Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek vysvětluje agregaci metrik v databázi časových řad, která zálohuje metriky platformy Azure Monitor a vlastní metriky. Článek platí také pro standardní metriky Application Insights.
Tyto informace v tomto článku jsou složité a poskytují se těm, kteří chtějí hlouběji prozkoumat systém metrik. Abyste mohli efektivně používat metriky služby Azure Monitor, nemusíte ho rozumět.
Přehled a termíny
Když do grafu přidáte metriku, průzkumník metrik automaticky předem vybere výchozí agregaci. Výchozí nastavení dává smysl v základních scénářích, ale pomocí různých agregací můžete získat další přehledy o metrikě. Zobrazení různých agregací na grafu vyžaduje porozumění tomu, jak s nimi pracuje průzkumník metrik.
Pojďme nejprve jasně definovat několik termínů:
- Hodnota metriky – jedna hodnota měření shromážděná pro konkrétní prostředek.
- Databáze Time-Series – Databáze optimalizovaná pro ukládání a načítání datových bodů, které obsahují hodnotu a odpovídající časové razítko.
- Časové období – obecné časové období.
- Časový interval – časové období mezi shromažďováním dvou hodnot metriky.
- Časový rozsah – časové období zobrazené v grafu. Typická výchozí hodnota je 24 hodin. K dispozici jsou pouze konkrétní rozsahy.
- Časová granularita nebo časové zrno – časové období použité k agregaci hodnot, aby bylo možné zobrazit v grafu. K dispozici jsou pouze konkrétní rozsahy. Aktuální minimum je 1 minuta. Hodnota časové granularity by měla být menší než vybraný časový rozsah, aby byla užitečná, jinak se pro celý graf zobrazí pouze jedna hodnota.
- Typ agregace – typ statistiky vypočítaný z více hodnot metrik.
- Agregace – proces přebírání více vstupních hodnot a jejich následné použití k vytvoření jedné výstupní hodnoty prostřednictvím pravidel definovaných typem agregace. Například vypočítání průměru více hodnot.
Shrnutí procesu
Metriky jsou řada hodnot uložených s časovým razítkem. V Azure se většina metrik ukládá do databáze časové řady metrik Azure. Při vykreslení grafu se hodnoty vybraných metrik načtou z databáze a pak se agregují samostatně na základě zvolené časové intervaly (označované také jako agregační interval). Velikost časové granularity vyberete pomocí výběru času v průzkumníku metrik. Pokud neprovedete explicitní výběr, granularity se automaticky zvolí na základě aktuálně zvoleného časového rozsahu. Po výběru jsou hodnoty metrik zachycené během každého intervalu členitosti agregovány a umístěny do grafu – jeden datový bod za interval.
Typy agregace
V Průzkumníku metrik je k dispozici pět základních typů agregace. Průzkumník metrik skryje agregace, které jsou irelevantní a nejde je použít pro danou metriku.
- Součet – součet všech hodnot zachycených v agregačním intervalu. Někdy se označuje jako celková agregace.
- Count – počet měření zachycených v agregačním intervalu. Počet nezohledňuje hodnotu měření, ale pouze počet záznamů.
- Průměr – průměr hodnot metrik zachycených v agregačním intervalu U většiny metrik je tato hodnota součet/počet.
- Min – nejmenší hodnota zachycená v agregačním intervalu.
- Maximum – největší hodnota zachycená v agregačním intervalu.
Předpokládejme například, že graf zobrazuje metriku Celkový odchozí provoz v síti pro virtuální počítač pomocí SUMA agregace za uplynulých 24 hodin. Časový rozsah a členitost lze změnit z pravého horního rohu grafu, jak je vidět na následujícím snímku obrazovky.
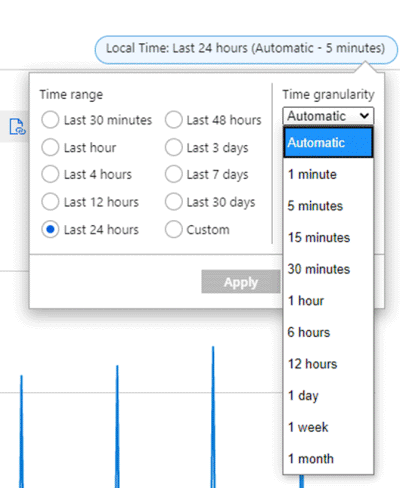
Pro časové intervaly = 30 minut a časový rozsah = 24 hodin:
- Graf je nakreslen ze 48 datových bodů. To je 24 hodin x 2 datové body za hodinu (60 minut/30min) agregované 1minutové datové body.
- Spojnicový graf spojuje 48 bodů v oblasti grafu.
- Každý datový bod představuje součet všech bajtů odchozí sítě odesílaných během každého z příslušných 30 minutových časových období.

Kliknutím na obrázky v této části zobrazíte větší verze.
Pokud přepnete časové intervaly na 15 minut, graf se nakreslí z 96 agregovaných datových bodů. To znamená, že 60min/15min = 4 datové body za hodinu x 24 hodin.

Pro časové intervaly 5 minut získáte 24 x (60/5) = 288 bodů.
Pro časové intervaly 1 minuty (nejmenší možné v grafu) získáte 24 x 60/1 = 1440 bodů.

Grafy vypadají pro tyto součty jinak, jak je znázorněno na předchozích snímcích obrazovky. Všimněte si, že tento virtuální počítač má v malém časovém období mnoho výstupů vzhledem ke zbytku časového intervalu.
Časová členitost umožňuje upravit poměr signálu k šumu v grafu. Vyšší agregace odstraňují šum a vyhlazují špičky. Všimněte si variant v dolním 1minutovém grafu a zjistěte, jak se vyhladí při přechodu na hodnoty vyšší členitosti.
Toto chování při vyhlazování je důležité, když tato data odesíláte do jiných systémů – například výstrahy. Obvykle nechcete být upozorňováni na krátké špičky v používání procesoru nad 90 %. Pokud ale procesor zůstane na 90 % po dobu 5 minut, je to pravděpodobně důležité. Pokud nastavíte pravidlo upozornění na procesor (nebo libovolnou metriku), zvýšení časové granularisty může snížit počet falešných upozornění, které obdržíte.
Je důležité určit, co je pro vaši úlohu "normální", abyste věděli, jaký časový interval je nejlepší. Toto je jednou z výhod dynamických upozornění, což je jiné téma, které zde není popsáno.
Jak systém shromažďuje metriky
Shromažďování dat se liší podle metrik.
Poznámka:
Následující příklady jsou zjednodušené pro ilustraci a skutečná data metrik zahrnutá v každé agregaci jsou ovlivněna daty dostupnými při vyhodnocení.
Frekvence sběru měření
Existují dva typy období kolekce.
Normální – Metrika se shromažďuje v konzistentním časovém intervalu, který se neliší.
Na základě aktivity – metrika se shromažďuje na základě toho, kdy dojde k transakci určitého typu. Každá transakce má položku metriky a časové razítko. Neshromažďují se v pravidelných intervalech, takže v daném časovém období existuje různý počet záznamů.
Členitost
Minimální časová členitost je 1 minuta, ale základní systém může zaznamenávat data rychleji v závislosti na metrice. Například procento procesoru pro virtuální počítač Azure se zaznamenává v časovém intervalu 15 sekund. Vzhledem k tomu, že selhání PROTOKOLU HTTP se sledují jako transakce, můžou snadno překročit více než jednu minutu. Další metriky, jako je SQL Storage, se zaznamenávají v časovém intervalu každých 20 minut. Tato volba záleží na jednotlivém poskytovateli a typu prostředků. Většina se snaží poskytnout nejmenší možný časový interval.
Dimenze, rozdělení a filtrování
Metriky se zaznamenávají pro každý jednotlivý prostředek. Úroveň, na které se metriky shromažďují, ukládají a můžou být grafované, se ale můžou lišit. Tato úroveň je reprezentována dalšími metrikami dostupnými v dimenzích metrik. Každý jednotlivý poskytovatel prostředků definuje, jak jsou podrobná data, která shromažďují. Azure Monitor definuje, jak se mají tyto podrobnosti zobrazovat a ukládat.
Když v Průzkumníku metrik namapujete metriku, máte možnost graf rozdělit podle dimenze. Rozčlenění grafu znamená, že se díváte na podkladová data pro podrobnější analýzu a vidíte, že tato data jsou buď vykreslena, nebo filtrována v Průzkumníku metrik.
Například Microsoft.ApiManagement/service má umístění jako dimenzi pro mnoho metrik.
Kapacita je jednou z těchto metrik. Rozměr Umístění znamená, že základní systém ukládá záznam metriky pro kapacitu každého umístění, a ne jen jeden pro celkový objem. Tyto informace pak můžete načíst nebo rozdělit v metrickém grafu.
Když se podíváte na celkovou dobu trvání požadavků brány, máte k dispozici 2 dimenze: Umístění a Hostitel. Tyto dimenze vám sdělují, z jakého umístění trvání pochází a jaký má hostitel název.
Jedna z flexibilnějších metrik, Požadavky, má 7 různých dimenzí.
Podrobnosti o jednotlivých metrikách a dostupných dimenzích najdete v článku Podporované metriky ve službě Azure Monitor. Kromě toho může dokumentace pro každého poskytovatele prostředků a typ poskytnout další informace o dimenzích a o tom, co měří.
K prozkoumání problému můžete použít rozdělení a filtrování. Níže je příklad obrázku znázorňující průměrný počet bajtů zápisu na disk pro skupinu virtuálních počítačů v rámci skupiny prostředků. Máme souhrn všech virtuálních počítačů s touto metrikou, ale můžeme se podívat, které jsou zodpovědné za špičky kolem 6:00. Jsou to stejné počítače? Kolik strojů je zapojeno?

Kliknutím na obrázky v této části zobrazíte větší verze.
Když použijeme rozdělení, uvidíme podkladová data, ale je to trochu bordel. Ukázalo se, že do výše uvedeného grafu se agreguje 20 virtuálních počítačů. V tomto případě jsme myší najeli na maximum v 6:00, které nám ukazuje, že příčinou je CH-DCVM11. Je těžké vidět zbytek dat spojených s tímto virtuálním počítačem kvůli jiným virtuálním počítačům, které způsobují nepřehlednost v grafu.

Pomocí filtrování můžeme graf vyčistit, abychom viděli, co se skutečně děje. Můžete zaškrtnout nebo odškrtnout virtuální počítače, které chcete zobrazit. Všimněte si tečkovaných čar. Ty jsou zmíněny v další části.

Další informace o tom, jak zobrazit rozdělení dat o dimenzi v grafu nástroje pro zkoumání metrik, najdete v tématu Použití filtrů dimenzí a rozdělení.
Hodnoty NULL a nula
Pokud systém očekává data metriky z prostředku, ale neobdrží je, zaznamená hodnotu NULL. Hodnota NULL se liší od nulové hodnoty, která se stává důležitou při výpočtu agregací a grafů. Hodnoty NULL se nezapočítávají jako platné hodnoty.
V různých grafech se prázdné hodnoty zobrazují odlišně. Bodové grafy nezobrazují tečku v grafu. Pruhové grafy neukazují sloupec. U spojnicových grafů se NULL může zobrazit jako tečkované nebo přerušované čáry podobně jako ty, které se zobrazují na snímku obrazovky v předchozí části. Při výpočtu průměrů, které zahrnují hodnoty NULLs, existuje méně datových bodů, ze kterého se má průměr vzít. Toto chování může někdy vést k neočekávanému poklesu hodnot v grafu, ale méně, než kdyby byla hodnota převedena na nulu a použita jako platný datový bod.
Vlastní metriky vždy používají hodnoty NUL, pokud nejsou přijata žádná data. Co se týče metrik platformy, každý poskytovatel prostředků se rozhodne, jestli použije nuly nebo NULLy na základě toho, co dává největší smysl pro danou metriku.
Upozornění služby Azure Monitor používají hodnoty, které poskytovatel prostředků zapisuje do databáze metrik, takže je důležité vědět, jak poskytovatel prostředků zpracovává hodnoty NUL, zobrazením dat nejprve.
Jak funguje agregace
Grafy metrik v předchozím systému zobrazují různé typy agregovaných dat. Systém předagaguje data tak, aby požadované grafy mohly zobrazit rychleji bez mnoha opakovaných výpočtů.
V tomto příkladu:
- Shromažďujeme fiktivní transakční metriku s názvem selhání PROTOKOLU HTTP.
- Server je rozměrem pro metriku selhání HTTP.
- Máme 3 servery – Server A, B a C.
Abychom zjednodušili vysvětlení, začneme jenom s typem agregace SUMA.
Subminutová až 1minutová agregace
První nezpracovaná data metrik se shromažďují a ukládají v databázi metrik služby Azure Monitor. V tomto případě má každý server transakční záznamy uložené s časovým razítkem, protože Server je dimenze. Vzhledem k tomu, že nejmenší časové období, které můžete zobrazit jako zákazník, je 1 minuta, jsou tato časová razítka nejprve agregována do 1minutových hodnot metrik pro každý jednotlivý server. Proces agregace pro Server B je znázorněn na obrázku níže. Servery A a C jsou zpracovány stejným způsobem a mají různá data.
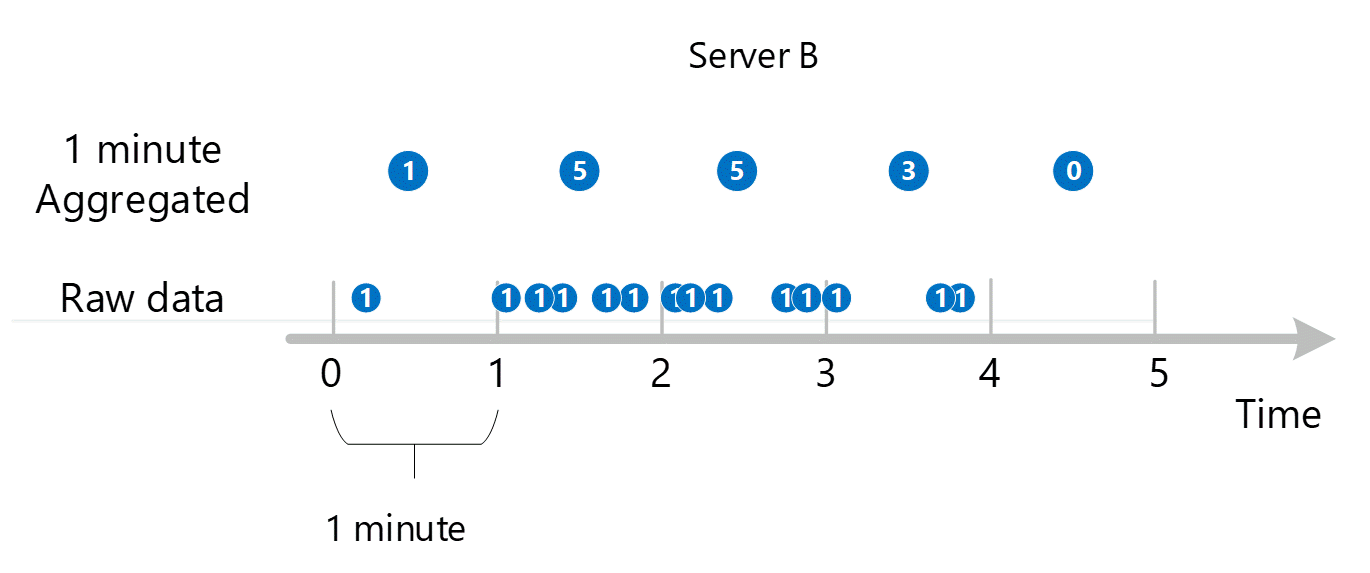
Výsledné 1minutové agregované hodnoty se ukládají jako nové položky v databázi metrik, aby je bylo možné shromáždit pro pozdější výpočty.
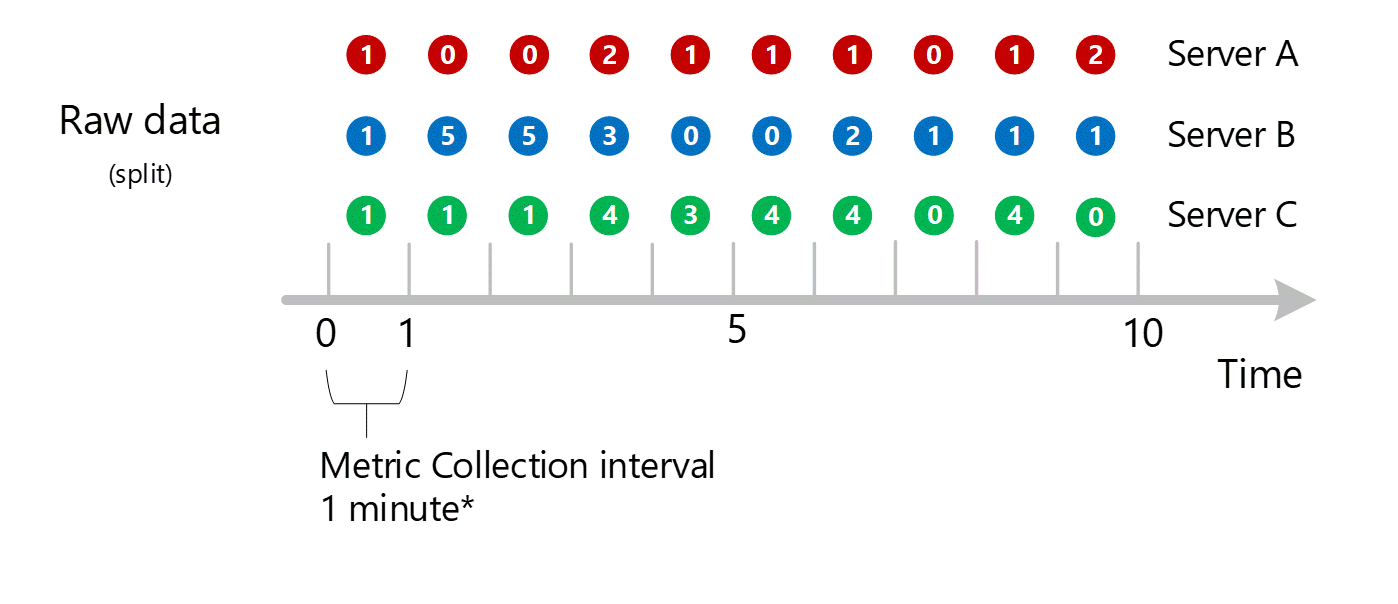
Agregace dimenzí
1-minutové výpočty se pak sbalí podle dimenze a znovu se uloží jako jednotlivé záznamy. V tomto případě se všechna data ze všech jednotlivých serverů agregují do 1minutové metriky intervalu a ukládají se do databáze metrik pro pozdější agregace.
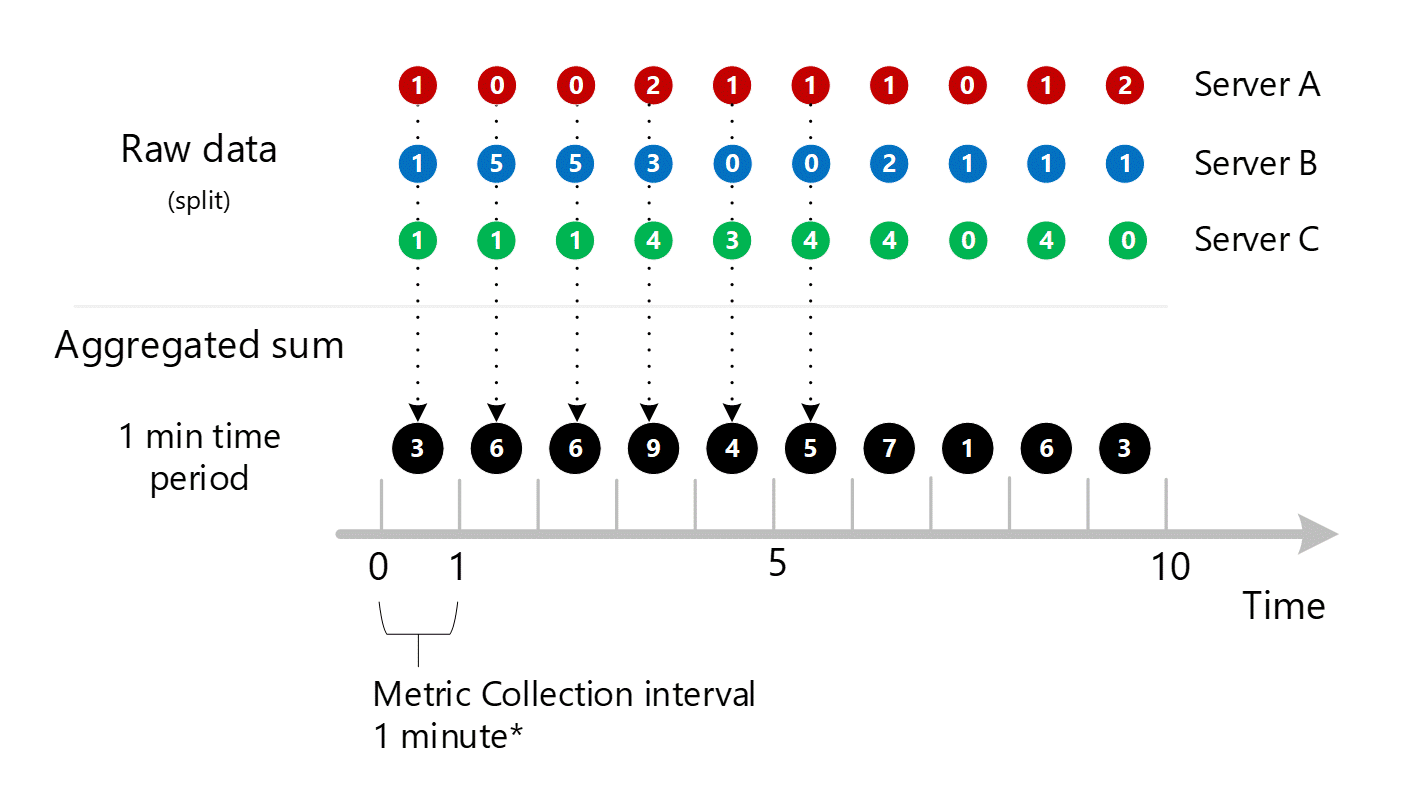
Pro přehlednost uvádí následující tabulka metodu agregace.
| Období | Server A | Server B | Server C | Součet (A+B+C) |
|---|---|---|---|---|
| Minuta 1 | 1 | 1 | 1 | 3 |
| Minuta 2 | 0 | 5 | 1 | 6 |
| Minuta 3 | 0 | 5 | 1 | 6 |
| Minuta 4 | 2 | 3 | 4 | 9 |
| Minuta 5 | 1 | 0 | 3 | 4 |
| Minuta 6 | 1 | 0 | 4 | 5 |
| Minuta 7 | 1 | 2 | 4 | 7 |
| Minuta 8 | 0 | 1 | 0 | 1 |
| Minuta 9 | 1 | 1 | 4 | 6 |
| Minuta 10 | 2 | 1 | 0 | 3 |
Výše je zobrazena pouze jedna dimenze, ale stejná agregace a proces ukládání probíhají pro všechny dimenze, které metrika podporuje.
- Shromážděte hodnoty do jednominutové agregované sady podle daného rozměru. Tyto hodnoty uložte.
- Transformace dimenze do agregovaného součtu za 1 minutu. Tyto hodnoty uložte.
Pojďme zavést další dimenzi selhání PROTOKOLU HTTP s názvem NetworkAdapter. Řekněme, že jsme měli různý počet adaptérů na server.
- Server A má 1 adaptér
- Server B má 2 adaptéry
- Server C má 3 adaptéry
Data pro následující transakce bychom shromáždili samostatně. Označí se jako:
- Jeden čas
- Hodnota
- Server, ze které transakce pochází
- Adaptér, ze kterého transakce pochází
Každý z těchto dílčích datových proudů by se pak agregoval do 1minutových hodnot časových řad a uložil do databáze metrik Služby Azure Monitor:
- Server A, Adaptér 1
- Server B, adaptér 1
- Server B, Adaptér 2
- Server C, Adaptér 1
- Server C, Adaptér 2
- Server C, Adaptér 3
Kromě toho by se uložily i následující sbalené agregace:
- Server A, Adapter 1 (protože není co sbalit, bude uložen znovu)
- Server B, adaptér 1+2
- Server C, adaptér 1+2+3
- Servery ALL, Adaptéry ALL
To ukazuje, že metriky s velkým počtem dimenzí mají větší počet agregací. Není důležité znát všechny permutace, jen pochopit důvod. Systém chce mít jednotlivá data i agregovaná data uložená pro rychlé načtení pro přístup k libovolnému grafu. Systém vybere buď nejrelevavantnější uloženou agregaci, nebo podkladová nezpracovaná data v závislosti na tom, co se rozhodnete zobrazit.
Agregace bez dimenzí
Vzhledem k tomu, že tato metrika má dimenzí Server, můžete se dostat k podkladovým datům pro server A, B a C prostřednictvím rozdělení a filtrování, jak bylo vysvětleno dříve v tomto článku. Pokud metrika neměla Server jako dimenzi, měl byste jako zákazník přístup pouze k souhrnným 1-minutovým součtům zobrazeným černě na diagramu. To znamená hodnoty 3, 6, 6, 6, 9 atd. Systém by také neudělal podkladovou práci k agregaci rozdělených hodnot, které by nikdy nepoužil v Průzkumníku metrik ani je neposílal prostřednictvím rozhraní REST API metrik.
Zobrazení časových granularizací nad 1 minutu
Pokud požadujete metriky s větší členitostí, použije systém 1minutové agregované součty k výpočtu součtů pro větší časové intervaly. Níže tečkované čáry zobrazují metodu součtu pro 2minutové a 5minutové časové intervaly. Opět pro jednoduchost zobrazujeme jenom typ agregace SUMA.
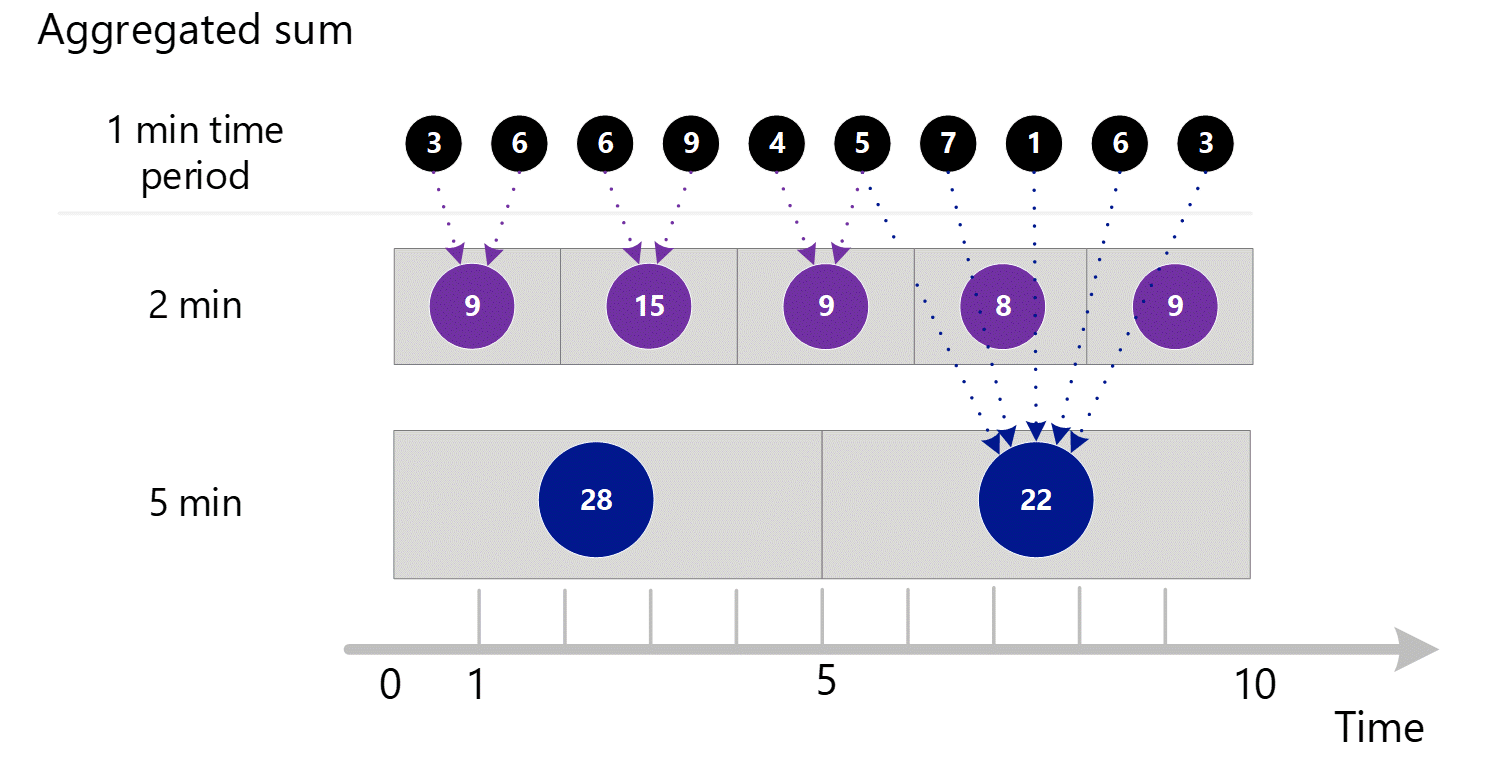
Pro dvojminutovou časovou granularitu.
| Období | Částky |
|---|---|
| Minuta 1 a 2 | (3 + 6) = 9 |
| Minuta 3 a 4 | (6 + 9) = 15 |
| Minuta 4 a 5 | (4 + 5) = 9 |
| Minuta 6 a 7 | (7 + 1) = 8 |
| Minuta 8 a 9 | (6 + 3) = 9 |
5minutová časová granularita.
| Období | Částky |
|---|---|
| Minuta 1 až 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minuta 6 až 10 | 5 + 7 + 1 + 6 + 3 = 22 |
Systém používá uložená agregovaná data, která poskytují nejlepší výkon.
Níže je větší diagram pro výše uvedený 1minutový proces agregace s některými šipkami, aby se zlepšila čitelnost.
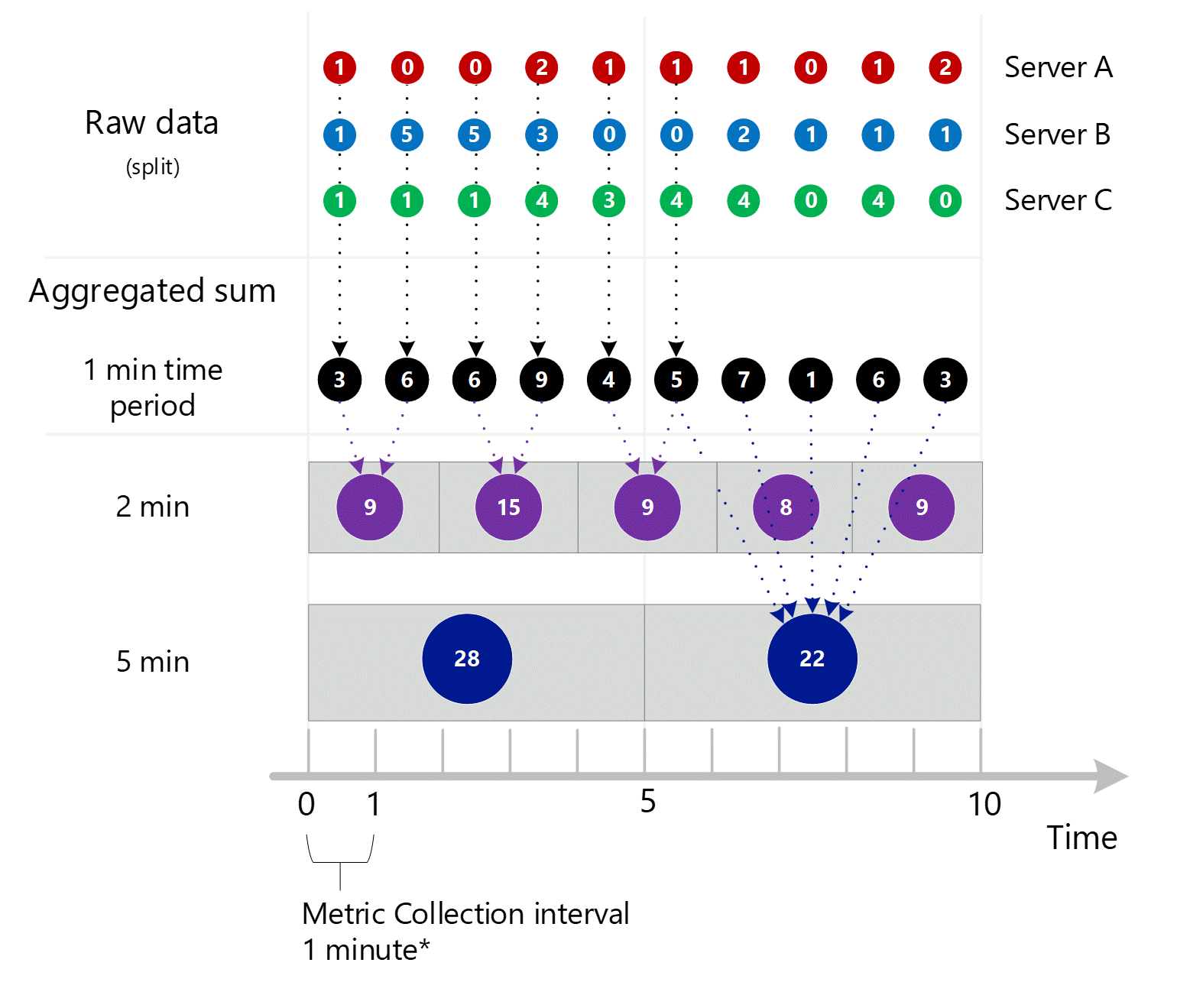
Složitější příklad
Následuje větší příklad použití hodnot pro fiktivní metriku s názvem Doba odezvy HTTP v milisekundách. Tady představujeme další úrovně složitosti.
- Zobrazíme agregaci pro součet, počet, minimum a maximum a výpočet pro průměr.
- Zobrazujeme hodnoty NULL a jejich vliv na výpočty.
Podívejte se na následující příklad. Pole a šipky ukazují příklady agregace a výpočtu hodnot.
Stejný 1minutový proces předběžné agregace, jak je popsáno v předchozí části, se vyskytuje u součtů, počtu, minimálního a maximálního počtu. Průměr však není předem agregovaný. Přepočítá se pomocí agregovaných dat, aby nedocházelo k chybám výpočtu.

Vezměte v úvahu minutu 6 pro jednominutovou agregaci, jak je zvýrazněno výše. Tato minuta je okamžikem, kdy se server B odpojil a přestal hlásit data, možná kvůli restartování.
Od 6. minuty a dále jsou počítané 1minutové typy agregace:
| Typ agregace | Hodnota | Poznámky |
|---|---|---|
| Suma | 53+20=73 | |
| Počet | 2 | Zobrazuje vliv hodnot NULL. Hodnota by byla 3, kdyby server byl online. |
| Minimální | 20 | |
| Maximálně | 53 | |
| Průměr | 73 / 2 | Vždy suma dělená počtem. Nikdy se neukládají a vždy se znovu přepočítávají pro každou úroveň podrobnosti pomocí agregovaných čísel pro tuto úroveň podrobnosti. Všimněte si přepočítání 5minutových a 10minutových časových intervalů, jak je zvýrazněno výše. |
Červená barva textu označuje hodnoty, které se mohou považovat za mimo normální rozsah, a ukazuje, jak se šíří (nebo nešíří) s tím, jak se zvyšuje časová granularita. Všimněte si, jak minimum a maximum značí, že existují základní anomálie, zatímco průměr a součty ztratí informace, jakmile se vaše časová členitost rozroste.
Můžete také vidět, že hodnoty NUL poskytují lepší výpočet průměru, než kdyby se místo toho použily nuly.
Poznámka:
I když ne v tomto příkladu, count se rovná součet v případech, kdy se metrika vždy zachycuje s hodnotou 1. To je běžné, když metrika sleduje výskyt transakční události – například počet selhání HTTP uvedených v předchozím příkladu v tomto článku.