Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Cosmos DB může uchovávat terabajty dat. Můžete provést rozsáhlou migraci dat a přesunout svou produkční úlohu do služby Azure Cosmos DB. Tento článek popisuje výzvy spojené s přesunem velkých objemů dat do služby Azure Cosmos DB a představuje nástroj, který pomáhá tyto výzvy řešit a migruje data do služby Azure Cosmos DB. V tomto případě zákazník použil rozhraní API služby Azure Cosmos DB pro NoSQL.
Před migrací celé úlohy do služby Azure Cosmos DB můžete migrovat podmnožinu dat, abyste ověřili některé aspekty, jako je volba klíče oddílu, výkon dotazů a modelování dat. Po ověření konceptu můžete přesunout celou úlohu do služby Azure Cosmos DB.
Nástroje pro migraci dat
Strategie migrace služby Azure Cosmos DB se v současné době liší v závislosti na volbě rozhraní API a velikosti dat. Pokud chcete migrovat menší datové sady – pro ověřování modelování dat, výkon dotazů, volbu klíče oddílu atd. – můžete použít konektor Azure Cosmos DB služby Azure Data Factory. Pokud znáte Spark, můžete se také rozhodnout, že k migraci dat použijete konektor Spark služby Azure Cosmos DB.
Výzvy pro rozsáhlé migrace
Stávající nástroje pro migraci dat do služby Azure Cosmos DB mají určitá omezení, která se projeví zejména ve velkém měřítku:
Omezené možnosti horizontálního navýšení kapacity: Aby bylo možné co nejrychleji migrovat terabajty dat do služby Azure Cosmos DB a efektivně využívat celou zřízenou propustnost, měli by mít klienti migrace možnost škálovat na neomezenou dobu.
Nedostatek sledování průběhu a kontrolních bodů: Je důležité sledovat průběh migrace a při migraci velkých datových sad mít kontrolní body. V opačném případě všechny chyby, ke kterým dojde během migrace, zastaví migraci a vy musíte proces spustit úplně od začátku. Pokud už bylo dokončeno 99 %, nebude produktivnější restartovat celý proces migrace.
Nedostatek fronty nedoručených zpráv: V rámci velkých datových sad může v některých případech dojít k problémům s částmi zdrojových dat. Kromě toho může dojít k přechodným problémům s klientem nebo sítí. Některý z těchto případů by neměl způsobit selhání celé migrace. I když většina nástrojů pro migraci má robustní možnosti opakování, které chrání před přerušovanými problémy, není vždy dostačující. Pokud je například méně než 0,01 % zdrojových datových dokumentů větších než 2 MB, způsobí to selhání zápisu dokumentu ve službě Azure Cosmos DB. V ideálním případě je vhodné, aby nástroj pro migraci uchovával tyto "neúspěšné" dokumenty do jiné fronty nedoručených zpráv, které je možné zpracovat po migraci.
U nástrojů, jako je Azure Data Factory nebo Azure Data Migration Services, je mnoho z těchto omezení opraveno.
Vlastní nástroj s knihovnou pro hromadné provádění
Problémy popsané v předchozí části je možné vyřešit pomocí vlastního nástroje, který lze snadno škálovat na více instancí a je odolný vůči přechodným selháním. Kromě toho může vlastní nástroj pozastavit a obnovit migraci na různých kontrolních bodech. Azure Cosmos DB již poskytuje knihovnu bulk executoru, která obsahuje některé z těchto funkcí. Například knihovna bulk executor už má funkci pro zpracování přechodných chyb a může škálovat vlákna v jednom uzlu tak, aby spotřebovala přibližně 500 K RU na uzel. Knihovna Bulk Executor také rozděluje zdrojovou datovou sadu do mikrodávek, které se provozují nezávisle jako forma vytváření kontrolních bodů.
Vlastní nástroj používá knihovnu bulk executoru a podporuje horizontální navýšení kapacity napříč více klienty, což zahrnuje i sledování chyb během procesu příjmu dat. Aby bylo možné tento nástroj použít, zdrojová data by se měla rozdělit do různých souborů ve službě Azure Data Lake Storage (ADLS), aby různé pracovní procesy migrace mohly každý soubor vyzvednout a ingestovat je do služby Azure Cosmos DB. Vlastní nástroj používá samostatnou kolekci, která ukládá metadata o průběhu migrace jednotlivých zdrojových souborů v ADLS a sleduje případné chyby, které s nimi souvisejí.
Následující obrázek popisuje proces migrace pomocí tohoto vlastního nástroje. Tento nástroj běží na sadě virtuálních počítačů a každý virtuální počítač dotazuje kolekci sledování ve službě Azure Cosmos DB, aby získal vlastnictví jedné z datových particí. Po dokončení se zdrojový oddíl dat načte nástrojem a ingestuje se do služby Azure Cosmos DB pomocí knihovny bulk executoru. Dále se aktualizuje kolekce sledování, aby zaznamenala průběh příjmu dat a případné chyby, ke kterým došlo. Po zpracování datového oddílu se nástroj pokusí zadat dotaz na další dostupný zdrojový oddíl. Pokračuje ve zpracování dalšího zdrojového oddílu, dokud nebudou migrována všechna data. Zdrojový kód nástroje je k dispozici v úložišti hromadného příjmu dat služby Azure Cosmos DB.
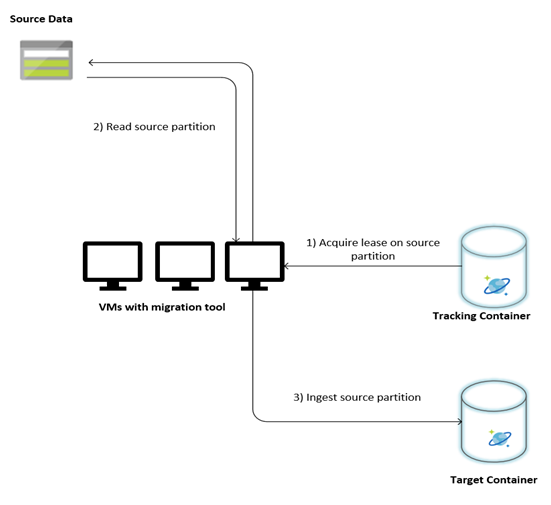
Kolekce sledování obsahuje dokumenty, jak je znázorněno v následujícím příkladu. Tyto dokumenty uvidíte pro každý oddíl ve zdrojových datech. Každý dokument obsahuje metadata pro zdrojový oddíl dat, jako je umístění, stav migrace a chyby (pokud existuje):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Požadavky na migraci dat
Před zahájením migrace dat je potřeba zvážit několik požadavků:
Odhad velikosti dat:
Velikost zdrojových dat nemusí přesně odpovídat velikosti dat ve službě Azure Cosmos DB. Ke kontrole velikosti dat ve službě Azure Cosmos DB je možné vložit několik ukázkových dokumentů ze zdroje. V závislosti na velikosti ukázkového dokumentu je možné odhadnout celkovou velikost dat ve službě Azure Cosmos DB po migraci.
Pokud je například každý dokument po migraci ve službě Azure Cosmos DB přibližně 1 kB a ve zdrojové datové sadě je přibližně 60 miliard dokumentů, znamená to, že odhadovaná velikost ve službě Azure Cosmos DB bude blízko 60 TB.
Předem vytvořte kontejnery s dostatečným množstvím RUs.
I když Azure Cosmos DB škáluje úložiště automaticky, nedoporučuje se začínat od nejmenší velikosti kontejneru. Menší kontejnery mají nižší dostupnost propustnosti, což znamená, že dokončení migrace bude trvat mnohem déle. Místo toho je užitečné vytvořit kontejnery s konečnou velikostí dat (podle odhadu v předchozím kroku) a ujistit se, že úloha migrace plně spotřebovává zřízenou propustnost.
Vzhledem k tomu, že se v předchozím kroku odhadla velikost dat přibližně 60 TB, je potřeba kontejner alespoň 2,4 M RU pro přizpůsobení celé datové sady.
Odhad rychlosti migrace:
Za předpokladu, že migrační úloha může spotřebovávat celou zřízenou propustnost, poskytuje tato propustnost odhad rychlosti migrace. Pokračujeme s předchozím příkladem, k napsání 1-KB dokumentu do NoSQL účtu služby Azure Cosmos DB API je potřeba pět RU. 2,4 milionu RU by umožnilo přenos 480 000 dokumentů za sekundu (nebo 480 MB/s). To znamená, že úplná migrace 60 TB trvá 125 000 sekund nebo přibližně 34 hodin.
Pokud chcete dokončit migraci do jednoho dne, měli byste zvýšit zřízenou propustnost na 5 milionů RU.
Vypněte indexování:
Vzhledem k tomu, že by migrace měla být dokončena co nejdříve, doporučujeme minimalizovat čas a spotřebu RU při vytváření indexů pro každý přijatý dokument. Azure Cosmos DB automaticky indexuje všechny vlastnosti, proto je vhodné minimalizovat indexování na několik vybraných termínů nebo ho úplně vypnout pro průběh migrace. Zásady indexování kontejneru můžete vypnout tak, že změníte indexingMode na žádný, jak je znázorněno zde:
{
"indexingMode": "none"
}
Po dokončení migrace můžete indexování aktualizovat.
Proces migrace
Po dokončení požadavků můžete migrovat data pomocí následujících kroků:
Nejprve naimportujte data ze zdroje do služby Azure Blob Storage. Pokud chcete zvýšit rychlost migrace, je užitečné paralelizovat různé zdrojové oddíly. Před zahájením migrace by se zdrojová sada dat měla rozdělit do souborů s velikostí kolem 200 MB.
Knihovna Bulk Executor může škálovat, aby spotřebovala 500 000 RU na jednom klientském virtuálním počítači. Vzhledem k tomu, že dostupná propustnost je 5 milionů RU, je potřeba zřídit 10 virtuálních počítačů s Ubuntu 16.04 (Standard_D32_v3) ve stejné oblasti, ve které se nachází vaše databáze Azure Cosmos DB. Tyto virtuální počítače byste měli připravit pomocí nástroje pro migraci a jeho souboru nastavení.
Spusťte krok ve frontě na jednom z u klientských virtuálních počítačů. Tento krok vytvoří kolekci sledování, která prohledá kontejner ADLS a vytvoří dokument sledování průběhu pro každý ze souborů oddílů zdrojové sady dat.
Potom spusťte krok importu na všech klientských virtuálních počítačích. Každý z klientů může převzít vlastnictví zdrojového oddílu a ingestovat data do služby Azure Cosmos DB. Jakmile je dokončena a její stav je aktualizován v kolekci sledování, mohou klienti poté dotazovat na další dostupný zdrojový oddíl v kolekci sledování.
Tento proces pokračuje, dokud se neingestovala celá sada zdrojových oddílů. Po zpracování všech zdrojových oddílů by se nástroj měl znovu spustit v režimu opravy chyb ve stejné kolekci sledování. Tento krok je nutný k identifikaci zdrojových oddílů, které by se měly znovu zpracovat kvůli chybám.
Některé z těchto chyb můžou být způsobené nesprávnými dokumenty ve zdrojových datech. Měly by se identifikovat a opravit. V dalším kroku byste měli znovu spustit krok importu u neúplných oddílů, abyste je znovu naimportovali.
Po dokončení migrace můžete ověřit, že počet dokumentů ve službě Azure Cosmos DB je stejný jako počet dokumentů ve zdrojové databázi. V tomto příkladu se celková velikost ve službě Azure Cosmos DB ukázala na 65 terabajtů. Po migraci je možné indexování selektivně zapnout a jednotky RU je možné snížit na úroveň potřebnou pro operace úlohy.
Další kroky
- Další informace získáte tak, že si vyzkoušíte ukázkové aplikace, které využívají knihovnu bulk executoru v .NET a Javě.
- Knihovna bulk executoru je integrovaná do konektoru Spark služby Azure Cosmos DB. Pro více informací vizte článek o konektoru Spark služby Azure Cosmos DB.
- Pokud potřebujete další pomoc s rozsáhlými migracemi, obraťte se na produktový tým služby Azure Cosmos DB tak, že otevřete lístek podpory pod typem problému Obecné rady a podtyp problému Velké migrace (TB+).
- Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB? Informace o stávajícím databázovém clusteru můžete použít k plánování kapacity.
- Pokud znáte pouze počet virtuálních jader a serverů ve vašem existujícím databázovém klastru, přečtěte si informace o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.