Kontroly stavu
CycleCloud nabízí dva mechanismy pro kontrolu stavu virtuálních počítačů: Kontroly stavu uzlů jsou novější funkce, která provádí kontroly během fáze zřizování a zabraňuje připojení virtuálních počítačů, které nejsou v pořádku, zatímco HealthCheck je pravidelně spouští poté, co se virtuální počítač připojí ke clusteru jako uzel.
Kontroly stavu uzlu
Kontroly stavu uzlů můžou detekovat hardware, který není v pořádku, ještě než se virtuální počítač může připojit ke clusteru CycleCloud. Aktuální verze této funkce bude spouštět skripty kontroly stavu integrované do oficiálních imagí AzureHPC, které najdete v části /opt/azurehpc/test/azurehpc-health-checks/. Zdroj pro tyto skripty se nachází v úložišti Kontroly stavu uzlu AzureHPC, ale upozorňujeme, že verze integrovaná do verze image AzureHPC vašeho clusteru nemusí být nejnovější dostupná v úložišti.
Požadavky
Aktuální verze kontrol stavu uzlů podporuje pouze image AzureHPC vydané po 7. listopadu 2023 (obsahující azurehpc-health-checks verze v2.0.6 nebo vyšší) a vlastní image, které z nich byly odvozeny. Kontroly stavu uzlů se v současné době ve Windows nepodporují.
Povolení kontrol stavu uzlů pro clustery služby Slurm
Formulář pro vytvoření clusteru Slurm nabízí zaškrtávací políčko pro povolení kontrol stavu uzlu na kartě Upřesnit nastavení . Zaškrtnutím tohoto políčka povolíte kontroly stavu uzlu v poli uzlů prostředí HPC clusteru. Pokud chcete povolit kontroly stavu uzlů u jiných polí uzlů (nebo pro jiné typy clusterů), musíte použít vlastní šablonu clusteru.
Kontroly stavu uzlů je možné ve spuštěném clusteru zakázat jednoduše zrušením zaškrtnutí políčka. Není nutné vertikálně snížit kapacitu pole uzlů, aby se změny projevily.
Vysvětlení výsledků kontrol stavu uzlů
Jakmile virtuální počítač projde kontrolami stavu, přejde do fáze konfigurace softwaru.
Pokud virtuální počítač selže s některým skriptem kontroly stavu, odešle se do CycleCloudu chybová zpráva a virtuálnímu počítači se automaticky zabrání připojit se ke clusteru.
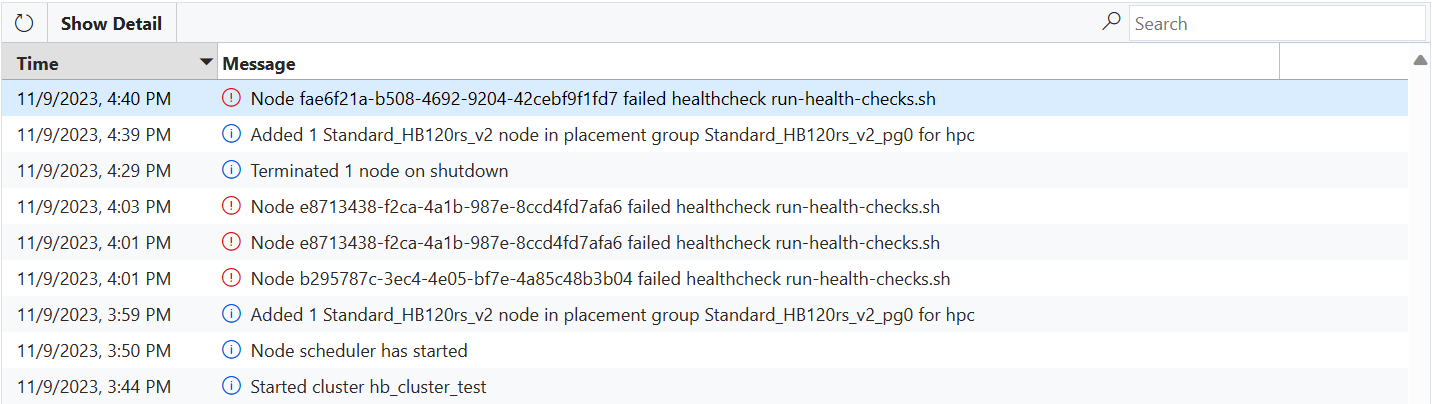
Pokud je virtuální počítač spuštěný v režimu NodeArray s povoleným nadměrným zřizováním (např. Slurm HPC Node Array), měl by se virtuální počítač automaticky nahradit v rámci nadměrného zřizování. V takovém případě se nevyžaduje žádná akce a virtuální počítače, které jsou v pořádku, se vyberou pro připojení ke clusteru (i když se na stránce clusteru zobrazí chybová zpráva, že jeden nebo více virtuálních počítačů selhalo).
Pokud je virtuální počítač spuštěný pro jeden uzel, pole uzlů se zakázaným nadměrným zřizováním (např. Slurm htc Node Array) nebo pokud více virtuálních počítačů neprojde kontrolami stavu, než podporuje nadměrné zřizování, přesune se uzel do stavu Selhání a přidělení selže. CycleCloud se může pokusit o obnovení image virtuálního počítače, aby se problém vyřešil, ale pokud opětovné vytvoření image selže, bude nutné uzel ukončit a nahradit (ručně správcem nebo automaticky pomocí automatického škálování).
Poznámka
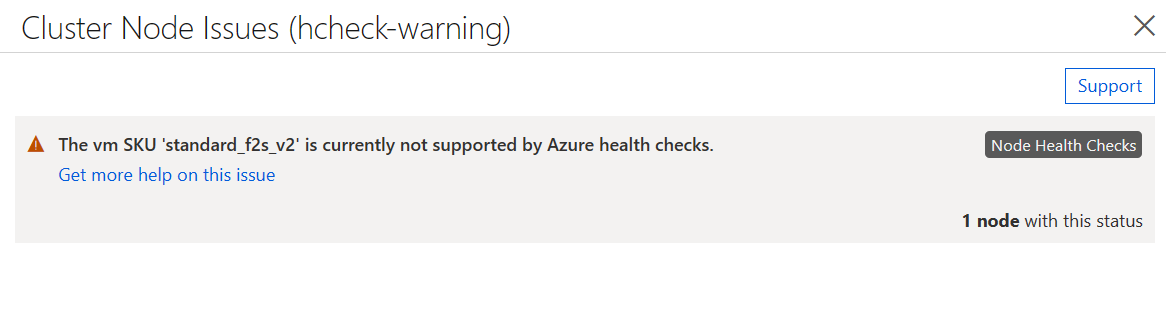
Pokud jste povolili kontroly stavu uzlů, ale image virtuálního počítače nesplňuje výše uvedené požadavky, budou se moct ke clusteru připojit všechny virtuální počítače, ale stav bude obsahovat upozornění, že kontroly nejsou podporované.
Referenční dokumentace k atributům
| Atribut | Typ | Definice |
|---|---|---|
| EnableNodeHealthChecks | Logická hodnota | (Volitelné) Povolit kontroly stavu uzlu při spuštění pro tento uzel nebo pole uzlů |
Kontrola stavu
Azure CycleCloud poskytuje mechanismus pro ukončení virtuálních počítačů, které nejsou v pořádku, s názvem HealthCheck. Skripty definované systémem i uživatelem (Python a Bash) se spouštějí pravidelně (5 minut ve Windows, 10 minut v Linuxu), aby se zjistil celkový stav virtuálního počítače. HealthCheck umožňuje správcům definovat podmínky, za kterých by se měly virtuální počítače ukončit, aniž by musely ručně monitorovat a opravovat.
Předdefinované skripty healthCheck
Virtuální počítače s podporou CycleCloudu se dodávají se dvěma výchozími skripty HealthCheck:
-
Skript converge_timeout ukončí instanci, která nedokončila konfiguraci softwaru, do čtyř hodin od spuštění. Tento časový limit lze řídit
cyclecloud.keepalive.timeoutnastavením (definovaným v sekundách). - Skript scheduled_shutdown vyhledá soubory tvůrce v $JETPACK_HOME/run/scheduled_shutdown, které obsahují jeden řádek s uvedením času vypnutí v sekundách unixového časového razítka a volitelný druhý řádek s vysvětlením. Pokud je aktuální čas pozdější než nejstarší časové razítko v souborech, virtuální počítač se považuje za poškozený.
Jak to funguje
Skripty HealthCheck se nacházejí v adresáři $JETPACK_HOME/config/healthcheck.d . Linux podporuje skripty Pythonu i Bash, zatímco Windows podporuje pouze skripty Pythonu. Skript by měl určit stav virtuálního počítače. Pokud se zjistí, že virtuální počítač není v pořádku, měl by se skript ukončit se stavem 254, který ve službě CycleCloud indikuje, že virtuální počítač není v pořádku a měl by se ukončit.
Po přihlášení k virtuálnímu počítači se spuštěnou kontrolou stavu můžete zabránit vypnutí virtuálního počítače spuštěním příkazu jetpack keepalive. V linuxových instancích můžete zadat časový rámec v hodinách nebo forever ve Windows forever je jedinou možností.
Poznámka
Když se zjistí, že virtuální počítač není v pořádku, agent HealthCheck požádá CycleCloud o ukončení virtuálního počítače. Virtuální počítač se nikdy místně nevyvítá pomocí shutdown příkazu . V případě, že virtuální počítač nebude moct komunikovat se službou CycleCloud, zůstane spuštěný, i když není v pořádku, dokud nebude dostupný ke službě CycleCloud.
Příklad
Jako jednoduchý příklad napíšeme skript HealthCheck, který zajistí, že virtuální počítač s Linuxem nebude aktivní déle než 24 hodin. Tento skript můžete použít k simulaci vyřazení s nízkou prioritou a otestovat, jak pracovní postup reaguje na vyřazený virtuální počítač. Tento skript se umístí do /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh.
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Poznámka
Tento skript můžete umístit na virtuální počítač prostřednictvím projektu CycleCloud nebo přidáním přímo při vytváření vlastní image.