Označování promluv v sadě Language Studio
Jakmile vytvoříte schéma pro svůj projekt, měli byste do projektu přidat trénovací promluvy. Promluvy by se měly podobat tomu, co budou uživatelé používat při interakci s projektem. Když přidáte promluvu, musíte přiřadit, ke kterému záměru patří. Po přidání promluvy označte slova v promluvě, která chcete extrahovat, jako entity.
Označování dat je zásadním krokem životního cyklu vývoje. tato data se použijí v dalším kroku při trénování modelu, aby se model mohl učit z označených dat. Pokud už máte označené promluvy, můžete je přímo importovat do projektu, ale musíte se ujistit, že data mají formát akceptovaných dat. Další informace o importu dat s popisky do projektu najdete v tématu Vytvoření projektu . Data s popisky informují model o tom, jak interpretovat text, a používají se k trénování a vyhodnocení.
Požadavky
Než budete moct data označit popisky, potřebujete:
- Projekt se úspěšně vytvořil.
Další informace najdete v tématu Životní cyklus vývoje projektu .
Pokyny pro popisky dat
Po vytvoření schématu a vytvoření projektu budete muset data označit popiskem. Označování dat je důležité, aby model věděl, která slova a věty budou přidruženy k záměrům a entitám v projektu. Budete chtít trávit čas označováním promluv – představením a upřesněním dat, která se použijí při trénování modelů.
Při přidávání promluv a jejich označování mějte na paměti:
Modely strojového učení se generalizují na základě označených příkladů, které zadáte. Čím více příkladů zadáte, tím více datových bodů model musí k lepšímu zobecnění.
Přesnost, konzistence a úplnost označených dat jsou klíčovými faktory pro určení výkonu modelu.
- Přesný popisek: Vždy označte každý záměr a entitu správným typem. Zahrňte jenom to, co chcete klasifikovat a extrahovat, abyste se vyhnuli zbytečným datům v popiscích.
- Označit konzistentně: Stejná entita by měla mít ve všech promluvách stejný popisek.
- Popisek úplně: Zadejte různé promluvy pro každý záměr. Označte všechny instance entity ve všech promluvách.
Přehledné označení promluv
Ujistěte se, že koncepty, na které odkazují vaše entity, jsou dobře definované a oddělitelné. Zkontrolujte, jestli můžete snadno spolehlivě určit rozdíly. Pokud to nemůžete, může to značit, že bude mít potíže i naučená komponenta.
Pokud existují podobnosti mezi entitami, ujistěte se, že existuje určitý aspekt vašich dat, který poskytuje signál pro rozdíl mezi nimi.
Pokud jste například vytvořili model pro rezervaci letů, může uživatel použít výrok typu "Chci let z Bostonu do Seattlu". Očekává se, že výchozí město a cílové město pro tyto výroky budou podobné. Signál k odlišení "Město původu" může být, že mu často předchází slovo "z".
