Ladění výkonu aplikací a databází ve službě Azure SQL Managed Instance
Platí pro: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Jakmile zjistíte problém s výkonem, ke kterému dochází u služby Azure SQL Managed Instance, je tento článek navržený tak, aby vám pomohl:
- Vylaďte aplikaci a použijte některé osvědčené postupy, které můžou zlepšit výkon.
- Vylaďte databázi změnou indexů a dotazů, abyste efektivněji pracovali s daty.
Tento článek předpokládá, že jste si prošli přehled monitorování a ladění a monitorování výkonu pomocí úložiště dotazů. Kromě toho tento článek předpokládá, že nemáte problém s výkonem související s využitím prostředků procesoru, který je možné vyřešit zvýšením velikosti výpočetních prostředků nebo úrovně služby za účelem poskytování dalších prostředků spravované instanci SQL.
Poznámka:
Podobné pokyny najdete v tématu Ladění aplikací a databází pro výkon ve službě Azure SQL Database.
Ladění aplikace
V tradičním místním SQL Serveru se proces počátečního plánování kapacity často odděluje od procesu spouštění aplikace v produkčním prostředí. Licence na hardware a produkty se kupují jako první a ladění výkonu se provede později. Když používáte Azure SQL, je vhodné probrat proces spuštění aplikace a jeho ladění. S modelem platby za kapacitu na vyžádání můžete svou aplikaci ladit tak, aby používala minimální prostředky, které jsou teď potřeba, místo nadměrného zřizování hardwaru na základě odhadů budoucích plánů růstu pro aplikaci, což často není správné.
Někteří zákazníci se můžou rozhodnout, že aplikaci nenaladí a místo toho se rozhodnou zřizovat hardwarové prostředky. Tento přístup může být dobrým nápadem, pokud nechcete změnit klíčovou aplikaci během zaneprázdněného období. Ladění aplikace ale může minimalizovat požadavky na prostředky a snížit měsíční vyúčtování.
Osvědčené postupy a antipatterny v návrhu aplikací pro azure SQL Managed Instance
I když jsou úrovně služby Azure SQL Managed Instance navržené tak, aby zlepšily stabilitu výkonu a předvídatelnost pro aplikaci, některé osvědčené postupy vám můžou pomoct ladit aplikaci, aby lépe využívala prostředky ve výpočetní velikosti. I když mnoho aplikací má výrazné zvýšení výkonu jednoduše přechodem na vyšší velikost výpočetních prostředků nebo úroveň služby, některé aplikace potřebují další ladění, aby mohly využívat vyšší úroveň služeb.
Pokud chcete zvýšit výkon, zvažte další ladění aplikací pro aplikace, které mají tyto charakteristiky:
Aplikace, které mají nízký výkon kvůli "chatty" chování
Chatty aplikace dělají nadměrné operace přístupu k datům, které jsou citlivé na latenci sítě. Možná budete muset upravit tyto typy aplikací, abyste snížili počet operací přístupu k datům do databáze. Výkon aplikace můžete například zlepšit pomocí technik, jako je dávkování ad hoc dotazů nebo přesunutí dotazů do uložených procedur. Další informace najdete v tématu Dávkové dotazy.
Databáze s náročným zatížením, které nemůže podporovat celý jeden počítač
Databáze, které překračují prostředky nejvyšší velikosti výpočetních prostředků Premium, můžou těžit z horizontálního navýšení kapacity úlohy. Další informace najdete v tématu Horizontální dělení mezi databázemi a funkční dělení.
Aplikace, které mají neoptimální dotazy
Aplikace, které mají špatně vyladěné dotazy, nemusí těžit z vyšší velikosti výpočetních prostředků. To zahrnuje dotazy, které nemají klauzuli WHERE, chybějící indexy nebo zastaralé statistiky. Tyto aplikace využívají standardní techniky ladění výkonu dotazů. Další informace najdete v tématu Chybějící indexy a ladění dotazů a rady.
Aplikace, které mají neoptimální návrh přístupu k datům
U aplikací, které mají problémy se souběžností přístupu k datům, například zablokování, nemusí mít vyšší velikost výpočetních prostředků. Zvažte snížení doby odezvy databáze ukládáním dat do mezipaměti na straně klienta se službou Ukládání do mezipaměti Azure nebo jinou technologií ukládání do mezipaměti. Viz Ukládání aplikační vrstvy do mezipaměti.
Pokud chcete zabránit zablokování ve službě Azure SQL Managed Instance, přečtěte si o nástrojích vzájemného zablokování v průvodci vzájemným zablokováním.
Ladění databáze
V této části se podíváme na některé techniky, které můžete použít k ladění databáze, abyste dosáhli nejlepšího výkonu pro vaši aplikaci a spustili ji s nejnižší možnou velikostí výpočetních prostředků. Některé z těchto technik odpovídají tradičním osvědčeným postupům ladění SQL Serveru, ale jiné jsou specifické pro službu Azure SQL Managed Instance. V některých případech můžete prozkoumat spotřebované prostředky databáze a najít oblasti pro další ladění a rozšíření tradičních technik SQL Serveru pro práci ve službě Azure SQL Managed Instance.
Identifikace a přidání chybějících indexů
Běžný problém s výkonem databáze OLTP souvisí s návrhem fyzické databáze. Schémata databáze se často navrhují a dodávají bez testování ve velkém měřítku (buď v zatížení, nebo v datovém objemu). Výkon plánu dotazů může být bohužel přijatelný v malém měřítku, ale výrazně se snižuje pod objemy dat na úrovni produkce. Nejběžnějším zdrojem tohoto problému je nedostatek vhodných indexů pro splnění filtrů nebo jiných omezení v dotazu. Chybějící indexy se často manifestují jako prohledávání tabulky, když může stačit hledání indexu.
V tomto příkladu použije vybraný plán dotazu kontrolu, když bude stačit hledání:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
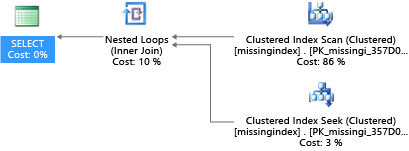
Zobrazení dynamické správy, která jsou integrovaná do SQL Serveru od roku 2005, se dívají na kompilace dotazů, ve kterých by index výrazně snížil odhadované náklady na spuštění dotazu. Během provádění dotazů databázový stroj sleduje, jak často se každý plán dotazů spouští, a sleduje odhadovanou mezeru mezi plánem spouštějícím dotazu a představou, kde tento index existoval. Pomocí těchto zobrazení dynamické správy můžete rychle odhadnout, které změny návrhu fyzické databáze můžou zlepšit celkové náklady na úlohy pro databázi a její skutečnou úlohu.
Pomocí tohoto dotazu můžete vyhodnotit potenciální chybějící indexy:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
V tomto příkladu byl výsledkem dotazu tento návrh:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Po vytvoření vybere stejný příkaz SELECT jiný plán, který místo kontroly použije hledání a pak plán spustí efektivněji:
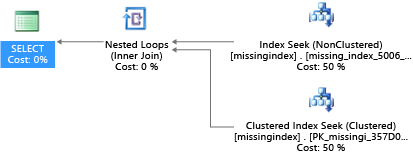
Klíčovým přehledem je, že vstupně-výstupní kapacita sdíleného, komoditního systému je omezenější než kapacita vyhrazeného serverového počítače. Při minimalizaci zbytečných vstupně-výstupních operací je k dispozici úroveň Premium, která využívá maximální využití systému v prostředcích jednotlivých velikostí výpočetních prostředků úrovní služby. Vhodné volby návrhu fyzické databáze mohou výrazně zlepšit latenci jednotlivých dotazů, zlepšit propustnost souběžných požadavků zpracovávaných podle jednotky škálování a minimalizovat náklady potřebné k uspokojení dotazu.
Další informace o ladění indexů pomocí chybějících požadavků indexu naleznete v tématu Ladění neclusterovaných indexů s chybějícími návrhy indexu.
Ladění dotazů a rady
Optimalizátor dotazů ve službě Azure SQL Managed Instance se podobá tradičnímu optimalizátoru dotazů SQL Serveru. Většina osvědčených postupů pro ladění dotazů a pochopení omezení modelu odůvodnění pro optimalizátor dotazů platí také pro spravovanou instanci Azure SQL. Pokud vyladíte dotazy ve službě Azure SQL Managed Instance, můžete získat další výhodu snížení agregovaných požadavků na prostředky. Vaše aplikace může běžet s nižšími náklady než neladěný ekvivalent, protože může běžet s nižší velikostí výpočetních prostředků.
Příkladem, který je běžný v SQL Serveru a který platí také pro službu Azure SQL Managed Instance, je způsob, jakým parametry optimalizátoru dotazů "sniffs". Během kompilace vyhodnocuje optimalizátor dotazů aktuální hodnotu parametru a určí, jestli může vygenerovat optimaličtější plán dotazu. I když tato strategie často může vést k plánu dotazu, který je výrazně rychlejší než plán zkompilovaný bez známých hodnot parametrů, v současné době funguje v Azure SQL Managed Instance imperfectly. (Nová funkce inteligentního výkonu dotazů zavedená s názvem SQL Server 2022Optimalizace plánu citlivosti parametru řeší scénář, kdy jeden plán uložený v mezipaměti parametrizovaného dotazu není optimální pro všechny možné příchozí hodnoty parametrů. V současné době není optimalizace plánu citlivosti parametrů ve službě Azure SQL Managed Instance dostupná.)
Někdy se parametr nešifruje a někdy se parametr šifruje, ale vygenerovaný plán je neoptimální pro úplnou sadu hodnot parametrů v úloze. Microsoft obsahuje rady dotazů (direktivy), abyste mohli záměrně určit záměr a přepsat výchozí chování při zašifrování parametrů. Pokud je výchozí chování pro konkrétní úlohu zákazníka nedostupné, můžete použít rady.
Následující příklad ukazuje, jak může procesor dotazů vygenerovat plán, který je neoptimální jak pro požadavky na výkon, tak pro prostředky. Tento příklad také ukazuje, že pokud používáte nápovědu k dotazu, můžete zkrátit dobu běhu dotazu a požadavky na prostředky pro vaši databázi:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Instalační kód vytvoří tabulku s nepravidelně distribuovanými t1 daty v tabulce. Optimální plán dotazu se liší podle toho, který parametr je vybrán. Chování při ukládání plánu do mezipaměti bohužel ne vždy rekompiuje dotaz na základě nejběžnější hodnoty parametru. Proto je možné, že se neoptimální plán uloží do mezipaměti a použije se pro mnoho hodnot, i když jiný plán může být v průměru lepší volbou plánu. Pak plán dotazu vytvoří dvě uložené procedury, které jsou identické, s tím rozdílem, že jeden obsahuje speciální nápovědu dotazu.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Doporučujeme počkat aspoň 10 minut, než začnete část 2 příkladu, aby výsledky byly ve výsledných telemetrických datech odlišné.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
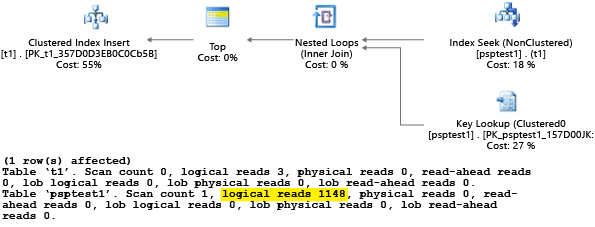
Každá část tohoto příkladu se pokusí spustit parametrizovaný příkaz insert 1 000krát (pro vygenerování dostatečného zatížení pro použití jako testovací datovou sadu). Při provádění uložených procedur procesor dotazu zkontroluje hodnotu parametru, která je předána procedury během první kompilace (parametr "sniffing"). Procesor uloží výsledný plán do mezipaměti a použije ho pro pozdější vyvolání, i když se hodnota parametru liší. Optimální plán se nemusí používat ve všech případech. Někdy potřebujete průvodce optimalizátorem, abyste vybrali plán, který je pro průměrný případ lepší než pro konkrétní případ z doby, kdy byl dotaz poprvé zkompilován. V tomto příkladu počáteční plán vygeneruje plán kontroly, který načte všechny řádky a vyhledá každou hodnotu, která odpovídá parametru:

Vzhledem k tomu, že jsme proceduru provedli pomocí hodnoty 1, byl výsledný plán pro hodnotu 1 optimální, ale byl neoptimální pro všechny ostatní hodnoty v tabulce. Výsledek pravděpodobně není to, co byste chtěli, kdybyste vybrali každý plán náhodně, protože plán provádí pomaleji a používá více prostředků.
Pokud test spustíte se nastavenou SET STATISTICS IO sadou ON, provede se logická kontrola v tomto příkladu na pozadí. Vidíte, že plán provádí 1 148 čtení (což je neefektivní, pokud se průměrný případ má vrátit jen jeden řádek):

Druhá část příkladu používá nápovědu dotazu k tomu, aby optimalizátoru řekl, aby během procesu kompilace použil konkrétní hodnotu. V tomto případě vynutí procesoru dotazů ignorovat hodnotu, která je předána jako parametr, a místo toho předpokládat UNKNOWN. To odkazuje na hodnotu, která má průměrnou frekvenci v tabulce (ignorování nerovnoměrné distribuce). Výsledný plán je plán založený na hledání, který je rychlejší a v průměru používá méně prostředků než plán v části 1 tohoto příkladu:
Efekt můžete zobrazit v zobrazení sys.server_resource_stats systémového katalogu. Data se shromažďují, agregují a aktualizují do 5 až 10 minut. Každé 15sekundové hlášení má jeden řádek. Příklad:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Můžete zkontrolovat sys.server_resource_stats , jestli prostředek pro test používá více nebo méně prostředků než jiný test. Při porovnávání dat oddělte časování testů tak, aby v zobrazení nebyly ve stejném 5minutovém okně sys.server_resource_stats . Cílem tohoto cvičení je minimalizovat celkové množství použitých prostředků, nikoli minimalizovat prostředky ve špičce. Obecně platí, že optimalizace části kódu pro latenci také snižuje spotřebu prostředků. Ujistěte se, že změny, které v aplikaci provedete, jsou nezbytné a že změny nemají negativní vliv na prostředí zákazníka pro uživatele, který může v aplikaci používat nápovědy pro dotazy.
Pokud má úloha sadu opakujících se dotazů, často dává smysl zachytávat a ověřovat optimální volby plánu, protože řídí minimální jednotku velikosti prostředků potřebnou k hostování databáze. Jakmile ho ověříte, občas znovu prověříte plány, které vám pomůžou zajistit, že nedošlo ke snížení jejich výkonu. Další informace o tipech dotazů (Transact-SQL)
Osvědčené postupy pro velmi rozsáhlé databázové architektury ve službě Azure SQL Managed Instance
Následující dvě části diskutují o dvou možnostech řešení problémů s velmi velkými databázemi ve službě Azure SQL Managed Instance.
Horizontální dělení napříč databázemi
Vzhledem k tomu, že azure SQL Managed Instance běží na komoditní hardwaru, jsou limity kapacity pro jednotlivé databáze nižší než u tradiční místní instalace SQL Serveru. Někteří zákazníci používají techniky horizontálního dělení k rozložení databázových operací do více databází, když se operace nevejdou do limitů jednotlivých databází ve službě Azure SQL Managed Instance. Většina zákazníků, kteří používají techniky horizontálního dělení ve službě Azure SQL Managed Instance, rozdělí svá data na jednu dimenzi napříč několika databázemi. U tohoto přístupu je potřeba pochopit, že aplikace OLTP často provádějí transakce, které se vztahují pouze na jeden řádek nebo malou skupinu řádků ve schématu.
Pokud například databáze obsahuje jméno zákazníka, objednávku a podrobnosti objednávky (například v AdventureWorks databázi), můžete tato data rozdělit do více databází seskupením zákazníka se souvisejícími informacemi o objednávce a objednávce. Můžete zaručit, že data zákazníka zůstanou v individuální databázi. Aplikace by rozdělila různé zákazníky mezi databáze a efektivně rozprostírá zatížení napříč několika databázemi. S horizontálním dělením se zákazníci můžou vyhnout maximálnímu limitu velikosti databáze, ale Azure SQL Managed Instance může zpracovávat také úlohy, které jsou výrazně větší než limity různých velikostí výpočetních prostředků, pokud každá jednotlivá databáze zapadá do limitů úrovně služby.
I když horizontální dělení databáze nezmenšuje agregovanou kapacitu prostředků pro řešení, je vysoce efektivní při podpoře velmi rozsáhlých řešení, která jsou rozložená do více databází. Každá databáze může běžet s jinou velikostí výpočetních prostředků, aby podporovala velmi rozsáhlé "efektivní" databáze s vysokými požadavky na prostředky.
Funkční dělení
Uživatelé často kombinují mnoho funkcí v jednotlivých databázích. Pokud má například aplikace logiku pro správu inventáře úložiště, může mít tato databáze logiku přidruženou k inventáři, sledování nákupních objednávek, uložených procedur a indexovaných nebo materializovaných zobrazení, která spravují generování sestav na konci měsíce. Tato technika usnadňuje správu databáze pro operace, jako je zálohování, ale vyžaduje také velikost hardwaru pro zpracování zatížení ve špičce napříč všemi funkcemi aplikace.
Pokud ve službě Azure SQL Managed Instance používáte architekturu horizontálního navýšení kapacity, je vhodné rozdělit různé funkce aplikace do různých databází. Pokud použijete tuto techniku, každá aplikace se škáluje nezávisle. S tím, jak se aplikace zvětšuje (a zatížení databáze se zvyšuje), může správce zvolit nezávislé velikosti výpočetních prostředků pro každou funkci v aplikaci. Při této architektuře může aplikace být větší než jeden komoditní počítač, který dokáže zpracovat, protože zatížení je rozložené mezi více počítačů.
Dávkové dotazy
U aplikací, které přistupují k datům pomocí častých, ad hoc dotazování, je značné množství doby odezvy vynaložené na síťovou komunikaci mezi aplikační vrstvou a databázovou vrstvou. I když jsou aplikace i databáze ve stejném datovém centru, může být latence sítě mezi těmito dvěma daty zvětšena velkým počtem operací přístupu k datům. Pokud chcete snížit dobu odezvy sítě pro operace přístupu k datům, zvažte použití možnosti dávkování ad hoc dotazů nebo jejich kompilace jako uložených procedur. Pokud ad hoc dotazy dávkováte, můžete v jedné cestě do databáze odeslat více dotazů jako jednu velkou dávku. Pokud v uložené proceduře zkompilujete ad hoc dotazy, můžete dosáhnout stejného výsledku, jako kdybyste je dávili. Když použijete uloženou proceduru, získáte také výhodu zvýšení pravděpodobnosti ukládání plánů dotazů do mezipaměti v databázi, abyste mohli uloženou proceduru znovu použít.
Některé aplikace jsou náročné na zápis. Někdy můžete snížit celkové vstupně-výstupní zatížení databáze zvážením toho, jak dávkové zápisy dohromady. Často je to jednoduché jako použití explicitních transakcí místo automatickéhocommit transakcí v uložených procedurách a ad hoc dávkách. Vyhodnocení různých technik, které můžete použít, najdete v tématu Dávkové techniky pro databázové aplikace v Azure. Experimentujte s vlastní úlohou a najděte správný model pro dávkování. Nezapomeňte pochopit, že model může mít mírně odlišné záruky transakční konzistence. Nalezení správné úlohy, která minimalizuje využití prostředků, vyžaduje nalezení správné kombinace konzistencí a kompromisů výkonu.
Ukládání do mezipaměti na úrovni aplikace
Některé databázové aplikace mají úlohy náročné na čtení. Vrstvy ukládání do mezipaměti můžou snížit zatížení databáze a potenciálně snížit velikost výpočetních prostředků potřebnou k podpoře databáze pomocí služby Azure SQL Managed Instance. Pokud máte v Azure Cache for Redis úlohu náročné na čtení, můžete data číst jednou (nebo jednou na počítač vrstvy aplikace v závislosti na tom, jak je nakonfigurovaná) a pak tato data ukládat mimo vaši databázi. Jedná se o způsob, jak snížit zatížení databáze (procesor a vstupně-výstupní operace čtení), ale existuje vliv na transakční konzistenci, protože data načtená z mezipaměti nemusí být synchronizovaná s daty v databázi. I když v mnoha aplikacích je určitá úroveň nekonzistence přijatelná, to neplatí pro všechny úlohy. Před implementací strategie ukládání do mezipaměti na úrovni aplikace byste měli plně pochopit všechny požadavky na aplikace.
Související obsah
- Nákupní model virtuálních jader – Azure SQL Managed Instance
- Konfigurace nastavení databáze tempdb pro službu Azure SQL Managed Instance
- Monitorování výkonu spravované instance Microsoft Azure SQL pomocí zobrazení dynamické správy
- Ladění neclusterovaných indexů s využitím návrhů týkajících se chybějících indexů
- Monitorování služby Azure SQL Managed Instance pomocí služby Azure Monitor