Monitorování výkonu služby Azure SQL Database pomocí zobrazení dynamické správy
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Zobrazení dynamické správy (DMV) můžete použít k monitorování výkonu úloh a diagnostice problémů s výkonem, které můžou být způsobené blokovanými nebo dlouhotrvajícími dotazy, kritickými body prostředků, neoptimálními plány dotazů a dalšími prostředky.
Tento článek obsahuje informace o tom, jak zjišťovat běžné problémy s výkonem dotazováním zobrazení dynamické správy prostřednictvím T-SQL. Můžete použít jakýkoli dotazovací nástroj, například:
Oprávnění
V Azure SQL Database v závislosti na velikosti výpočetních prostředků, možnosti nasazení a datech v zobrazení dynamické správy může dotazování dynamické správy vyžadovat buď VIEW DATABASE STATEnebo VIEW SERVER PERFORMANCE STATEnebo VIEW SERVER SECURITY STATE oprávnění. Poslední dvě oprávnění jsou součástí VIEW SERVER STATE oprávnění. Oprávnění k zobrazení stavu serveru jsou udělena prostřednictvím členství v odpovídajících rolích serveru. Pokud chcete zjistit, která oprávnění se vyžadují k dotazování na konkrétní zobrazení dynamické správy, projděte si zobrazení dynamické správy a vyhledejte článek popisující zobrazení dynamické správy.
Pokud chcete uživateli databáze udělit VIEW DATABASE STATE oprávnění, spusťte následující dotaz a nahraďte database_user ho názvem instančního objektu uživatele v databázi:
GRANT VIEW DATABASE STATE TO [database_user];
Pokud chcete udělit členství v ##MS_ServerStateReader## roli serveru pro přihlášení pojmenované login_name na logickém serveru, připojte se k master databázi a pak jako příklad spusťte následující dotaz:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Může trvat několik minut, než se udělení oprávnění projeví. Další informace najdete v tématu Omezení rolí na úrovni serveru.
Monitorování využití prostředků
Využití prostředků můžete monitorovat na úrovni databáze pomocí následujících zobrazení. Tato zobrazení platí pro samostatné databáze a databáze v elastickém fondu.
Využití prostředků můžete monitorovat na úrovni elastického fondu pomocí následujících zobrazení:
Využití prostředků můžete monitorovat na úrovni dotazu pomocí nástroje SQL Database Query Performance Insight na webu Azure Portal nebo prostřednictvím úložiště dotazů.
sys.dm_db_resource_stats
V každé databázi můžete použít zobrazení sys.dm_db_resource_stats . V zobrazení se sys.dm_db_resource_stats zobrazují nedávná data o využití prostředků vzhledem k limitům velikosti výpočetních prostředků. Procento využití procesoru, vstupně-výstupních operací dat, zápisů protokolů, pracovních vláken a využití paměti směrem k limitu se zaznamenávají pro každý 15sekundový interval a uchovávají se přibližně po dobu jedné hodiny.
Vzhledem k tomu, že toto zobrazení poskytuje podrobná data o využití prostředků, použijte sys.dm_db_resource_stats nejprve pro všechny analýzy aktuálního stavu nebo řešení potíží. Tento dotaz například ukazuje průměrné a maximální využití prostředků pro aktuální databázi za poslední hodinu:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Další dotazy najdete v příkladech v sys.dm_db_resource_stats.
sys.resource_stats
Zobrazení sys.resource_stats v master databázi obsahuje další informace, které vám pomůžou monitorovat výkon databáze na konkrétní úrovni služby a velikosti výpočetních prostředků. Data se shromažďují každých 5 minut a uchovávají se přibližně po dobu 14 dnů. Toto zobrazení je užitečné pro dlouhodobou historickou analýzu způsobu, jakým vaše databáze využívá prostředky.
Následující graf ukazuje využití prostředků procesoru pro databázi Premium s velikostí výpočetních prostředků P2 za každou hodinu v týdnu. Tento graf začíná v pondělí, zobrazuje pět pracovních dnů a pak zobrazuje víkend, kdy v aplikaci dochází mnohem méně.
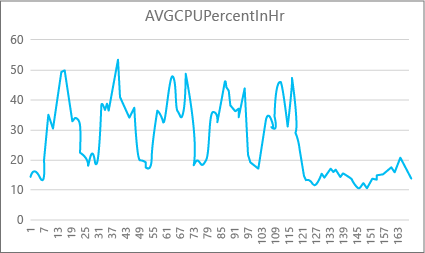
Z dat má tato databáze v současné době špičku zatížení procesoru s využitím procesoru přes 50 procent vzhledem k velikosti výpočetních prostředků P2 (v úterý v polovině dne). Pokud je procesor dominantním faktorem v profilu prostředků aplikace, můžete se rozhodnout, že P2 je správná velikost výpočetních prostředků, která zaručuje, že úloha bude vždy vyhovovat. Pokud očekáváte, že aplikace bude v průběhu času růst, je vhodné mít další vyrovnávací paměť prostředků, aby aplikace nikdy nedosáhla limitu na úrovni výkonu. Pokud zvětšíte velikost výpočetních prostředků, můžete se vyhnout chybám viditelným zákazníkům, ke kterým může dojít v případě, že databáze nemá dostatečný výkon pro efektivní zpracování požadavků, zejména v prostředích citlivých na latenci.
U jiných typů aplikací můžete stejný graf interpretovat odlišně. Pokud se například aplikace pokusí zpracovat data mzdy každý den a má stejný graf, tento typ modelu dávkové úlohy může být v pořádku s velikostí výpočetních prostředků P1. Výpočetní velikost P1 má ve srovnání s 200 DTU ve výpočetní velikosti P2 100 DTU. Velikost výpočetních prostředků P1 poskytuje polovinu výkonu výpočetní velikosti P2. Takže 50 % využití procesoru v P2 se rovná 100% využití procesoru v P1. Pokud aplikace nemá časové limity, nemusí být důležité, pokud dokončení úlohy trvá 2 hodiny nebo 2,5 hodiny, pokud se dokončí dnes. Aplikace v této kategorii pravděpodobně může použít velikost výpočetních prostředků P1. Můžete využít skutečnost, že během dne existují období, kdy je využití prostředků nižší, takže každý "velký vrchol" může později v den přetépat do jednoho z průseků. Velikost výpočetních prostředků P1 může být vhodná pro takový druh aplikace (a ušetřit peníze), pokud se úlohy můžou dokončit každý den.
Databázový stroj zveřejňuje informace o spotřebovaných prostředcích pro každou aktivní databázi v sys.resource_stats zobrazení master databáze na každém logickém serveru. Data v zobrazení se agregují podle 5minutových intervalů. Zobrazení těchto dat v tabulce může několik minut trvat, takže sys.resource_stats je užitečnější pro historickou analýzu místo analýzy téměř v reálném čase. Dotazem na sys.resource_stats zobrazení zobrazte nedávnou historii databáze a ověřte, jestli velikost výpočetních prostředků, kterou jste zvolili, v případě potřeby doručila požadovaný výkon.
Poznámka:
Abyste mohli dotazovat sys.resource_stats v následujících příkladech, musíte být připojení k master databázi.
Tento příklad ukazuje data v sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
Následující příklad ukazuje různé způsoby, jak můžete pomocí sys.resource_stats zobrazení katalogu získat informace o tom, jak vaše databáze používá prostředky:
Pokud se chcete podívat na použití prostředku za poslední týden pro uživatelskou databázi
userdb1, můžete tento dotaz spustit a nahradit vlastní název databáze:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Pokud chcete vyhodnotit, jak dobře vaše úloha odpovídá velikosti výpočetních prostředků, musíte přejít k podrobnostem jednotlivých aspektů metrik prostředků: procesor, vstupně-výstupní operace dat, zápis protokolu, počet pracovních procesů a počet relací. Tady je upravený dotaz, který používá
sys.resource_statsk hlášení průměrných a maximálních hodnot těchto metrik prostředků pro každou velikost výpočetních prostředků, pro kterou byla databáze zřízena:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Pomocí těchto informací o průměrných a maximálních hodnotách jednotlivých metrik prostředků můžete posoudit, jak dobře vaše úloha zapadá do vámi zvolené velikosti výpočetních prostředků. Obvykle průměrné hodnoty z
sys.resource_statsposkytují dobrý směrný plán pro použití s cílovou velikostí.Pro databáze nákupních modelů DTU:
Můžete například použít úroveň služby Standard s velikostí výpočetních prostředků S2. Průměrné procento využití pro čtení a zápisy procesoru a vstupně-výstupních operací je nižší než 40 procent, průměrný počet pracovních procesů je nižší než 50 a průměrný počet relací je nižší než 200. Vaše úloha se může vejít do velikosti výpočetních prostředků S1. Je snadné zjistit, jestli se vaše databáze vejde do limitů pracovních procesů a relací. Pokud chcete zjistit, jestli databáze zapadá do nižší velikosti výpočetních prostředků, vydělte číslo DTU nižší velikosti výpočetních prostředků číslem DTU vaší aktuální velikosti výpočetních prostředků a potom vynásobte výsledek číslem 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Výsledkem je relativní rozdíl výkonu mezi dvěma velikostmi výpočetních prostředků v procentech. Pokud využití prostředků toto procento nepřekračuje, může se vaše úloha vejít do nižší velikosti výpočetních prostředků. Musíte se ale podívat na všechny rozsahy hodnot využití prostředků a určit procento, jak často by se vaše úloha databáze vešla do nižší velikosti výpočetních prostředků. Následující dotaz vypíše procento přizpůsobení podle dimenze prostředku na základě prahové hodnoty 40 procent, které jsme vypočítali v tomto příkladu:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Na základě úrovně databázové služby se můžete rozhodnout, jestli vaše úloha zapadá do nižší velikosti výpočetních prostředků. Pokud je cíl úlohy databáze 99,9 % a předchozí dotaz vrátí hodnoty větší než 99,9 % pro všechny tři dimenze prostředků, vaše úloha pravděpodobně zapadá do nižší velikosti výpočetních prostředků.
Když se podíváte na procento přizpůsobení, získáte přehled o tom, jestli byste měli přejít na další vyšší velikost výpočetních prostředků, abyste splnili svůj cíl. Například využití procesoru pro ukázkovou databázi za poslední týden:
Průměrné procento procesoru Maximální procento procesoru 24.5 100.00 Průměrný procesor je přibližně čtvrtina limitu velikosti výpočetních prostředků, která by se dobře vešla do velikosti výpočetních prostředků databáze.
Pro nákupní model DTU a databáze nákupních modelů virtuálních jader:
Maximální hodnota ukazuje, že databáze dosáhne limitu velikosti výpočetních prostředků. Potřebujete přejít na další vyšší velikost výpočetních prostředků? Podívejte se, kolikrát vaše úloha dosáhne 100 procent, a pak ji porovnejte s cílem úlohy databáze.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Toto procento je počet ukázek, které vaše úloha odpovídá aktuální velikosti výpočetních prostředků. Pokud tento dotaz vrátí hodnotu menší než 99,9 % pro některou ze tří dimenzí prostředků, vaše vzorkovaná průměrná úloha překročila limity. Zvažte přechod na další vyšší velikost výpočetních prostředků nebo použijte techniky ladění aplikací, abyste snížili zatížení databáze.
sys.dm_elastic_pool_resource_stats
sys.dm_db_resource_statsPodobně jako sys.dm_elastic_pool_resource_stats poskytuje nedávná a podrobná data o využití prostředků pro elastický fond. Zobrazení se dá dotazovat v jakékoli databázi v elastickém fondu, aby poskytovalo data o využití prostředků pro celý fond, a ne v žádné konkrétní databázi. Procentuální hodnoty hlášené tímto zobrazením dynamické správy se vztahují k limitům elastického fondu, které můžou být vyšší než limity pro databázi ve fondu.
Tento příklad ukazuje souhrnná data o využití prostředků pro aktuální elastický fond za posledních 15 minut:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Pokud zjistíte, že jakékoli využití prostředků se v významném časovém období blíží 100 %, budete možná muset zkontrolovat využití prostředků pro jednotlivé databáze ve stejném elastickém fondu, abyste zjistili, kolik jednotlivých databází přispívá k využití prostředků na úrovni fondu.
sys.elastic_pool_resource_stats
sys.resource_statsPodobně jako sys.elastic_pool_resource_stats v master databázi poskytuje historická data o využití prostředků pro všechny elastické fondy na logickém serveru. Můžete použít sys.elastic_pool_resource_stats historické monitorování za posledních 14 dnů, včetně analýzy trendu využití.
Tento příklad ukazuje souhrnná data o využití prostředků za posledních 7 dnů pro všechny elastické fondy na aktuálním logickém serveru. Spusťte dotaz v master databázi.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Souběžné požadavky
Pokud chcete zobrazit aktuální počet souběžných požadavků, spusťte tento dotaz v uživatelské databázi:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Jedná se jen o snímek v jednom bodu v čase. Pokud chcete lépe porozumět požadavkům na úlohy a souběžné požadavky na požadavky, budete muset v průběhu času shromáždit mnoho vzorků.
Průměrná míra požadavků
Tento příklad ukazuje, jak zjistit průměrnou míru požadavků pro databázi nebo pro databáze v elastickém fondu za časové období. V tomto příkladu je časové období nastavené na 30 sekund. Můžete ho upravit úpravou WAITFOR DELAY příkazu. Spusťte tento dotaz v uživatelské databázi. Pokud je databáze v elastickém fondu a pokud máte dostatečná oprávnění, výsledky zahrnují další databáze v elastickém fondu.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Aktuální relace
Pokud chcete zobrazit počet aktuálních aktivních relací, spusťte tento dotaz na databázi:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Tento dotaz vrátí počet k určitému bodu v čase. Pokud v průběhu času shromáždíte více vzorků, budete mít nejlepší představu o využití relace.
Nedávná historie požadavků, relací a pracovních procesů
Tento příklad vrátí nedávné historické využití požadavků, relací a pracovních vláken pro databázi nebo pro databáze v elastickém fondu. Každý řádek představuje snímek využití prostředků v určitém okamžiku pro databázi. Sloupec requests_per_second je průměrná frekvence požadavků v časovém intervalu, který končí na snapshot_time. Pokud je databáze v elastickém fondu a pokud máte dostatečná oprávnění, výsledky zahrnují další databáze v elastickém fondu.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Výpočet velikosti databází a objektů
Následující dotaz vrátí velikost dat v databázi (v megabajtech):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Následující dotaz vrátí velikost jednotlivých objektů (v megabajtech) v databázi:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identifikace problémů s výkonem procesoru
Tato část vám pomůže identifikovat jednotlivé dotazy, které jsou hlavními příjemci procesoru.
Pokud je spotřeba procesoru delší dobu vyšší než 80 %, zvažte následující kroky řešení potíží, ať už k problému s procesorem dochází nebo k tomuto problému došlo v minulosti. Můžete také postupovat podle kroků v této části a proaktivně identifikovat dotazy s nejvyšším využitím procesoru a vyladit je. V některých případech vám snížení spotřeby procesoru umožní vertikálně snížit kapacitu databází a elastických fondů a ušetřit náklady.
Postup řešení potíží je stejný pro samostatné databáze a databáze v elastickém fondu. Spusťte všechny dotazy v uživatelské databázi.
K problému s procesorem dochází teď
Pokud k problému dochází právě teď, existují dva možné scénáře:
Mnoho jednotlivých dotazů, které kumulativní spotřebovávají vysoké využití procesoru
Pomocí následujícího dotazu identifikujte nejčastější dotazy podle hodnoty hash dotazu:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Dlouho trvající dotazy využívající procesor jsou stále spuštěné
Pomocí následujícího dotazu identifikujte tyto dotazy:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
K problému s procesorem došlo v minulosti.
Pokud k problému došlo v minulosti a chcete provést analýzu původní příčiny, použijte úložiště dotazů. Uživatelé s přístupem k databázi můžou dotazovat data úložiště dotazů pomocí T-SQL. Úložiště dotazů ve výchozím nastavení zachytává agregované statistiky dotazů pro jednohodinové intervaly.
Pomocí následujícího dotazu se podívejte na aktivitu pro dotazy s vysokým využitím procesoru. Tento dotaz vrátí prvních 15 dotazů využívajících procesor. Nezapomeňte změnit
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()časové období jiné než poslední dvě hodiny:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Jakmile identifikujete problematické dotazy, je čas tyto dotazy ladit, aby se snížilo využití procesoru. Případně můžete zvolit zvětšení velikosti výpočetních prostředků databáze nebo elastického fondu, abyste tento problém vyřešili.
Další informace o zpracování problémů s výkonem procesoru ve službě Azure SQL Database najdete v tématu Diagnostika a řešení potíží s vysokým využitím procesoru ve službě Azure SQL Database.
Identifikace problémů s výkonem VV operací
Při identifikaci problémů s výkonem vstupně-výstupních operací úložiště jsou hlavní typy čekání:
PAGEIOLATCH_*U problémů s vstupně-výstupními operacemi datových souborů (včetně
PAGEIOLATCH_SH,PAGEIOLATCH_EX).PAGEIOLATCH_UPPokud název typu čekání obsahuje vstupně-výstupní operace, odkazuje na problém s vstupně-výstupními operacemi. Pokud v názvu západky stránky neexistuje vstupně-výstupní operace, odkazuje na jiný typ problému, který nesouvisí s výkonem úložiště (napříkladtempdbkolize).WRITE_LOGV případě problémů s vstupně-výstupními operacemi transakčního protokolu.
Pokud právě teď dochází k problému s vstupně-výstupními operacemi
Pomocí sys.dm_exec_requests nebo sys.dm_os_waiting_tasks wait_type wait_time
Identifikace dat a využití vstupně-výstupních operací protokolu
Pomocí následujícího dotazu identifikujte data a využití vstupně-výstupních operací protokolu.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Další příklady použití sys.dm_db_resource_statsnajdete v části Monitorování prostředků dále v tomto článku.
Pokud bylo dosaženo limitu vstupně-výstupních operací, máte dvě možnosti:
- Upgrade velikosti výpočetních prostředků nebo úrovně služby
- Identifikujte a vylaďte dotazy, které využívají nejvíce vstupně-výstupních operací.
Zobrazení vstupně-výstupních operací souvisejících s vyrovnávací pamětí pomocí úložiště dotazů
Pokud chcete identifikovat nejčastější dotazy podle čekání souvisejících s vstupně-výstupními operacemi, můžete pomocí následujícího dotazu úložiště dotazů zobrazit poslední dvě hodiny sledované aktivity:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Můžete také použít zobrazení sys.query_store_runtime_stats se zaměřením na dotazy s velkými hodnotami v polích avg_physical_io_reads a avg_num_physical_io_reads sloupcích.
Zobrazení celkových vstupně-výstupních operací protokolu pro čekání WRITELOG
Pokud je WRITELOGtyp čekání, pomocí následujícího dotazu zobrazte celkový počet vstupně-výstupních operací protokolu podle příkazu:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identifikace problémů s výkonem databáze tempdb
Běžné typy čekání spojené s tempdb problémy jsou PAGELATCH_* (ne PAGEIOLATCH_*). PAGELATCH_* Čekání ale neznamená, že máte tempdb kolize. Toto čekání může také znamenat, že kvůli souběžným požadavkům, které cílí na stejnou stránku dat, dochází na stránce dat ke kolizím uživatelských objektů. Pokud chcete dále potvrdit tempdb kolize, použijte sys.dm_exec_requests k potvrzení, že wait_resource hodnota začíná místem 2:x:y , kde 2 je tempdb ID databáze, x je ID souboru a y je ID stránky.
Pro tempdb kolizí je běžnou metodou omezení nebo přepsání kódu aplikace, který spoléhá na tempdb. Mezi běžné tempdb oblasti použití patří:
- Dočasné tabulky
- Proměnné tabulek
- Parametry vracející tabulku
- Dotazy s plány dotazů, které využívají řazení, hash spojení a zařazování
Další informace najdete v databázi tempdb v Azure SQL.
Všechny databáze v elastickém fondu sdílejí stejnou tempdb databázi. Vysoké tempdb využití prostoru v jedné databázi může mít vliv na jiné databáze ve stejném elastickém fondu.
Nejčastější dotazy, které používají proměnné tabulek a dočasné tabulky
Pomocí následujícího dotazu identifikujte nejčastější dotazy, které používají proměnné tabulky a dočasné tabulky:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identifikace dlouhotrvajících transakcí
Pomocí následujícího dotazu identifikujte dlouhotrvající transakce. Dlouhotrvající transakce brání vyčištění úložiště trvalých verzí (PVS). Další informace najdete v tématu Řešení potíží se zrychleným obnovením databáze.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identifikace problémů s výkonem čekání na přidělení paměti
Pokud je RESOURCE_SEMAPHOREvaším hlavním typem čekání , může dojít k problému s čekáním na přidělení paměti, kdy dotazy nemůžou spustit, dokud nezískají dostatečně velké přidělení paměti.
Určení, jestli je čekání RESOURCE_SEMAPHORE top wait
Pomocí následujícího dotazu určete, jestli RESOURCE_SEMAPHORE je čekání hlavní čekání. Indikuje to také, že by se v nedávné historii zobrazilo RESOURCE_SEMAPHORE rostoucí pořadí čekání. Další informace o řešení potíží s čekáním na přidělení paměti najdete v tématu Řešení potíží s nízkým výkonem nebo nedostatkem paměti způsobených přidělením paměti na SQL Serveru.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identifikace příkazů s vysokým využitím paměti
Pokud ve službě Azure SQL Database narazíte na chyby nedostatku paměti, projděte si sys.dm_os_out_of_memory_events. Další informace najdete v tématu Řešení chyb nedostatku paměti ve službě Azure SQL Database.
Nejprve upravte následující skript tak, aby aktualizoval relevantní hodnoty start_time a end_time. Potom spuštěním následujícího dotazu identifikujte příkazy s vysokým využitím paměti:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identifikace 10 nejlepších grantů aktivní paměti
Pomocí následujícího dotazu identifikujte 10 nejlepších grantů aktivní paměti:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Monitorování připojení
Pomocí zobrazení sys.dm_exec_connections můžete načíst informace o připojeních vytvořených ke konkrétní databázi a podrobnosti o jednotlivých připojeních. Pokud je databáze v elastickém fondu a máte dostatečná oprávnění, vrátí zobrazení sadu připojení pro všechny databáze v elastickém fondu. Kromě toho je zobrazení sys.dm_exec_sessions užitečné při načítání informací o všech aktivních připojeních uživatelů a interních úlohách.
Zobrazení aktuálních relací
Následující dotaz načte informace o vašem aktuálním připojení a relaci. Pokud chcete zobrazit všechna připojení a relace, odeberte klauzuli WHERE .
Zobrazí se všechny spuštěné relace v databázi pouze v případě, že máte VIEW DATABASE STATE oprávnění k databázi při provádění sys.dm_exec_requests a sys.dm_exec_sessions zobrazení. V opačném případě se zobrazí pouze aktuální relace.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Monitorování výkonu dotazů
Pomalé nebo dlouhotrvající dotazy můžou spotřebovávat významné systémové prostředky. Tato část ukazuje, jak pomocí zobrazení dynamické správy zjistit několik běžných problémů s výkonem dotazů pomocí zobrazení dynamické správy sys.dm_exec_query_stats . Zobrazení obsahuje jeden řádek na příkaz dotazu v rámci plánu v mezipaměti a životnost řádků jsou svázané se samotným plánem. Při odebrání plánu z mezipaměti se z tohoto zobrazení odstraní odpovídající řádky. Pokud dotaz nemá například plán uložený v mezipaměti, protože OPTION (RECOMPILE) se používá, nezobrazí se ve výsledcích tohoto zobrazení.
Vyhledání nejčastějších dotazů podle času procesoru
Následující příklad vrátí informace o prvních 15 dotazech seřazených podle průměrného času procesoru na spuštění. Tento příklad agreguje dotazy podle jejich hodnoty hash dotazu, aby se logicky ekvivalentní dotazy seskupily podle kumulativní spotřeby prostředků.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Monitorování plánů dotazů pro kumulativní čas procesoru
Neefektivní plán dotazů může také zvýšit spotřebu procesoru. Následující příklad určuje, který dotaz používá nejvíce kumulativní procesor v poslední historii.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Monitorování blokovaných dotazů
Pomalé nebo dlouhotrvající dotazy můžou přispívat k nadměrné spotřebě prostředků a být důsledkem blokovaných dotazů. Příčinou blokování může být špatný návrh aplikace, chybné plány dotazů, nedostatek užitečných indexů atd.
Pomocí tohoto zobrazení můžete sys.dm_tran_locks získat informace o aktuální aktivitě uzamčení v databázi. Příklady kódu najdete v tématu sys.dm_tran_locks. Další informace o řešení potíží s blokováním najdete v tématu Vysvětlení a řešení problémů blokujících Azure SQL.
Monitorování zablokování
V některých případech můžou dva nebo více dotazů navzájem blokovat, což vede k vzájemnému zablokování.
Můžete vytvořit trasování rozšířených událostí pro zachycení událostí vzájemného zablokování a pak vyhledat související dotazy a jejich plány provádění v úložišti dotazů. Další informace najdete v tématu Analyzovat a zabránit zablokování ve službě Azure SQL Database, včetně testovacího prostředí, které způsobí zablokování v AdventureWorksLT. Přečtěte si další informace o typech prostředků, které můžou vzájemné zablokování.
Související obsah
- Seznámení se službou Azure SQL Database a službou Azure SQL Managed Instance
- Diagnostika a řešení potíží s vysokým využitím procesoru ve službě Azure SQL Database
- Optimalizace aplikací a databází z hlediska výkonu v Azure SQL Database
- Vysvětlení a řešení problémů s blokováním služby Azure SQL Database
- Analýza a zabránění zablokování ve službě Azure SQL Database
- Monitorování úloh Azure SQL pomocí sledovacího procesu databáze (Preview)
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro