Principy jazyků svazků ve službě Azure NetApp Files
Jazyk svazku (podobně jako systémové národní prostředí v klientských operačních systémech) na svazku Azure NetApp Files řídí podporované jazyky a znakové sady při použití protokolů NFS a SMB. Azure NetApp Files používá výchozí jazyk svazku C.UTF-8, který poskytuje kódování UTF-8 kompatibilní s POSIX pro znakové sady. Jazyk C.UTF-8 nativně podporuje znaky s velikostí 0–3 bajtů, což zahrnuje většinu světových jazyků na základní vícejazyčné rovině (BMP) (včetně japonštiny, němčiny a většiny hebrejštiny a cyrilice). Další informace o BMP naleznete v kódu Unicode.
Znaky mimo BMP někdy překračují velikost 3 bajtů podporovanou službou Azure NetApp Files. Proto musí použít logiku náhradní dvojice, kdy se k vytvoření nových znaků zkombinují více znakových sad. Symboly emoji, například spadají do této kategorie a jsou podporovány ve službě Azure NetApp Files ve scénářích, kdy se nevynucuje UTF-8: například klienti Windows, kteří používají kódování UTF-16 nebo NFSv3, které nevynucují UTF-8. NFSv4.x vynucuje UTF-8, což znamená, že náhradní párové znaky se při použití NFSv4.x nezobrazují správně.
Nestandardní kódování, například Shift-JIS a méně běžné znaky CJK, se také nezobrazují správně při vynucení UTF-8 v Azure NetApp Files.
Tip
Text byste měli odesílat a přijímat pomocí UTF-8, abyste se vyhnuli situacím, kdy se znaky nedají správně přeložit, což může způsobit chybové scénáře vytvoření nebo přejmenování souboru nebo kopírování.
V Azure NetApp Files se v současné době nastavení jazyka svazku nedá změnit. Další informace naleznete v tématu Chování protokolu se speciálními znakovými sadami.
Osvědčené postupy najdete v tématu Osvědčené postupy znakové sady.
Kódování znaků ve svazcích NFS a SMB ve službě Azure NetApp Files
V prostředí pro sdílení souborů Azure NetApp Files jsou názvy souborů a složek reprezentovány řadou znaků, které koncoví uživatelé čtou a interpretují. Způsob zobrazení těchto znaků závisí na tom, jak klient odesílá a přijímá kódování těchto znaků. Pokud například klient odesílá starší kódování ASCII (American Standard Code for Information Interchange) do svazku Azure NetApp Files při přístupu, je omezený na zobrazení pouze znaků podporovaných ve formátu ASCII.
Například japonský znak pro data je 資. Vzhledem k tomu, že tento znak nelze reprezentovat v ASCII, klient používající kódování ASCII zobrazí znak "?" místo 資.
ASCII podporuje pouze 95 tisknutelných znaků, hlavně těch, které se nacházejí v anglickém jazyce. Každý z těchto znaků používá 1 bajt, který je faktorem celkové délky cesty k souboru na svazku Azure NetApp Files. Tím se omezí internacionalizace datových sad, protože názvy souborů můžou mít různé znaky, které ASCII nerozpozná, od japonštiny po cyrilici až po emoji. Mezinárodní standard (ISO/IEC 8859) se pokusil podporovat více mezinárodních znaků, ale měl také svá omezení. Většina moderních klientů odesílá a přijímá znaky pomocí nějaké formy Unicode.
Unicode
V důsledku omezení kódování ASCII a ISO/IEC 8859 byl zaveden standard Unicode, aby si každý mohl zobrazit jazyk domovské oblasti ze svých zařízení.
- Unicode podporuje více než milion znakových sad zvýšením počtu bajtů na jeden znak povolených (až 4 bajty) a celkovým počtem bajtů povolených v cestě k souboru na rozdíl od starších kódování, jako je ASCII.
- Unicode podporuje zpětnou kompatibilitu tím, že pro ASCII zarezervuje prvních 128 znaků a zároveň zajišťuje, aby prvních 256 bodů kódu bylo stejné jako standard ISO/IEC 8859.
- Ve standardu Unicode jsou znakové sady rozdělené do rovin. Rovina je souvislá skupina 65 536 bodů kódu. Celkem je ve standardu Unicode 17 rovin (0–16). Limit je 17 kvůli omezením UTF-16.
- Rovina 0 je základní vícejazyčná rovina (BMP). Tato rovina obsahuje nejčastěji používané znaky ve více jazycích.
- Z 17 rovin, pouze pět aktuálně přiřazených znakových sad jako Unicode verze 15.1.
- Roviny 1-17 se označují jako doplňkové vícejazyčné roviny (SMP) a obsahují méně používané znakové sady, například staré systémy psaní, jako jsou cuneiform a hieroglyphs, a také speciální čínské/japonské/korejské znaky (CJK).
- Metody pro zobrazení délky znaků a velikostí cest a řízení kódování odesílaných do systému naleznete v tématu Převod souborů na jiné kódování.
Unicode Transformační formát unicode používá jako svůj standard, přičemž UTF-8 a UTF-16 jsou dva hlavní formáty.
Roviny Unicode
Unicode využívá 17 rovin o 65 536 znacích (256 bodů kódu vynásobených 256 polí v rovině) s rovinou 0 jako základní vícejazyčnou rovinou (BMP). Tato rovina obsahuje nejčastěji používané znaky ve více jazycích. Vzhledem k tomu, že jazyky a znakové sady světa překračují 65536 znaků, je k podpoře méně běžně používaných znakových sad potřeba více rovin.
Například rovina 1 ( doplňkové vícejazyčné roviny (SMP)) zahrnuje historické skripty, jako jsou cuneiform a egyptský hieroglyfy a některé Osage, Warang Citi, Adlam, Wancho a Toto. Rovina 1 obsahuje také některé symboly a emotikony .
Rovina 2 – doplňkový ideografický rovina (SIP) – obsahuje čínské/japonské/korejské (CJK) sjednocené ideografii. Znaky v rovině 1 a 2 jsou obecně 4 bajty velikosti.
Příklad:
- "Grinning face with big eyes" emotikony "😃" v letadle 1 je 4 bajty ve velikosti.
- Egyptský hieroglyf "𓀀" v letadle 1 je velikost 4 bajty.
- Znak Osage "𐒸" v rovině 1 má velikost 4 bajty.
- Znak CJK "𫝁" v rovině 2 má velikost 4 bajty.
Vzhledem k tomu, že všechny tyto znaky mají >velikost 3 bajty, vyžadují správné fungování náhradních dvojic. Azure NetApp Files nativně podporuje náhradní páry, ale zobrazení znaků se liší v závislosti na používaném protokolu, nastavení národního prostředí klienta a nastavení vzdálené aplikace pro klientský přístup.
UTF-8
UTF-8 používá 8bitové kódování a může mít až 1 112 064 bodů kódu (nebo znaků). UTF-8 je standardní kódování ve všech jazycích v operačních systémech s Linuxem. Vzhledem k tomu, že UTF-8 používá 8bitové kódování, je maximální možné celé číslo bez znaménka 255 (2^8 – 1), což je také maximální délka názvu souboru pro toto kódování. UTF-8 se používá na více než 98 % stránek na internetu, takže je zdaleka nejschvalovanější kódovací normou. Pracovní skupina WEB Hypertext Application Technology Working Group (WHATWG) považuje UTF-8 za povinné kódování pro všechny [text] a z bezpečnostních důvodů by aplikace prohlížeče neměly používat UTF-16.
Znaky ve formátu UTF-8 používají 1 až 4 bajty, ale téměř všechny znaky ve všech jazycích používají 1 až 3 bajty. Například:
- Písmeno latinky "A" používá 1 bajt. (Jeden z 128 vyhrazených znaků ASCII)
- Symbol autorských práv "©" používá 2 bajty.
- Znak "ä" používá 2 bajty. (1 bajt pro "a" + 1 bajt pro umlaut)
- Japonský symbol Kanji pro data (資) používá 3 bajty.
- Emoji s grinningem tváře (😃) používá 4 bajty.
Národní prostředí jazyka můžou používat buď standardní formát UTF-8 (C.UTF-8), nebo formát specifický pro konkrétní oblast, například en_US. UTF-8, ja. UTF-8 atd. Kódování UTF-8 byste měli použít pro linuxové klienty při přístupu ke službě Azure NetApp Files, kdykoli je to možné. Od OS X klienti macOS také používají pro výchozí kódování UTF-8 a neměli by být upraveni.
Klienti Windows používají UTF-16. Ve většině případů by toto nastavení mělo zůstat ve výchozím nastavení pro národní prostředí operačního systému, ale novější klienti nabízejí podporu beta pro znaky UTF-8 pomocí zaškrtávacího políčka. Termináloví klienti ve Windows je také možné podle potřeby upravit tak, aby používali UTF-8 v PowerShellu nebo CMD. Další informace naleznete v tématu Chování duálního protokolu se speciálními znakovými sadami.
UTF-16
UTF-16 používá 16bitové kódování a je schopen kódování všech 1 112 064 bodů kódu Unicode. Kódování pro UTF-16 může použít jednu nebo dvě 16bitové jednotky kódu, každý 2 bajty ve velikosti. Všechny znaky v UTF-16 používají velikost 2 nebo 4 bajtů. Znaky v UTF-16, které používají 4 bajty, využívají náhradní dvojice, které kombinují dva samostatné dvoubajtové znaky k vytvoření nového znaku. Tyto doplňkové znaky spadají mimo standardní rovinu BMP a do jedné z dalších vícejazyčných rovin.
UTF-16 se používá v operačních systémech Windows a rozhraníCH API, Javě a JavaScriptu. Vzhledem k tomu, že nepodporuje zpětnou kompatibilitu s formáty ASCII, nikdy nezískála popularitu na webu. UTF-16 tvoří pouze přibližně 0,002 % všech stránek na internetu. Pracovní skupina WHATWG (Web Hypertext Application Technology Working Group) považuje UTF-8 za povinné kódování pro veškerý text a doporučuje, aby aplikace pro zabezpečení prohlížeče nepoužíly UTF-16.
Azure NetApp Files podporuje většinu znaků UTF-16 včetně náhradních párů. V případech, kdy není znak podporovaný, hlásí klienti Windows chybu "Název souboru, který jste zadali, není platný nebo příliš dlouhý".
Zpracování znakové sady přes vzdálené klienty
Vzdálená připojení k klientům, kteří připojují svazky Azure NetApp Files (například připojení SSH k klientům s Linuxem pro přístup k připojením NFS), je možné nakonfigurovat tak, aby odesílala a přijímala konkrétní kódování jazyka svazků. Kódování jazyka odeslané klientovi prostřednictvím nástroje pro vzdálené připojení řídí způsob vytváření a zobrazování znakových sad. V důsledku toho může vzdálené připojení, které používá jiné kódování jazyka než jiné vzdálené připojení (například dvě různá okna PuTTY), zobrazovat různé výsledky pro znaky při výpisu názvů souborů a složek ve svazku Azure NetApp Files. Vevětšiněch
Například použití kódování UTF-8 pro vzdálené připojení ukazuje předvídatelné výsledky pro znaky ve svazcích Azure NetApp Files, protože C.UTF-8 je jazyk svazku. Japonský znak pro "data" (資) se v závislosti na kódování odesílané terminálem zobrazuje jinak.
Kódování znaků v PuTTY
Pokud okno PuTTY používá UTF-8 (nachází se v nastavení překladu Windows), znak je správně reprezentován pro připojený svazek NFSv3 v Azure NetApp Files:

Pokud okno PuTTY používá jiné kódování, například ISO-8859-1:1998 (Latin-1, Západní Evropa), zobrazí se stejný znak jinak, i když je název souboru stejný.

PuTTY ve výchozím nastavení neobsahuje kódování CJK. K dispozici jsou opravy pro přidání těchto jazykových sad do PuTTY.
Kódování znaků v Bastionu
Microsoft Azure doporučuje používat Bastion pro vzdálené připojení k virtuálním počítačům v Azure. Při použití Bastionu se kódování jazyka odesílané a přijaté v konfiguraci nezpřístupní, ale využívá standardní kódování UTF-8. Výsledkem je, že většina znakových sad zobrazených v PuTTY pomocí UTF-8 by měla být viditelná také v Bastionu za předpokladu, že se v používaném protokolu podporují znakové sady.

Tip
Další terminály SSH lze použít, jako je TeraTerm. TeraTerm ve výchozím nastavení poskytuje širší škálu podporovaných znakových sad, včetně kódování CJK a nestandardních kódování, jako je Shift-JIS.
Chování protokolu se speciálními znakovými sadami
Svazky Azure NetApp Files používají kódování UTF-8 a nativně podporují znaky, které nepřekračují 3 bajty. Všechny znaky v sadě ASCII a UTF-8 se zobrazují správně, protože spadají do rozsahu 1 až 3 bajty. Příklad:
- Znak latinky "A" používá 1 bajt (jeden z 128 vyhrazených znaků ASCII).
- Symbol © autorských práv používá 2 bajty.
- Znak "ä" používá 2 bajty (1 bajt pro "a" a 1 bajt pro umlaut).
- Japonský symbol Kanji pro data (資) používá 3 bajty.
Azure NetApp Files podporuje také některé znaky, které přes logiku náhradního páru (například emoji) překračují 3 bajty, za předpokladu, že je podporuje kódování klienta a verze protokolu. Další informace o chování protokolu najdete v tématech:
Chování protokolu SMB
Ve svazcích SMB azure NetApp Files vytváří a udržuje dva názvy souborů nebo adresářů v libovolném adresáři, který má přístup z klienta SMB: původní dlouhý název a název ve formátu 8.3.
Názvy souborů v PROTOKOLU SMB s Azure NetApp Files
Pokud názvy souborů nebo adresářů překračují povolené bajty znaků nebo používají nepodporované znaky, Služba Azure NetApp Files vygeneruje název formátu 8.3 následujícím způsobem:
- Zkrátí původní název souboru nebo adresáře.
- Připojí vlnovku (~) a číslici (1–5) k názvům souborů nebo adresářů, které už nejsou po zkrácení jedinečné. Pokud existuje více než pět souborů s neunique názvy, Azure NetApp Files vytvoří jedinečný název bez vztahu k původnímu názvu. U souborů Azure NetApp Files zkrátí příponu názvu souboru na tři znaky.
Pokud například klient NFS vytvoří soubor s názvem specifications.html, Azure NetApp Files vytvoří název specif~1.htm souboru za formátem 8.3. Pokud tento název již existuje, Azure NetApp Files použije na konci názvu souboru jiné číslo. Pokud například klient systému souborů NFS vytvoří jiný soubor s názvem specifications\_new.html, formát specifications\_new.html 8.3 je specif~2.htm.
Speciální znak v SMB s Azure NetApp Files
Při použití protokolu SMB se svazky Azure NetApp Files jsou kvůli podpoře náhradních párů povolené znaky, které překračují 3 bajty používané v názvech souborů a složek (včetně emotikon). Následuje, co Průzkumník Windows vidí znaky mimo BMP ve složce vytvořené z klienta Systému Windows při použití angličtiny s výchozím kódováním UTF-16.
Poznámka:
Výchozí písmo v Průzkumníku Windows je Segoe UI. Změny písma můžou ovlivnit zobrazení některých znaků v klientech.

Způsob zobrazení znaků v klientovi závisí na systémovém písmu a nastavení jazyka a národního prostředí. Obecně platí, že znaky, které spadají do BMP, jsou podporovány napříč všemi protokoly bez ohledu na to, jestli je kódování UTF-8 nebo UTF-16.
Při použití cmd nebo PowerShellu může zobrazení znakové sady záviset na nastavení písma. Tyto nástroje mají ve výchozím nastavení omezené možnosti písma. CmD jako výchozí písmo používá Consolas.
Názvy souborů se nemusí zobrazovat podle očekávání, protože některé konzoly nativně nepodporují uživatelské rozhraní Segoe ani jiná písma, která vykreslují speciální znaky správně.
Tento problém je možné vyřešit u klientů s Windows pomocí prostředí PowerShell ISE, který poskytuje robustnější podporu písem. Například nastavení ise PowerShellu na Segoe UI zobrazí názvy souborů s podporovanými znaky správně.

Prostředí PowerShell ISE je ale určené pro skriptování místo správy sdílených složek. Novější verze Windows nabízejí Terminál Windows, což umožňuje kontrolu nad písmy a kódovacími hodnotami.
Poznámka:
chcp Pomocí příkazu zobrazte kódování terminálu. Úplný seznam znakových stránek najdete v tématu Identifikátory znakové stránky.

Pokud je svazek povolený pro duální protokol (NFS i SMB), můžete sledovat různá chování. Další informace naleznete v tématu Chování duálního protokolu se speciálními znakovými sadami.
Chování systému souborů NFS
Způsob, jakým systém souborů NFS zobrazuje speciální znaky, závisí na používané verzi systému souborů NFS, nastavení národního prostředí klienta, nainstalovaná písma a nastavení používaného klienta vzdáleného připojení. Například použití Bastionu pro přístup ke klientovi Ubuntu může zpracovávat zobrazení znaků jinak než klient PuTTY nastavený na jiné národní prostředí na stejném virtuálním počítači. Následující příklady systému souborů NFS závisí na těchto nastaveních národního prostředí pro virtuální počítač s Ubuntu:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Chování NFSv3
NFSv3 nevynucuje kódování UTF u souborů a složek. Ve většině případů by speciální znakové sady neměly mít žádné problémy. Použitý klient připojení ale může ovlivnit, jak se znaky odesílají a přijímají. Například použití znaků Unicode mimo BMP pro název složky v klientovi připojení Azure Bastion může vést k neočekávanému chování kvůli fungování kódování klienta.
Na následujícím snímku obrazovky Bastion nemůže zkopírovat a vložit hodnoty do výzvy rozhraní příkazového řádku mimo prohlížeč při pojmenování adresáře přes NFSv3. Při pokusu o zkopírování a vložení hodnoty NFSv3Bastion𓀀𫝁😃𐒸, speciální znaky se ve vstupu zobrazí jako uvozovky.

Příkaz copy-paste je povolený přes NFSv3, ale znaky se vytvoří jako jejich číselné hodnoty, které ovlivňují jejich zobrazení:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Toto zobrazení je způsobeno kódováním, které Bastion používá k odesílání textových hodnot při kopírování a vkládání.
Při použití PuTTY k vytvoření složky se stejnými znaky přes NFSv3, název složky než jiný v Bastionu, než kdy byl Bastion použit k jeho vytvoření. Emotikona se zobrazí podle očekávání (vzhledem k nainstalovanému nastavení písem a národního prostředí), ale ostatní znaky (například Osage "𐒸") ne.

V okně PuTTY se znaky zobrazují správně:

Chování NFSv4.x
NFSv4.x vynucuje kódování UTF-8 v názvech souborů a složek podle specifikace internationalizace RFC-8881.
V důsledku toho, pokud je odeslán speciální znak s jiným kódováním než UTF-8, NFSv4.x nemusí tuto hodnotu povolit.
V některých případech může být příkaz povolen pomocí znaku mimo základní vícejazyčnou rovinu (BMP), ale po vytvoření nemusí zobrazit hodnotu.
Například vydání mkdir s názvem složky včetně znaků "𓀀𫝁😃𐒸" (znaky v doplňkových vícejazyčných rovinách (SMP) a doplňkové ideografické roviny (SIP)) se zdá být úspěšné v NFSv4.x. Složka se při spuštění ls příkazu nezobrazí.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Složka existuje ve svazku. Změna na tento skrytý název adresáře funguje v klientovi PuTTY a v rámci tohoto adresáře je možné vytvořit soubor.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Příkaz statistiky z PuTTY také potvrzuje, že složka existuje:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
I když je složka potvrzena, příkazy se zástupnými znaky nefungují, protože klient nemůže oficiálně "zobrazit" složku v zobrazení.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 odešle klientovi chybu, když narazí na znak, který nespoléhá na kódování UTF-8.
Například při použití Bastionu k pokusu o přístup ke stejnému adresáři, který jsme vytvořili pomocí PuTTY přes NFSv4.1, je to výsledek:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL se vztahuje na RFC-8881.
Vzhledem k tomu, že ke složce je možné přistupovat z PuTTY (kvůli odesílanému a přijatému kódování), je možné ji zkopírovat, pokud je zadaný název. Po zkopírování této složky ze svazku Azure NetApp Files NFSv4.1 do svazku Azure NetApp Files NFSv3 se zobrazí název složky:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Stejnou NFS4ERR\_INVAL chybu můžete vidět, pokud se pokusíte převést soubor (pomocí ikonyv) do jiného formátu než UTF-8, například Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Další informace naleznete v tématu Převod souborů na jiné kódování.
Chování duálního protokolu
Azure NetApp Files umožňuje přístup ke svazkům NFS i SMB prostřednictvím přístupu pomocí duálního protokolu. Vzhledem k obrovským rozdílům v kódování jazyka používaném systémem SOUBORŮ NFS (UTF-8) a SMB (UTF-16) můžou mít znakové sady, názvy souborů a složek a délky cest velmi odlišné chování napříč protokoly.
Zobrazení souborů a složek vytvořených systémem souborů NFS z protokolu SMB
Pokud se služba Azure NetApp Files používá pro přístup k protokolům SMB a NFS, může být znaková sada nepodporovaná UTF-16 použita v názvu souboru vytvořeném pomocí UTF-8 přes SYSTÉM SOUBORŮ NFS. Pokud v těchto scénářích smb přistupuje k souboru s nepodporovanými znaky, název se v protokolu SMB zkrátí pomocí konvence krátkých názvů souborů 8.3.
Soubory vytvořené NFSv3 a chování protokolu SMB se znakovými sadami
NFSv3 nevynucuje kódování UTF-8. Znaky používající nestandardní kódování jazyka (například Shift-JIS) fungují se službou Azure NetApp Files při použití NFSv3.
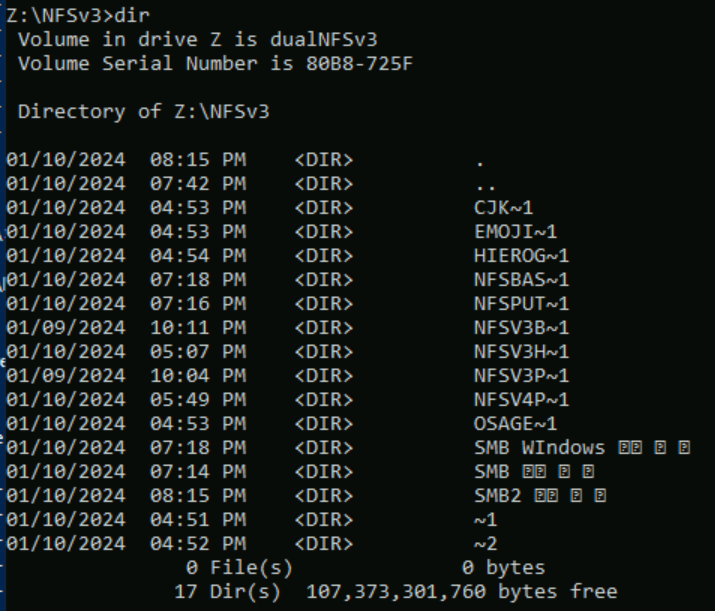
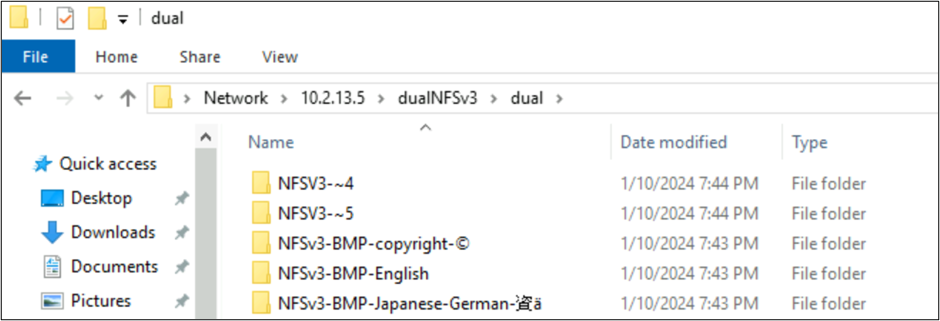
V následujícím příkladu se ve svazku Azure NetApp Files pomocí NFSv3 vytvořila řada názvů složek používajících různé znakové sady z různých rovin v kódování Unicode. Při zobrazení z NFSv3 se zobrazí správně.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Ve Windows SMB se složky se znaky nalezenými v BMP zobrazují správně, ale znaky mimo danou rovinu se zobrazují s formátem názvu 8.3 kvůli převodu UTF-8/UTF-16 nekompatibilní pro tyto znaky.
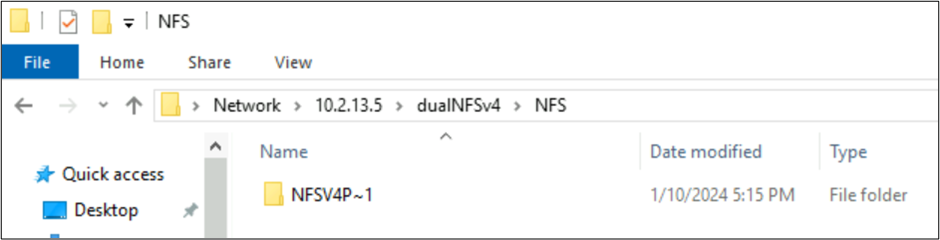
Soubory vytvořené NFSv4.1 a chování protokolu SMB se znakovými sadami
V předchozích příkladech se vytvořila složka s názvem NFSv4 Putty 𓀀𫝁😃𐒸 na svazku Azure NetApp Files přes NFSv4.1, ale pomocí NFSv4.1 se nedá zobrazit. Můžete ho ale vidět pomocí protokolu SMB. Název je zkrácený v protokolu SMB na podporovaný formát 8.3 kvůli nepodporovaným znakovým sadám vytvořeným z klienta NFS a nekompatibilní převod UTF-8/UTF-16 pro znaky v různých rovině Unicode.
Pokud název složky používá standardní znaky UTF-8 nalezené v BMP (angličtina nebo jinak), pak SMB správně přeloží názvy.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
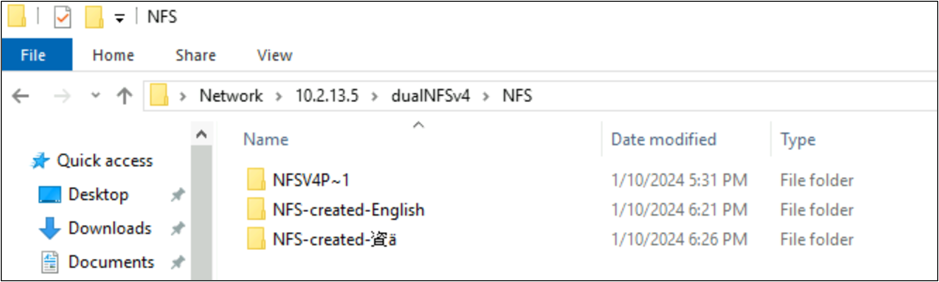
Soubory a složky vytvořené protokolem SMB přes systém souborů NFS
Klienti Windows jsou primárním typem klientů, kteří se používají pro přístup ke sdíleným složkám SMB. Tito klienti mají výchozí kódování UTF-16. V systému Windows je možné podporovat některé kódované znaky UTF-8 tím, že ho povolíte v nastavení oblasti:
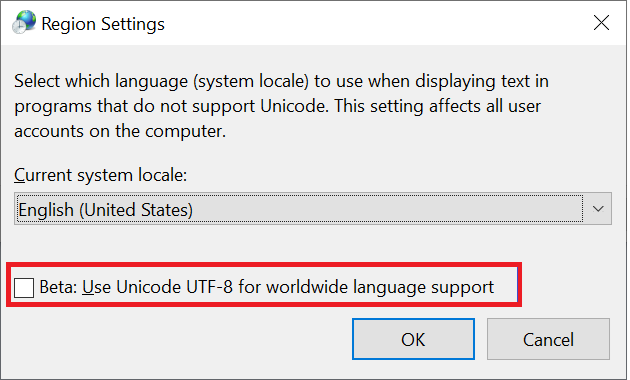
Při vytvoření souboru nebo složky přes sdílenou složku SMB ve službě Azure NetApp Files se znaková sada používá jako UTF-16. V důsledku toho klienti používající kódování UTF-8 (například klienti NFS se systémem Linux) nemusí být schopni správně přeložit některé znakové sady – zejména znaky, které spadají mimo základní vícejazyčnou rovinu (BMP).
Nepodporované chování znaků
Když klient NFS v těchto scénářích přistupuje k souboru vytvořenému pomocí protokolu SMB s nepodporovanými znaky, zobrazí se název jako řada číselných hodnot představujících hodnoty Unicode pro tento znak.
Například tato složka byla vytvořena v Průzkumníku Windows pomocí znaků mimo BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
Přes NFSv3 se zobrazí složka vytvořená protokolem SMB:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Přes NFSv4.1 se složka vytvořená protokolem SMB zobrazí takto:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Podporované chování znaků
Pokud jsou znaky v BMP, mezi protokoly SMB a NFS a jejich verzemi nejsou žádné problémy.
Například název složky vytvořené pomocí protokolu SMB na svazku Azure NetApp Files se znaky nalezenými v BMP v různých jazycích (angličtina, němčina, cyrilice, Runic) zobrazuje v pořádku ve všech protokolech a verzích.
- Základní latinka SMB
- Řečtina "ͶΘΩ"
- Cyrilice "ЄЊ"
- Runic "ᚠᚱᛯ"
- Ideografii kompatibility CJK "豈滑虜"
Takto se název zobrazí v protokolu SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Takto se název zobrazí z NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Takto se název zobrazí z NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Převod souborů na různá kódování
Názvy souborů a složek nejsou jedinými částmi objektů systému souborů, které využívají kódování jazyka. Obsah souboru (například speciální znaky v textovém souboru) může také hrát roli. Pokud se například soubor pokusíte uložit se speciálními znaky v nekompatibilním formátu, může se zobrazit chybová zpráva. V tomto případě nelze soubor s znaky Katagana uložit do ANSI, protože tyto znaky v tomto kódování neexistují.
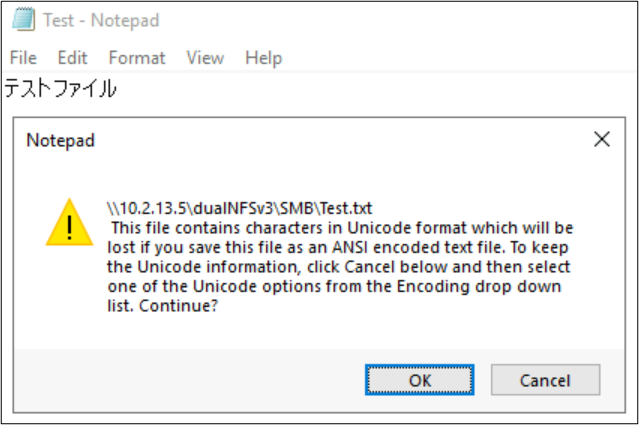
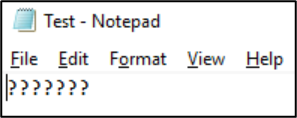
Po uložení souboru v daném formátu se znaky převedou na otazníky:
Kódování souborů je možné zobrazit z klientů NAS. V klientech Windows můžete k zobrazení kódování souboru použít aplikaci, jako je Poznámkový blok nebo Poznámkový blok++. Pokud jsou v klientovi nainstalované Subsystém Windows pro Linux (WSL) nebo Git, file můžete použít příkaz.
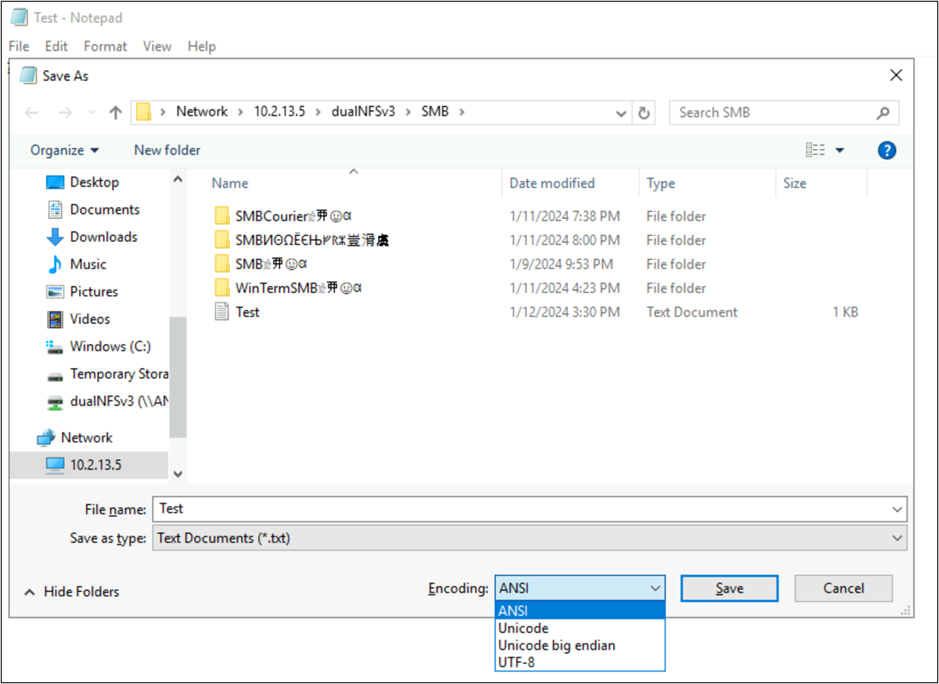
Tyto aplikace také umožňují změnit kódování souboru uložením jako různých typů kódování. Kromě toho se dá PowerShell použít k převodu kódování souborů pomocí rutin Get-Content a Set-Content rutin.
Například soubor utf8-text.txt je kódován jako UTF-8 a obsahuje znaky mimo BMP. Vzhledem k tomu, že se používá UTF-8, zobrazí se znaky správně.
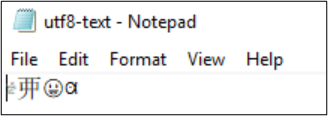
Pokud je kódování převedeno na UTF-32, znaky se nezobrazují správně.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
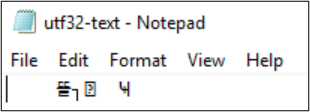
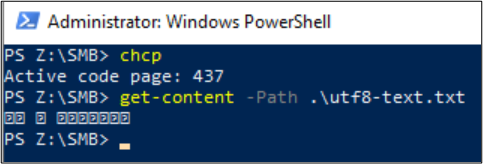
Get-Content lze také použít k zobrazení obsahu souboru. PowerShell ve výchozím nastavení používá kódování UTF-16 (znaková stránka 437) a výběry písma pro konzolu jsou omezené, takže formátovaný soubor UTF-8 se speciálními znaky nelze správně zobrazit:
Klienti Linuxu file můžou pomocí příkazu zobrazit kódování souboru. V prostředích se dvěma protokoly může v případě vytvoření souboru pomocí protokolu SMB zkontrolovat kódování souborů klient Linuxu, který používá systém souborů NFS.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Převod kódování souborů lze provést na klientech s Linuxem iconv pomocí příkazu. Seznam podporovaných formátů kódování zobrazíte pomocí iconv -lpříkazu .
Například kódovaný soubor UTF-8 lze převést na UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Pokud cílové kódování nepodporuje znakovou sadu názvu souboru nebo v obsahu souboru, převod není povolený. Například Shift-JIS nemůže podporovat znaky v obsahu souboru.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Pokud soubor obsahuje znaky podporované kódováním, převod bude úspěšný. Pokud například soubor obsahuje znaky Katagana テストファイル, převod Shift-JIS bude úspěšný přes systém souborů NFS. Vzhledem k tomu, že klient NFS používaný tady nerozumí shift-JIS kvůli nastavení národního prostředí, kódování ukazuje "neznámý-8bit".
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Vzhledem k tomu, že svazky Azure NetApp Files podporují pouze formátování kompatibilní s kódováním UTF-8, jsou znaky Katagana převedeny na nečitelný formát.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Při použití NFSv4.x je převod povolen, pokud jsou uvnitř obsahu souboru přítomny nekompatibilní znaky, i když NFSv4.x vynucuje kódování UTF-8. V tomto příkladu se v souboru s kódováním UTF-8 se znaky Katagana umístěné na svazku Azure NetApp Files správně zobrazí obsah souboru.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Po převodu se ale znaky v souboru zobrazují nesprávně kvůli nekompatibilnímu kódování.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Pokud název souboru obsahuje nepodporované znaky pro UTF-8, převod proběhne úspěšně přes NFSv3, ale převezme služby při selhání NFSv4.x kvůli vynucení UTF-8 verze protokolu.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Osvědčené postupy znakové sady
Při použití speciálních znaků nebo znaků mimo standardní svazek BMP (Basic Multilingual Plane) ve svazcích Azure NetApp Files byste měli vzít v úvahu některé osvědčené postupy.
- Vzhledem k tomu, že svazky Azure NetApp Files používají jazyk svazků UTF-8, mělo by kódování souborů pro klienty NFS také používat kódování UTF-8 pro konzistentní výsledky.
- Znakové sady v názvech souborů nebo obsažené v obsahu souboru by měly být kompatibilní s UTF-8 pro správné zobrazení a funkčnost.
- Vzhledem k tomu, že SMB používá kódování znaků UTF-16, nemusí se znaky mimo BMP správně zobrazovat přes systém souborů NFS ve svazcích se dvěma protokoly. Co je to možné, minimalizujte použití speciálních znaků v obsahu souboru.
- Nepoužívejte speciální znaky mimo BMP v názvech souborů, zejména při použití svazků se NFSv4.1 nebo svazky se dvěma protokoly.
- U znakových sad, které nejsou v BMP, by kódování UTF-8 mělo povolit zobrazení znaků v Azure NetApp Files při použití jednoho souborového protokolu (pouze SMB nebo pouze NFS). Svazky se dvěma protokoly ale ve většině případů tyto znakové sady nedokážou přizpůsobit.
- U svazků Azure NetApp Files se nepodporuje nestandardní kódování (například Shift-JIS).
- Na svazcích Azure NetApp Files se podporují náhradní znaky páru (například emoji).
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro