Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak obnovit databáze SAP HANA spuštěné na virtuálních počítačích Azure pomocí webu Azure Portal a že služba Azure Backup zálohovala do trezoru služby Recovery Services. Azure Backup umožňuje používat obnovená data k vytváření kopií pro scénáře vývoje a testování nebo k návratu do předchozího stavu. Databázi můžete obnovit také pomocí Azure CLI.
Azure Backup teď podporuje zálohování a obnovení instance replikace systému SAP HANA (HSR) pomocí webu Azure Portal. Operaci obnovení můžete provést také pomocí Azure CLI.
Poznámka:
- Proces obnovení pro databáze HANA s HSR je stejný jako proces obnovení pro databáze HANA bez HSR. Podle doporučení SAP můžete databáze obnovit pomocí režimu HSR jako samostatné databáze. Pokud má cílový systém povolený režim HSR, nejprve režim zakažte a pak databázi obnovte. Pokud ale obnovujete jako soubory, není potřeba vypnout režim HSR (přerušení HSR).
- Obnovení původního umístění (OLR) se v současné době nepodporuje pro HSR. Případně vyberte obnovení alternativního umístění a pak ze seznamu vyberte zdrojový virtuální počítač jako hostitele.
- Obnovení do instance HSR se nepodporuje. Obnovení pouze do instance HANA je však podporováno.
Informace o podporovaných konfiguracích a scénářích najdete v matici podpory zálohování SAP HANA.
Obnovit do určitého bodu v čase nebo do bodu obnovení
Azure Backup obnoví databáze SAP HANA spuštěné na virtuálních počítačích Azure. Dokáže:
Obnovte je k určitému datu nebo času (na sekundu) pomocí záloh protokolů. Azure Backup automaticky určuje odpovídající úplné zálohy, rozdílové zálohy a řetěz záloh protokolů, které jsou potřeba k obnovení na základě vybraného času. Další informace.
Obnovte je do určitého úplného nebo rozdílového zálohování, abyste je obnovili do konkrétního bodu obnovení. Další informace.
Požadavky
Než začnete obnovovat databázi, mějte na paměti následující:
Databázi můžete obnovit pouze do instance SAP HANA, která je ve stejné oblasti.
Cílová instance musí být registrovaná ve stejném trezoru jako zdroj. Přečtěte si další informace o zálohování databází SAP HANA.
Azure Backup nemůže identifikovat dvě různé instance SAP HANA na stejném virtuálním počítači. Obnovení dat z jedné instance do druhé na stejném virtuálním počítači proto není možné.
Pokud chcete zajistit, aby cílová instance SAP HANA byla připravená k obnovení, zkontrolujte stav připravenosti zálohování :
Na webu Azure Portal přejděte do Centra zálohování a pak vyberte Zálohování.
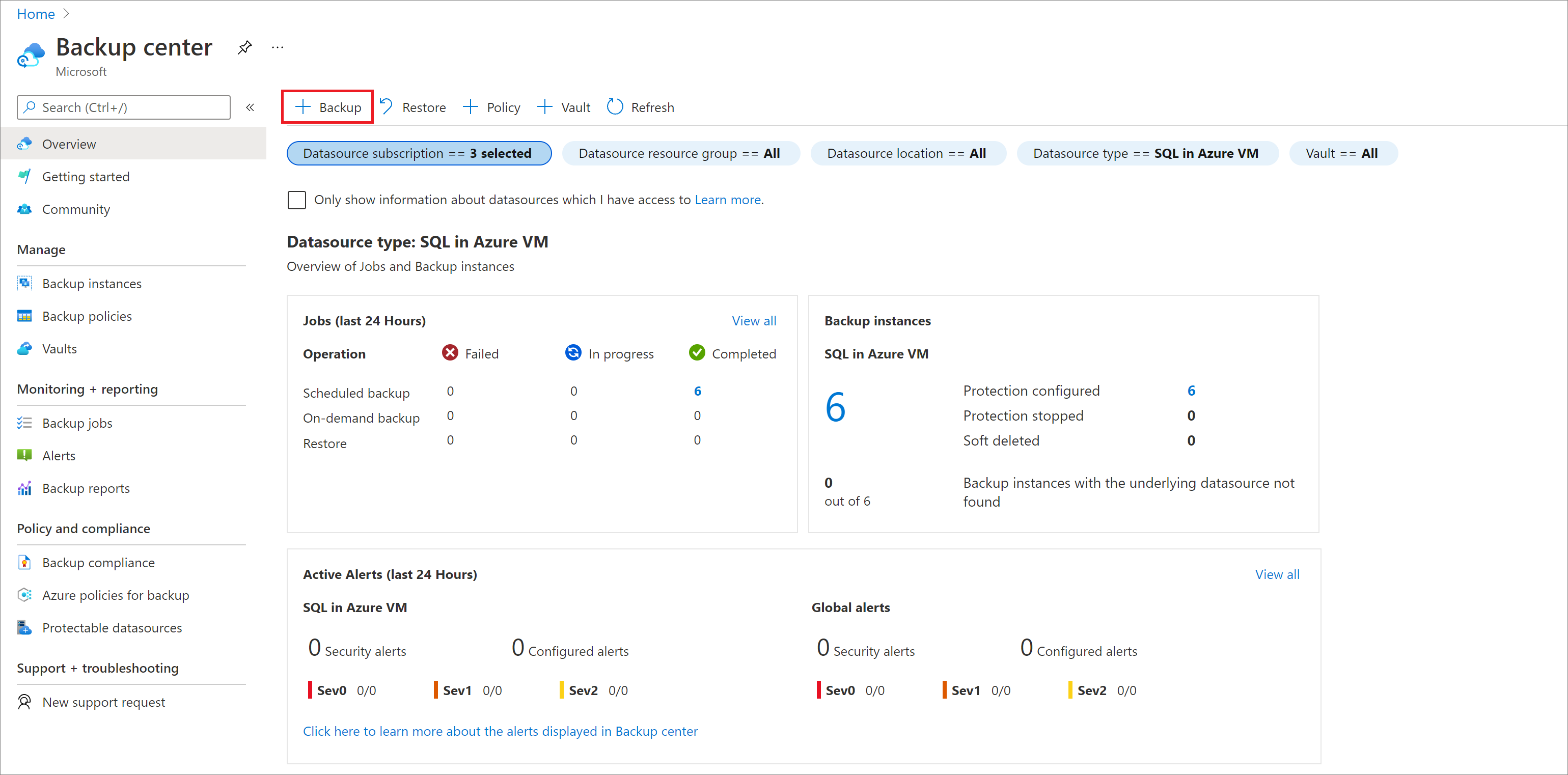
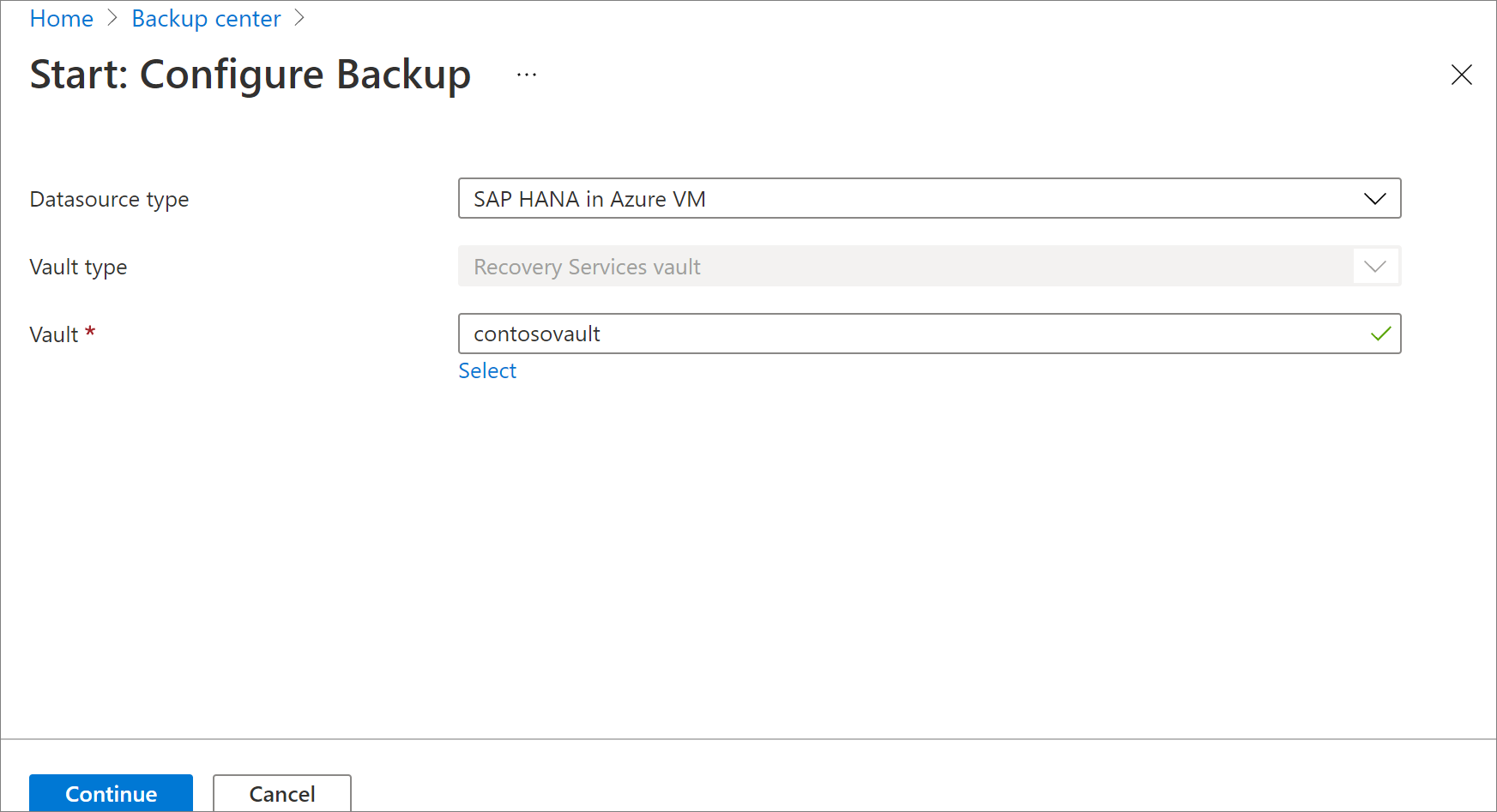
Na obrazovce Start: Nakonfigurujte podokno Zálohování pro typ Zdroje dat, vyberte na virtuálním počítači Azure SAP HANA, vyberte trezor, do kterého je instance SAP HANA zaregistrovaná, a pak vyberte Pokračovat.
