Zrychlení analýz velkých objemů dat v reálném čase pomocí konektoru Spark
Platí pro:![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Poznámka:
Od zář 2020 se tento konektor aktivně neudržuje. Konektor Apache Spark pro SQL Server a Azure SQL je teď k dispozici s podporou vazeb Pythonu a R, jednodušším rozhraním pro hromadné vkládání dat a mnoha dalších vylepšení. Důrazně doporučujeme, abyste místo tohoto konektoru vyhodnotili nový konektor a použili ho. Informace o starém konektoru (této stránce) se uchovávají pouze pro účely archivace.
Konektor Spark umožňuje databázím ve službě Azure SQL Database, Azure SQL Managed Instance a SQL Serveru fungovat jako vstupní zdroj dat nebo výstupní jímka dat pro úlohy Sparku. Umožňuje využívat transakční data v reálném čase v analýze velkých objemů dat a uchovávat výsledky pro ad hoc dotazy nebo generování sestav. V porovnání s integrovaným konektorem JDBC tento konektor umožňuje hromadně vkládat data do databáze. Díky 10x až 20x rychlejšímu výkonu může překračovat vkládání řádků po řádech. Konektor Spark podporuje ověřování pomocí Microsoft Entra ID (dříve Azure Active Directory) pro připojení k Azure SQL Database a Azure SQL Managed Instance, což umožňuje připojení databáze z Azure Databricks pomocí účtu Microsoft Entra. Poskytuje podobná rozhraní s integrovaným konektorem JDBC. Pomocí tohoto nového konektoru můžete snadno migrovat stávající úlohy Sparku.
Poznámka:
ID Microsoft Entra se dříve označovalo jako Azure Active Directory (Azure AD).
Stažení a sestavení konektoru Spark
Úložiště GitHub pro starý konektor, na který jste dříve odkazované z této stránky, se aktivně neudržuje. Místo toho důrazně doporučujeme vyhodnotit a používat nový konektor.
Oficiální podporované verze
| Komponenta | Verze |
|---|---|
| Apache Spark | 2.0.2 nebo novější |
| Scala | 2.10 nebo novější |
| Ovladač Microsoft JDBC pro SQL Server | 6.2 nebo novější |
| Microsoft SQL Server | SQL Server 2008 nebo novější |
| Azure SQL Database | Podporováno |
| Azure SQL Managed Instance | Podporováno |
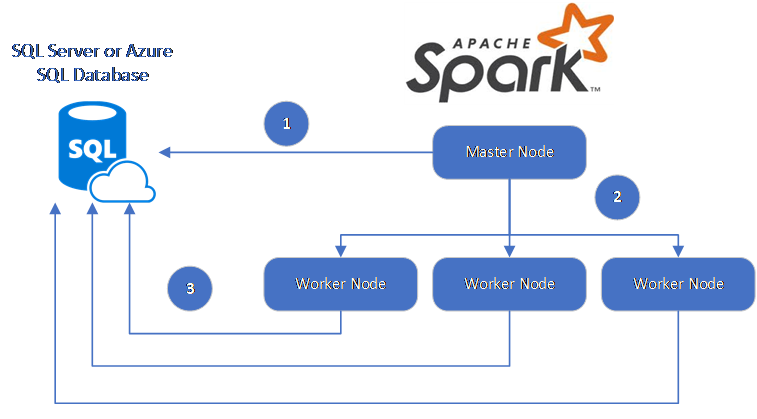
Konektor Spark využívá ovladač Microsoft JDBC pro SQL Server k přesunu dat mezi pracovními uzly Sparku a databázemi:
Tok dat je následující:
- Hlavní uzel Sparku se připojí k databázím ve službě SQL Database nebo SQL Serveru a načte data z konkrétní tabulky nebo pomocí konkrétního dotazu SQL.
- Hlavní uzel Sparku distribuuje data do pracovních uzlů pro transformaci.
- Pracovní uzel se připojuje k databázím, které se připojují ke službě SQL Database a SQL Serveru a zapisují data do databáze. Uživatel se může rozhodnout použít vložení řádku po řádku nebo hromadné vložení.
Následující diagram znázorňuje tok dat.
Sestavení konektoru Spark
V současné době projekt konektoru používá maven. Pokud chcete vytvořit konektor bez závislostí, můžete spustit:
- Čistý balíček mvn
- Stáhněte si nejnovější verze SOUBORU JAR ze složky vydané verze.
- Zahrnutí jar Sparku pro SQL Database
Připojení a čtení dat pomocí konektoru Spark
K databázím ve službě SQL Database a SQL Serveru se můžete připojit z úlohy Sparku za účelem čtení nebo zápisu dat. Můžete také spustit dotaz DML nebo DDL v databázích v SQL Database a SQL Serveru.
Čtení dat z Azure SQL a SQL Serveru
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Čtení dat z Azure SQL a SQL Serveru pomocí zadaného dotazu SQL
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Zápis dat do Azure SQL a SQL Serveru
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Spuštění dotazu DML nebo DDL v Azure SQL a SQL Serveru
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Připojení ze Sparku pomocí ověřování Microsoft Entra
Ke službě SQL Database a službě SQL Managed Instance se můžete připojit pomocí ověřování Microsoft Entra. Ověřování Microsoft Entra umožňuje centrálně spravovat identity uživatelů databáze a jako alternativu k ověřování SQL.
Připojení pomocí režimu ověřování ActiveDirectoryPassword
Požadavek na nastavení
Pokud používáte režim ověřování ActiveDirectoryPassword, musíte stáhnout microsoft-authentication-library-for-java a jeho závislosti a zahrnout je do cesty sestavení Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Připojení pomocí přístupového tokenu
Požadavek na nastavení
Pokud používáte režim ověřování na základě přístupového tokenu, musíte stáhnout knihovnu microsoft-authentication-for-java a její závislosti a zahrnout je do cesty sestavení Java.
Informace o získání přístupového tokenu k databázi ve službě Azure SQL Database nebo azure SQL Managed Instance najdete v tématu Použití ověřování Microsoft Entra.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Zápis dat s využitím hromadného vložení
Tradiční konektor jdbc zapisuje data do databáze pomocí vložení řádku po řádku. Pomocí konektoru Spark můžete zapisovat data do Azure SQL a SQL Serveru pomocí hromadného vložení. Výrazně zvyšuje výkon zápisu při načítání velkých datových sad nebo načítání dat do tabulek, kde se používá index columnstore.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Další kroky
Pokud jste to ještě neudělali, stáhněte si konektor Spark z úložiště Azure-sqldb-spark na GitHubu a prozkoumejte další prostředky v úložišti:
Můžete si také projít příručku Apache Spark SQL, datové rámce a datové sady a dokumentaci k Azure Databricks.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro