Osvědčené postupy pro projekty datových věd s využitím analýz v cloudovém měřítku v Azure
Tyto osvědčené postupy doporučujeme pro použití analýz na úrovni cloudu v Microsoft Azure k zprovoznění projektů datových věd.
Vývoj šablony
Vytvořte šablonu, která sečte sadu služeb pro vaše projekty datových věd. Použijte šablonu, která seskupuje sadu služeb, které pomáhají zajistit konzistenci napříč různými případy použití týmů pro datové vědy. Doporučujeme vytvořit konzistentní podrobný plán ve formě úložiště šablon. Toto úložiště můžete použít pro různé projekty datových věd v rámci vašeho podniku, které vám pomůžou zkrátit dobu nasazení.
Pokyny pro šablony datových věd
Vytvořte šablonu datových věd pro vaši organizaci s následujícími pokyny:
Vyvíjejte sadu šablon infrastruktury jako kódu (IaC) pro nasazení pracovního prostoru Azure Machine Učení. Zahrňte prostředky, jako je trezor klíčů, účet úložiště, registr kontejneru a Přehledy aplikace.
Do těchto šablon zahrňte nastavení úložišť dat a cílových výpočetních prostředků, jako jsou výpočetní instance, výpočetní clustery a Azure Databricks.
Osvědčené postupy pro nasazení
V reálném čase
- Zahrnutí nasazení služby Azure Data Factory nebo Azure Synapse do šablon a služeb Azure Cognitive Services
- Šablony by měly poskytovat všechny potřebné nástroje pro provádění fáze zkoumání datových věd a počáteční operacionalizaci modelu.
Důležité informace o počátečním nastavení
V některých případech můžou datoví vědci ve vaší organizaci vyžadovat prostředí pro rychlou analýzu podle potřeby. Tato situace je běžná v případě, že projekt datových věd není formálně nastavený. Například projektový manažer, nákladový kód nebo nákladové středisko, které může být nutné pro křížové účtování v Rámci Azure, nemusí chybět, protože chybějící prvek potřebuje schválení. Uživatelé ve vaší organizaci nebo týmu můžou potřebovat přístup k prostředí datových věd, aby porozuměli datům a mohli vyhodnotit proveditelnost projektu. Některé projekty také nemusí vyžadovat úplné prostředí datových věd kvůli malému počtu datových produktů.
V jiných případech může být nutný úplný projekt datových věd s vyhrazeným prostředím, řízením projektů, kódem nákladů a nákladovým centrem. Úplné projekty datových věd jsou užitečné pro více členů týmu, kteří chtějí spolupracovat, sdílet výsledky a potřebují zprovoznit modely, jakmile bude fáze zkoumání úspěšná.
Proces nastavení
Šablony by se měly nasadit na základě jednotlivých projektů po jejich nastavení. Každý projekt by měl obdržet alespoň dvě instance pro oddělení vývojových a produkčních prostředí. V produkčním prostředí by neměl mít přístup žádná jednotlivá osoba a vše by se mělo nasadit prostřednictvím kanálů kontinuální integrace nebo průběžného vývoje a instančního objektu. Tyto principy produkčního prostředí jsou důležité, protože azure machine Učení neposkytuje podrobný model řízení přístupu na základě role v rámci pracovního prostoru. Uživatelský přístup nemůžete omezit na konkrétní sadu experimentů, koncových bodů nebo kanálů.
Stejná přístupová práva se obvykle vztahují na různé typy artefaktů. Je důležité oddělit vývoj od produkčního prostředí, aby se zabránilo odstranění produkčních kanálů nebo koncových bodů v pracovním prostoru. Spolu se šablonou je potřeba vytvořit proces, který datovým týmům poskytne možnost požadovat nová prostředí.
Pro jednotlivé projekty doporučujeme nastavit různé služby AI, jako je Azure Cognitive Services. Když nastavíte různé služby AI na základě jednotlivých projektů, nasazení probíhají pro každou skupinu prostředků datového produktu. Tato zásada vytváří jasné oddělení od pohledu přístupu k datům a snižuje riziko neoprávněného přístupu k datům nesprávnými týmy.
Scénář streamování
V případě případů použití v reálném čase a streamování by se nasazení měla testovat na downsized Azure Kubernetes Service (AKS). Testování může být ve vývojovém prostředí, abyste před nasazením do produkční služby AKS nebo služby Aplikace Azure pro kontejnery ušetřili náklady. Měli byste provést jednoduché vstupní a výstupní testy, abyste měli jistotu, že služby reagují podle očekávání.
