Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Migrace vysoce výkonných databází úrovně Exadata do cloudu se stále více stává imperativním pro zákazníky Microsoftu. Softwarové sady dodavatelského řetězce obvykle nastavují vysoký standard kvůli intenzivním požadavkům na I/O operace úložiště se smíšenou zátěží čtení a zápisu spravovanou jedním výpočetním uzlem. Infrastruktura Azure v kombinaci se službou Azure NetApp Files dokáže splňovat požadavky této vysoce náročné úlohy. Tento článek představuje příklad toho, jak byla tato poptávka splněna pro jednoho zákazníka a jak Může Azure splňovat požadavky vašich důležitých úloh Oracle.
Výkon Oracle na podnikové úrovni
Při zkoumání horních limitů výkonu je důležité rozpoznat a omezit všechna omezení, která by mohla falešně zkosit výsledky. Pokud například záměrem je prokázat možnosti výkonu systému úložiště, měl by být klient ideálně nakonfigurovaný tak, aby se procesor nestal omezujícím faktorem před dosažením limitů výkonu úložiště. K tomuto účelu testování začalo s typem instance E104ids_v5, protože tento virtuální počítač je vybaven nejen síťovým rozhraním 100 Gb/s, ale s stejně velkým limitem výchozího přenosu dat (100 Gb/s).
Testování proběhlo ve dvou fázích:
- První fáze se zaměřila na testování pomocí standardního nástroje SLOB2 (Silly Little Oracle Benchmark) Kevin Clossona – verze 2.5.4. Cílem je řídit co nejvíce vstupně-výstupních operací Oracle z jednoho virtuálního počítače na více svazků Azure NetApp Files a pak škálovat pomocí více databází, aby bylo možné demonstrovat lineární škálování.
- Po otestování limitů škálování se naše testování přepíná na levnější, ale téměř tak schopné E96ds_v5 pro fázi testování zákazníka pomocí skutečné úlohy aplikace dodavatelského řetězce a dat z reálného světa.
Výkon škálování SLOB2
Následující grafy zachycují profil výkonu jednoho E104ids_v5 virtuálního počítače Azure s jednou databází Oracle 19c s osmi svazky Azure NetApp Files s osmi koncovými body úložiště. Svazky jsou rozdělené do tří skupin disků ASM: data, protokol a archivace. Skupině datových disků bylo přiděleno pět svazků, skupině disků protokolu dva svazky a skupině archivních disků jeden svazek. Všechny výsledky zachycené v tomto článku byly shromážděny pomocí produkčních oblastí Azure a aktivních produkčních služeb Azure.
Pokud chcete nasadit Oracle na virtuální počítače Azure pomocí více svazků Azure NetApp Files na více koncových bodech úložiště, použijte skupinu svazků aplikací pro Oracle.
Architektura s jedním hostitelem
Následující diagram znázorňuje architekturu, pro kterou bylo testování dokončeno; Všimněte si, že databáze Oracle se rozprostírá mezi několika svazky a koncovými body služby Azure NetApp Files.

Úložiště jednoho hostitele: vstupně-výstupní operace
Následující diagram znázorňuje 100% náhodně vybraných úloh s mírou zasažení vyrovnávací paměti databáze přibližně 8%. SLOB2 dokázalo řídit přibližně 850 000 vstupně-výstupních požadavků za sekundu při zachování latence událostí sekvenčního čtení souboru databáze v milisekundách. S velikostí bloku databáze 8K, což odpovídá přibližně 6 800 MiB/s propustnosti úložiště.

Propustnost jednoho hostitele
Následující diagram ukazuje, že pro úlohy náročné na šířku pásma náročné na sekvenční vstupně-výstupní operace, jako jsou úplné prohledávání tabulek nebo aktivity RMAN, může Služba Azure NetApp Files poskytovat možnosti plné šířky pásma samotného virtuálního počítače E104ids_v5.

Poznámka:
Vzhledem k tomu, že výpočetní instance má teoretickou maximální šířku pásma, přidání další souběžnosti aplikací vede pouze ke zvýšení latence na straně klienta. Výsledkem je, že úlohy SLOB2 překračují cílový časový rámec dokončení, takže počet vláken byl omezen na šest.
Výkon škálovatelného rozšíření systému SLOB2
Následující grafy zachycují profil výkonu tří E104ids_v5 virtuálních počítačů Azure, na kterých běží jedna databáze Oracle 19c a každá má vlastní sadu svazků Azure NetApp Files a stejné rozložení skupiny disků ASM, jak je popsáno v části Vertikální navýšení výkonu. Grafika ukazuje, že s Azure NetApp Files multi-volume/multi-endpoint se výkon snadno škáluje s konzistencí a předvídatelností.
Architektura s více hostiteli
Následující diagram znázorňuje architekturu, pro kterou bylo testování dokončeno; všimněte si tří databází Oracle rozložených mezi více svazky a koncovými body služby Azure NetApp Files. Koncové body můžou být vyhrazené pro jednoho hostitele, jak je znázorněno u virtuálního počítače Oracle 1 nebo sdílené mezi hostiteli, jak je znázorněno v oracle VM2 a Oracle VM 3.

Vícehostitelské úložiště IO
Následující diagram znázorňuje 100% náhodně vybraných úloh s mírou zasažení vyrovnávací paměti databáze přibližně 8%. SLOB2 dokázalo řídit přibližně 850 000 vstupně-výstupních požadavků za sekundu ve všech třech hostitelích jednotlivě. SLOB2 toho dokázal dosáhnout, zatímco paralelně zpracovával celkem přibližně 2 500 000 vstupně-výstupních požadavků za sekundu, přičemž každý hostitel stále udržoval latenci sekvenčního čtení souboru databáze pod milisekundu. S velikostí bloku databáze 8 KB se mezi třemi hostiteli rovná přibližně 20 000 MiB/s.

Propustnost pro více hostitelů
Následující diagram ukazuje, že u sekvenčních úloh může Azure NetApp Files stále poskytovat možnosti plné šířky pásma samotného virtuálního počítače E104ids_v5 i v případě, že se škáluje směrem ven. SLOB2 dokázal provádět vstupně-výstupní operace s celkovou rychlostí přes 30 000 MiB/s napříč třemi hostiteli během paralelního provozu.

Skutečný výkon
Po otestování limitů škálování pomocí SLOB2 se testy prováděly se sadou aplikací v reálném dodavatelském řetězci proti Oracle v Azure NetApp files s vynikajícími výsledky. Následující data ze sestavy AWR (Oracle Automatic Workload Repository) přinášejí zvýrazněný pohled na to, jak se provedla jedna v konkrétní kritická úloha.
Tato databáze má kromě úlohy aplikace významné další vstupně-výstupní operace, protože je povolená funkce flashback a má velikost bloku databáze 16 tisíc. V části profilu vstupně-výstupních operací sestavy AWR je zřejmé, že ve srovnání se čtením existuje velký poměr zápisů.
| - | Čtení a zápis za sekundu | Počet čtení za sekundu | Zápis za sekundu |
|---|---|---|---|
| Celkem (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Navzdory události sekvenčního čekání na čtení souboru db s vyšší latencí při 2,2 ms než při testování SLOB2 tento zákazník zaznamenal patnáctminutové snížení doby provádění úloh pocházející z databáze RAC v Exadata na databázi jedné instance v Azure.
Omezení prostředků Azure
Všechny systémy nakonec narazily na omezení prostředků, tradičně označované jako chokepointy. Databázové úlohy, zejména velmi náročné, jako jsou sady aplikací dodavatelského řetězce, jsou entity náročné na prostředky. Nalezení těchto omezení prostředků a jejich zpracování je nezbytné pro úspěšné nasazení. Tato část osvětluje různá omezení, se kterými se můžete setkat v právě takovém prostředí, a jak se s nimi vypořádat. V jednotlivých dílčích oddílech se dozvíte jak osvědčené postupy, tak odůvodnění.
Virtuální počítače
Tato část podrobně popisuje kritéria, která se mají zvážit při výběru virtuálních počítačů pro zajištění nejlepšího výkonu, a odůvodnění výběru provedeného při testování. Azure NetApp Files je služba NaS (Network Attached Storage), proto je pro optimální výkon důležitá vhodná velikost šířky pásma sítě.
Čipové sady
Prvním tématem zájmu je výběr čipové sady. Ujistěte se, že libovolná skladová položka virtuálního počítače, kterou vyberete, je postavená na jedné čipové sadě z důvodů konzistence. Varianta Intel E_v5 virtuálních počítačů běží na konfiguraci Intel Xeon Platinum 8370C (Ice Lake) třetí generace. Všechny virtuální počítače v této rodině jsou vybaveny jedním síťovým rozhraním 100 Gb/s. Naproti tomu řada E_v3, kterou jsme zmínili například, je postavená na čtyřech samostatných čipových sadách s různými šířkami pásma fyzické sítě. Čtyři čipové sady používané v E_v3 rodině (Broadwell, Skylake, Cascade Lake, Haswell) mají různé rychlosti procesoru, které ovlivňují charakteristiky výkonu počítače.
Pečlivě si přečtěte dokumentaci ke službě Azure Compute a věnujte pozornost možnostem čipové sady. Pro Azure NetApp Files se také podívejte na osvědčené postupy skladových položek virtuálních počítačů Azure. Výběr virtuálního počítače s jednou čipovou sadou je vhodnější pro nejlepší konzistenci.