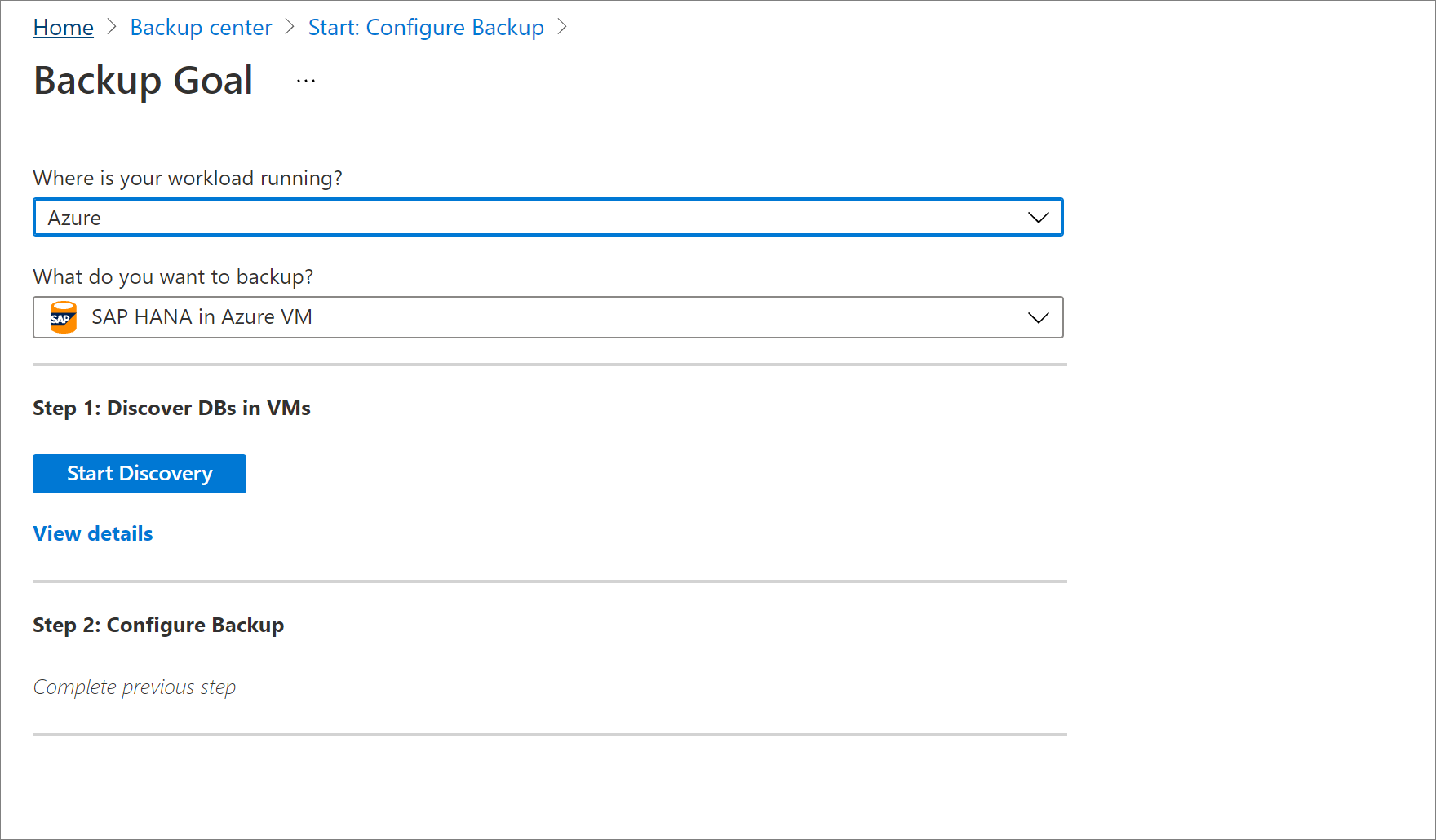
V části Zjistit databáze ve virtuálních počítačích vyberte Zobrazit podrobnosti.
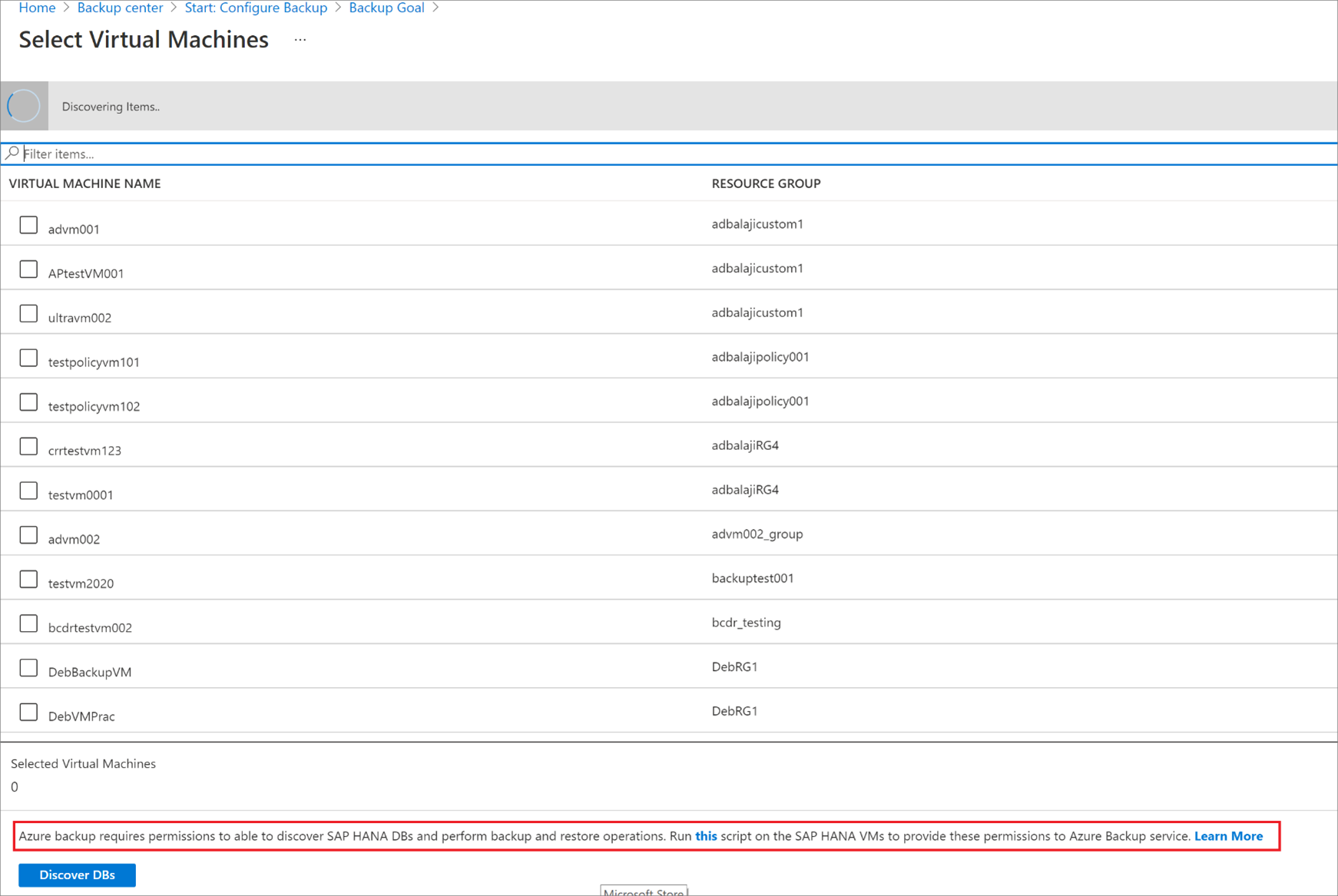
Zkontrolujte připravenost zálohování cílového virtuálního počítače.
Další informace o typech obnovení, které SAP HANA podporuje, najdete v poznámkovém 1642148 SAP HANA.


Obnovení databáze
K obnovení databáze potřebujete následující oprávnění:
- Operátor zálohování: Poskytuje oprávnění v trezoru, ve kterém provádíte obnovení.
- Přispěvatel (zápis): Poskytuje přístup ke zdrojovému virtuálnímu počítači, který je zálohovaný.
-
Přispěvatel (zápis): Poskytuje přístup k cílovému virtuálnímu počítači.
- Pokud provádíte obnovení do stejného virtuálního počítače, jedná se o zdrojový virtuální počítač.
- Pokud provádíte obnovení do jiného umístění, jedná se o nový cílový virtuální počítač.
Na webu Azure Portal přejděte do Centra zálohování a pak vyberte Obnovit.
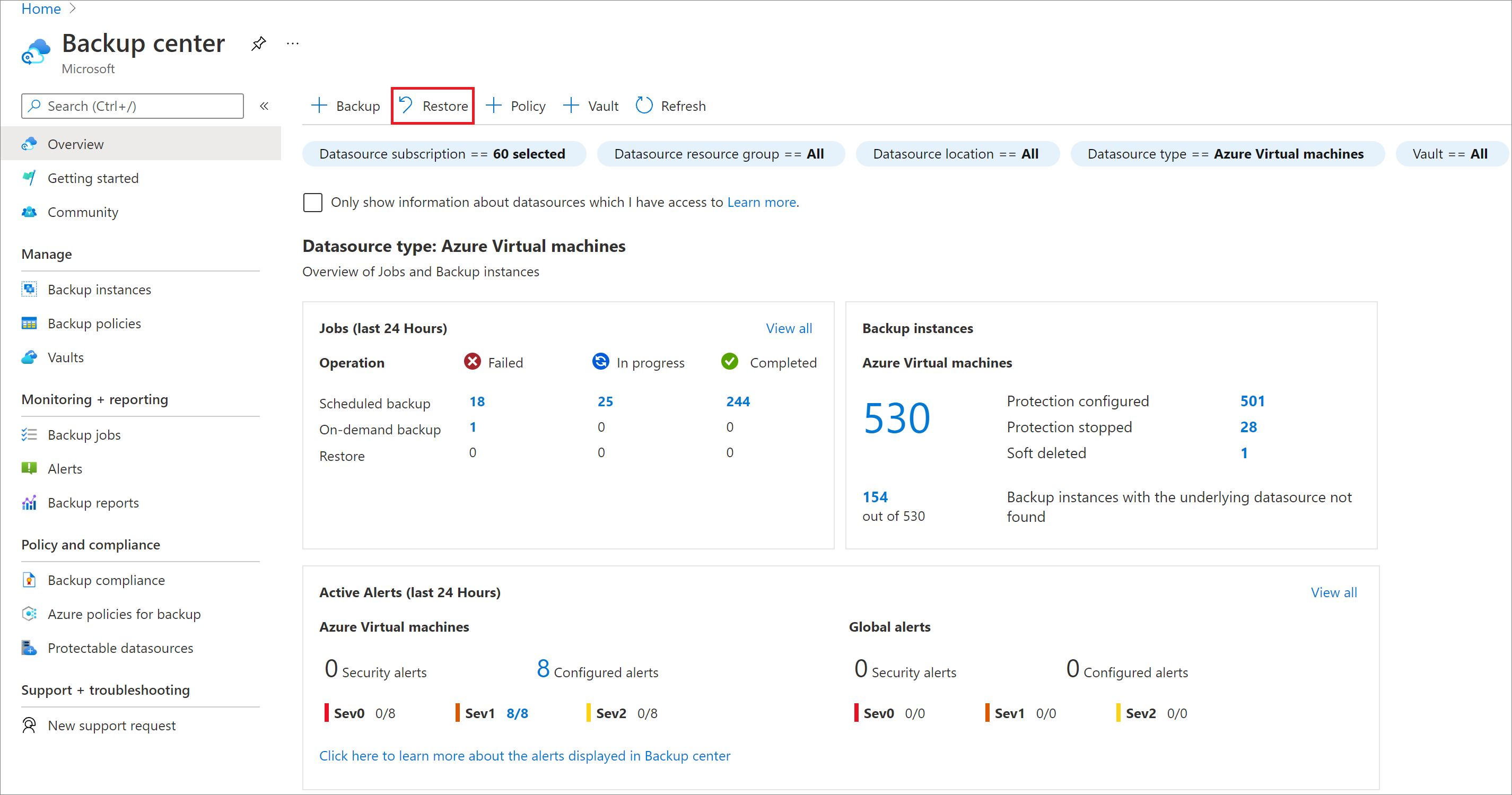
Jako typ zdroje dat vyberte SAP HANA na virtuálním počítači Azure, vyberte databázi, kterou chcete obnovit, a pak vyberte Pokračovat.
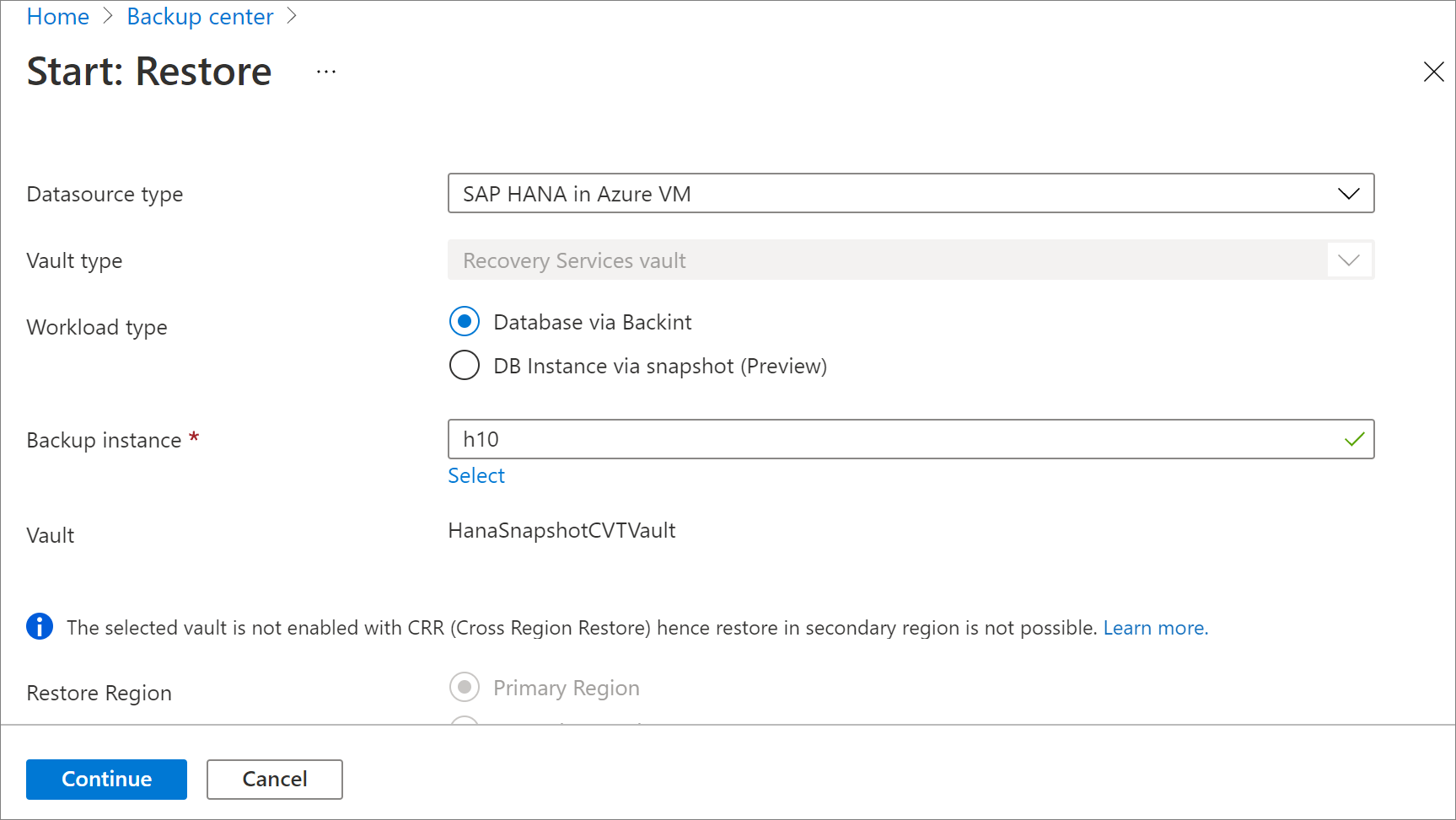
V části Konfigurace obnovení určete, kde nebo jak obnovit data:
- Alternativní umístění: Obnovte databázi do alternativního umístění a ponechte původní zdrojovou databázi.
- Přepsání databáze: Obnovte data do stejné instance SAP HANA jako původní zdroj. Tato možnost přepíše původní databázi.

Poznámka:
Během obnovy (platí pouze pro scénář front-end IP virtuální adresy/vyrovnávače zatížení), pokud se pokoušíte obnovit zálohu na cílový uzel po změně režimu HSR na samostatný nebo po přerušení režimu HSR před obnovou podle doporučení SAP, ujistěte se, že vyrovnávač zatížení je nasměrován na cílový uzel.
Ukázkové scénáře:
- Pokud v předregistračním skriptu používáte hdbuserstore set SYSTEMKEY localhost , během obnovení nebudou žádné problémy.
- Pokud je váš *hdbuserstore nastavený
SYSTEMKEY <load balancer host/ip>ve skriptu předběžné registrace a pokoušíte se obnovit zálohu do cílového uzlu, ujistěte se, že nástroj pro vyrovnávání zatížení odkazuje na cílový uzel, který je potřeba obnovit.
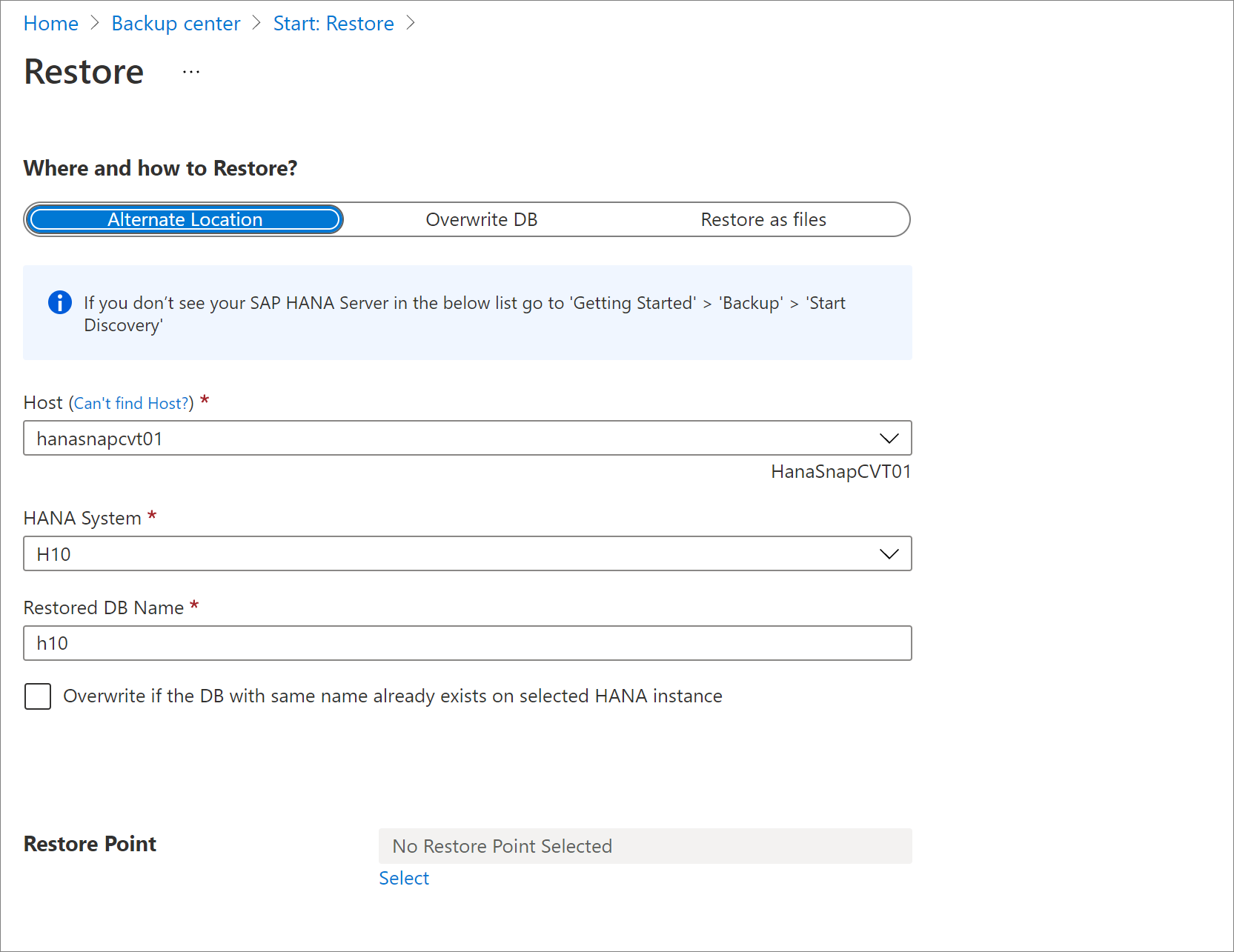
Obnovení do alternativního umístění
V podokně Obnovit v části Kde a jak provést obnovení? vyberte Alternativní umístění.
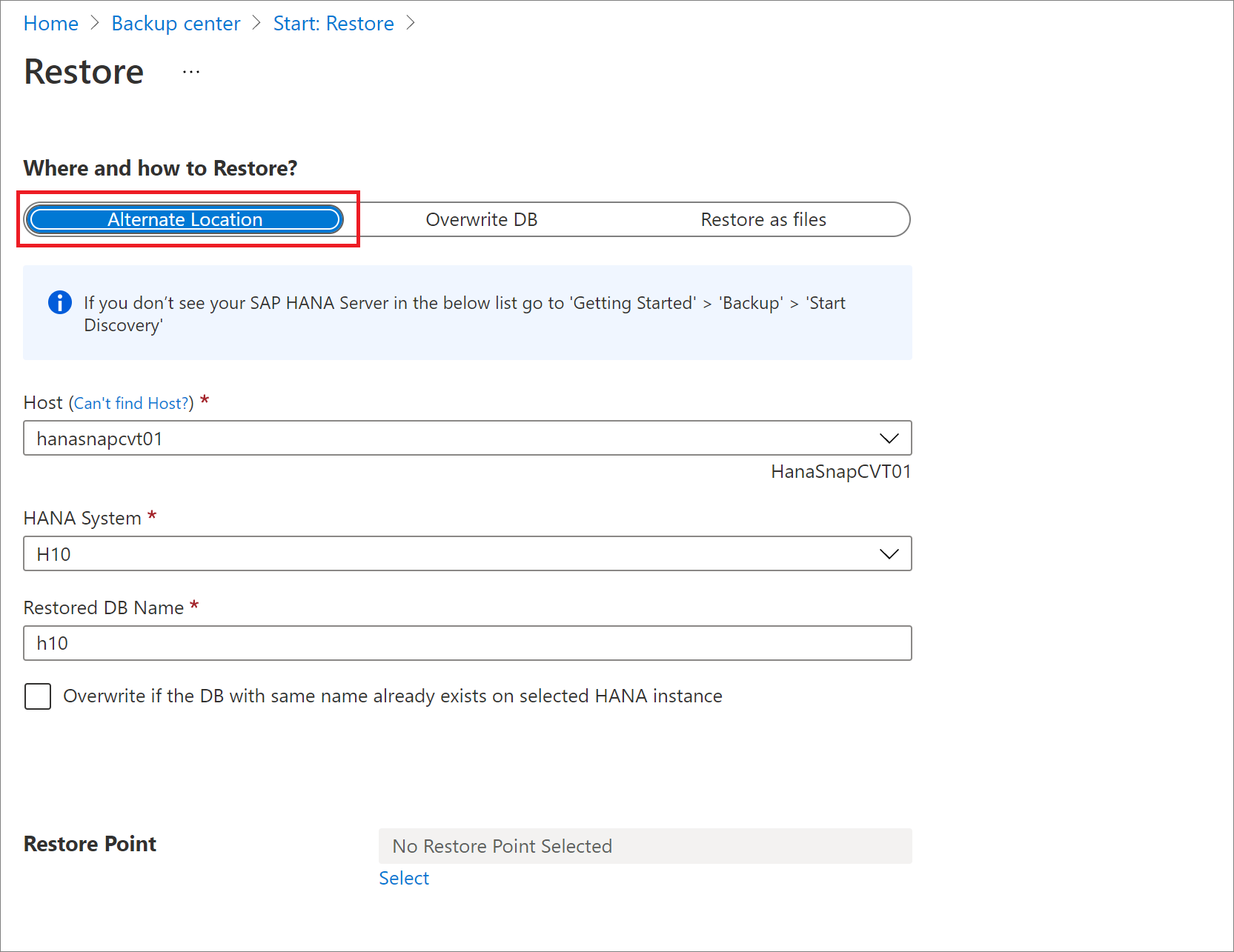
Vyberte název hostitele SAP HANA a název instance, do které chcete databázi obnovit.
Zkontrolujte, jestli je cílová instance SAP HANA připravená k obnovení, a to zajištěním připravenosti zálohování. Další informace najdete v části Předpoklady.
Do pole Obnovený název databáze zadejte název cílové databáze.
Poznámka:
Obnovení jedné databáze v kontejneru (SDC) musí postupovat podle těchto kontrol.
Pokud je to možné, zaškrtněte políčko Přepsat, pokud databáze se stejným názvem již existuje u vybrané instance HANA.
V položce Vybrat bod obnovení vyberte Protokoly (Bod v čase) pro obnovení do určitého bodu v čase. Nebo vyberte možnost Úplné a rozdílové, abyste se obnovili do určitého bodu obnovy.
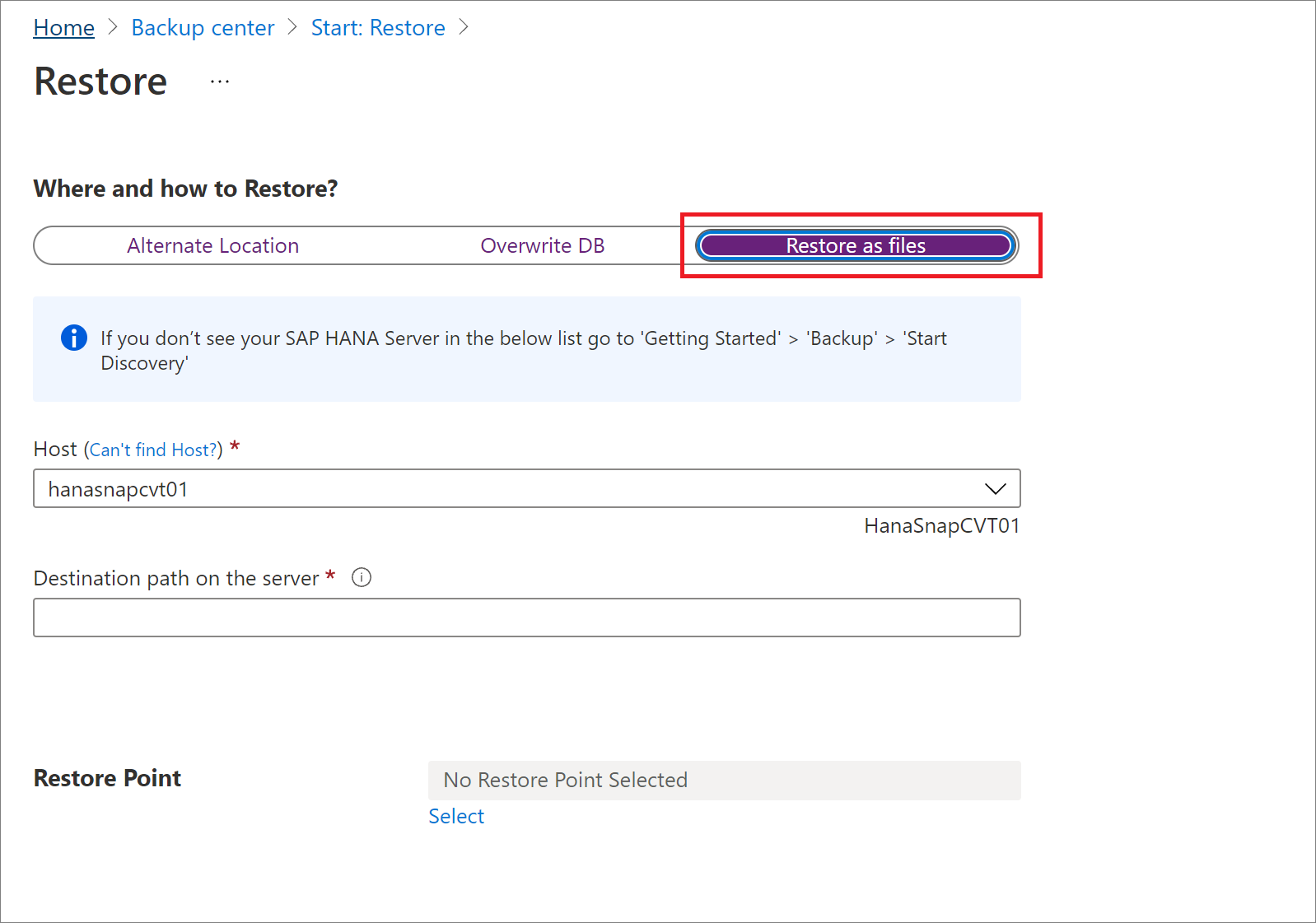
Obnovit jako soubory
Poznámka:
Obnovit jako soubory nefunguje na sdíleních CIFS, ale funguje pro NFS.
Pokud chcete zálohovaná data obnovit jako soubory místo databáze, vyberte Obnovit jako soubory. Po výpisu souborů do zadané cesty je můžete převést na jakýkoli počítač SAP HANA, ve kterém je chcete obnovit jako databázi. Vzhledem k tomu, že soubory můžete přesunout do libovolného počítače, můžete teď obnovit data napříč předplatnými a oblastmi.
V podokně Obnovit v části Kde a jak obnovit? vyberte Obnovit jako soubory.
Vyberte název hostitele nebo serveru HANA, do kterého chcete obnovit záložní soubory.
Do pole Cílová cesta na serveru zadejte cestu ke složce na serveru, který jste vybrali v předchozím kroku. Toto je umístění, kde služba vypíše všechny potřebné záložní soubory.
Vypsané soubory jsou:
- Záložní soubory databáze
- Soubory metadat JSON (pro každý zahrnutý záložní soubor)
Cesta ke sdílené síťové složce nebo cesta připojené sdílené složky Azure, která je zadaná jako cílová cesta, obvykle umožňuje snadnější přístup k těmto souborům jinými počítači ve stejné síti nebo se stejnou sdílenou složkou Azure, která je k nim připojená.
Poznámka:
Pokud chcete obnovit záložní soubory databáze ve sdílené složce Azure připojené k cílovému registrovanému virtuálnímu počítači, ujistěte se, že má kořenový účet oprávnění ke čtení a zápisu sdílené složky.
Vyberte bod obnovení, do kterého se obnoví všechny záložní soubory a složky.
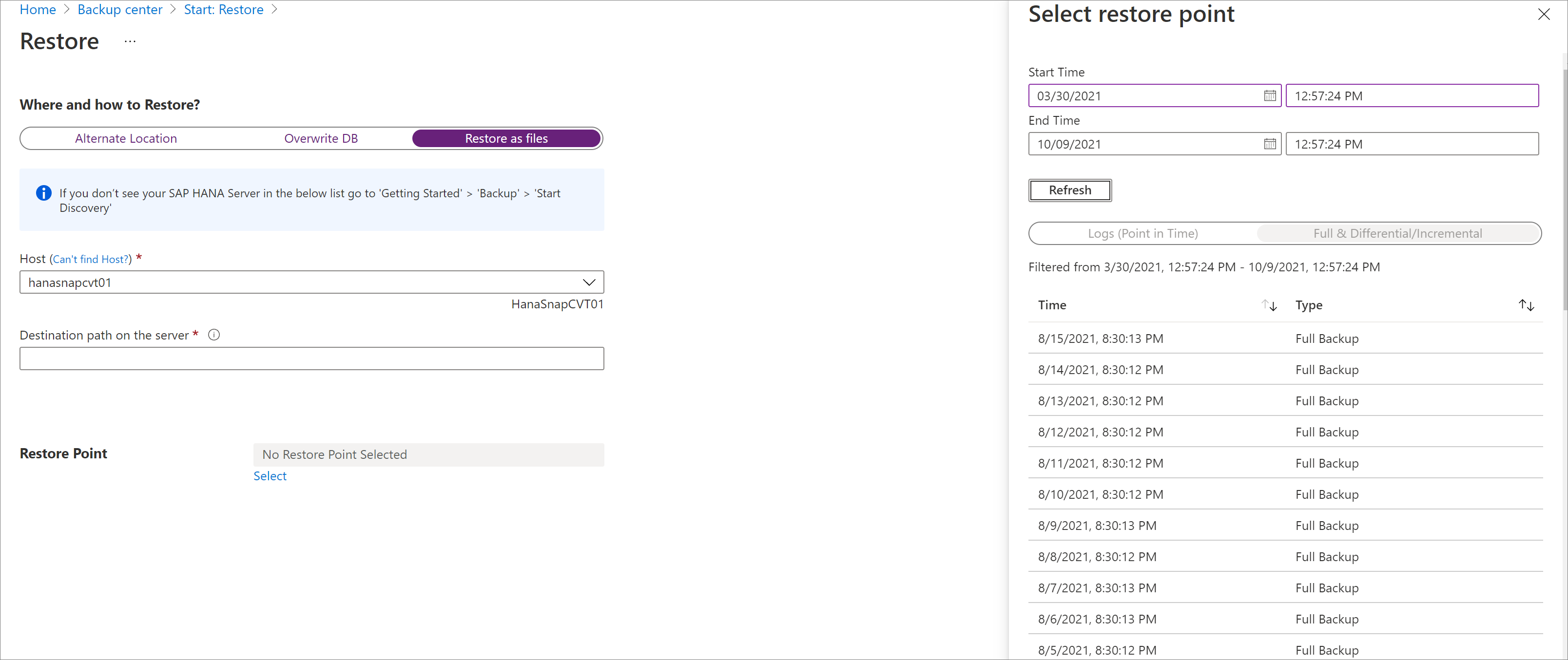
Všechny záložní soubory přidružené k vybranému bodu obnovení se uloží do cílového umístění.
V závislosti na typu bodu obnovení, který jste vybrali (
Bod v čase neboÚplné & Rozdílové ), uvidíte v cílové cestě vytvořené jednu nebo více složek. Jedna ze složek, Data_<datum a čas obnovy>, obsahuje plné zálohy, a druhá složka, Log, obsahuje logové zálohy a další zálohy (jako jsou rozdílové a přírůstkové).Poznámka:
Pokud jste vybrali možnost Obnovit k určitému bodu v čase, můžou soubory protokolu, které byly přeneseny do cílového virtuálního počítače, někdy obsahovat protokoly za hranice bodu v čase, který jste zvolili k obnovení. Azure Backup to dělá, aby se zajistilo, že jsou zálohy protokolů pro všechny služby HANA k dispozici pro konzistentní a úspěšné obnovení ke zvolenému bodu v čase.
Přesuňte obnovené soubory na server SAP HANA, kam je chcete obnovit jako databázi, a pak udělejte toto:
a. Spuštěním následujícího příkazu nastavte oprávnění ke složce nebo adresáři, kde jsou uložené záložní soubory:
chown -R <SID>adm:sapsys <directory>b) Spusťte další sadu příkazů jako
<SID>adm:su: <sid>admc) Vygenerujte soubor katalogu pro obnovení. Extrahujte BackupId ze souboru metadat JSON pro úplné zálohování, které použijete později v operaci obnovení. Ujistěte se, že úplné zálohy a zálohy protokolů (které nejsou k dispozici pro obnovení z úplné zálohy) jsou v různých složkách, a odstraňte soubory metadat JSON v těchto složkách. Běh:
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile>-
<DataFileDir>: Složka, která obsahuje úplné zálohy. -
<LogFilesDir>: Složka, která obsahuje zálohy protokolů, rozdílové zálohy a přírůstkové zálohy. Pro úplné obnovení zálohy, protože složka protokolu není vytvořená, přidejte prázdný adresář. -
<PathToPlaceCatalogFile>: Složka, do které se musí umístit vygenerovaný soubor katalogu.
d. Obnovení můžete provést pomocí nově generovaného souboru katalogu prostřednictvím hana Studia nebo spuštěním dotazu na obnovení nástroje SAP HANA HDBSQL s tímto nově vygenerovaným katalogem. Tady jsou uvedené dotazy HDBSQL:
Pokud chcete otevřít výzvu HDBSQL, spusťte následující příkaz:
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDBObnovit do určitého bodu v čase:
Pokud vytváříte novou obnovenou databázi, spuštěním příkazu HDBSQL vytvořte novou databázi
<DatabaseName>a pak pomocí příkazuALTER SYSTEM STOP DATABASE <db> IMMEDIATEzastavte databázi pro obnovení. Pokud ale obnovujete pouze existující databázi, zastavte databázi spuštěním příkazu HDBSQL.Potom spuštěním následujícího příkazu obnovte databázi:
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE-
<DatabaseName>: Název nové databáze nebo existující databáze, kterou chcete obnovit. -
<Timestamp>: Přesné časové razítko pro obnovení do konkrétního okamžiku v čase. -
<DatabaseName@HostName>: Název databáze, jejíž záloha se používá k obnovení, a název hostitele nebo serveru SAP HANA, na kterém se tato databáze nachází. MožnostUSING SOURCE <DatabaseName@HostName>určuje, že záloha dat (použitá k obnovení) je databáze s jiným identifikátorem SID nebo názvem než cílový počítač SAP HANA. Není nutné ji zadávat pro obnovení, která se provádí na stejném serveru HANA, ze kterého se provádí zálohování. -
<PathToGeneratedCatalogInStep3>: Cesta k souboru katalogu, který byl vygenerován v kroku c. -
<DataFileDir>: Složka, která obsahuje úplné zálohy. -
<LogFilesDir>: Složka obsahující zálohy protokolů, rozdílové zálohování a přírůstkové zálohování (pokud existuje). -
<BackupIdFromJsonFile>: BackupId, který byl extrahován v kroku c.
-
Jak obnovit z konkrétní úplné nebo rozdílové zálohy:
Pokud vytváříte novou obnovenou databázi, spuštěním příkazu HDBSQL vytvořte novou databázi
<DatabaseName>a pak pomocí příkazuALTER SYSTEM STOP DATABASE <db> IMMEDIATEzastavte databázi pro obnovení. Pokud ale obnovujete pouze existující databázi, zastavte databázi spuštěním příkazu HDBSQL:RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG-
<DatabaseName>: Název nové databáze nebo existující databáze, kterou chcete obnovit. -
<Timestamp>: Přesné časové razítko pro obnovení do konkrétního okamžiku v čase. -
<DatabaseName@HostName>: Název databáze, jejíž záloha se používá k obnovení, a název hostitele nebo serveru SAP HANA, na kterém se tato databáze nachází. MožnostUSING SOURCE <DatabaseName@HostName>určuje, že záloha dat (použitá k obnovení) je databáze s jiným identifikátorem SID nebo názvem než cílový počítač SAP HANA. Proto není nutné zadávat pro obnovení, která se provádí na stejném serveru HANA, z kterého bylo zálohování provedeno. -
<PathToGeneratedCatalogInStep3>: Cesta k souboru katalogu, který byl vygenerován v kroku c. -
<DataFileDir>: Složka, která obsahuje úplné zálohy. -
<LogFilesDir>: Složka obsahující zálohy protokolů, rozdílové zálohování a přírůstkové zálohování (pokud existuje). -
<BackupIdFromJsonFile>: BackupId, který byl extrahován v kroku c.
-
Obnovení pomocí ID zálohy:
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILEPříklady:
Obnovení systému SAP HANA na stejném serveru:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILEObnovení tenanta SAP HANA na stejném serveru:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILEObnovení SYSTÉMU SAP HANA na jiném serveru:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILEObnovení tenanta SAP HANA na jiném serveru:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE
-

Částečné obnovení jako soubory
Služba Azure Backup rozhoduje o řetězu souborů, které se mají během obnovení stahovat jako soubory. Existují ale scénáře, kdy nebudete chtít znovu stáhnout celý obsah.
Můžete mít například zálohovací politiku týdenních úplných záloh, denní diferenciální zálohy a protokoly a už jste stáhli soubory pro konkrétní diferenciál. Zjistili jste, že toto není správný bod obnovení, a rozhodli jste se stáhnout diferenciální data následujícího dne. Teď potřebujete jenom rozdílový soubor, protože už máte počáteční úplné zálohování. Díky částečnému obnovení jako soubory, které poskytuje Azure Backup, teď můžete úplné zálohování vyloučit ze stahovacího řetězce a stáhnout pouze rozdílovou zálohu.
Vyloučení typů záložních souborů
ExtensionSettingOverrides.json je soubor JSON (JavaScript Object Notation), který obsahuje přepsání pro více nastavení služby Azure Backup pro SQL. Chcete-li provést částečné obnovení jako operace se soubory, musíte přidat nové pole JSON . RecoveryPointsToBeExcludedForRestoreAsFiles Toto pole obsahuje řetězcovou hodnotu, která označuje, které typy bodů obnovení by měly být vyloučeny v další operaci obnovení jako operace se soubory .
Na cílovém počítači, na kterém se mají soubory stahovat, přejděte do složky opt/msawb/bin .
Pokud ještě neexistuje, vytvořte nový soubor JSON s názvem ExtensionSettingOverrides.JSON.
Přidejte následující pár klíč-hodnota JSON:
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }Změňte oprávnění a vlastnictví souboru:
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonNevyžaduje se žádné restartování žádné služby. Služba Azure Backup se pokusí vyloučit typy zálohování v řetězu obnovení, jak je uvedeno v tomto souboru.
RecoveryPointsToBeExcludedForRestoreAsFiles přijímá pouze konkrétní hodnoty, které označují body obnovení, které mají být vyloučeny během obnovení. Pro SAP HANA jsou tyto hodnoty:
-
ExcludeFull. Jiné typy zálohování, jako jsou rozdílové, přírůstkové a protokoly, se stáhnou, pokud se nacházejí v řetězci bodů obnovení. -
ExcludeFullAndDifferential. Jiné typy zálohování, jako jsou přírůstkové a protokoly, se stáhnou, pokud se nacházejí v řetězu bodů obnovení. -
ExcludeFullAndIncremental. Další typy záloh, jako jsou rozdílové zálohy a protokoly, budou staženy, pokud jsou přítomny v řetězci bodů obnovení. -
ExcludeFullAndDifferentialAndIncremental. Jiné typy zálohování, jako jsou protokoly, se stáhnou, pokud se nacházejí v řetězu bodů obnovení.
Obnovení k určitému časovému okamžiku
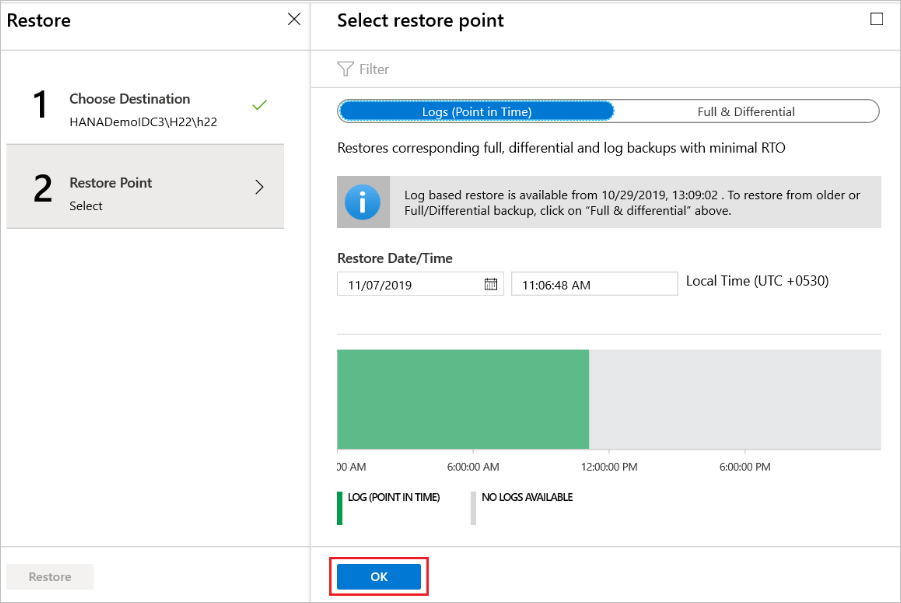
Pokud jste jako typ obnovení vybrali Protokoly (bod v čase), postupujte takto:
Vyberte bod obnovení z grafu protokolu a pak vyberte OK a zvolte bod obnovení.
V nabídce Obnovit vyberte Obnovit a spusťte úlohu obnovení.
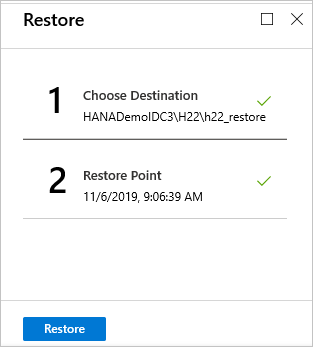
Průběh obnovení můžete sledovat v oblasti Oznámení nebo ho sledovat tak , že v nabídce databáze vyberete Úlohy obnovení .

Obnovení do konkrétního bodu obnovy
Pokud jste jako typ obnovení vybrali možnost Full &Differential , postupujte takto:
Ze seznamu vyberte bod obnovení a pak vyberte OK a zvolte bod obnovení.
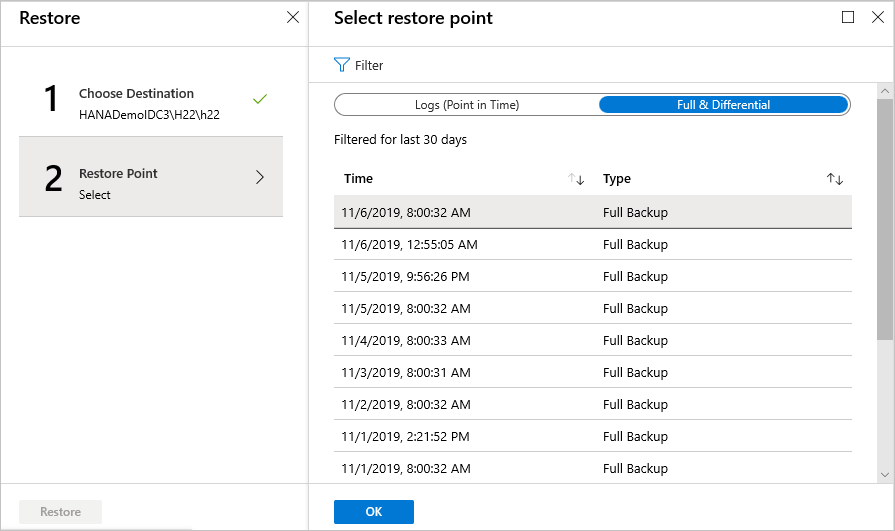
V nabídce Obnovit vyberte Obnovit a spusťte úlohu obnovení.
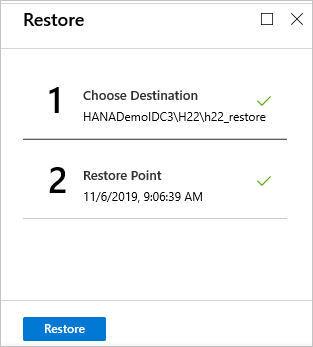
Průběh obnovení můžete sledovat v oblasti Oznámení nebo ho sledovat tak , že v nabídce databáze vyberete Úlohy obnovení .
Poznámka:
Při obnově v rámci Více databázových kontejnerů (MDC), po obnovení systémové databáze na cílovou instanci, musíte znovu spustit skript předběžné registrace. Následné obnovení databáze tenanta bude úspěšné. Další informace najdete v tématu Řešení potíží s obnovením více databází kontejnerů.
Obnovení napříč regiony
Jako jednu z možností obnovení umožňuje obnovení mezi oblastmi (CRR) obnovit databáze SAP HANA hostované na virtuálních počítačích Azure v sekundární oblasti, což je spárovaná oblast Azure.
Pokud chcete začít používat tuto funkci, přečtěte si téma Nastavení obnovení mezi oblastmi.
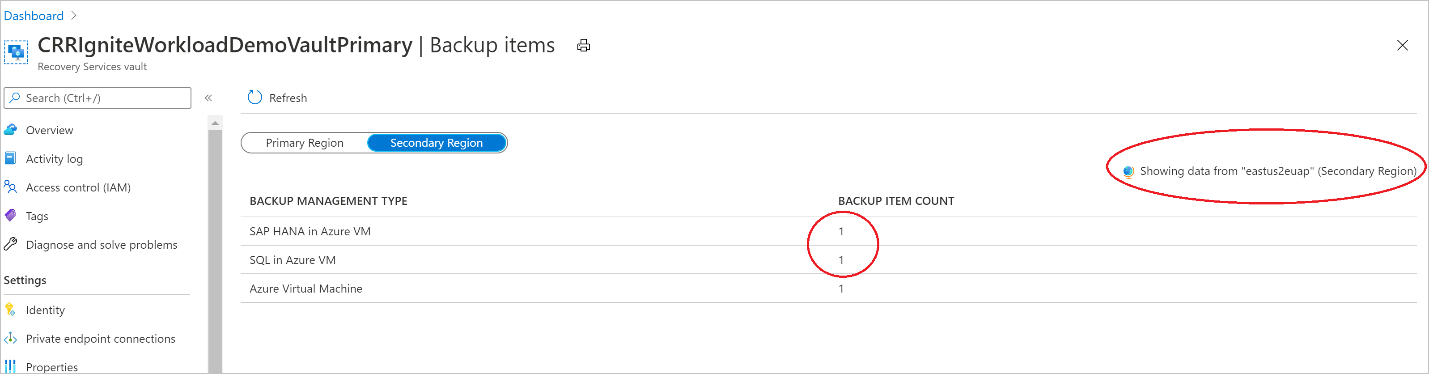
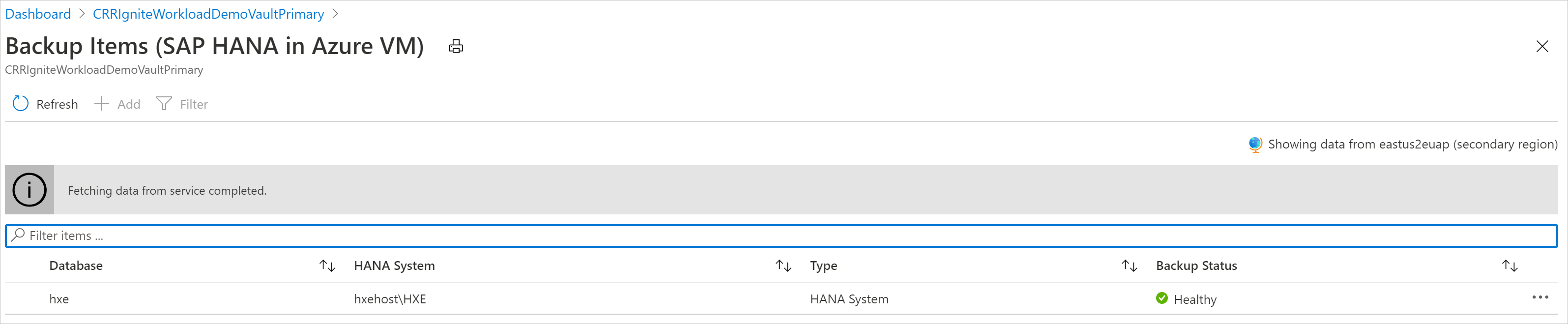
Zobrazení zálohovaných položek v sekundární oblasti
Pokud je povolený CRR, můžete zobrazit zálohované položky v sekundární oblasti.
- Na webu Azure Portal přejděte do trezoru služby Recovery Services a pak vyberte Zálohované položky.
- Vyberte sekundární oblast pro zobrazení položek v sekundární oblasti.
Poznámka:
V seznamu se zobrazují jenom typy správy záloh, které podporují funkci CRR. V současné době je povolena pouze podpora obnovení dat sekundární oblasti do sekundární oblasti.
Obnovení v sekundární oblasti
Uživatelské prostředí obnovení sekundární oblasti se podobá uživatelskému prostředí obnovení primární oblasti. Když nakonfigurujete podrobnosti v podokně Konfigurace obnovení, budete vyzváni k zadání pouze parametrů sekundární oblasti. Trezor by měl existovat v sekundární oblasti a server SAP HANA by se měl zaregistrovat do trezoru v sekundární oblasti.
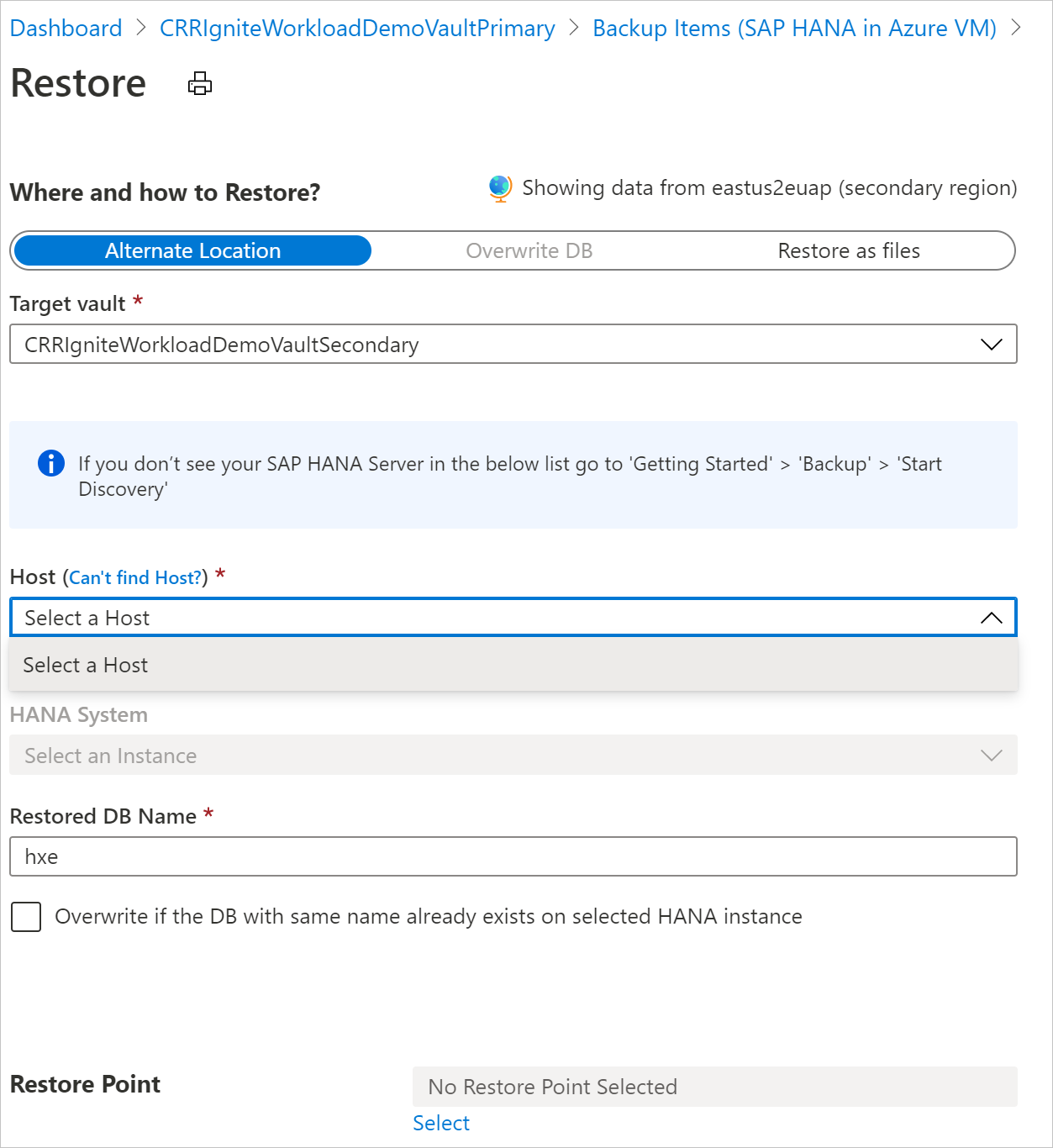
Poznámka:
- Po aktivaci obnovení a ve fázi přenosu dat není možné úlohu obnovení zrušit.
- Role a úroveň přístupu potřebné pro provedení operace obnovení mezi regiony jsou role Operátora zálohování v předplatném a přístup Přispěvatele (zápis) na zdrojovém a cílovém virtuálním počítači. Pokud chcete zobrazit úlohy zálohování, čtenář služby Backup je minimální oprávnění vyžadovaná v předplatném.
- Cíl bodu obnovení (RPO) pro data zálohování, která mají být k dispozici v sekundární oblasti, je 12 hodin. Proto když zapnete CRR, RPO pro sekundární oblast je 12 hodin + doba trvání protokolování frekvence (což lze nastavit na minimálně 15 minut).
Seznamte se s minimálními požadavky na role pro obnovení napříč oblastmi.
Monitorování obnovovacích úloh v sekundární oblasti
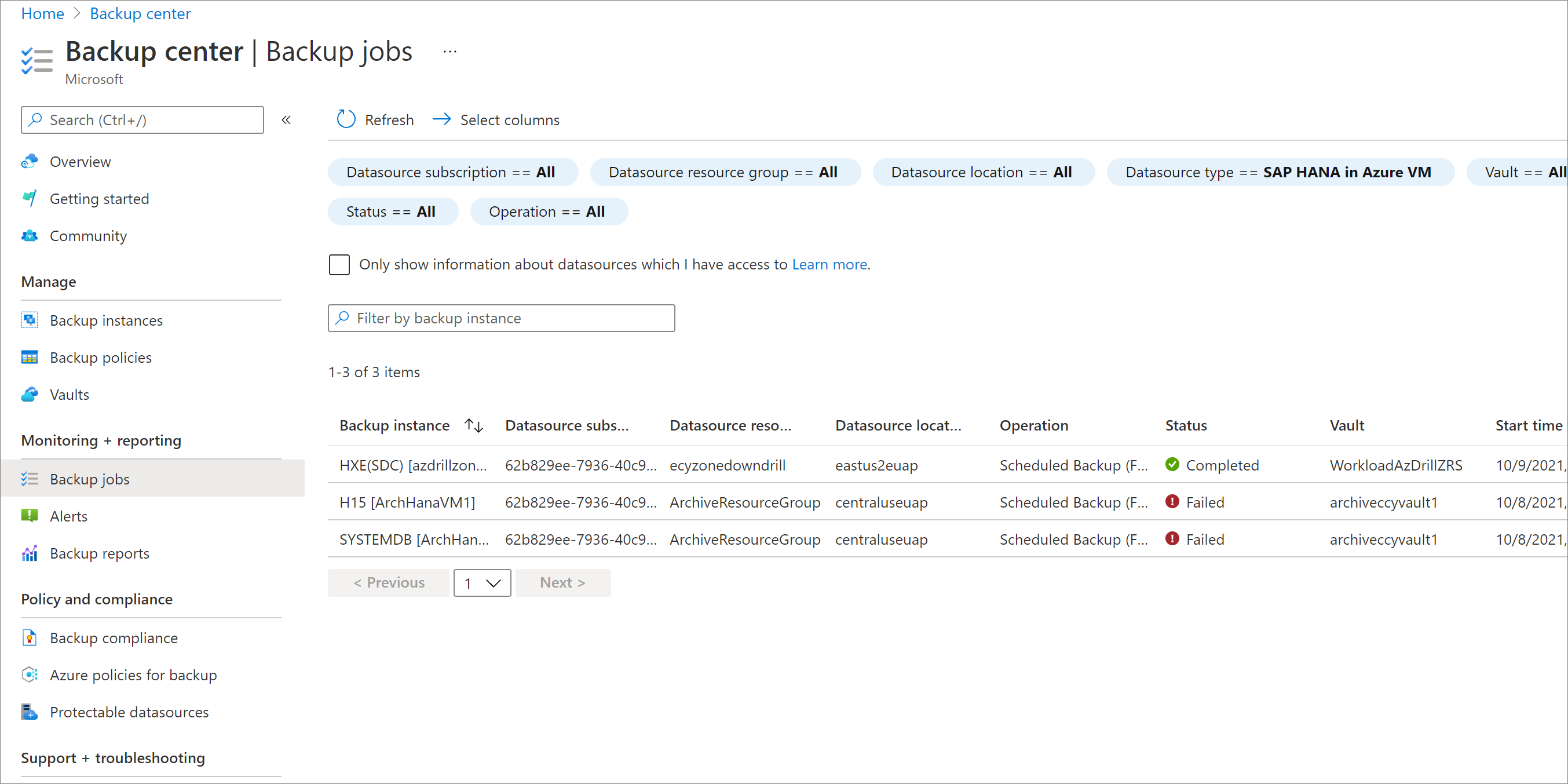
Na webu Azure Portal přejděte do Centra zálohování a pak vyberte Úlohy zálohování.
Pokud chcete zobrazit úlohy v sekundární oblasti, použijte filtr Operace pro CrossRegionRestore.

Obnovení napříč předplatnými
Azure Backup teď umožňuje obnovit databázi SAP HANA do libovolného předplatného (podle následujících požadavků Azure RBAC) z bodu obnovení. Ve výchozím nastavení se Azure Backup obnoví do stejného předplatného, ve kterém jsou dostupné body obnovení.
S obnovením mezi předplatnými (CSR) máte flexibilitu obnovení do libovolného předplatného a jakéhokoli trezoru v rámci vašeho tenanta, pokud jsou k dispozici oprávnění k obnovení. Ve výchozím nastavení je csr povolené pro všechny trezory služby Recovery Services (existující a nově vytvořené trezory).
Poznámka:
- Obnovení napříč předplatnými můžete aktivovat z trezoru služby Recovery.
- CSR se podporuje jenom pro streamování a zálohování založené na backintu a nepodporuje se pro zálohování založené na snímcích.
- Obnovení mezi oblastmi (CRR) s CSR není podporováno.
Obnovení přenosu mezi předplatnými do aktivovaného trezoru s privátním koncovým bodem
Provedení obnovení napříč předplatnými do trezoru s aktivovaným soukromým koncovým bodem:
- Ve zdrojovém trezoru služby Recovery Services přejděte na kartu Sítě.
- Přejděte do části Privátní přístup a vytvořte privátní koncové body.
- Vyberte předplatné cílového trezoru, ve kterém chcete provést obnovení.
- V části Virtuální síť vyberte virtuální síť cílového virtuálního počítače, který chcete obnovit v rámci předplatného.
- Vytvořte privátní koncový bod a aktivujte proces obnovení.
Požadavky Azure RBAC
| Typ operace | Operátor zálohování | Úložiště služeb pro obnovení | Alternativní operátor |
|---|---|---|---|
| Obnovení databáze nebo obnovení jako souborů | Virtual Machine Contributor |
Zdrojový virtuální počítač, který byl zálohován | Místo předdefinované role můžete zvážit vlastní roli, která má následující oprávnění: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
Cílový virtuální počítač, ve kterém se databáze obnoví, nebo se vytvoří soubory. | Místo předdefinované role můžete zvážit vlastní roli, která má následující oprávnění: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
Cílový trezor služby Recovery Services |
Ve výchozím nastavení je v trezoru služby Recovery Services povolený CSR. Pokud chcete aktualizovat nastavení obnovení trezoru služby Recovery Services, přejděte do části Vlastnosti>Obnovení mezi předplatnými a proveďte požadované změny.

Obnovení mezi různými předplatnými pomocí Azure CLI
az backup vault create
Přidejte parametr cross-subscription-restore-state , který umožňuje nastavit stav CSR trezoru během vytváření a aktualizace trezoru.
az backup recoveryconfig show
Přidejte parametr --target-subscription-id, který vám umožní při aktivaci obnovení mezi předplatnými poskytnout cílové předplatné jako vstup pro zdroje dat SQL nebo HANA.
Příklad:
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}