Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Cosmos DB nabízí různé možnosti, jak povolit rozsáhlé analýzy a vytváření sestav BI pro vaše provozní data.
Pokud chcete získat smysluplné přehledy o datech služby Azure Cosmos DB, možná budete muset dotazovat pomocí agregačních funkcí, jako je součet, počet atd., napříč několika databázemi a kolekcemi ve službě Cosmos DB a případně dotazovat na jiné zdroje dat, jako je Azure SQL Database nebo lakehouse. Tyto dotazy potřebují velký výpočetní výkon, který pravděpodobně spotřebovává více jednotek žádostí (RU) a v důsledku toho můžou tyto dotazy potenciálně ovlivnit výkon klíčových úloh.
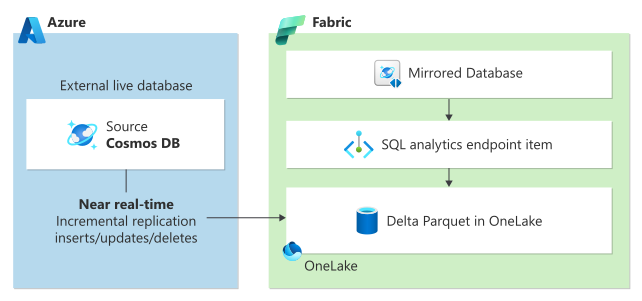
Chcete-li izolovat transakční úlohy od vlivu složitých analytických dotazů na výkon a pomoci kombinovat tato data s jinými zdroji dat ve vaší organizaci, Azure Cosmos DB a Microsoft Fabric řeší tyto výzvy tím, že nabízejí bez-ETL, nákladově efektivní analytická řešení se zrcadlením v Azure Cosmos DB a Cosmos DB v Microsoft Fabric.
Důležité
Synapse Link pro Cosmos DB se už pro nové projekty nepodporuje. Tuto funkci nepoužívejte.
Použijte "Mirroring" Azure Cosmos DB pro Microsoft Fabric, které je nyní všeobecně dostupné. Zrcadlení poskytuje stejné výhody nulového ETL a je plně integrováno s Microsoft Fabric. Další informace najdete v přehledu zrcadlení služby Cosmos DB.
Možnost 1: Zrcadlení dat Azure Cosmos DB do Microsoft Fabric
Zrcadlení v Microsoft Fabric poskytuje bezproblémové prostředí bez ETL pro integraci stávajících dat Azure Cosmos DB se zbývajícími daty v Microsoft Fabric pro skutečné hybridní transakční/analytické zpracování (HTAP) s úplnou izolací úloh mezi transakčními a analytickými systémy. Vaše data Azure Cosmos DB se nepřetržitě replikují přímo do Fabric OneLake téměř v reálném čase, aniž by to mělo vliv na výkon transakčních úloh nebo spotřebovávají jednotky žádostí (RU).
Data v OneLake jsou uložená v opensourcovém rozdílovém formátu a automaticky jsou k dispozici všem analytickým modulům v prostředcích Fabric.
K přístupu k datům v režimu OneLake v režimu DirectLake můžete použít integrované funkce Power BI. Díky vylepšením Copilotu ve Fabricu můžete využít sílu generativní umělé inteligence k získání klíčových poznatků o obchodních datech. Kromě Power BI můžete použít T-SQL ke spouštění složitých agregačních dotazů nebo ke zkoumání dat používat Spark. K datům v poznámkových blocích můžete bezproblémově přistupovat a používat datové vědy k vytváření modelů strojového učení.
Pokud chcete začít se zrcadlováním, navštivte kurz Začínáme se zrcadlením.
Možnost 2: Azure Cosmos DB ve Fabric
Cosmos DB v Microsoft Fabric je databáze NoSQL optimalizovaná pro AI se zjednodušeným prostředím pro správu. Jako vývojář můžete použít Cosmos DB v Fabric k vytváření aplikací umělé inteligence s menšími obtížemi a aniž byste museli provádět typické úlohy správy databází. Jako uživatel analytických nástrojů je možné službu Cosmos DB použít jako vrstvu pro zpracování s nízkou latencí, a tím zrychlit sestavy a tak obsloužit tisíce uživatelů současně.
Cosmos DB v Microsoft Fabric používá stejný engine a stejnou infrastrukturu jako Azure Cosmos DB for NoSQL, ale je úzce integrována do Fabric. Cosmos DB poskytuje datový model bez schématu ideální pro částečně strukturovaná data nebo vývoj datových modelů; nabízí neomezené, automatické a okamžité škálování s nízkou latencí a integrovanou vysokou dostupností.
Pokud chcete začít pracovat se službou Cosmos DB v Microsoft Fabric, navštivte Vytvořte databázi Cosmos DB v Microsoft Fabric.