Použití Azure Databricks v rámci analýzy v cloudovém měřítku v Azure
Azure Databricks je platforma pro analýzu dat optimalizovaná pro platformu Microsoft Azure Cloud Services. Azure Databricks nabízí dvě prostředí pro vývoj aplikací náročných na data:
Azure Databricks SQL, který umožňuje spouštět rychlé ad hoc dotazy SQL na datové jezero.
Azure Databricks Datová Věda & Engineering (někdy označované jako pracovní prostor) je analytická platforma založená na Apache Sparku. Je integrovaná s Azure, která poskytuje nastavení jedním kliknutím, zjednodušené pracovní postupy a interaktivní pracovní prostor, který umožňuje spolupráci mezi datovými inženýry, datovými vědci a inženýry strojového učení.
V případě analýzy v cloudu se zaměříme na Azure Databricks Datová Věda & Engineering.
Přehled
Pro každou cílovou zónu dat, kterou nasadíte, máte možnost nasadit dva sdílené pracovní prostory. Jeden pro příjem dat a druhý pro analýzu.
- Technický pracovní prostor Azure Databricks pro příjem a zpracování se připojí k Azure Data Lake prostřednictvím instančních objektů Azure. Označuje se jako nezávislá na příjmu dat.
- Pracovní prostor analýzy Azure Databricks je možné zřídit pro všechny datové vědce a datové provozní týmy. Tento pracovní prostor by se připojil k Azure Data Lake pomocí předávacího ověřování Microsoft Entra. V cílové zóně dat sdílíte analýzu Azure Databricks a pracovní prostor datových věd se všemi uživateli, kteří mají přístup k pracovnímu prostoru.
Pokud máte automatizovaný modul pro příjem dat, pracovní prostor přípravy Azure Databricks používá instanci služby Azure Key Vault vytvořenou ve skupině prostředků služby Azure metadata pro spouštění kanálů příjmu dat z nezpracovaných dat do rozšířeného stavu.
Pracovní prostor Analýzy Azure Databricks by měl mít zásady clusteru, které vyžadují vytvoření clusterů s vysokou souběžností. Tento typ clusteru umožňuje prozkoumání datového jezera pomocí předávání přihlašovacích údajů Microsoft Entra. Další informace najdete v tématu Řízení přístupu a konfigurace datových jezer ve službě Azure Data Lake Storage.
Konfigurace Azure Databricks
Nasazení Azure Databricks je částečně založené na parametrech prostřednictvím šablony Azure Resource Manageru a skriptů YAML, ale vyžaduje také ruční zásah ke konfiguraci všech pracovních prostorů.
Všechny pracovní prostory Azure Databricks by měly používat plán Premium, který poskytuje následující požadované funkce:
- Optimalizované automatické škálování výpočetních prostředků
- Předávací ověřování přihlašovacích údajů Microsoft Entra
- Podmíněné ověřování
- Řízení přístupu k poznámkovým blokům, clusterům, úlohám a tabulkám založené na rolích
- Protokoly auditu
Pokud chcete zajistit soulad s analýzou na úrovni cloudu, doporučujeme, aby všechny pracovní prostory měly nakonfigurované následující výchozí možnosti nasazení:
- Pracovní prostory Azure Databricks se připojí k externí instanci metastoru Apache Hive v cílové zóně dat.
- Nakonfigurujte každý pracovní prostor tak, aby odesílal diagnostické protokolování Databricks do Azure Log Analytics v databricks-monitoring-rg.
- Implementujte zásady clusteru, abyste omezili možnost vytvářet clustery na základě sady pravidel. Další informace najdete v tématu Správa zásad clusteru.
- Definujte více zásad clusteru. V rámci procesu onboardingu přiřaďte jednotlivým cílovým skupinám oprávnění k používání provozním týmem cílové zóny dat. Ve výchozím nastavení se oprávnění k vytvoření clusteru udělí jenom provoznímu týmu. Různým týmům nebo skupinám se udělí oprávnění k používání zásad clusteru.
- Pomocí zásad clusteru v kombinaci s fondy Azure Databricks můžete zkrátit dobu spuštění a automatického škálování clusteru udržováním sady nečinných instancí připravených k použití. Další informace najdete v tématu Fondy.
- Načtěte všechny provozní tajné kódy Azure Databricks, jako jsou přihlašovací údaje SPN a připojovací řetězec, z instance služby Azure Key Vault.
- Nakonfigurujte samostatnou podnikovou aplikaci na pracovní prostor pro použití s SCIM (systém pro správu identit napříč doménami). Propojením s pracovním prostorem Azure Databricks můžete řídit přístup a oprávnění ke každému pracovnímu prostoru. Další informace naleznete v tématu Zřizování uživatelů a skupin pomocí SCIM a konfigurace zřizování SCIM pro Microsoft Entra ID.
Upozorňující
Selhání konfigurace pracovního prostoru Azure Databricks tak, aby používalo rozhraní SCIM Azure Databricks, má vliv na to, jak poskytujete kontrolní mechanismy zabezpečení. Přesune se z automatizovaného na ruční proces a přeruší všechny kanály CI/CD nasazení.
Pro všechny pracovní prostory Databricks jsou nastavené následující možnosti řízení přístupu:
- Řízení viditelnosti pracovního prostoru: povoleno (výchozí: zakázáno)
- Řízení viditelnosti clusteru: povoleno (výchozí: zakázáno)
- Řízení viditelnosti úlohy: povoleno (výchozí: zakázáno)
Pro pracovní prostor analýzy Azure Databricks můžete povolit následující možnosti:
- Export poznámkového bloku: zakázáno (výchozí: povoleno)
- Funkce schránky tabulky poznámkových bloků: zakázané (výchozí: povolené)
- Řízení přístupu k tabulce: povoleno (výchozí: zakázáno)
- Podmíněný přístup Microsoft Entra
Nasazení Azure Databricks
Pokud nasadíte pracovní prostory Azure Databricks jako součást nasazení nové cílové zóny dat. Následující obrázek ukazuje ukázkový pracovní postup nasazení prostředí Azure Databricks v analýzách v cloudovém měřítku.
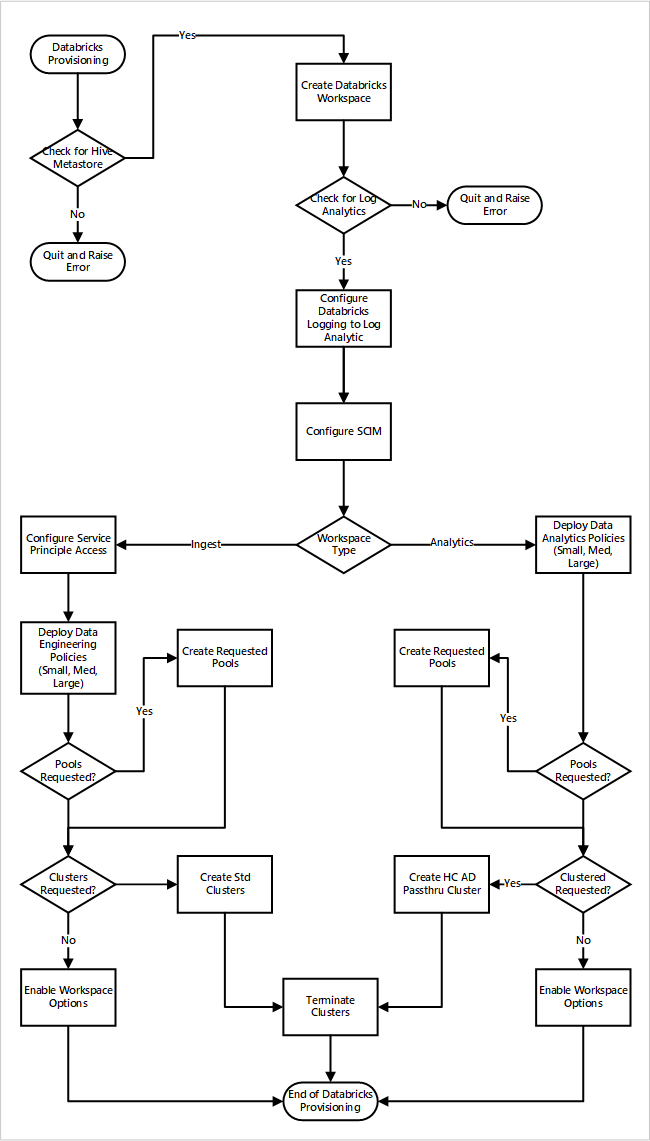
- Proces zřizování nejprve zajistí, že instance metastoru Apache Hive existuje v cílové zóně dat. Pokud se nepodaří najít metastore Apache Hive, ukončí se a vyvolá chybu.
- Po úspěšném vyhledání metastoru Apache Hive se vytvoří pracovní prostor.
- Proces zkontroluje pracovní prostor služby Log Analytics v cílové zóně dat. Pokud se nepodaří najít pracovní prostor služby Log Analytics, ukončí se a vyvolá chybu.
- Pro každý pracovní prostor vytvoří aplikaci Microsoft Entra a nakonfiguruje SCIM.
Pro pracovní prostor ingestování Azure Databricks:
- Proces nakonfiguruje pracovní prostor s přístupem instančního objektu.
- Nasadí se zásady přípravy dat definované provozním týmem datové platformy.
- Pokud provozní tým cílové zóny dat požádal o fondy nebo clustery Databricks, můžete je integrovat do procesu nasazení.
- Umožňuje možnosti pracovního prostoru specifické pro technický pracovní prostor Azure Databricks.
Pro pracovní prostor Analýzy Azure Databricks:
- Proces nasadí zásady analýzy dat, které definoval provozní tým datové platformy.
- Pokud provozní tým cílové zóny dat požádal o fondy nebo clustery Databricks, můžete je integrovat do procesu nasazení.
- Umožňuje možnosti pracovního prostoru specifické pro technický pracovní prostor Azure Databricks.
Externí metastore Hive
V nasazení pracovního prostoru Azure Databricks:
- Nový globální inicializační skript konfiguruje nastavení metastoru Apache Hive pro všechny clustery. Tento skript spravuje nové rozhraní API globálních inicializačních skriptů .
Nové rozhraní API globálních inicializačních skriptů je ve verzi Public Preview. Funkce Public Preview v Azure Databricks jsou připravené pro produkční prostředí a tým podpory je podporuje. Další informace najdete ve verzích Azure Databricks Preview.
- Toto řešení používá Azure Database for MySQL k ukládání instance metastoru Apache Hive. Tato databáze byla vybrána pro svou nákladovou efektivitu a vysokou kompatibilitu s Apache Hivem.
Další kroky
Analýzy na úrovni cloudu berou v úvahu následující pokyny pro integraci Azure Databricks: