Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje jev "flapping" při automatickém škálování a jak se mu vyhnout.
Flapping označuje stav smyčky, který způsobuje sérii protichůdných událostí v rámci škálování. K flappingu dojde, když událost škálování aktivuje opačnou událost škálování.
Automatické škálování vyhodnotí čekající změnu kapacity a zjistí, jestli by to způsobilo nestabilitu. V případech, kdy může dojít k kolísání, může automatické škálování přeskočit akci škálování a znovu ji vyhodnotit při dalším běhu, nebo může škálovat o méně než zadaný počet instancí prostředků. Proces vyhodnocení automatického škálování probíhá při každém spuštění modulu automatického škálování, což je v závislosti na typu prostředku každých 30 až 60 sekund.
Aby byly zajištěny adekvátní prostředky, nekontroluje se možnost nestability u událostí zvyšování kapacity. Automatické škálování odloží pouze událost snížení kapacity, aby se zabránilo nestabilitě.
Předpokládejme například následující pravidla:
- Vertikální navýšení kapacity o 1 instanci, když průměrné využití procesoru překročí 50 %.
- Škálování snížení počtu instancí o 1 instanci, pokud je průměrné využití procesoru nižší než 30 %.
V tabulce níže na T0, když je využití na 56 %, se spustí akce rozšíření kapacity a výsledkem je 56% využití procesoru napříč 2 instancemi. To poskytuje průměr 28 % pro škálovací sadu. Vzhledem k tomu, že 28 % je menší než práh pro zmenšení, automatické škálování by se mělo snížit. Škálování by vrátilo škálovací sadu na 56% využití procesoru, které aktivuje akci horizontálního navýšení kapacity.
| Čas | Počet instancí | Procesor% | Cpu % na instanci | Událost pro škálování | Výsledný počet instancí |
|---|---|---|---|---|---|
| T0 | 1 | 56% | 56% | Horizontální navýšení kapacity | 2 |
| T1 | 2 | 56% | 28 % | Škálovat dovnitř | 1 |
| T2 | 1 | 56% | 56% | Horizontální navýšení kapacity | 2 |
| T3 | 2 | 56% | 28 % | Škálovat dovnitř | 1 |
Pokud by zůstalo nekontrolované, probíhala by neustálá série událostí s rostoucím rozsahem. V této situaci ale modul automatického škálování odloží událost škálování na T1 a během dalšího spuštění automatického škálování znovu vyhodnocuje. Škálování směrem dolů proběhne pouze poté, co průměrné využití procesoru klesne pod 30 %.
Flapping je často způsobeno:
- Malé nebo žádné okraje mezi prahovými hodnotami
- Škálování podle více instancí
- Horizontální navýšení nebo snížení kapacity s využitím různých metrik
Malé nebo žádné okraje mezi prahovými hodnotami
Abyste se vyhnuli kolísání, zachovejte odpovídající okraje mezi prahovými hodnotami škálování.
Například následující pravidla, která nemají rozdíl mezi prahovými hodnotami, způsobují nestabilitu.
- Škálování při počtu >vláken ≤ 600
- Škálování při počtu < vláken 600
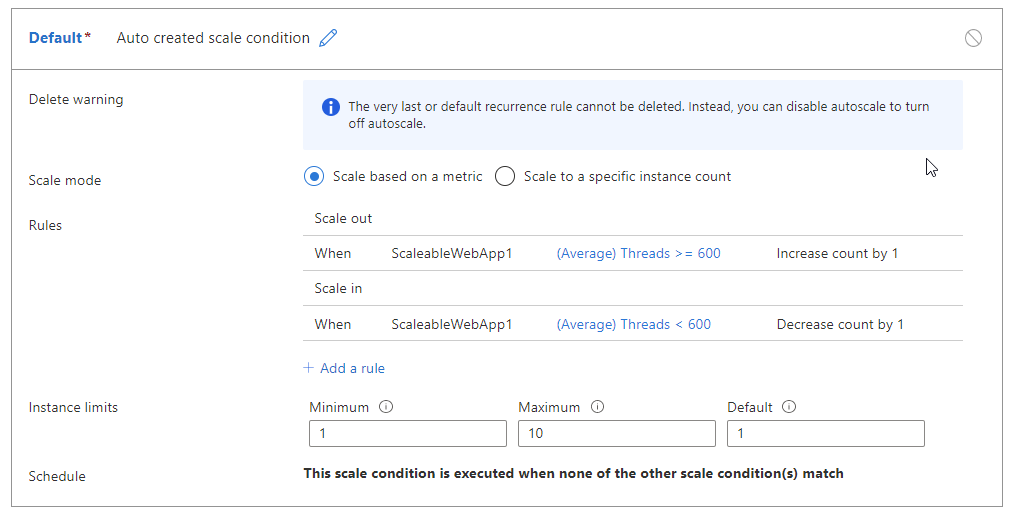
Následující tabulka ukazuje potenciální výsledek těchto pravidel automatického škálování:
| Čas | Počet instancí | Počet vláken | Počet vláken na instanci | Událost pro škálování | Výsledný počet instancí |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Horizontální navýšení kapacity | 3 |
| T1 | 3 | 1250 | 417 | Škálovat dovnitř | 2 |
- V době T0 existují dvě instance zpracovávající 1250 vláken nebo 625 treadů na instanci. Automatické škálování rozšiřuje na tři instance.
- Po škálování na úrovni T1 máme stále stejných 1250 vláken, ale se třemi instancemi je to pouze 417 vláken na instanci. Aktivuje se událost snížení kapacity.
- Před horizontálním škálováním automatické škálování vyhodnotí, co by se stalo, když dojde k události horizontálního snížení kapacity. V tomto příkladu 1250 / 2 = 625, to znamená 625 vláken na instanci. Automatické škálování by po horizontálním navýšení kapacity muselo okamžitě horizontálně snížit kapacitu. Pokud by se znovu zvýšilo zatížení a bylo by nutné škálovat, proces by se opakoval, což by vedlo k nestabilní smyčce.
- Aby se této situaci zabránilo, automatické škálování se nes škáluje. Automatické škálování přeskočí aktuální událost škálování a v dalším cyklu provádění znovu vyhodnocuje pravidlo.
V tomto případě to vypadá, že automatické škálování nefunguje, protože neprobíhá žádná událost škálování. Na stránce nastavení automatického škálování zkontrolujte kartu Historie spuštění a zkontrolujte, jestli nedošlo k nějakému flappingu.

Nastavení přiměřeného okraje mezi prahovými hodnotami zabrání výše uvedenému scénáři. Příklad:
- Škálování při počtu >vláken ≤ 600
- Škálování při počtu < vláken 400

Pokud je počet vláken při škálování dovnitř 400, celkový počet vláken by musel klesnout pod 1200, aby došlo k události škálování. Podívejte se na následující tabulku.
| Čas | Počet instancí | Počet vláken | Počet vláken na instanci | Událost pro škálování | Výsledný počet instancí |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Horizontální navýšení kapacity | 3 |
| T1 | 3 | 1250 | 417 | žádná významná událost | 3 |
| T2 | 3 | 1180 | 394 | zmenšení kapacity | 2 |
| T3 | 3 | 1180 | 590 | žádná významná událost | 2 |
Škálování podle více instancí
Pokud se chcete vyhnout flappingu při horizontálním navýšení nebo snížení kapacity o více než jednu instanci, může se automatické škálování škálovat o méně než počet instancí zadaných v pravidle.
Například následující pravidla můžou způsobit tzv. "flapping":
- Rozšiřte o 20, když je počet požadavků >= 200 na instanci.
- NEBO, když je zatížení CPU > 70 % na jednu instanci.
- Pokud se <počet požadavků =50 na instanci škáluje o 10.
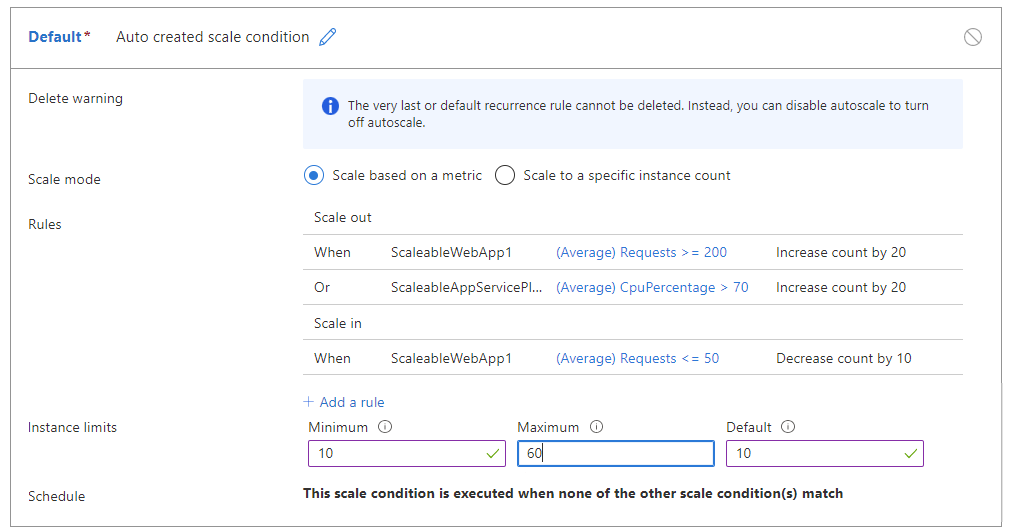
Následující tabulka ukazuje potenciální výsledek těchto pravidel automatického škálování:
| Čas | Počet instancí | Procesor | Počet požadavků | Událost pro škálování | Výsledné instance | Komentáře |
|---|---|---|---|---|---|---|
| T0 | 30 | 65 % | 3000 nebo 100 za jednu instanci. | Žádná událost škálování | 30 | |
| T1 | 30 | 65 | 1 500 | Snížit počet instancí o 3 | 27 | Vertikální navýšení kapacity o 10 by způsobilo odhadovaný nárůst procesoru nad 70 %, což vede k události horizontálního navýšení kapacity. |
V době T0 běží aplikace s 30 instancemi, celkovým počtem požadavků 3000 a využitím procesoru 65 % na instanci.
Pokud počet požadavků v T1 klesne na 1500 požadavků nebo 50 požadavků na instanci, automatické škálování se pokusí škálovat o 10 instancí na 20. Automatické škálování kapacity však odhaduje, že zatížení procesoru pro 20 instancí bude vyšší než 70 %, což způsobí událost rozšíření kapacity.
Aby se zabránilo flappingu, modul automatického škálování odhadne využití procesoru pro instance vyšší než 20, dokud nenajde počet instancí, ve kterém se všechny metriky nacházejí v definovaných prahových hodnotách:
- Udržujte využití CPU pod 70 %.
- Udržujte počet požadavků na instanci vyšší než 50.
- Snižte počet instancí pod 30.
V takovém případě se automatické škálování může škálovat o 3, od 30 do 27 instancí, aby vyhovovalo pravidlům, i když pravidlo určuje snížení o 10. Do protokolu aktivit se zapíše zpráva protokolu s popisem, který zahrnuje snížení měřítka s aktualizovaným počtem instancí, aby se zabránilo přerušovanému chování.
Pokud automatické škálování nedokáže najít vhodný počet instancí, škálování v případě potřeby přeskočí a během dalšího cyklu znovu vyhodnocuje.
Poznámka:
Pokud modul automatického škálování zjistí, že k flappingu může dojít v důsledku škálování na cílový počet instancí, pokusí se také škálovat na nižší počet instancí mezi aktuálním počtem a cílovým počtem. Pokud v tomto rozsahu nedochází k flappingu, automatické škálování bude pokračovat s novým cílem.
Soubory protokolu
V protokolu aktivit vyhledejte flapping pomocí následujícího dotazu:
// Activity log, CategoryValue: Autoscale
// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action
AzureActivity
|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action"
|sort by TimeGenerated desc
Níže je příklad záznamu protokolu aktivit pro flapping:

{
"eventCategory": "Autoscale",
"eventName": "FlappingOccurred",
"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444",
"eventProperties":
"{"Description":"Scale down will occur with updated instance count to avoid flapping.
Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'.
Current instance count: '6',
Intended new instance count: '1'.
Actual new instance count: '4'",
"ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan",
"OldInstancesCount":6,
"NewInstancesCount":4,
"ActiveAutoscaleProfile":{"Name":"Auto created scale condition",
"Capacity":{"Minimum":"1","Maximum":"30","Default":"1"},
"Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}",
"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa",
"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z",
"resource": "scaleableappserviceplan",
"resourceGroup": "RG-001",
"resourceProviderValue": "MICROSOFT.WEB",
"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e",
"activityStatusValue": "Succeeded"
}
Další kroky
Další informace o automatickém škálování najdete v následujících zdrojích informací: