Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Azure Cosmos DB for PostgreSQL se už pro nové projekty nepodporuje. Tuto službu nepoužívejte pro nové projekty. Místo toho použijte jednu z těchto dvou služeb:
Azure Cosmos DB for NoSQL můžete použít pro distribuované databázové řešení navržené pro vysoce škálovatelné scénáře s 99,999% smlouvou o úrovni služeb (SLA), okamžitým automatickým škálováním a automatickým převzetím služeb při selhání napříč několika oblastmi.
Použijte funkci Elastic Clusters služby Azure Database for PostgreSQL pro horizontálně dělené PostgreSQL pomocí opensourcového rozšíření Citus.
ID tenanta jako klíč horizontálního dělení
ID tenanta je sloupec v kořenovém adresáři úlohy nebo v horní části hierarchie ve vašem datovém modelu. Například v tomto schématu elektronického obchodování SaaS by to bylo ID obchodu:
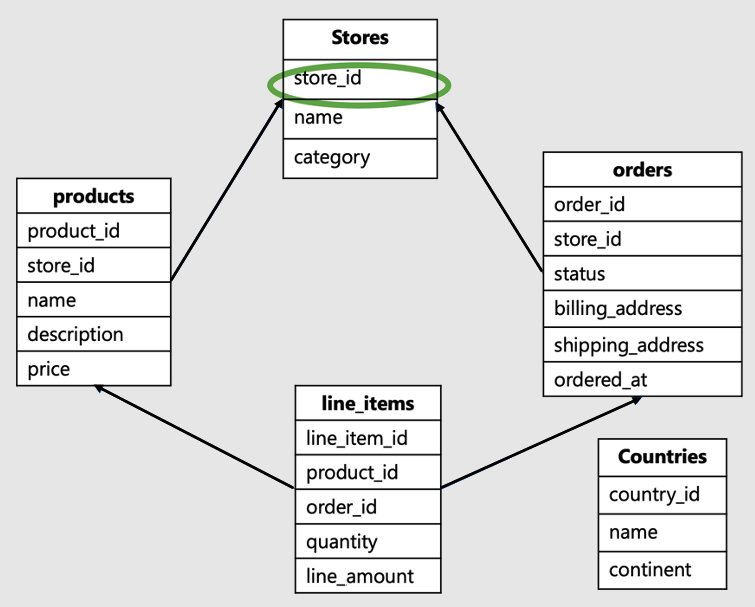
Tento datový model by byl typický pro firmu, jako je Shopify. Hostuje weby pro několik online obchodů, kde každá úložiště komunikuje s vlastními daty.
- Tento datový model má spoustu tabulek: obchody, produkty, objednávky, řádkové položky a země.
- Tabulka stores je v horní části hierarchie. Produkty, objednávky a řádkové položky jsou všechny přidruženy k obchodům, a proto jsou v hierarchii níže.
- Tabulka zemí nesouvisí s jednotlivými obchody, je společná pro všechny obchody.
V tomto příkladu, store_idkterý je v horní části hierarchie, je identifikátor tenanta. Je to správný shardovací klíč.
store_id Výběr klíče horizontálního oddílu umožňuje kolaci dat napříč všemi tabulkami pro jedno úložiště v jednom pracovním procesu.
Společné přidělení tabulek úložištěm má výhody:
- Poskytuje pokrytí SQL, jako jsou cizí klíče, JOIN. Transakce pro jednoho tenanta jsou lokalizovány na jednom pracovním uzlu, kde každý tenant existuje.
- Dosahuje výkonu v řádu milisekund. Dotazy pro jednoho tenanta se místo paralelizace směrují do jednoho uzlu, což pomáhá optimalizovat síťové přeskoky a zachovat škálovatelnost výpočetních prostředků a paměti.
- Škáluje se. S rostoucím počtem tenantů můžete přidávat uzly a vyrovnát tenanty do nových uzlů nebo dokonce izolovat velké tenanty s jejich vlastními uzly. Izolace nájemce umožňuje poskytovat vyhrazené prostředky.
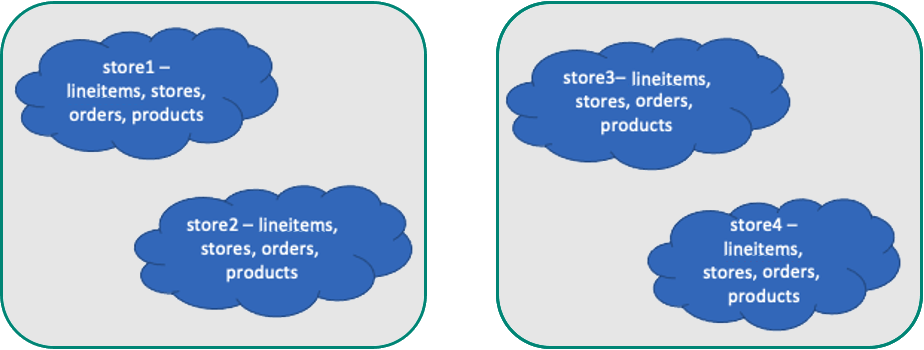
Optimální datový model pro aplikace s více tenanty
V tomto příkladu bychom měli distribuovat tabulky specifické pro úložiště podle ID úložiště a vytvořit countries referenční tabulku.
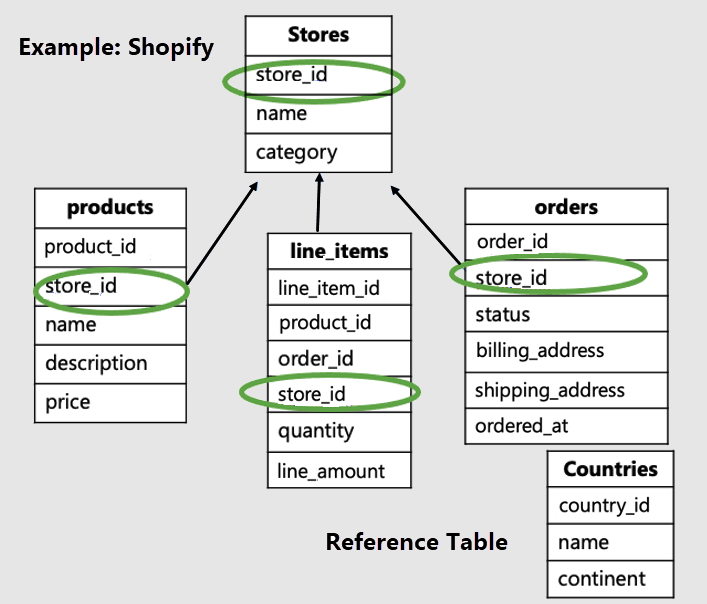
Všimněte si, že tabulky specifické pro tenanty mají ID tenanta a jsou distribuované. V našem příkladu se distribuují obchody, produkty a line_items. Zbývající tabulky jsou referenční tabulky. V našem příkladu je tabulka zemí referenční tabulkou.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Všechny velké tabulky by měly mít ID nájemce.
- Pokud migrujete existující aplikaci s více tenanty do služby Azure Cosmos DB for PostgreSQL, možná budete muset trochu denormalizovat a přidat sloupec ID tenanta do velkých tabulek, pokud chybí, a pak znovu vyplňte chybějící hodnoty sloupce.
- U nových aplikací ve službě Azure Cosmos DB for PostgreSQL se ujistěte, že je ID tenanta k dispozici ve všech tabulkách specifických pro tenanta.
Nezapomeňte zahrnout ID tenanta u omezení primárního, jedinečného a cizího klíče v distribuovaných tabulkách ve formě složeného klíče. Pokud má například tabulka primární klíč id, převést ho na složený klíč (tenant_id,id).
U referenčních tabulek není potřeba měnit klíče.
Úvahy o dotazech pro nejlepší výkon
Distribuované dotazy, které filtrují ID tenanta, běží nejefektivněji v aplikacích s více tenanty. Zajistěte, aby vaše dotazy byly vždy vymezeny na jednoho tenanta.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
Filtr ID tenanta je potřeba přidat i v případě, že původní podmínky filtru jednoznačně identifikují požadované řádky. Filtr ID tenanta, zatímco zdánlivě redundantní, říká službě Azure Cosmos DB for PostgreSQL, jak směrovat dotaz do jednoho pracovního uzlu.
Podobně při spojení dvou distribuovaných tabulek zajistěte, aby obě tabulky byly vymezeny na jednoho tenanta. Rozsah je možné provést tak, že zajistíte, aby podmínky připojení zahrnovaly ID tenanta.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
K dispozici jsou pomocné knihovny pro několik oblíbených aplikačních architektur, které usnadňují zahrnutí ID tenanta do dotazů. Tady jsou pokyny:
Další kroky
Teď jsme dokončili zkoumání modelování dat pro škálovatelné aplikace. Dalším krokem je připojení a dotazování databáze s použitím zvoleného programovacího jazyka.