Ujistěte se, že v trénovacích i testovacích datech označíte všechny instance každé entity. Jedním z přístupů je použití funkce search k vyhledání všech výskytů slova nebo fráze v datech, abyste zjistili, jestli jsou správně označené.
Označte testovací data pro entity, které nemají žádnou naučenou komponentu , a také pro ty, které je mají. To vám pomůže zajistit, aby vaše metriky vyhodnocení byly přesné.
U vícejazyčných projektů přidávání promluv v jiných jazycích zvyšuje výkon modelu v těchto jazycích, ale vyhněte se duplikování dat ve všech jazycích, které chcete podporovat. Pokud například chcete zlepšit výkon robota kalendáře u uživatelů, může vývojář přidat příklady většinou v angličtině a několik také ve španělštině nebo francouzštině. Můžou přidávat promluvy, jako jsou:
- "Set a meeting with Matt and Kevintomorrow at 12 PM." (angličtina)
- "Odpovědět nezávazně na schůzku s týdenní aktualizací" (angličtina)
- "Cancelar mi próxima reunión." (španělština)
Jak označovat výroky
K označení promluv použijte následující postup:
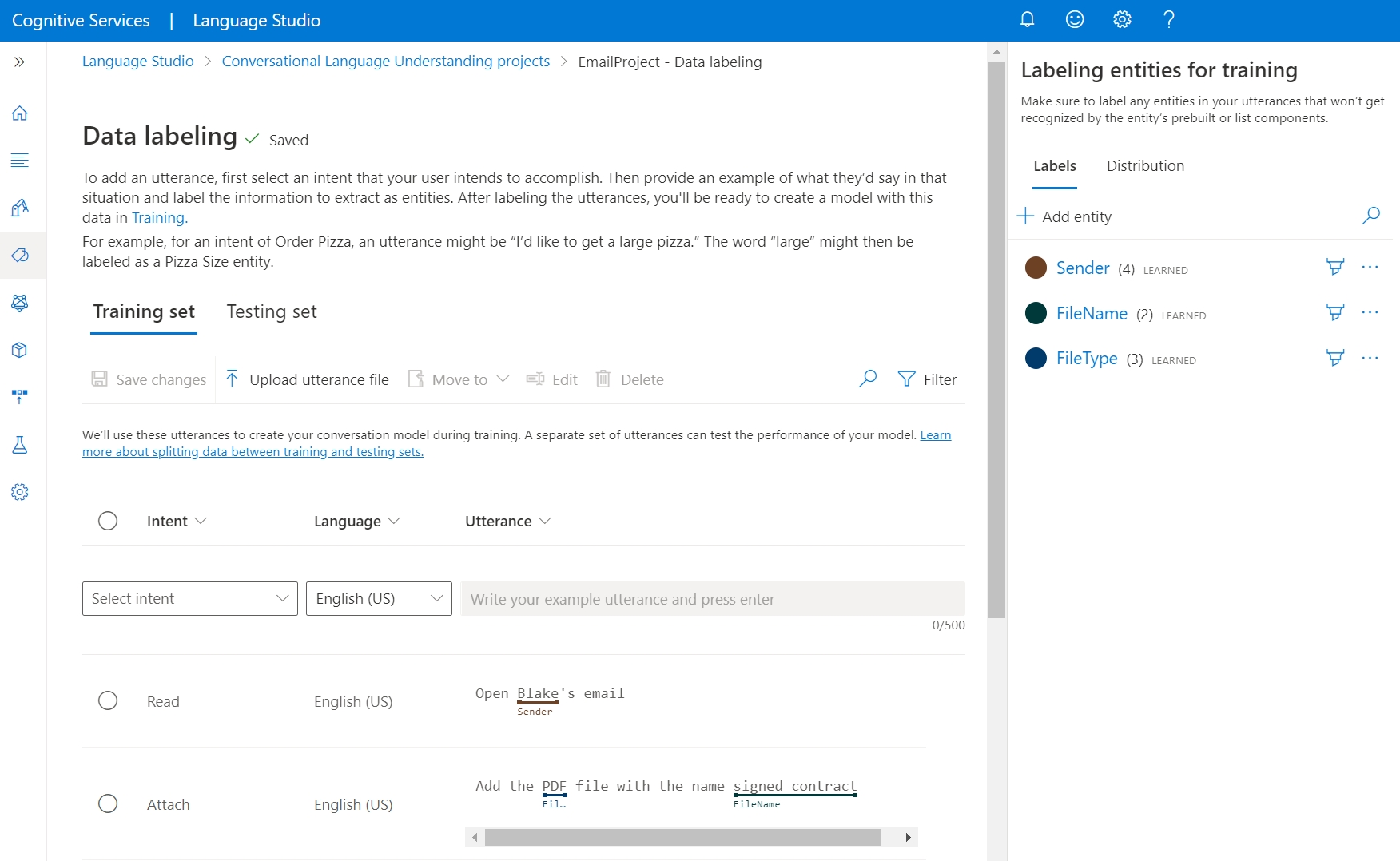
Přejděte na stránku projektu v nástroji Language Studio.
V nabídce na levé straně vyberte Popisování dat. Na této stránce můžete začít přidávat promluvy a popisovat je. Promluvu můžete nahrát také přímo kliknutím na Nahrát soubor promluvy v horní nabídce a ujistěte se, že odpovídá přijatému formátu.
V horních pivotech můžete zobrazení změnit na trénovací nebotestovací sadu. Přečtěte si další informace o trénovacích a testovacích sadách a o tom, jak se používají k trénování a vyhodnocení modelu.
Tip
Pokud plánujete použít možnost Automaticky rozdělit testovací sadu od rozdělení trénovacích dat , přidejte do trénovací sady všechny promluvy.
V rozevírací nabídce Vybrat záměr vyberte jeden ze záměrů, jazyk promluvy (u vícejazyčných projektů) a samotnou promluvu. Stisknutím klávesy Enter do textového pole promluvy přidejte promluvu.
Entity v promluvě můžete označovat dvěma způsoby:
Možnost Popis Popisek pomocí štětce Vyberte ikonu štětce vedle entity v pravém podokně a pak zvýrazněte text v promluvě, kterou chcete označit. Popisek pomocí vložené nabídky Zvýrazněte slovo, které chcete označit jako entitu, a zobrazí se nabídka. Vyberte entitu, pomocí které chcete tato slova označit. V pravém bočním podokně pod pivotem Popisky najdete všechny typy entit v projektu a počet označených instancí na každý z nich.
V pivotu Distribuce můžete zobrazit distribuci mezi trénovací a testovací sady. Máte dvě možnosti zobrazení:
- Celkový počet instancí na označenou entitu , kde můžete zobrazit počet všech označených instancí konkrétní entity.
- Jedinečné promluvy na označenou entitu , kde se každá promluva počítá, pokud obsahuje alespoň jednu označenou instanci této entity.
- Promluvy na záměr , kde můžete zobrazit počet promluv na záměr.


Poznámka
Seznam a předem připravené komponenty se nezobrazují na stránce popisků dat a všechny popisky tady platí jenom pro naučenou komponentu.
Odebrání popisku:
- V promluvě vyberte entitu, ze které chcete odebrat popisek.
- Projděte si nabídku, která se zobrazí, a vyberte Odebrat popisek.
Odstranění entity:
- V pravém bočním podokně vyberte entitu, kterou chcete upravit.
- Vyberte tři tečky vedle entity a v rozevírací nabídce vyberte požadovanou možnost.
Návrhy promluv pomocí Azure OpenAI
V CLU použijte Azure OpenAI k návrhu promluv, které chcete přidat do projektu pomocí modelů GPT. Nejprve musíte získat přístup a vytvořit prostředek v Azure OpenAI. Pak budete muset vytvořit nasazení pro modely GPT. Postupujte podle pokynů uvedených tady.
Než začnete, je funkce navrhnout promluvy dostupná jenom v případě, že se váš prostředek jazyka nachází v následujících oblastech:
- East US
- Středojižní USA
- West Europe
Na stránce Popisování dat:
- Vyberte tlačítko Navrhnout promluvy . Na pravé straně se otevře podokno s výzvou k výběru prostředku Azure OpenAI a nasazení.
- Při výběru prostředku Azure OpenAI vyberte Připojit, což vašemu prostředku jazyka umožní přímý přístup k prostředku Azure OpenAI. Přiřadí vašemu prostředku jazyka roli
Cognitive Services Userprostředku Azure OpenAI, což vašemu aktuálnímu prostředku jazyka umožňuje přístup ke službě Azure OpenAI. Pokud připojení selže, podle následujících kroků přidejte správnou roli do prostředku Azure OpenAI ručně. - Jakmile je prostředek připojený, vyberte nasazení. Doporučený model pro nasazení Azure OpenAI je
text-davinci-002. - Vyberte záměr, pro který chcete dostávat návrhy. Ujistěte se, že záměr, který jste vybrali, má alespoň 5 uložených promluv, které se mají povolit pro návrhy promluv. Návrhy poskytované službou Azure OpenAI jsou založené na nejnovějších promluvách , které jste pro tento záměr přidali.
- Vyberte Generovat promluvy. Po dokončení se navrhované promluvy zobrazí s tečkovanou čárou kolem ní s poznámkou Vygenerovanou pomocí umělé inteligence. Tyto návrhy je potřeba přijmout nebo odmítnout. Přijetím návrhu ho jednoduše přidáte do projektu, jako byste ho přidali sami. Pokud ho odmítnete, návrh se úplně odstraní. Součástí projektu budou jenom přijaté promluvy, které se použijí k trénování nebo testování. Můžete to přijmout nebo odmítnout kliknutím na zelená tlačítka pro zaškrtnutí nebo červené zrušení vedle každého výroku. Můžete také použít
Accept alltlačítka aReject allna panelu nástrojů.

Použití této funkce znamená, že se vašemu prostředku Azure OpenAI účtuje podobný počet tokenů jako navrhované vygenerované promluvy. Podrobnosti o cenách azure OpenAI najdete tady.
Přidání požadovaných konfigurací do prostředku Azure OpenAI
Pokud se nezdaří připojení prostředku jazyka k prostředku Azure OpenAI, postupujte takto:
Povolte správu identit pro prostředek jazyka pomocí následujících možností:
Váš prostředek jazyka musí mít správu identit, aby ho bylo možné povolit pomocí Azure Portal:
- Přejděte do prostředku jazyka.
- V nabídce vlevo v části Správa prostředků vyberte Identita.
- Na kartě Přiřazený systém nezapomeňte nastavit Stav na Zapnuto.
Po povolení spravované identity přiřaďte roli Cognitive Services User prostředku Azure OpenAI pomocí spravované identity prostředku jazyka.
- Přihlaste se k Azure Portal a přejděte k prostředku Azure OpenAI.
- Na levé straně vyberte kartu Access Control (IAM).
- Vyberte Přidat > přidat přiřazení role.
- Vyberte Role funkce úlohy a klikněte na Další.
- Vyberte
Cognitive Services Userze seznamu rolí a klikněte na Další. - Vyberte Přiřadit přístup ke spravované identitě a vyberte Vybrat členy.
- V části Spravovaná identita vyberte Jazyk.
- Vyhledejte prostředek a vyberte ho. Potom vyberte tlačítko Vybrat níže a dokončete proces vedle.
- Zkontrolujte podrobnosti a vyberte Zkontrolovat a přiřadit.

Po několika minutách aktualizujte Language Studio a budete se moct úspěšně připojit k Azure OpenAI.