Konfigurace a správa pojmenovaných replik Hyperscale
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Tento článek obsahuje ukázky pro konfiguraci a správu pojmenované repliky hyperškálování služby Azure SQL Database.
Vytvoření pojmenované repliky Hyperscale
Následující ukázkové scénáře vás provedou vytvořením pojmenované repliky WideWorldImporters_NamedReplica pro databázi WideWorldImporterspomocí webu Azure Portal, T-SQL, PowerShellu nebo Azure CLI.
Následující příklad vytvoří pojmenovanou repliku WideWorldImporters_NamedReplica pro databázi WideWorldImporters pomocí T-SQL. Primární replika používá cíl na úrovni služby HS_Gen5_4, zatímco pojmenovaná replika používá HS_Gen5_2. Oba používají stejný logický server s názvem contosoeast.
Na webu Azure Portal přejděte do databáze, pro kterou chcete vytvořit pojmenovanou repliku.
Na stránce SQL Database vyberte databázi, přejděte do správy dat, vyberte Repliky a pak vyberte Vytvořit repliku.
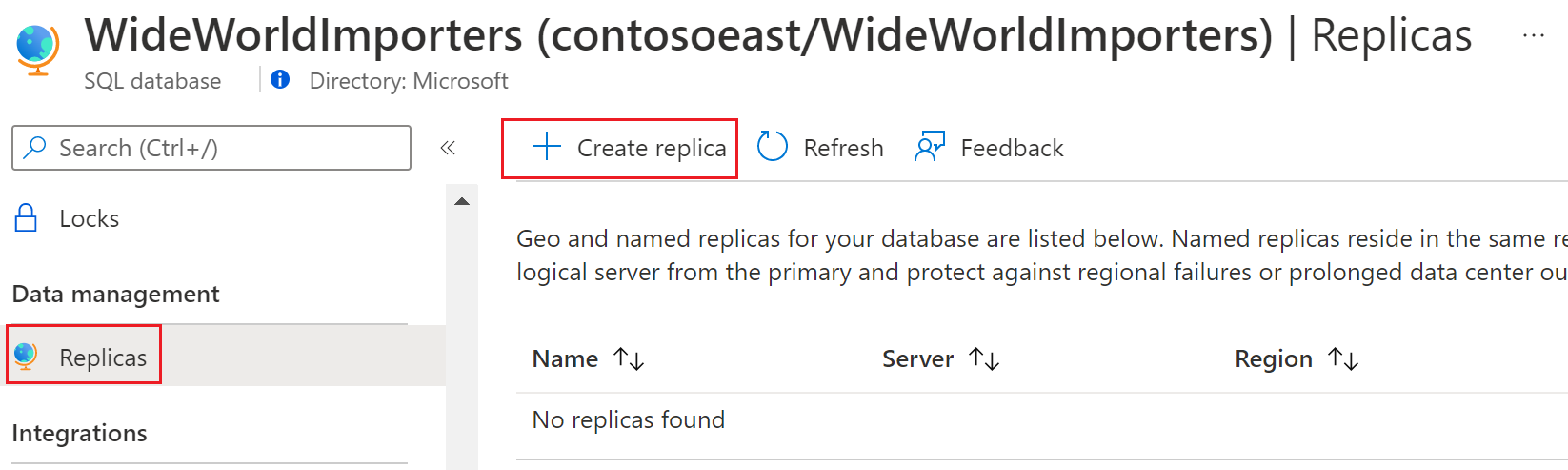
V části Konfigurace repliky zvolte pojmenovanou repliku. Vyberte existující server nebo vytvořte nový server pro pojmenovanou repliku. Zadejte název databáze pojmenované repliky a v případě potřeby nakonfigurujte možnosti compute a úložiště .

Volitelně můžete nakonfigurovat zónově redundantní hyperškálování pojmenované repliky. Další informace najdete v tématu Zónová redundance ve službě Azure SQL Database Hyperscale pojmenovaných replik.
