Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Azure Cosmos DB for PostgreSQL se už pro nové projekty nepodporuje. Tuto službu nepoužívejte pro nové projekty. Místo toho použijte jednu z těchto dvou služeb:
Azure Cosmos DB for NoSQL můžete použít pro distribuované databázové řešení navržené pro vysoce škálovatelné scénáře s 99,999% smlouvou o úrovni služeb (SLA), okamžitým automatickým škálováním a automatickým převzetím služeb při selhání napříč několika oblastmi.
Použijte funkci Elastic Clusters služby Azure Database for PostgreSQL pro horizontálně dělené PostgreSQL pomocí opensourcového rozšíření Citus.
Kolokace znamená ukládání souvisejících informací na stejných uzlech. Dotazy můžou být rychlé, pokud jsou všechna potřebná data dostupná bez jakéhokoli síťového provozu. Umístění souvisejících dat na oddělených uzlech umožňuje efektivní paralelní spouštění dotazů na každém uzlu.
Kolokace dat pro tabulky distribuované pomocí hodnot hash
Ve službě Azure Cosmos DB for PostgreSQL se řádek uloží do horizontálního oddílu, pokud hodnota hash v distribučním sloupci spadá do rozsahu hodnot hash horizontálního oddílu. Shardy se stejným rozsahem hash jsou vždy umístěny na stejný uzel. Řádky se stejnými hodnotami distribučního sloupce jsou vždy na stejném uzlu napříč tabulkami. Koncept tabulek distribuovaných pomocí hash se označuje také jako horizontální dělení na základě řádků. V shardování založeném na schématu jsou tabulky v rámci distribuovaného schématu vždy umístěny na stejném místě.
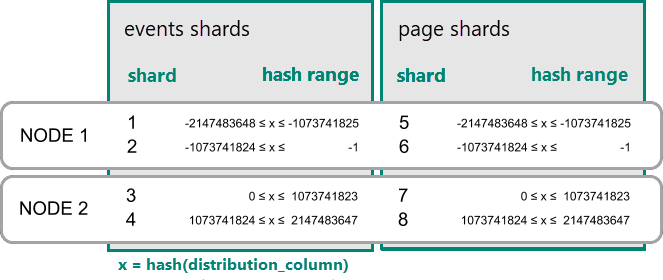
Praktický příklad kolokace
Zvažte následující tabulky, které můžou být součástí saaS pro víceklientské webové analýzy:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Teď chceme odpovědět na dotazy, které může vydat řídicí panel pro zákazníky. Příkladem dotazu je vrácení počtu návštěv za poslední týden pro všechny stránky začínající na /blog v tenantovi šest.
Pokud se naše data nacházela na jednom serveru PostgreSQL, mohli bychom dotaz snadno vyjádřit pomocí bohaté sady relačních operací nabízených SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Pokud pracovní sada pro tento dotaz zapadá do paměti, je vhodným řešením tabulka s jedním serverem. Podívejme se na příležitosti škálování datového modelu pomocí služby Azure Cosmos DB for PostgreSQL.
Distribuce tabulek podle ID
Dotazy na jednom serveru začnou zpomalovat, jakmile se zvýší počet nájemníků a množství dat uložených pro každého nájemníka. Pracovní sada se přestane vejít do paměti a procesor se stává úzkým hrdlem.
V tomto případě můžeme data horizontálně dělit napříč mnoha uzly pomocí služby Azure Cosmos DB for PostgreSQL. První a nejdůležitější volbou, kterou musíme udělat, když se rozhodneme pro shardování, je distribuční sloupec. Začněme naivním výběrem pro event_id tabulku událostí a page_id pro page tabulku:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Když jsou data rozptýlená mezi různými pracovními procesy, nemůžeme provést spojení stejně jako na jednom uzlu PostgreSQL. Místo toho musíme vydat dva dotazy:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Potom je potřeba výsledky těchto dvou kroků zkombinovat aplikací.
Spouštění dotazů musí konzultovat data v horizontálních oddílech rozptýlených napříč uzly.
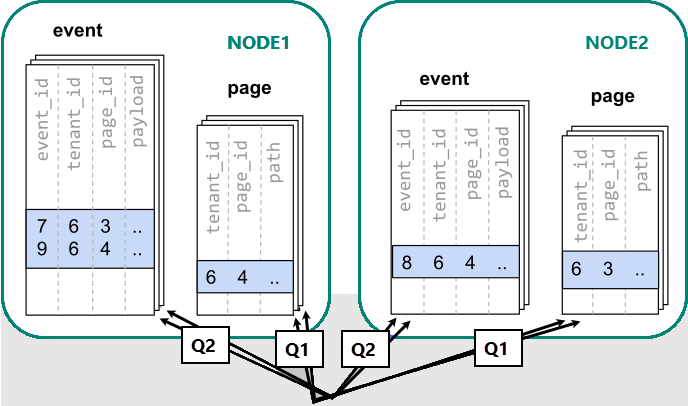
V tomto případě distribuce dat vytváří značné nevýhody:
- Režie při dotazování na jednotlivé fragmenty a spouštění více dotazů.
- Zatížení při vracení mnoha řádků z Q1 klientovi
- Druhý kvartál se stává velkým.
- Potřeba psát dotazy v několika krocích vyžaduje změny v aplikaci.
Data jsou rozptýlená, takže je možné paralelizovat dotazy. Má smysl jen tehdy, když množství práce, kterou dotaz vykonává, je podstatně větší než režie při dotazování mnoha oddílů.
Distribuce tabulek podle tenanta
Ve službě Azure Cosmos DB for PostgreSQL je zaručeno, že řádky se stejnou hodnotou distribučního sloupce budou na stejném uzlu. Začneme znovu a můžeme vytvořit naše tabulky s tenant_id jako distribučním sloupcem.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Azure Cosmos DB for PostgreSQL teď dokáže odpovědět na původní dotaz na jednoúčelový server beze změny (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Vzhledem k filtrování a použití tenant_id si Azure Cosmos DB for PostgreSQL uvědomuje, že celý dotaz může být zodpovězen pomocí sady horizontálně přidělených shardů, které obsahují data pro daného tenanta. Jeden uzel PostgreSQL může odpovědět na dotaz v jednom kroku.
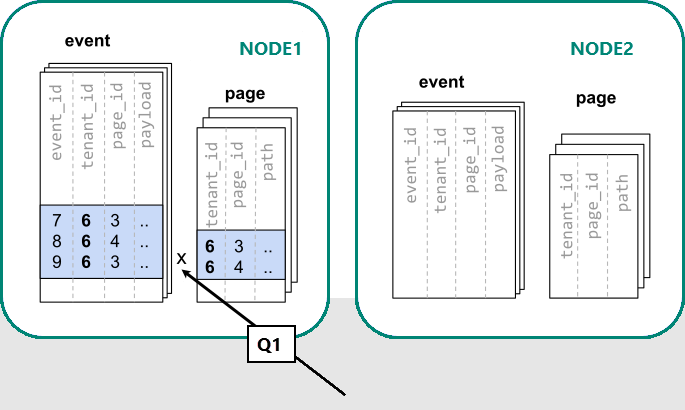
V některých případech je potřeba změnit dotazy a schémata tabulek tak, aby zahrnovaly ID tenanta v jedinečných omezeních a podmínkách spojení. Tato změna je obvykle jednoduchá.
Další kroky
- Podívejte se, jak jsou data tenanta umístěna v multitenantním tutoriálu.