Dostupná šířka pásma
Je důležité pochopit rozdíl mezi dostupnou šířkou pásma síťového rozhraní virtuálního počítače a měřenou šířkou pásma použitou na stejné straně. Pokud dokumentace ke službě Azure Compute hovoří o limitech šířky pásma sítě, použijí se tyto limity jenom pro výchozí přenos dat (zápis). Příchozí (čtení) provoz není měřený a proto je omezený pouze fyzickou šířkou pásma samotné síťové karty (NIC). Šířka pásma sítě většiny virtuálních počítačů převyšuje limit odchozího přenosu aplikovaný na počítač.
Vzhledem k tomu, že jsou svazky Azure NetApp Files připojené k síti, je možné omezení odchozího přenosu dat považovat za to, že platí konkrétně pro zápisy, zatímco příchozí přenos dat je definován jako čtení a úlohy podobné čtení. I když je výchozí limit většiny počítačů větší než šířka pásma sítě síťové karty, totéž nelze říci pro E104_v5 použité při testování tohoto článku. E104_v5 má 100 Gb/s síťovou kartu s limitem odchozího provozu nastaveným na 100 Gb/s. Ve srovnání má E96_v5 síťovou kartu s 100 Gb/s NIC s odchozím limitem 35 Gb/s a neomezeným příchozím přenosem dat na 100 Gb/s. S tím, jak se virtuální počítače zmenšují, omezení výchozího přenosu dat se zmenší, ale příchozí přenos dat zůstává nefetterovaný logickými limity.
Omezení výchozího přenosu dat jsou pro virtuální počítače široká a používají se jako takové pro všechny síťové úlohy. Při použití Oracle Data Guard jsou všechny zápisy zdvojovány do archivačních protokolů a je třeba brát v úvahu omezení přenosu dat při výchozím postupu. To platí také pro archivační záznam s více cílovými místy a pro RMAN, pokud se používá. Při výběru virtuálních počítačů se seznamte s nástroji příkazového řádku, jako je ethtool, které zpřístupňují konfiguraci síťové karty, protože Azure nedokumentuje konfigurace síťového rozhraní.
Síťová souběžnost
Virtuální počítače Azure a svazky Azure NetApp Files jsou vybaveny určitými objemy šířky pásma. Jak je znázorněno dříve, pokud má virtuální počítač dostatečnou kapacitu procesoru, může úloha teoreticky spotřebovat šířku pásma, která je k dispozici – to je v mezích použitého limitu síťové karty nebo výchozího přenosu dat. V praxi se ale množství dosažitelné propustnosti predikuje na souběžnost úlohy v síti, tedy počtu síťových toků a koncových bodů sítě.
Pro lepší pochopení si přečtěte část omezení toku sítě v dokumentu o šířce pásma sítě pro virtuální počítače. Poznatky: čím více síťových toků připojuje klienta k úložišti, tím větší je potenciální výkon.
Oracle podporuje dva samostatné klienty NFS, Kernelový NFS a Direct NFS (dNFS). Kernel NFS donedávna podporoval jediný síťový tok mezi dvěma koncovými body (výpočetní zařízení – úložiště). Přímý NFS, ten výkonnější ze dvou, podporuje proměnlivý počet síťových toků – testy ukázaly stovky jedinečných připojení na koncový bod – zvyšující nebo snižující se podle zatížení. Vzhledem k škálování síťového provozu mezi dvěma koncovými body je Přímý NFS mnohem preferován před NFS jádra, a proto je doporučenou konfigurací. Produktová skupina Azure NetApp Files nedoporučuje používat Kernel NFS s úlohami Oracle. Další informace najdete v tématu Výhody používání služby Azure NetApp Files se službou Oracle Database.
Souběžnost spouštění
Použití systému souborů NFS s přímým přístupem, jedné čipové sady pro konzistenci a pochopení omezení šířky pásma sítě vám zatím stačí. Aplikace nakonec řídí výkon. Důkazy konceptu používající SLOB2 a důkazy konceptu používající sadu aplikací reálného dodavatelského řetězce s použitím skutečných zákaznických dat dosáhly značné propustnosti pouze díky vysoké míře souběžnosti; první mód používá významný počet vláken na schéma, druhý mód na více připojení z několika aplikačních serverů. Stručně řečeno souběžnost řídí úlohy, nízkou souběžnost a nízkou propustnost, vysokou souběžnost– vysokou propustnost, pokud je infrastruktura zavedená tak, aby podporovala stejnou propustnost.
Akcelerované síťové služby
Akcelerované sítě umožňují virtuálnímu počítači využít virtualizaci SR-IOV (Single Root I/O Virtualization), což výrazně zlepšuje jeho síťový výkon. Tato cesta s vysokým výkonem obchází hostitele z cesty k datům, což snižuje latenci, zpoždění a využití procesoru u nejnáročnějších síťových úloh na podporovaných typech virtuálních počítačů. Při nasazování virtuálních počítačů prostřednictvím nástrojů pro správu konfigurace, jako je terraform nebo příkazový řádek, mějte na paměti, že akcelerované síťové služby nejsou ve výchozím nastavení povolené. Pro zajištění optimálního výkonu povolte akcelerované síťové služby. Všimněte si, že zrychlené síťové připojení je povolené nebo zakázané na bázi jednotlivých síťových rozhraní. Akcelerovaná síťová funkce je ta, která může být dynamicky povolená nebo zakázaná.
Poznámka:
Tento článek obsahuje odkazy na termín SLAVE, termín, který už Microsoft nepoužívá. Až bude tento termín ze softwaru odstraněn, odstraníme ho i z tohoto článku.
Efektivní způsob, jak zajistit povolení zrychleného síťového připojení pro síťový adaptér, je prostřednictvím terminálu Linux. Pokud je pro síťové rozhraní povolené akcelerované síťové rozhraní, je k první síťové kartě přidružená druhá virtuální síťová karta. Tato druhá síťová karta je nakonfigurována systémem s povoleným příznakem SLAVE . Pokud není k dispozici žádná síťová karta s příznakem SLAVE, akcelerovaná síť není pro toto rozhraní povolena.
Ve scénáři, kdy je nakonfigurováno více síťových adaptérů, je potřeba určit, které SLAVE rozhraní je přidružené k síťové kartě používané k připojení svazku NFS. Přidání síťových karet na virtuální počítač nemá žádný vliv na výkon.
Pomocí následujícího postupu identifikujte mapování mezi nakonfigurovaným síťovým rozhraním a přidruženým virtuálním rozhraním. Tento proces ověří, že je pro konkrétní síťovou kartu na vašem počítači s Linuxem povolená akcelerovaná síťová karta, a zobrazí rychlost fyzického příchozího přenosu dat, kterého může síťová karta potenciálně dosáhnout.
-
ip aSpusťte příkaz:
-
/sys/class/net/Uveďte adresář ID síťové karty, které ověřujete (eth0v příkladu) agreppro slovo nižší:ls /sys/class/net/eth0 | grep lower lower_eth1 -
ethtoolSpusťte příkaz na ethernetovém zařízení označeném jako nižší zařízení v předchozím kroku.
Virtuální počítač Azure: Omezení šířky pásma sítě a disku
Při čtení dokumentace k limitům výkonu virtuálních počítačů Azure se vyžaduje úroveň odborných znalostí. Mějte na paměti:
- Dočasná propustnost úložiště a čísla IOPS odkazují na možnosti výkonu dočasného úložiště přímo připojeného k virtuálnímu počítači.
- Propustnost disku bez mezipaměti a vstupně-výstupní čísla odkazují konkrétně na Disk Azure (Premium, Premium v2 a Ultra) a nemají žádný vliv na síťové připojené úložiště, jako je Azure NetApp Files.
- Připojení dalších síťových adaptérů k virtuálnímu počítači nemá žádný vliv na limity výkonu nebo možnosti výkonu virtuálního počítače (zdokumentované a otestované tak, aby byly pravdivé).
- Maximální šířka pásma sítě odkazuje na limity pro odchozí přenosy dat (tj. při zápisu, když se zapojí služba Azure NetApp Files), které jsou uplatňovány na šířku pásma sítě virtuálních počítačů. Nejsou použita žádná omezení příchozího přenosu dat (tj. čtení při použití služby Azure NetApp Files). Díky dostatečnému výkonu procesoru, souběžnému síťovému připojení a dostatečně bohatým koncovým bodům může virtuální počítač teoreticky dovést příchozí provoz k limitům síťové karty. Jak je zmíněno v části Dostupná šířka pásma sítě, použijte nástroje, které
ethtoolslouží k zobrazení šířky pásma síťové karty.
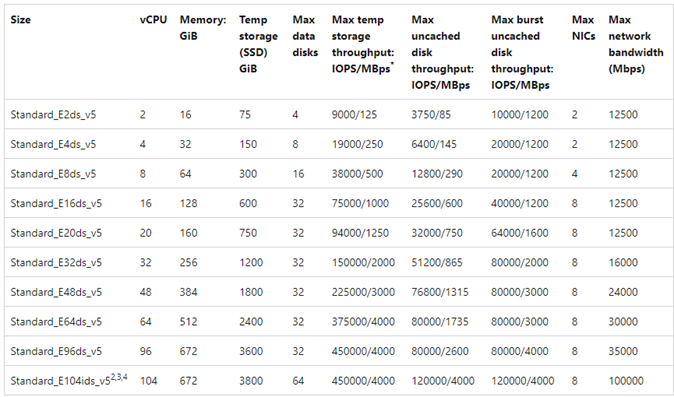
Pro referenci se zobrazí ukázkový graf:
Azure NetApp Files
Služba Azure NetApp Files prvního výrobce úložiště azure poskytuje vysoce dostupné plně spravované řešení úložiště, které podporuje náročné úlohy Oracle zavedené dříve.
Vzhledem k tomu, že omezení výkonu úložiště při škálování zvyšováním kapacity v databázi Oracle jsou dobře pochopitelná, tento článek se záměrně zaměřuje na výkon úložiště při horizontálním škálování na více systémů. Horizontální navýšení kapacity úložiště znamená, že poskytuje jednu instanci Oracle přístup k mnoha svazkům Azure NetApp Files, kde se tyto svazky distribuují přes několik koncových bodů úložiště.
Škálováním pracovního zatížení databáze napříč několika svazky takovým způsobem se výkon databáze stává nezávislým na horních limitech svazků a koncových bodů. S úložištěm, které již neomezuje výkon, se architektura virtuálního počítače (procesor, síťová karta a limity výstupu VM) stává překážkou, se kterou je třeba se vypořádat. Jak je uvedeno v sekci virtuálních počítačů, při výběru instancí E104ids_v5 a E96ds_v5 bylo toto zohledněno.
Bez ohledu na to, jestli je databáze umístěná na jednom svazku s velkou kapacitou nebo rozložená do několika menších svazků, celkové finanční náklady jsou stejné. Výhodou distribuce vstupně-výstupních operací mezi více svazků a koncových bodů na rozdíl od jednoho svazku a koncového bodu je zabránění limitům šířky pásma – můžete použít úplně to, za co platíte.
Důležité
Pokud chcete nasadit službu Azure NetApp Files v multiple volume:multiple endpoint konfiguraci, požádejte o pomoc specialistu na Azure NetApp Files nebo architekta cloudových řešení.
Databáze
Databáze Oracle verze 19c je aktuální dlouhodobou verzí Oracle a používá se k získání všech testovacích výsledků diskutovaných v tomto dokumentu.
Pro zajištění nejlepšího výkonu byly všechny databázové svazky připojeny pomocí Direct NFS, použití Kernel NFS se kvůli omezením výkonu nedoporučuje. Porovnání výkonu mezi těmito dvěma klienty najdete v tématu Výkon databáze Oracle na jednotlivých svazcích Azure NetApp Files. Všimněte si, že byly použity všechny relevantní opravy dNFS (Oracle Support ID 1495104), stejně jako osvědčené postupy popsané v databázích Oracle v Microsoft Azure pomocí sestavy Azure NetApp Files .
I když Oracle a Azure NetApp Files podporují NFSv3 i NFSv4.1, protože NFSv3 je vyspělejší protokol, který je obecně považován za nejstabilnější a je spolehlivější možností pro prostředí, která jsou vysoce citlivá na přerušení. Testování popsané v tomto článku bylo dokončeno přes NFSv3.
Důležité
Některé z doporučených oprav, které Oracle dokumentuje v rámci ID podpory 1495104, jsou kritické pro zachování integrity dat, když se používá dNFS. Aplikace těchto oprav se důrazně doporučuje pro produkční prostředí.
Pro svazky NFS se podporuje automatická správa úložiště (ASM). Ačkoli je obvykle spojováno s blokovým úložištěm, kde ASM nahrazuje správu logických svazků (LVM) i systém souborů, hraje ASM důležitou roli ve více svazkových scénářích NFS a stojí za důkladné zvážení. Jednou z takových výhod ASM je dynamické online přidávání a vyrovnávání mezi nově přidanými svazky NFS a koncovými body, což zjednodušuje správu a umožňuje rozšíření výkonu i kapacity. I když ASM samo o sobě nezvyšuje výkon databáze, jeho použití zabraňuje horkým souborům a nutnosti ruční údržby distribuce souborů – to je výhoda, která je snadno patrná.
Ke generování všech výsledků testů probíraných v tomto článku se použila konfigurace ASM přes dNFS. Následující diagram znázorňuje rozložení souboru ASM ve svazcích Azure NetApp Files a přidělení souborů skupinám disků ASM.

Při používání ASM přes připojené svazky NFS služby Azure NetApp Files existují určitá omezení, pokud jde o snímky úložiště, které je možné překonat s určitými aspekty architektury. Pokud ho chcete podrobně zkontrolovat, obraťte se na odborníka na Azure NetApp Files nebo architekta cloudových řešení.
Syntetické testovací nástroje a nastavení
Tato sekce popisuje testovací architekturu, nastavitelné parametry a specifické detaily konfigurace. Zatímco předchozí část se zaměřuje na důvody, proč se provádějí rozhodnutí o konfiguraci, tato část se konkrétně zaměřuje na to, "co" rozhodnutí o konfiguraci obnášejí.
Automatizované nasazení
- Databázové virtuální počítače se nasazují pomocí skriptů Bash dostupných na GitHubu.
- Rozložení a přidělení více svazků a koncových bodů Azure NetApp Files se dokončí ručně. Pokud potřebujete pomoc, musíte spolupracovat se specialistou na Azure NetApp Files nebo architektem cloudových řešení.
- Instalace mřížky, konfigurace ASM, vytvoření a konfigurace databáze a prostředí SLOB2 na každém počítači se konfiguruje pomocí Ansible pro konzistenci.
- Paralelní spouštění testů SLOB2 napříč více hostiteli se také dokončí pomocí Ansible pro konzistenci a souběžné provádění.
Konfigurace virtuálního počítače
| Konfigurace | Hodnota |
|---|---|
| oblast Azure | Západní Evropa |
| SKU virtuálního stroje | E104ids_v5 |
| Počet síťových adaptérů | 1 POZNÁMKA: Přidání virtuálních síťových adaptérů nemá žádný vliv na počet systémů |
| Maximální šířka pásma odchozí sítě (Mb/s) | 100 000 |
| Dočasné úložiště (SSD): GiB | 3,800 |
Konfigurace systému
Všechna požadovaná nastavení konfigurace systému Oracle pro verzi 19c byla implementována podle dokumentace Oracle.
Do systémového souboru Linuxu /etc/sysctl.conf byly přidány následující parametry:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Všechny svazky Azure NetApp Files byly připojeny s následujícími možnostmi připojení NFS.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parametry databáze
| Parametry | Hodnota |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Konfigurace SLOB2
Všechna generování úloh pro testování byla dokončena pomocí nástroje SLOB2 verze 2.5.4.
Čtrnáct schémat SLOB2 bylo načteno do standardního tabulkového prostoru Oracle a následně běželo spolu s nastavením konfiguračního souboru, což dohromady nastavilo datovou sadu SLOB2 na 7 TiB. Následující nastavení reprezentují vykonání náhodného čtení pro SLOB2. Parametr SCAN_PCT=0 konfigurace se během sekvenčního testování změnil na SCAN_PCT=100 .
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
V případě náhodného testování čtení se provedlo devět spuštění SLOB2. Počet vláken byl zvýšen o šest při každé iteraci testů počínaje jednou.
Pro sekvenční testování bylo provedeno sedm spuštění SLOB2. Počet vláken byl zvýšen o dva s každou iterací testů počínaje jednou. Počet vláken byl omezen na šest kvůli dosažení maximálních limitů šířky pásma sítě.
Metriky AWR
Všechny metriky výkonu byly hlášeny prostřednictvím úložiště AWR (Oracle Automatic Workload Repository). Ve výsledcích jsou uvedené následující metriky:
- Propustnost: součet průměrné propustnosti čtení a propustnosti zápisu z oddílu Profil zatížení AWR
- Průměrné požadavky na vstupně-výstupní operace čtení z oddílu Profilu zatížení AWR
- Databázový soubor čekací událost sekvenčního čtení průměrná doba čekání ze sekce AWR Foreground Wait Events
Migrace z účelově vytvořených, inženýrovaných systémů do cloudu
Oracle Exadata je navržená systémová kombinace hardwaru a softwaru, která je považována za nejoptimaličtější řešení pro spouštění úloh Oracle. Přestože cloud má v celkovém schématu technického světa významné výhody, tyto specializované systémy můžou vypadat neuvěřitelně atraktivní pro ty, kteří si přečetli a prohlédli optimalizace, které Oracle vytvořil na základě svých konkrétních úloh.
Pokud jde o spuštění Oracle na Exadata, existuje několik běžných důvodů, proč je exadata zvolena:
- 1–2 vysoké IO úlohy, které jsou přirozeně vhodné pro funkce Exadata, a protože tyto úlohy vyžadují významné inženýrské funkce Exadata, zbytek databází běžících společně s nimi byl konsolidován do Exadata.
- Složité nebo náročné úlohy OLTP, které potřebují RAC pro škálování a jsou náročné na architekturu s proprietárním hardwarem bez hlubokých znalostí optimalizace Oracle, nebo se mohou stát technickým dluhem, který nelze optimalizovat.
- Nevyužitá stávající Exadata s různými úlohami: existuje buď kvůli předchozím migracím, konci životního cyklu předchozí Exadata, nebo z důvodu touhy pracovat/testovat Exadata interně.
Je nezbytné, aby všechny migrace ze systému Exadata pochopili z hlediska úloh a jak jednoduchá nebo složitá může být migrace. Sekundární potřeba je pochopit důvod nákupu Exadata z pohledu stavu. Dovednosti v oblasti Exadata a RAC jsou vysoce žádané a mohou být důvodem, proč technické zainteresované strany doporučily jejich pořízení.
Důležité
Bez ohledu na scénář by měly být výsledné poznatky takové, že pro všechny databázové úlohy pocházející z Exadata platí: čím více se využívá vlastních funkcí Exadata, tím složitější je migrace a plánování. Prostředí, která nevyužívají proprietární funkce Exadata, mají příležitosti pro jednodušší proces migrace a plánování.
K vyhodnocení těchto příležitostí k úlohám je možné použít několik nástrojů:
- Automatické úložiště úloh (AWR):
- Všechny databáze Exadata mají licenci k používání sestav AWR a funkcí spojených s výkonem a diagnostikou.
- Je vždy zapnutá a shromažďuje data, která je možné použít k zobrazení historických informací o úlohách a vyhodnocení využití. Hodnoty ve špičce můžou vyhodnotit vysoké využití v systému,
- Sestavy AWR s širším oknem můžou posoudit celkovou pracovní zátěž a poskytnout cenný přehled o využití funkcí a o tom, jak efektivně migrovat pracovní zátěž na jiné než Exadata. Přehledy AWR se špičkovou hodnotou jsou nejlepší pro optimalizaci výkonu a řešení potíží.
- Sestava AWR global (RAC-Aware) pro Exadata obsahuje také oddíl specifický pro Exadata, který přejde k podrobnostem o využití konkrétních funkcí Exadata a poskytuje cenné informace o mezipaměti flash, flash protokolování, vstupně-výstupní operace a další využití funkcí databázovým uzlem a uzlem buňky.
Oddělení od Exadata
Při identifikaci úloh Oracle Exadata pro migraci do cloudu zvažte následující otázky a datové body:
- Využívá úloha více funkcí Exadata mimo výhody hardwaru?
- Inteligentní kontroly
- Indexy úložiště
- Mezipaměť Flash
- Protokolování flash
- Hybridní sloupcová komprese
- Je zátěž efektivně offloadována pomocí Exadata? Jaký je poměr úloh (více než 10% času databáze) při nejdůležitějších událostech popředí pomocí:
- Kontrola inteligentní tabulky v buňce (optimální)
- Víceblokové fyzické čtení buněk (méně optimální)
- Jednoblokové fyzické čtení buňky (nejméně optimální)
- Hybridní sloupcová komprese (HCC/EHCC): Co je komprimovaný vs. nekomprimovaný poměr:
- Utrácí databáze více než 10% času databáze při komprimaci a dekomprimaci dat?
- Prozkoumejte zvýšení výkonu predikátů při použití komprese v dotazech: je dosažený výkon hodnotný ve srovnání s úsporou získanou kompresí?
- Fyzické IO buněk: Zkontrolujte úspory dosažené z:
- množství směrované na databázový uzel pro vyrovnání zátěže CPU.
- určuje počet bajtů vrácených inteligentním skenováním. Tyto hodnoty je možné odečíst ve vstupně-výstupních operacích pro procento jediného blokového fyzického čtení buněk, jakmile migruje z Exadata.
- Všimněte si počtu logických čtení z mezipaměti. Určete, jestli bude pro úlohu vyžadována mezipaměť Flash v cloudovém řešení IaaS.
- Porovnejte celkový počet bajtů fyzického čtení a zápisu s celkovým součtem provedeným v mezipaměti. Je možné zvýšit paměť, aby se eliminovaly požadavky na fyzické čtení (je běžné, že někteří zmenšují SGA, aby vynutili odsazení zátěže pro Exadata)?
- Ve statistikách systému určete, na jaké objekty má vliv jaká statistika. Pokud je cílem ladění SQL, pak další indexování, dělení nebo jiné fyzické ladění může zátěž výrazně optimalizovat.
- Zkontrolujte parametry inicializace kvůli podtržítkům (_) nebo zastaralým parametrům, které mohou vyžadovat odůvodnění kvůli jejich vlivu na výkon databáze.
Konfigurace serveru Exadata
Ve verzi Oracle 12.2 a novějších bude v globální sestavě AWR zahrnuto specifické rozšíření pro Exadata. Tato sestava obsahuje oddíly, které poskytují výjimečnou hodnotu migrace z Exadata.
Podrobnosti o verzi Exadata a systému
Podrobnosti upozornění uzlu buňky
Neonline disky Exadata
Odlehlé hodnoty pro libovolné statistiky operačního systému Exadata
Žlutá/růžová: Obavy. Exadata neběží optimálně.
Červená: Výkon Exadata je výrazně ovlivněný.
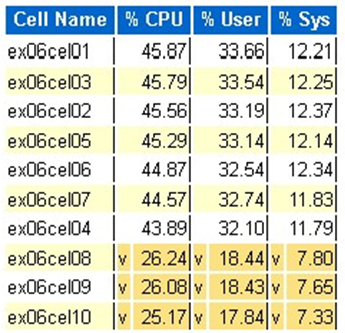
Statistika procesoru operačního systému Exadata: horní buňky
- Tyto statistiky shromažďují operační systém v buňkách a nejsou omezeny na tuto databázi nebo instance.
-
va tmavě žluté pozadí značí odlehlou hodnotu pod nízkým rozsahem. -
^a světle žluté pozadí označují odlehlou hodnotu nad horní hranicí. - Nejvyšší buňky podle procenta využití CPU jsou zobrazeny a jsou v sestupném pořadí podle využití CPU.
- Průměr: 39,34% CPU, 28,57% uživatel, 10,77% sys
Čtení fyzického bloku jedné buňky
Využití mezipaměti Flash
Dočasné I/O
Efektivita sloupcové mezipaměti
Hlavní databáze podle propustnosti vstupně-výstupních operací
I když je možné provést posouzení velikosti, existují některé otázky týkající se průměrů a simulovaných špiček, které jsou integrované do těchto hodnot pro velké úlohy. Tato část, která se nachází na konci sestavy AWR, je mimořádně cenná, protože ukazuje jak průměrné využití flash paměti, tak disku u 10 nejvýkonnějších databází na Exadatě. Přestože mnozí mohou předpokládat, že chtějí přizpůsobit velikost databází pro maximální výkon v cloudu, pro většinu nasazení to nedává smysl (více než 95% je v průměrném rozsahu; s vypočítanou simulovanou špičkou může být průměrný rozsah větší než 98%). Je důležité platit za to, co je potřeba, a to i pro nejvyšší zatížení z Oracle, a zkoumání nejlepších databází podle prostupnosti IO operací může objasnit potřeby prostředků pro databázi.
Správná velikost Oracle pomocí AWR v Exadata
Při plánování kapacity pro místní systémy je přirozené mít do hardwaru integrovanou významnou režii. V následujících letech musí naddimenzovaný hardware sloužit pracovní zátěži Oracle, bez ohledu na přidání zátěže v důsledku růstu dat, změn kódu nebo aktualizací.
Jednou z výhod cloudu je možnost škálování prostředků na hostiteli virtuálního počítače a v úložišti, které lze provést při rostoucích požadavcích. To pomáhá šetřit náklady na cloud a licenční náklady, které jsou připojené k využití procesoru (relevantní pro Oracle).
Nastavení správné velikosti zahrnuje odebrání hardwaru z tradiční migrace metodou "lift and shift" a použití informací o úlohách poskytovaných úložištěm automatických úloh společnosti Oracle (AWR) k zvednutí a přesunutí úlohy do výpočetních prostředků a úložiště, které je speciálně navržené tak, aby ji podporovalo v cloudu podle výběru zákazníka. Proces správné velikosti zajišťuje, že architektura v budoucnu odebere technický dluh infrastruktury, redundanci architektury, ke které dojde, pokud by se duplikace místního systému replikovala do cloudu a implementuje cloudové služby, kdykoli je to možné.
Odborníci na danou problematiku ze společností Microsoft a Oracle odhadli, že více než 80% databází Oracle je nadměrně přidělováno a že dosáhnou stejných nákladů nebo úspor při přechodu do cloudu, pokud si před migrací do cloudu udělají čas na úpravu velikosti zátěže databází Oracle. Toto posouzení vyžaduje, aby odborníci na databáze v týmu přesunuli svůj názor na to, jak mohli v minulosti provádět plánování kapacity, ale stojí za investice zúčastněných stran do cloudu a cloudové strategie firmy.
Další kroky
- Spouštění nejnáročnějších úloh Oracle v Azure bez snížení výkonu nebo škálovatelnosti
- Architektury řešení využívající Azure NetApp Files – Oracle
- Návrh a implementace databáze Oracle v Azure
- Nástroj pro odhad velikosti úloh Oracle na virtuální počítače Azure IaaS
- Referenční architektury pro Oracle Database Enterprise Edition v Azure
- Pochopte skupiny svazků aplikací Azure NetApp Files pro SAP HANA