- Na stránce Konfigurovat databázi vyberte možnost Ano , chcete tuto zónu databáze nastavit jako redundantní?
- Přidejte do konfigurace aspoň jednu sekundární repliku s vysokou dostupností.
- Vyberte Použít.
Vyberte Zkontrolovat a vytvořit, zkontrolujte informace a pak vyberte Vytvořit.
Zahájí se proces nasazení pojmenované repliky.
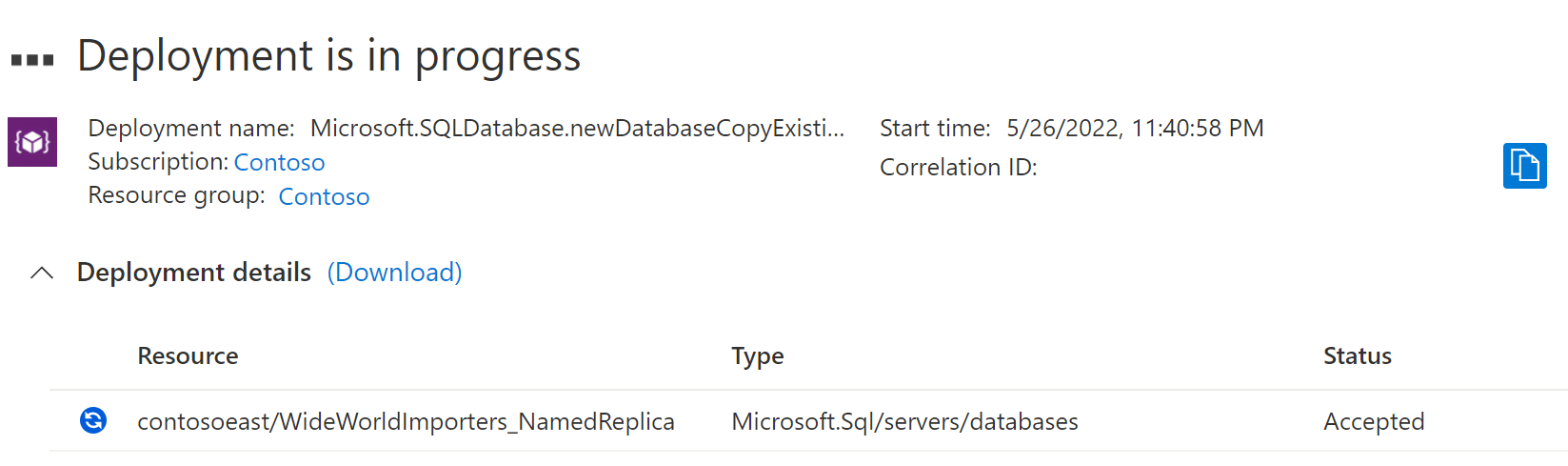
Po dokončení nasazení zobrazí pojmenovaná replika svůj stav.
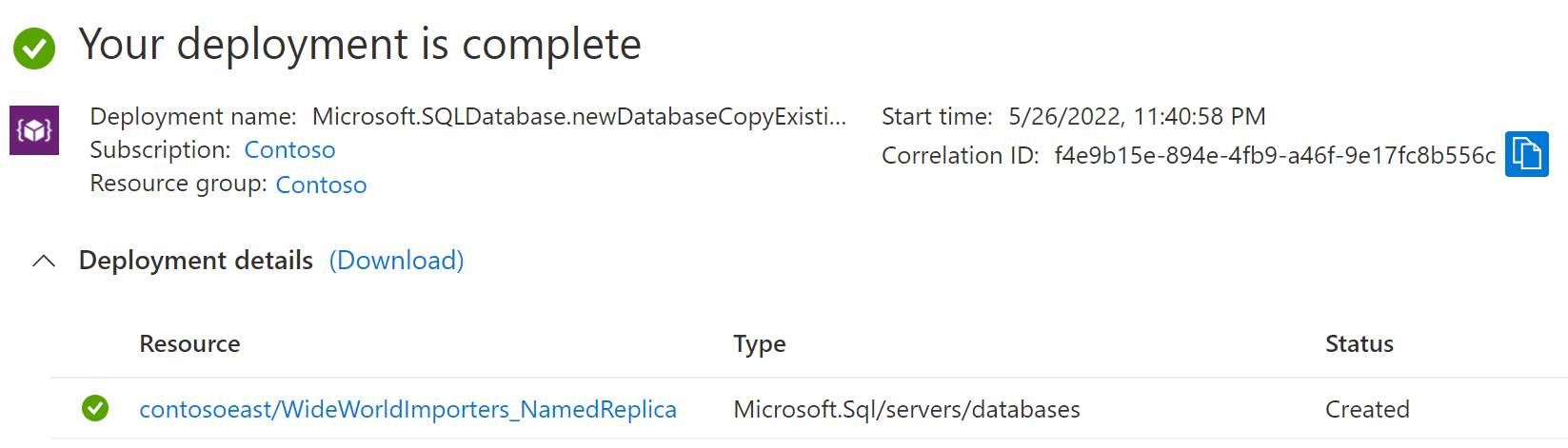
Vraťte se na stránku primární databáze a pak vyberte Repliky. Vaše pojmenovaná replika je uvedená v části Pojmenované repliky.






Vzhledem k tomu, že neexistuje žádný přesun dat, ve většině případů se vytvoří pojmenovaná replika přibližně za minutu. Jakmile je pojmenovaná replika dostupná, zobrazí se z webu Azure Portal nebo z libovolného nástroje příkazového řádku, jako je AZ CLI nebo PowerShell. Pojmenovaná replika je použitelná jako běžná databáze jen pro čtení.
Připojení k pojmenované replice Hyperscale
Pokud se chcete připojit k pojmenované replice Hyperscale, musíte pro tuto pojmenovanou repliku použít připojovací řetězec odkazující na jeho server a názvy databází. Není nutné zadávat možnost ApplicationIntent=ReadOnly , protože pojmenované repliky jsou vždy jen pro čtení.
Stejně jako u replik vysoké dostupnosti, i když primární, ha a pojmenované repliky sdílejí stejná data na stejné sadě stránkových serverů, jsou mezipaměti dat na každé pojmenované replice synchronizované s primárním serverem. Synchronizaci udržuje služba transakčního protokolu, která předává záznamy protokolu z primární na pojmenované repliky. V důsledku toho může aplikace záznamů protokolu probíhat v závislosti na zatížení zpracovávané pojmenovanou replikou v různých rychlostech, a proto můžou mít různé repliky odlišnou latenci dat vzhledem k primární replice.
Úprava pojmenované repliky hyperškálování
Cíl na úrovni služby pojmenované repliky můžete definovat při jeho vytváření pomocí ALTER DATABASE příkazu nebo jiným způsobem (portál, AZ CLI, PowerShell). Pokud po vytvoření pojmenované repliky potřebujete změnit cíl na úrovni služby, můžete to udělat pomocí ALTER DATABASE ... MODIFY příkazu na samotné pojmenované replice.
V následujícím příkladu WideWorldImporters_NamedReplica je pojmenovaná replika WideWorldImporters databáze.
Otevřete stránku databáze pojmenované repliky a pak vyberte Compute + Storage. Aktualizujte virtuální jádra.

Odebrání pojmenované repliky Hyperscale
Pokud chcete odebrat pojmenovanou repliku hyperškálování, vyřadíte ji stejně jako běžnou databázi.
Otevřete stránku databáze pojmenované repliky a zvolte Delete možnost.

Důležité
Pojmenované repliky se automaticky odeberou při odstranění primární repliky, ze které byly vytvořeny.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro