Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
I když databáze bez schématu, jako je Azure Cosmos DB, usnadňují ukládání a dotazování nestrukturovaných a částečně strukturovaných dat, zamyslete se nad datovým modelem za účelem optimalizace výkonu, škálovatelnosti a nákladů.
Jak se ukládají data? Jak vaše aplikace načítá a dotazuje data? Je vaše aplikace náročné na čtení nebo zápis?
Po přečtení tohoto článku můžete odpovědět na následující otázky:
- Co je modelování dat a proč je důležité?
- Jak se modelování dat ve službě Azure Cosmos DB liší od relační databáze?
- Jak vyjadřujete relace dat v nerelační databázi?
- Kdy vložím data a kdy se připojím k datům?
Čísla ve formátu JSON
Azure Cosmos DB ukládá dokumenty ve formátu JSON, takže je důležité určit, jestli se mají čísla před uložením ve formátu JSON převést na řetězce. Převeďte všechna čísla na hodnotu String , pokud by mohla překročit hranice čísel s dvojitou přesností, jak definuje institute of Electrical and Electronics Engineers (IEEE) 754 binary64.
Specifikace JSON vysvětluje, proč je použití čísel mimo tuto hranici špatným postupem kvůli problémům s interoperabilitou. Tyto obavy jsou zvláště důležité pro sloupec klíče oddílu, protože je neměnný a vyžaduje, aby se migrace dat později změnila.
Vložení dat
Když modelujete data ve službě Azure Cosmos DB, považují se entity za samostatné položky reprezentované jako dokumenty JSON.
Nejprve se podíváme, jak můžeme modelovat data v relační databázi. Následující příklad ukazuje, jak může být osoba uložena v relační databázi.
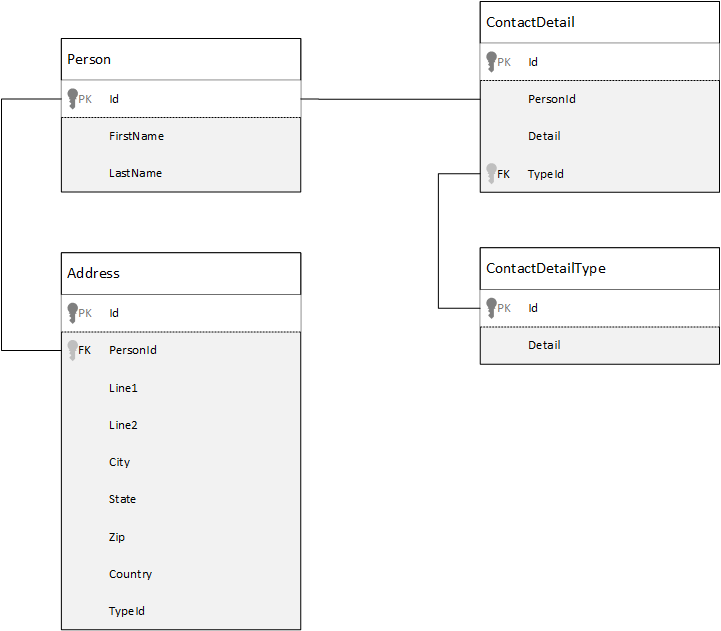
Strategií při práci s relačními databázemi je normalizovat všechna vaše data. Normalizace dat obvykle zahrnuje převzetí entity, jako je osoba, a jejich rozdělení do samostatných komponent. V tomto příkladu může mít osoba více záznamů podrobností o kontaktu a více záznamů adres. Podrobnosti o kontaktech můžete dále rozdělit extrahováním běžných polí, jako je typ. Stejný přístup platí pro adresy. Každý záznam lze klasifikovat jako home nebo business.
Hlavním principem při normalizaci dat je zabránit ukládání redundantních dat v každém záznamu a místo toho odkazovat na ně. V tomto příkladu potřebujete pro získání informací o osobě se všemi kontaktními údaji a adresami použít JOINS k efektivní kompozici (nebo denormalizaci) dat za běhu.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Aktualizace kontaktních údajů a adres jedné osoby vyžaduje operace zápisu v mnoha jednotlivých tabulkách.
Teď se podíváme na to, jak bychom modeloval stejná data jako samostatná entita ve službě Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Pomocí tohoto přístupu jsme denormalizovali záznam osoby vložením všech informací souvisejících s touto osobou, jako jsou jejich kontaktní údaje a adresy, do jednoho dokumentu JSON . Vzhledem k tomu, že nejsme omezeni na pevné schéma, máme flexibilitu provádět věci, jako mít kontaktní údaje v různých formátech.
Načtení kompletního záznamu osoby z databáze je nyní jedinou operací čtení pro jeden kontejner pro jednu položku. Aktualizace kontaktních údajů a adres záznamu osoby je také jedinou operací zápisu na jednu položku.
Denormalizace dat může snížit počet dotazů a aktualizace, které vaše aplikace potřebuje k dokončení běžných operací.
Kdy vložit
Obecně platí, že vložené datové modely používejte v případech:
- Mezi entitami jsou obsažené vztahy.
- Mezi entitami existuje vztah 1:1 .
- Data se mění zřídka.
- Data se nezvětšují bez omezení.
- Data se často vyhledávají společně.
Note
Obvykle denormalizované datové modely poskytují lepší výkon čtení .
Kdy nevkládat
I když obecné pravidlo ve službě Azure Cosmos DB je denormalizovat vše a vkládat všechna data do jedné položky, tento přístup může vést k situacím, kterým je lépe se vyhnout.
Vezměte tento fragment kódu JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Tento příklad může vypadat jako entita příspěvku s vloženými komentáři, pokud bychom modelovali typický blog nebo systém pro správu obsahu (CMS). Problém s tímto příkladem je, že pole komentářů není nevázané, což znamená, že neexistuje žádný (praktický) limit počtu komentářů, které může mít libovolný příspěvek. Tento návrh může způsobit problémy, protože velikost položky může být neomezeně velká, takže se jí vyhněte.
S rostoucí velikostí položek se přenos, čtení a aktualizace dat ve velkém měřítku stává náročnější.
V tomto případě by bylo lepší zvážit následující datový model.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Tento model má položku pro každý komentář s vlastností, která obsahuje identifikátor příspěvku. Tento model umožňuje, aby příspěvky obsahovaly libovolný počet komentářů a efektivně se zvětšují. Uživatelé, kteří chtějí zobrazit více než jen nejnovější komentáře, by dotazovali tento kontejner tak, že by předali postId, což by měl být partiční klíč pro kontejner komentářů.
Dalším případem, kdy vkládání dat není dobrý nápad, je, když se vložená data často používají napříč položkami a často se mění.
Vezměte tento fragment kódu JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Tento příklad může představovat portfolio akcií osoby. Rozhodli jsme se vložit informace o akciích do každého dokumentu portfolia. V prostředí, kde se související data často mění, bude vkládání dat, která se rovněž často mění, znamenat, že budete muset neustále aktualizovat každé portfolio. Pomocí příkladu aplikace burzovního obchodování aktualizujete každou položku portfolia pokaždé, když se obchoduje akcie.
Akcie zbzb se dají obchodovat stovkykrát za jeden den a tisíce uživatelů můžou mít zbzb ve svých portfoliech. S datovým modelem, jako je tento příklad, musí systém aktualizovat tisíce dokumentů portfolia mnohokrát denně, což se špatně škáluje.
Referenční data
Vkládání dat funguje dobře v mnoha případech, ale existují scénáře, kdy denormalizace dat způsobuje více problémů, než stojí za to. Tak co můžete dělat?
Můžete vytvářet vztahy mezi entitami v databázích dokumentů, nejen v relačních databázích. V databázi dokumentů může jedna položka obsahovat informace, které se připojují k datům v jiných dokumentech. Azure Cosmos DB není určený pro složité relace, jako jsou ty v relačních databázích, ale jednoduché propojení mezi položkami jsou možné a můžou být užitečné.
Ve formátu JSON použijeme příklad portfolia akcií z předchozího příkladu, ale tentokrát místo vložení odkazujeme na skladovou položku v portfoliu. Díky tomu se skladová položka často mění v průběhu dne, jedinou položkou, kterou je potřeba aktualizovat, je jeden skladový dokument.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Jednou z nevýhod tohoto přístupu je, že vaše aplikace musí vytvořit několik databázových požadavků, aby získala informace o jednotlivých akciích v portfoliu dané osoby. Díky tomuto návrhu je zápis dat rychlejší, protože k aktualizacím často dochází. Ale čtení nebo dotazování dat je pomalejší, což je pro tento systém méně důležité.
Note
Normalizované datové modely můžou vyžadovat více požadavků na server.
A co cizí klíče?
Vzhledem k tomu, že neexistuje žádný koncept omezení, jako je cizí klíč, databáze neověřuje žádné vztahy mezi dokumenty; tyto odkazy jsou efektivně "slabé". Pokud chcete zajistit, aby data, na která položka odkazuje, skutečně existuje, musíte tento krok provést ve vaší aplikaci nebo pomocí triggerů na straně serveru nebo uložených procedur ve službě Azure Cosmos DB.
Kdy odkazovat
Obecně platí, že normalizované datové modely používejte v případech:
- Představuje vztah 1:N.
- Reprezentace relací mnoho k mnoha (M:N).
- Související data se často mění.
- Odkazovaná data můžou být nevázaná.
Note
Normalizace obvykle poskytuje lepší výkon zápisu .
Kam mám vztah umístit?
Růst vztahu pomáhá určit, do které položky se má odkaz uložit.
Pokud se podíváme na JSON, který modeluje vydavatele a knihy.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Pokud je počet knih na vydavatele malý a růst je omezený, může být užitečné uložit odkaz na knihu uvnitř položky vydavatele. Pokud je však počet knih na vydavatele nevázaný, pak by tento datový model vedl ke proměnlivosti, rostoucím polím, jako v ukázkovém dokumentu vydavatele.
Přepnutí struktury vede k modelu, který představuje stejná data, ale zabraňuje velkým proměnlivým kolekcím.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
V tomto příkladu už dokument vydavatele neobsahuje nevázanou kolekci. Místo toho každý dokument knihy obsahuje odkaz na jeho vydavatele.
Návody modelovat relace M:N?
V relační databázi se relace M:N často modelují pomocí spojování tabulek. Tyto relace pouze spojují záznamy z jiných tabulek dohromady.
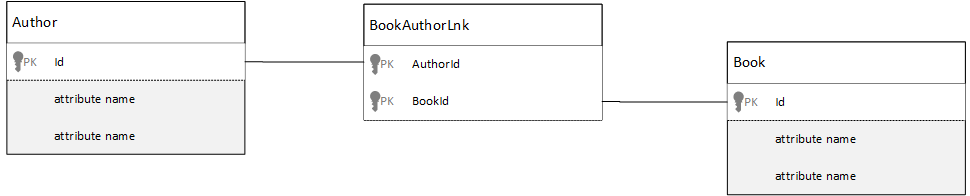
Může být lákavé replikovat stejnou věc pomocí dokumentů a vytvořit datový model, který vypadá podobně jako v následujícím příkladu.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Tento přístup funguje, ale načítání autora spolu s jeho knihami nebo knihy s jejím autorem vždy vyžaduje alespoň dva další dotazy na databázi. Jeden dotaz na připojovanou položku a pak další dotaz pro získání skutečné položky, která se připojuje.
Pokud toto spojení spojuje jenom dva části dat, proč ho úplně nezahodíte? Podívejte se na následující příklad.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
S tímto modelem můžete snadno zjistit, které knihy autor napsal, když se podíváte na jeho dokument. Můžete také zjistit, kteří autoři napsali knihu, tak, že dokument knihy zkontrolujete. Nemusíte používat samostatnou tabulku spojení ani provádět další dotazy. Díky tomuto modelu bude vaše aplikace rychlejší a jednodušší získat data, která potřebuje.
Hybridní datové modely
Prozkoumáme vkládání (nebo denormalizaci) a odkazování (nebo normalizaci) dat. Každý přístup nabízí výhody a zahrnuje kompromisy.
Nemusí být vždy buď nebo. Neváhejte trochu kombinovat věci.
V závislosti na konkrétních vzorech využití a úlohách vaší aplikace může mít kombinování vložených a odkazovaných dat smysl. Tento přístup by mohl zjednodušit aplikační logiku, zkrátit dobu odezvy serveru a udržovat dobrý výkon.
Podívejte se na následující JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Zde jsme (většinou) postupovali za vloženým modelem, kde se data z jiných entit vkládají do dokumentu nejvyšší úrovně, ale na jiná data se odkazují.
Pokud se podíváte na dokument knihy, můžeme v poli autorů vidět několik zajímavých prvků. Existuje pole id, které používáme k odkazování na dokument autora, což je standardní praxe v normalizovaném modelu, ale pak máme také name a thumbnailUrl. Mohli bychom použít pouze id a nechat aplikaci načíst všechny další informace, které potřebuje z odpovídající položky autora pomocí "odkazu". Vzhledem k tomu, že aplikace zobrazuje jméno autora a jeho miniaturu s každou knihou, denormalizace některých dat od autora snižuje počet dotazů na server na knihu v seznamu.
Pokud se jméno autora změní nebo aktualizuje fotku, budete muset aktualizovat každou knihu, kterou publikoval. U této aplikace však za předpokladu, že autoři zřídka mění jejich názvy, je toto kompromis přijatelné rozhodnutí o návrhu.
V tomto příkladu jsou předem vypočtené agregované hodnoty, které během operace čtení šetří nákladné zpracování. V příkladu jsou některá data vložená do položky autora data, která se počítají za běhu. Při každém publikování nové knihy se vytvoří položka knihy a pole countOfBooks se nastaví na vypočítanou hodnotu na základě počtu knižních dokumentů, které existuje pro určitého autora. Tato optimalizace by byla dobrá v systémech náročných na čtení, kde si můžeme dovolit provádět výpočty u zápisů za účelem optimalizace čtení.
Možnost mít model s předem přepočítanými poli je možná, protože Azure Cosmos DB podporuje transakce s více dokumenty. Kvůli tomuto omezení mnoho úložišť NoSQL nemůže provádět transakce napříč dokumenty, a proto doporučují rozhodnutí o návrhu, jako je "vždy vložit vše". Pomocí služby Azure Cosmos DB můžete použít triggery na straně serveru nebo uložené procedury, které vkládají knihy a aktualizují autory v rámci transakce ACID. Teď nemusíte vkládat všechno do jedné položky, abyste měli jistotu, že vaše data zůstanou konzistentní.
Rozlišovat mezi různými typy položek
V některých scénářích můžete chtít kombinovat různé typy položek ve stejné kolekci; tato volba návrhu je obvykle případ, kdy chcete mít více souvisejících dokumentů, které se nacházejí ve stejném oddílu. Můžete například vložit knihy i recenze knih do stejné kolekce a rozdělit je podle bookId. V takové situaci obvykle chcete do dokumentů přidat pole, které identifikuje jejich typ, aby se odlišily.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modelování dat pro Microsoft Fabric a zrcadlení služby Azure Cosmos DB
Azure Cosmos DB Mirroring je cloud-native funkce HTAP (Hybrid Transactional And Analytical Processing), která umožňuje spouštět analytické procesy v reálném čase nad provozními daty ve službě Azure Cosmos DB. Fabric Mirroring vytváří bezproblémovou integraci mezi Azure Cosmos DB a OneLake v Microsoft Fabric.
Tato integrace umožňuje spouštět rychlé a cenově dostupné dotazy na velké sady dat. Nemusíte kopírovat data nebo se starat o dopad na vaši transakční úlohu. Když zapnete zrcadlení pro kontejner, všechny změny provedené v datech se zkopírují do OneLake téměř okamžitě. Nemusíte nastavovat záznam změn ani spouštět úlohy extrakce, transformace a načítání dat (ETL). Systém udržuje obě úložiště synchronizovaná za vás.
Díky zrcadlení služby Azure Cosmos DB se nyní můžete přímo připojit ke svým kontejnerům Azure Cosmos DB z Microsoft Fabric a přistupovat k datům bez nákladů na žádostivé jednotky prostřednictvím T-SQL dotazů skrze SQL koncový bod k vašim datům nebo přímo ke Spark z OneLake.
Automatické odvození schématu
Transakční úložiště Azure Cosmos DB je částečně strukturovaná data zaměřená na řádky, zatímco OneLake v Microsoft Fabric používá sloupcový a strukturovaný formát. Tento převod se automaticky provede pro zákazníky. Proces převodu má omezení: maximální počet vnořených úrovní, maximální počet vlastností, nepodporované datové typy a další.
Note
V kontextu analytického úložiště považujeme za vlastnost následující struktury:
- "elementy" nebo "páry řetězců a hodnot oddělené
:" - Objekty JSON, oddělené pomocí
{a} - Pole JSON s oddělovači
[a]
Pomocí následujících technik můžete minimalizovat účinek převodů odvozování schématu a maximalizovat analytické schopnosti.
Normalizace
Normalizace je méně relevantní, protože Microsoft Fabric umožňuje připojit kontejnery pomocí T-SQL nebo Spark SQL. Očekávané výhody normalizace jsou:
- Menší nároky na data
- Menší transakce.
- Méně vlastností na dokument
- Datové struktury s menším počtem vnořených úrovní
Díky menšímu počtu vlastností a menšímu počtu úrovní v datech se analytické dotazy urychlují. Pomáhá také zajistit, aby všechny části vašich dat byly součástí OneLake. Počet úrovní a vlastností, které jsou reprezentovány ve OneLake, jsou omezené.
Dalším důležitým faktorem normalizace je to, že OneLake podporuje sady výsledků s až 1 000 sloupci a zveřejnění vnořených sloupců také počítá do tohoto limitu. Jinými slovy, koncové body SQL ve Fabric mají limit 1 000 vlastností.
Co ale dělat, protože denormalizace je důležitou technikou modelování dat pro Azure Cosmos DB? Odpovědí je, že musíte najít správnou rovnováhu pro své transakční a analytické úlohy.
Klíč oddílu
Klíč oddílu služby Azure Cosmos DB (PK) se v Microsoft Fabric nepoužívá. Díky této izolaci můžete zvolit PK pro vaše transakční data se zaměřením na příjem dat a bodové čtení, zatímco dotazy napříč oddíly lze provádět v Microsoft Fabric. Podívejme se na příklad:
V hypotetickém globálním scénáři IoT device id slouží jako dobrý klíč oddílu, protože všechna zařízení generují podobný objem dat, což brání problémům s přehřátými oddíly. Pokud ale chcete analyzovat data více než jednoho zařízení, například "všechna data ze včerejška" nebo "součty na město", může dojít k problémům, protože tyto dotazy jsou dotazy napříč oddíly. Tyto dotazy můžou poškodit výkon transakcí, protože ke spuštění používají část vaší propustnosti v jednotkách žádostí. S Microsoft Fabric ale můžete tyto analytické dotazy spouštět bez nákladů na jednotky žádostí. Rozdílový formát ve OneLake je optimalizovaný pro analytické dotazy.
Datové typy a názvy vlastností
Článek o pravidlech automatického odvozování schématu uvádí, jaké jsou podporované datové typy. I když moduly runtime Microsoft Fabric můžou zpracovávat podporované datové typy odlišně, nepodporované datové typy blokují reprezentaci v analytickém úložišti. Jedním z příkladů je: Když používáte řetězce DateTime, které odpovídají standardu ISO 8601 UTC, Spark pooly v Microsoft Fabric tyto sloupce reprezentují jako string a bezserverové SQL je reprezentuje jako varchar(8000).
Zploštění dat
Každá vlastnost na nejvyšší úrovni dat Azure Cosmos DB se stane sloupcem v analytickém úložišti. Vlastnosti uvnitř vnořených objektů nebo polí se ve OneLake ukládají jako JSON. Vnořené struktury vyžadují dodatečné zpracování z modulů Runtime Sparku nebo SQL, aby se data zploštěla. To může při práci s velmi velkým množstvím dat přidat náklady na výpočetní prostředky a latenci. Tam, kde je to jednoduché, použijte pro svá data plochý datový model. Alespoň se vyhněte nadměrnému vnoření dat v datových modelech.
Položka má ve OneLake id pouze dva sloupce a contactDetails. Všechna ostatní data, email, a phone, vyžadují ke čtení další zpracování prostřednictvím funkcí SQL nebo Sparku.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Zploštění eliminuje tuto potřebu. Níže je uvedeno , id, emaila phone jsou všechny přímo přístupné jako sloupce bez dalšího zpracování
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Vrstvení dat
Microsoft Fabric umožňuje snížit náklady z následujících perspektiv:
- V transakční databázi běží méně dotazů.
- PK optimalizovaný pro příjem dat a čtení záznamů podle klíče, což snižuje nároky na data, scénáře přetížených oddílů a štěpení oddílů.
- Ve vašem prostředí nejsou spuštěné žádné úlohy ETL, což znamená, že pro ně nemusíte přidělovat jednotky žádostí.
Řízená redundance
Tato technika je skvělou alternativou pro situace, kdy už datový model existuje a nedá se změnit. Nebo pokud jsou data příliš složitá s příliš mnoha vnořenými úrovněmi nebo příliš mnoha vlastnostmi. V takovém případě můžete pomocí kanálu změn služby Azure Cosmos DB replikovat data do jiného kontejneru, použít požadované transformace a pak nakonfigurovat zrcadlení pro tento kontejner do Microsoft Fabric pro účely analýzy. Podívejme se na příklad:
Scenario
Kontejner CustomersOrdersAndItems se používá k ukládání online objednávek včetně podrobností o zákazníkovi a položkách: fakturační adresa, dodací adresa, způsob doručení, stav doručení, cena položek atd. Je reprezentováno pouze prvních 1 000 vlastností a nejsou zahrnuty klíčové informace, což znemožňuje analýzu ve Fabric. Kontejner obsahuje petabajty dat, takže není možné změnit aplikaci a změnit její model.
Dalším aspektem problému je objem velkých objemů dat. Analytické oddělení neustále používá miliardy řádků, což jim znemožňuje použití tttl pro odstranění starých dat. Udržování celé historie dat v transakční databázi kvůli analytickým potřebám je nutí neustále zvyšovat RU/s, což má vliv na náklady. Transakční a analytické úlohy současně soupeří o stejné prostředky.
Co můžete udělat?
Řešení s informačním kanálem změn
- Řešením je použití Change Feed k naplnění tří nových kontejnerů:
Customers,Orders, aItems. S použitím Change Feed můžete normalizovat a zploštit data a odstranit nepotřebné informace z datového modelu. - Kontejner
CustomersOrdersAndItemsteď má nastavenou hodnotu TTL (Time to Live), která umožňuje uchovávat data pouze po dobu šesti měsíců, což umožňuje snížit využití dalších jednotek žádostí, protože ve službě Azure Cosmos DB je minimálně jedna jednotka žádosti za GB. Méně dat, méně jednotek žádostí
Klíčové poznatky
Největší poznatky z tohoto článku jsou, že modelování dat ve scénáři bez schématu je stejně důležité jako kdykoli předtím.
Stejně jako neexistuje jediný způsob, jak znázorňovat část dat na obrazovce, neexistuje jediný způsob, jak modelovat data. Potřebujete porozumět své aplikaci a tomu, jak vytváří, spotřebovává a zpracovává data. Použitím zde uvedených pokynů můžete vytvořit model, který řeší okamžité potřeby vaší aplikace. Když se vaše aplikace změní, využijte flexibilitu databáze bez schématu k snadnému přizpůsobení a vývoji datového modelu.