V dalším kroku můžete modely nasadit do požadované služby. Tento cílový výpočetní objekt pro nasazení je jediný, který je obecně dostupný a doporučený pro produkční úlohy v clusteru AKS. Tento krok je důležitější v případě, že je vyžadována podpora grafického procesoru (GPU) nebo programovatelného hradlového pole. Další nativní možnosti nasazení, které podporují tyto požadavky na hardware, nejsou v současné době dostupné ve službě Azure Machine Učení.
Azure Machine Učení vyžaduje mapování 1:1 na clustery AKS. Každé nové připojení k pracovnímu prostoru Azure Machine Učení přeruší předchozí připojení mezi AKS a Učení Azure Machine. Po zmírnění tohoto omezení doporučujeme nasadit centrální clustery AKS jako sdílené prostředky a připojit je k příslušným pracovním prostorům.
Další centrální testovací instance AKS by se měla hostovat, pokud by se zátěžové testy měly provést před přesunutím modelu do produkční služby AKS. Testovací prostředí by mělo poskytovat stejný výpočetní prostředek jako produkční prostředí, aby se zajistilo, že výsledky budou co nejvíce podobné produkčnímu prostředí.
Scénář služby Batch
Ne všechny případy použití vyžadují nasazení clusteru AKS. Případ použití nepotřebuje nasazení clusteru AKS, pokud velké objemy dat potřebují bodování pravidelně nebo jsou založené na události. Velké objemy dat můžou být například založeny na tom, kdy se data zahodí do konkrétního účtu úložiště. Kanály azure machine Učení a výpočetní clustery Azure Machine Učení by se měly používat pro nasazení během těchto typů scénářů. Tyto kanály by se měly orchestrovat a spouštět ve službě Data Factory.
Identifikace správných výpočetních prostředků
Před nasazením modelu ve službě Azure Machine Učení do AKS musí uživatel zadat prostředky, jako je procesor, paměť RAM a GPU, které by se měly přidělit příslušnému modelu. Definování těchto parametrů může být složitý a zdlouhavý proces. Abyste mohli identifikovat dobrou sadu parametrů, musíte provést zátěžové testy s různými konfiguracemi. Tento proces můžete zjednodušit pomocí funkce profilace modelů na počítači Azure Učení, což je dlouhotrvající úloha, která testuje různé kombinace přidělení prostředků a používá identifikovanou latenci a dobu odezvy (RTT) k doporučení optimální kombinace. Tyto informace můžou pomoct skutečnému nasazení modelu v AKS.
K bezpečné aktualizaci modelů ve službě Azure Machine Učení by týmy měly použít řízenou funkci zavedení (Preview) k minimalizaci výpadků a zachování konzistentního koncového bodu REST modelu.
Osvědčené postupy a pracovní postup pro MLOps
Zahrnutí ukázkového kódu do úložišť datových věd
Projekty datových věd můžete zjednodušit a urychlit, pokud mají vaše týmy určité artefakty a osvědčené postupy. Doporučujeme vytvářet artefakty, které můžou všechny týmy datových věd používat při práci se službou Azure Machine Učení a příslušnými nástroji datového prostředí. Datoví a technici strojového učení by měli vytvářet a poskytovat artefakty.
Mezi tyto artefakty by měly patřit:
Ukázkové poznámkové bloky, které ukazují, jak:
- Načtení, připojení a práce s datovými produkty
- Protokolovat metriky a parametry
- Odešlete trénovací úlohy do výpočetních clusterů.
Artefakty vyžadované pro operacionalizaci:
- Ukázkové kanály azure machine Učení
- Ukázkové služby Azure Pipelines
- Další skripty potřebné ke spouštění kanálů
Dokumentace
Použití dobře navržených artefaktů k zprovoznění kanálů
Artefakty můžou urychlit fáze zkoumání a zprovoznění projektů datových věd. Strategie forkování DevOps může pomoct škálovat tyto artefakty napříč všemi projekty. Vzhledem k tomu, že toto nastavení podporuje použití Gitu, můžou uživatelé a celkový proces automatizace využívat poskytnuté artefakty.
Tip
Ukázkové kanály Azure Machine Učení by měly být vytvořené pomocí sady SDK (Software Developer Kit) Pythonu nebo založeného na jazyce YAML. Nové prostředíYAchm platformě YAML bude v budoucnu více než budoucí, Učení protože produktový tým Produktový tým Azure Machine Učení je přesvědčený, že YAML bude sloužit jako jazyk definice pro všechny artefakty v rámci služby Azure Machine Učení.
Ukázkové kanály pro každý projekt nefungují, ale dají se použít jako směrný plán. Ukázkové kanály můžete upravit pro projekty. Kanál by měl zahrnovat nejdůležitější aspekty každého projektu. Kanál může například odkazovat na cílový výpočetní objekt, referenční datové produkty, definovat parametry, definovat vstupy a definovat kroky provádění. Stejný proces by se měl provést pro Azure Pipelines. Azure Pipelines by také měla používat sadu Azure Machine Učení SDK nebo rozhraní příkazového řádku.
Kanály by měly ukázat, jak:
- Připojení do pracovního prostoru z kanálu DevOps.
- Zkontrolujte, jestli je k dispozici požadovaný výpočetní výkon.
- Odešlete úlohu.
- Zaregistrujte a nasaďte model.
Artefakty nejsou vhodné pro všechny projekty po celou dobu a můžou vyžadovat přizpůsobení, ale základ může urychlit operacionalizaci a nasazení projektu.
Strukturování úložiště MLOps
Můžete mít situace, kdy uživatelé ztratí přehled o tom, kde můžou najít a ukládat artefakty. Abyste se těmto situacím vyhnuli, měli byste požádat o více času na komunikaci a vytvoření struktury složek nejvyšší úrovně pro standardní úložiště. Všechny projekty by měly dodržovat strukturu složek.
Poznámka:
Koncepty uvedené v této části je možné použít v místních prostředích, amazon web services, Palantir a Azure.
Navrhovaná struktura složek nejvyšší úrovně pro úložiště MLOps (operace strojového učení) je znázorněná v následujícím diagramu:
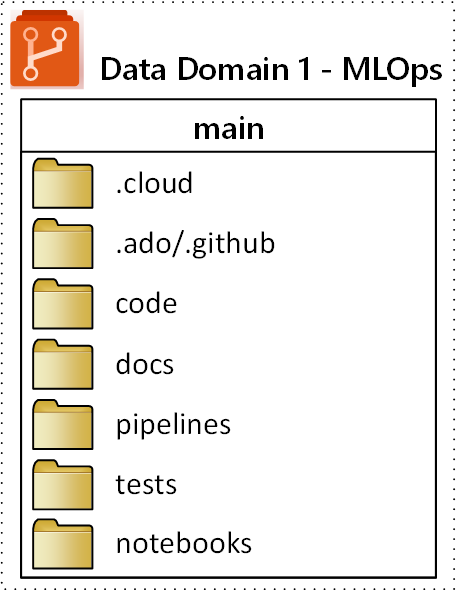
Pro každou složku v úložišti platí následující účely:
| Složka | Účel |
|---|---|
.cloud |
Uložte kód a artefakty specifické pro cloud do této složky. Artefakty zahrnují konfigurační soubory pro pracovní prostor Učení Azure, včetně definic cílových výpočetních prostředků, úloh, registrovaných modelů a koncových bodů. |
.ado/.github |
Ukládejte artefakty Azure DevOps nebo GitHubu, jako jsou kanály YAML nebo vlastníci kódu, do této složky. |
code |
Do této složky zahrňte skutečný kód vyvinutý jako součást projektu. Tato složka může obsahovat balíčky Pythonu a některé skripty, které se používají pro příslušné kroky kanálu strojového učení. Doporučujeme oddělit jednotlivé kroky, které je potřeba udělat v této složce. Mezi běžné kroky patří předběžné zpracování, trénování modelu a registrace modelu. Definujte závislosti, jako jsou závislosti Conda, image Dockeru nebo jiné pro každou složku. |
docs |
Tuto složku použijte pro účely dokumentace. Tato složka ukládá soubory a obrázky Markdownu, které popisují projekt. |
pipelines |
Ukládejte definice kanálů Azure Machine Učení v YAML nebo Pythonu v této složce. |
tests |
Zapisujte testy jednotek a integrace, které je potřeba spustit, aby se zjistily chyby a problémy v rané fázi projektu v této složce. |
notebooks |
Oddělte poznámkové bloky Jupyter od skutečného projektu Pythonu s touto složkou. Ve složce by měl mít každý jednotlivec podsložku, která by se měla vrátit se změnami jejich poznámkových bloků a zabránit konfliktům při slučování Gitu. |
Další krok
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro