vytvoření nového centra úloh s větším počtem oddílů. Konfigurace více oddílů způsobí, že modul runtime vytvoří více řídicích front pro distribuci zatížení. Každý oddíl odpovídá hodnotě 1:1 s řídicí frontou s maximálním počtem 16 oddílů.Zpoždění zpětného dotazování: Další běžnou příčinou zpoždění orchestrace je dříve popsané chování zpětného dotazování pro řídicí fronty. Toto zpoždění se ale očekává pouze v případě, že je aplikace škálovaná na dvě nebo více instancí. Pokud existuje pouze jedna instance aplikace nebo pokud instance aplikace, která spouští orchestraci, je také stejnou instancí, která dotazuje frontu cílového ovládacího prvku, nedojde ke zpoždění dotazování fronty. Zpoždění zpětného dotazování můžete snížit aktualizací nastavení host.json , jak je popsáno výše.
Objekty blob
Ve většině případů Durable Functions nepoužívá k uchování dat objekty blob služby Azure Storage. Fronty a tabulky ale mají omezení velikosti, která můžou Durable Functions zabránit v uchování všech požadovaných dat do řádku úložiště nebo zprávy fronty. Pokud je například část dat, která je potřeba zachovat ve frontě, při serializaci větší než 45 kB, Durable Functions data zkomprimuje a uloží je do objektu blob. Při uchovávání dat do úložiště objektů blob tímto způsobem ukládá Durable Function odkaz na tento objekt blob do řádku tabulky nebo zprávy fronty. Když Durable Functions potřebuje načíst data, automaticky je načte z objektu blob. Tyto objekty blob jsou uložené v kontejneru <taskhub>-largemessagesobjektů blob .
Otázky výkonu
Dodatečné kroky komprese a operace objektů blob pro velké zprávy mohou být nákladné z hlediska nákladů na latenci procesoru a vstupně-výstupních operací. Kromě toho Durable Functions potřebuje načíst trvalá data v paměti a může to udělat při provádění mnoha různých funkcí najednou. V důsledku toho může zachování velkých datových částí způsobit také vysoké využití paměti. Pokud chcete minimalizovat režii paměti, zvažte ruční uchovávání velkých datových částí (například v úložišti objektů blob) a předávání odkazů na tato data. Tímto způsobem může kód načíst data pouze v případě potřeby, aby se zabránilo redundantnímu zatížení během přehrání funkcí orchestrátoru. Ukládání datových částí na místní disky se ale nedoporučuje , protože není zaručeno, že stav na disku bude k dispozici, protože funkce se můžou spouštět na různých virtuálních počítačích po celou dobu jejich životnosti.
Výběr účtu úložiště
Fronty, tabulky a objekty blob používané Durable Functions se vytvářejí v nakonfigurovaným účtu Služby Azure Storage. Účet, který chcete použít, můžete zadat pomocí durableTask/storageProvider/connectionStringName nastavení (nebo durableTask/azureStorageConnectionStringName nastavení v Durable Functions 1.x) v souboru host.json.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
Pokud není zadaný, použije se výchozí AzureWebJobsStorage účet úložiště. U úloh citlivých na výkon se ale doporučuje nakonfigurovat jiný než výchozí účet úložiště. Durable Functions službu Azure Storage intenzivně využívá a použití vyhrazeného účtu úložiště izoluje Durable Functions využití úložiště od interního využití hostitelem Azure Functions.
Poznámka
Při použití poskytovatele služby Azure Storage se vyžadují standardní účty Azure Storage pro obecné účely. Všechny ostatní typy účtů úložiště se nepodporují. Důrazně doporučujeme používat starší účty úložiště pro obecné účely v1 pro Durable Functions. Novější účty úložiště v2 mohou být výrazně dražší pro Durable Functions úlohy. Další informace o typech účtů služby Azure Storage najdete v dokumentaci k přehledu účtu úložiště .
Škálování orchestratoru na více instancí
Zatímco funkce aktivit je možné elastickým přidáním dalších virtuálních počítačů neomezeně škálovat, jednotlivé instance a entity orchestrátoru jsou omezené tak, aby obývaly jeden oddíl, a maximální počet oddílů je ohraničen partitionCount nastavením v host.json.
Poznámka
Obecně řečeno, funkce orchestrátoru jsou určeny k tomu, aby byly jednoduché a neměly by vyžadovat velké množství výpočetního výkonu. Proto není nutné vytvářet velký počet oddílů řídicí fronty, abyste získali velkou propustnost pro orchestrace. Většinu náročné práce byste měli provádět ve funkcích bezstavové aktivity, které je možné škálovat neomezeně.
Počet ovládacích front je definován v souboru host.json . Následující příklad fragmentu kódu host.json nastaví durableTask/storageProvider/partitionCount vlastnost (nebo durableTask/partitionCount v Durable Functions 1.x) na 3. Všimněte si, že existuje tolik řídicích front, kolik je oddílů.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Centrum úloh je možné nakonfigurovat s 1 až 16 oddíly. Pokud není zadaný, výchozí počet oddílů je 4.
Ve scénářích s nízkým provozem bude vaše aplikace škálovat, takže oddíly budou spravovány malým počtem pracovních procesů. Představte si například následující diagram.
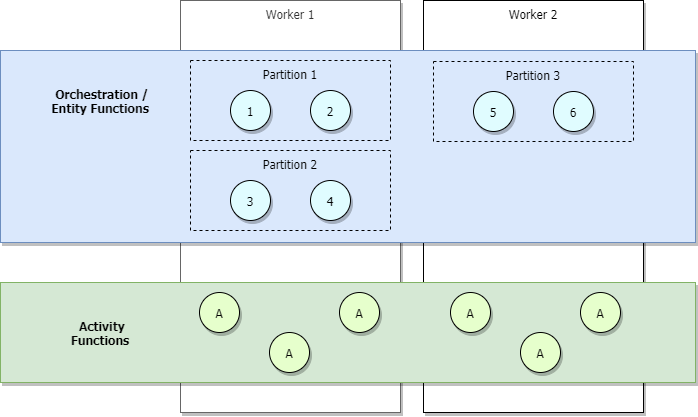
V předchozím diagramu vidíme, že orchestrátory 1 až 6 mají vyrovnávání zatížení napříč oddíly. Podobně i oddíly, jako jsou aktivity, mají vyrovnávání zatížení napříč pracovními procesy. Oddíly jsou vyrovnány zatížení napříč pracovními procesy bez ohledu na počet orchestrátorů, které začínají.
Pokud používáte plány Azure Functions Consumption nebo Elastic Premium nebo pokud máte nakonfigurované automatické škálování založené na zatížení, při zvýšení provozu se přidělí více pracovních procesů a oddíly nakonec vyrovná zatížení mezi všemi pracovními procesy. Pokud budeme pokračovat v horizontálním navýšení kapacity, nakonec bude každý oddíl spravovat jeden pracovní proces. Naopak aktivity budou i nadále vyrovnávání zatížení napříč všemi pracovními procesy. To je vidět na následujícím obrázku.
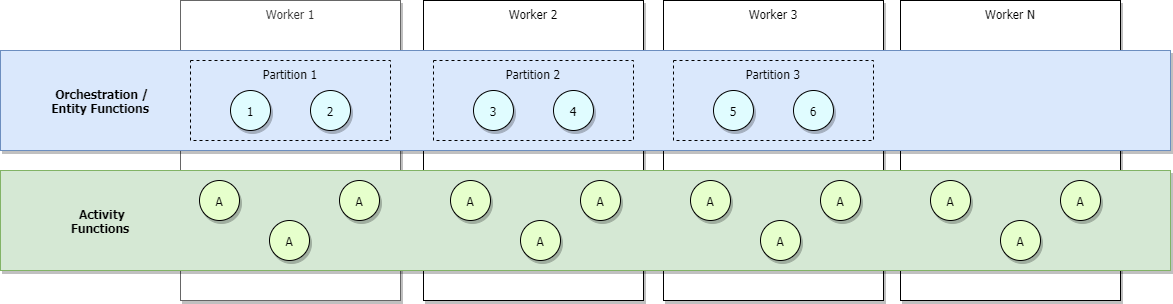
Horní mez maximálního počtu souběžných aktivních orchestrací v daném okamžiku se rovná počtu pracovních procesů přidělených vaší aplikaci krát hodnotu pro maxConcurrentOrchestratorFunctions. Toto horní omezení je možné zpřesnit, když jsou vaše oddíly plně škálované na více instancí napříč pracovními procesy. Při úplném horizontálním navýšení kapacity a vzhledem k tomu, že každý pracovní proces bude mít pouze jednu instanci hostitele služby Functions, bude maximální počet aktivních souběžných instancí orchestrátoru roven vašemu počtu oddílů násobku vaší hodnoty pro maxConcurrentOrchestratorFunctions.
Poznámka
V tomto kontextu aktivní znamená, že se orchestrace nebo entita načte do paměti a zpracovává nové události. Pokud orchestrace nebo entita čeká na další události, jako je návratová hodnota funkce aktivity, uvolní se z paměti a už se nepovažuje za aktivní. Orchestrace a entity se následně znovu načtou do paměti pouze v případech, kdy je potřeba zpracovat nové události. Neexistuje žádný praktický maximální počet celkových orchestrací nebo entit, které by mohly běžet na jednom virtuálním počítači, i když jsou všechny ve stavu Spuštěno. Jediným omezením je počet současně aktivní orchestrace nebo instancí entit.
Následující obrázek znázorňuje scénář s plně škálovaným navýšením kapacity, kdy se přidají další orchestrátory, ale některé jsou neaktivní, a zobrazují se šedě.
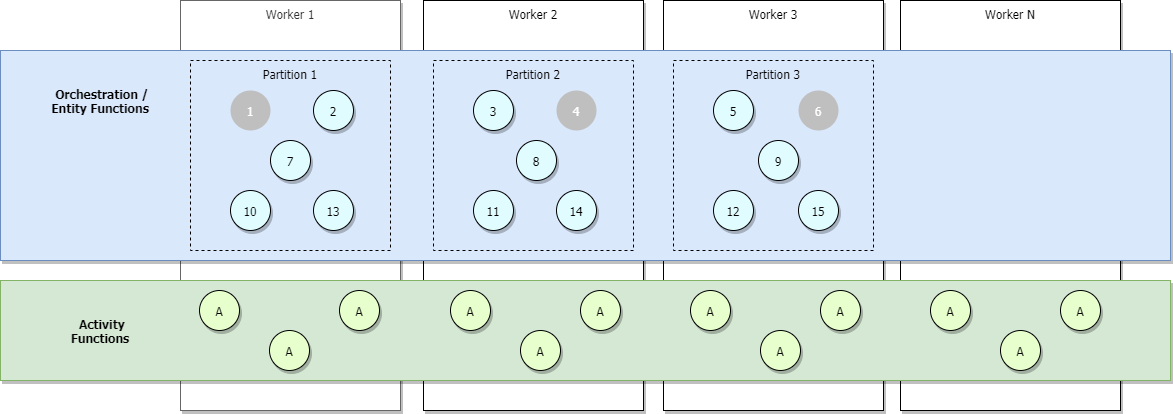
Během horizontálního navýšení kapacity je možné zapůjčení řídicích front redistribuovat napříč instancemi hostitelů služby Functions, aby se zajistilo rovnoměrné rozdělení oddílů. Tato zapůjčení se interně implementují jako zapůjčení služby Azure Blob Storage a zajišťují, aby každá instance nebo entita orchestrace běžela najednou jenom na jedné instanci hostitele. Pokud je centrum úloh nakonfigurované se třemi oddíly (a tedy třemi řídicími frontami), je možné vyrovnává zatížení instancí a entit orchestrace napříč všemi třemi hostitelskými instancemi hostitelů, které drží zapůjčení. Pokud chcete zvýšit kapacitu pro provádění funkcí aktivity, můžete přidat další virtuální počítače.
Následující diagram znázorňuje, jak hostitel Azure Functions komunikuje s entitami úložiště v prostředí se škálováním na více instancí.
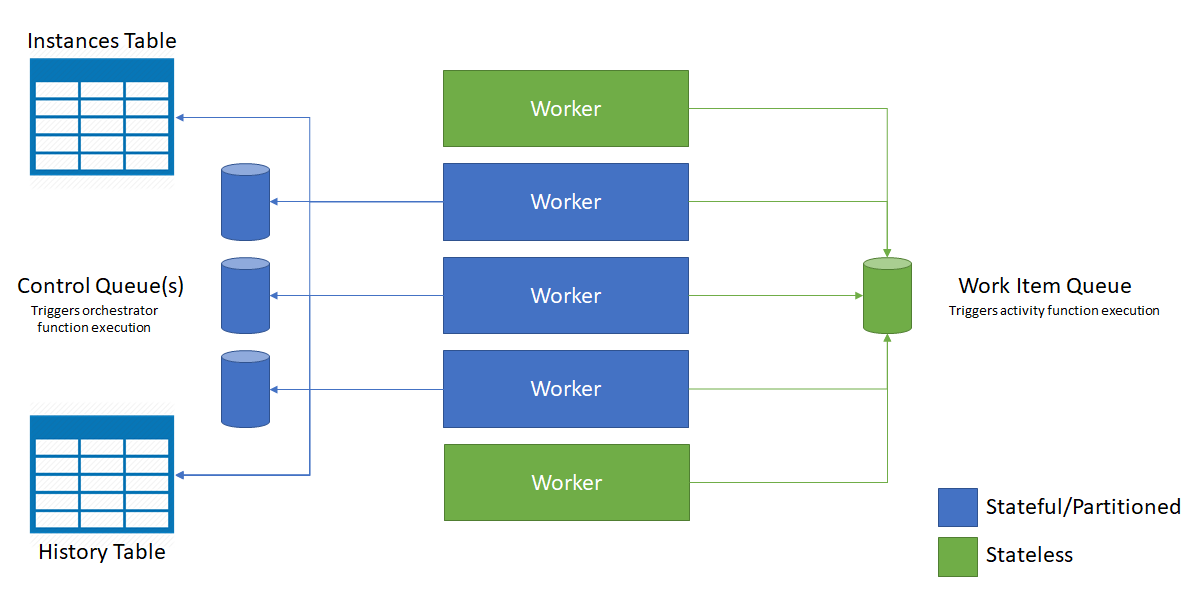
Jak je znázorněno v předchozím diagramu, všechny virtuální počítače soupeří o zprávy ve frontě pracovních položek. Zprávy z řídicích front ale můžou získávat jenom tři virtuální počítače a každý virtuální počítač uzamkne jednu řídicí frontu.
Instance a entity orchestrace se distribuují napříč všemi instancemi fronty řízení. Distribuce se provádí pomocí hodnoty hash ID instance orchestrace nebo názvu entity a páru klíčů. ID instancí orchestrace jsou ve výchozím nastavení náhodná identifikátory GUID, které zajišťují, že instance jsou rovnoměrně distribuované napříč všemi řídicími frontami.
Obecně řečeno, funkce orchestrátoru jsou určeny k tomu, aby byly jednoduché a neměly by vyžadovat velké množství výpočetního výkonu. Proto není nutné vytvářet velký počet oddílů řídicí fronty, aby se získala velká propustnost pro orchestrace. Většinu náročné práce byste měli provádět ve funkcích bezstavové aktivity, které je možné škálovat neomezeně.
Rozšířené relace
Rozšířené relace jsou mechanismus ukládání do mezipaměti , který udržuje orchestrace a entity v paměti i po dokončení zpracování zpráv. Typickým účinkem povolení rozšířených relací je snížení počtu vstupně-výstupních operací oproti základnímu úložišti s trvalou životností a celková vyšší propustnost.
Rozšířené relace můžete povolit nastavením durableTask/extendedSessionsEnabled na v true souboru host.json . Pomocí durableTask/extendedSessionIdleTimeoutInSeconds nastavení můžete řídit, jak dlouho se bude nečinná relace uchovávat v paměti:
Funkce 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Funkce 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Existují dvě potenciální nevýhody tohoto nastavení, o které je potřeba vědět:
- Celkově dochází k nárůstu využití paměti aplikace funkcí, protože nečinné instance nejsou z paměti tak rychle uvolněny.
- K celkovému snížení propustnosti může dojít, pokud existuje mnoho souběžných, jedinečných, krátkodobých spuštění orchestrátoru nebo funkce entity.
Pokud je například durableTask/extendedSessionIdleTimeoutInSeconds nastavená doba 30 sekund, pak krátkodobá epizoda funkce orchestrátoru nebo entity, která se spustí za méně než 1 sekundu, stále zabírá paměť po dobu 30 sekund. Započítává se také do durableTask/maxConcurrentOrchestratorFunctions výše uvedené kvóty, což může bránit spuštění dalších funkcí orchestrátoru nebo entity.
Konkrétní účinky rozšířených relací na funkce orchestrátoru a entit jsou popsané v dalších částech.
Poznámka
Rozšířené relace jsou v současné době podporované jenom v jazycích .NET, jako jsou C# nebo F#. Nastavení extendedSessionsEnabled na true pro jiné platformy může vést k problémům s modulem runtime, jako je například tiché selhání spouštění aktivit a funkcí aktivovaných orchestrací.
Přehrání funkce Orchestratoru
Jak už bylo zmíněno dříve, funkce orchestrátoru se přehrávají pomocí obsahu tabulky Historie . Ve výchozím nastavení se kód funkce orchestrátoru přehrává pokaždé, když je dávka zpráv vyřazena z fronty ovládacího prvku. I když používáte model fan-outu a čekáte na dokončení všech úkolů (například pomocí Task.WhenAll() v .NET, context.df.Task.all() v JavaScriptu nebo context.task_all() Pythonu), dojde k opakováním, ke kterým dojde při zpracování dávek odpovědí na úkoly v průběhu času. Pokud jsou povolené rozšířené relace, instance funkcí orchestrátoru se uchovávají v paměti déle a nové zprávy je možné zpracovávat bez přehrání celé historie.
Zlepšení výkonu rozšířených relací se nejčastěji pozoruje v následujících situacích:
- Pokud je souběžně spuštěný omezený počet instancí orchestrace.
- Když orchestrace mají velký počet sekvenčních akcí (například stovky volání funkcí aktivit), které se rychle dokončí.
- Při orchestraci fan-out a fan-in velký počet akcí, které se dokončí přibližně ve stejnou dobu.
- Když funkce orchestrátoru potřebují zpracovávat velké zprávy nebo zpracovávat data náročná na procesor.
Ve všech ostatních situacích obvykle nedochází k žádnému pozorovatelnému zlepšení výkonu funkcí orchestrátoru.
Poznámka
Tato nastavení by se měla používat až po úplném vývoji a otestovaní funkce orchestrátoru. Výchozí agresivní chování při přehrání může být užitečné při zjišťování porušení omezení kódu funkce orchestrátoru v době vývoje, a proto je ve výchozím nastavení zakázané.
Cíle výkonu
Následující tabulka uvádí očekávané maximální hodnoty propustnosti pro scénáře popsané v části Cíle výkonu článku Výkon a škálování .
"Instance" označuje jednu instanci funkce orchestrátoru spuštěnou na jednom malém virtuálním počítači (A1) v Azure App Service. Ve všech případech se předpokládá, že jsou povolené rozšířené relace . Skutečné výsledky se můžou lišit v závislosti na procesoru nebo vstupně-výstupních operacích provedených kódem funkce.
| Scenario | Maximální propustnost |
|---|---|
| Sekvenční provádění aktivit | 5 aktivit za sekundu na instanci |
| Paralelní spouštění aktivit (fan-out) | 100 aktivit za sekundu na instanci |
| Paralelní zpracování odpovědi (ventilátor) | 150 odpovědí za sekundu na instanci |
| Zpracování externích událostí | 50 událostí za sekundu na instanci |
| Zpracování operace entity | 64 operací za sekundu |
Pokud se nezobrazují očekávaná čísla propustnosti a využití procesoru a paměti se zdá být v pořádku, zkontrolujte, jestli příčina nesouvisí se stavem vašeho účtu úložiště. Rozšíření Durable Functions může výrazně zatěžovat účet služby Azure Storage a dostatečně vysoké zatížení může vést k omezování účtu úložiště.
Tip
V některých případech můžete výrazně zvýšit propustnost externích událostí, fan-in aktivit a operací entit zvýšením hodnoty controlQueueBufferThreshold nastavení v souboru host.json. Zvýšení této hodnoty nad výchozí způsobí, že poskytovatel úložiště Durable Task Framework použije více paměti k agresivnějšímu předběžnému načítání těchto událostí, čímž se sníží zpoždění spojená s odstraňováním zpráv z řídicích front služby Azure Storage. Další informace najdete v referenční dokumentaci k souboru host.json .
Zpracování s vysokou propustností
Architektura back-endu Služby Azure Storage klade určitá omezení maximálního teoretického výkonu a škálovatelnosti Durable Functions. Pokud testování ukáže, že Durable Functions ve službě Azure Storage nesplňuje vaše požadavky na propustnost, měli byste místo toho zvážit použití poskytovatele úložiště Netherite pro Durable Functions.
Pokud chcete porovnat dosažitelnou propustnost pro různé základní scénáře, přečtěte si část Základní scénáře dokumentace k poskytovateli úložiště Netherite.
Back-end úložiště Netherite navrhl a vyvinul Microsoft Research. Využívá Azure Event Hubs a databázové technologie FASTER nad objekty blob stránky Azure. Návrh nástroje Netherite umožňuje výrazně vyšší propustnost zpracování orchestrací a entit ve srovnání s jinými poskytovateli. V některých srovnávacích scénářích se ve srovnání s výchozím poskytovatelem Azure Storage ukázalo, že se propustnost zvýší o více než řád.
Další informace o podporovaných poskytovatelích úložiště pro Durable Functions a jejich porovnání najdete v dokumentaci k poskytovatelům Durable Functions úložiště.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro