Hromadné kopírování z databáze do Azure Data Exploreru pomocí šablony Azure Data Factory
Azure Data Explorer je rychlá plně spravovaná služba pro analýzu dat. Nabízí analýzu velkých objemů dat, která streamují z mnoha zdrojů, jako jsou aplikace, weby a zařízení IoT.
Pokud chcete kopírovat data z databáze v Oracle Serveru, Netezza, Teradata nebo SQL Serveru do Azure Data Exploreru, musíte načíst obrovské objemy dat z více tabulek. Data se obvykle musí rozdělit do jednotlivých tabulek, abyste mohli načíst řádky s více vlákny paralelně z jedné tabulky. Tento článek popisuje šablonu, která se má v těchto scénářích použít.
Šablony služby Azure Data Factory jsou předdefinované kanály služby Data Factory. Tyto šablony vám můžou pomoct rychle začít se službou Data Factory a zkrátit dobu vývoje projektů integrace dat.
Hromadné kopírování z databáze do šablony Azure Data Exploreru vytvoříte pomocí aktivit Vyhledávání a ForEach. Pro rychlejší kopírování dat můžete pomocí šablony vytvořit mnoho kanálů pro každou databázi nebo tabulku.
Důležité
Nezapomeňte použít nástroj, který je vhodný pro množství dat, která chcete zkopírovat.
- Pomocí šablony Hromadné kopírování z databáze do Azure Data Exploreru zkopírujte velké objemy dat z databází, jako je SQL server a Google BigQuery, do Azure Data Exploreru.
- Pomocí nástroje Pro kopírování dat služby Data Factory zkopírujte několik tabulek s malými nebo středními objemy dat do Azure Data Exploreru.
Požadavky
- Předplatné Azure. Vytvořte bezplatný účet Azure.
- Cluster a databáze Azure Data Exploreru. Vytvořte cluster a databázi.
- Datová továrna. Vytvořte datovou továrnu.
- Zdroj dat.
Create ControlTableDataset
ControlTableDataset označuje, jaká data se zkopírují ze zdroje do cíle v kanálu. Počet řádků označuje celkový počet kanálů potřebných ke zkopírování dat. Jako součást zdrojové databáze byste měli definovat ControlTableDataset.
Příklad formátu zdrojové tabulky SQL Serveru je uvedený v následujícím kódu:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Prvky kódu jsou popsány v následující tabulce:
| Vlastnost | Popis | Příklad |
|---|---|---|
| PartitionId | Pořadí kopírování | 0 |
| SourceQuery | Dotaz, který označuje, která data se zkopírují během modulu runtime kanálu. | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | Název cílové tabulky | Tabulka MyAdx |
Pokud je vaše ControlTableDataset v jiném formátu, vytvořte srovnatelný ControlTableDataset pro váš formát.
Použití hromadného kopírování z databáze do šablony Azure Data Exploreru
V podokně Začínáme vyberte Vytvořit kanál ze šablony a otevřete podokno Galerie šablon.
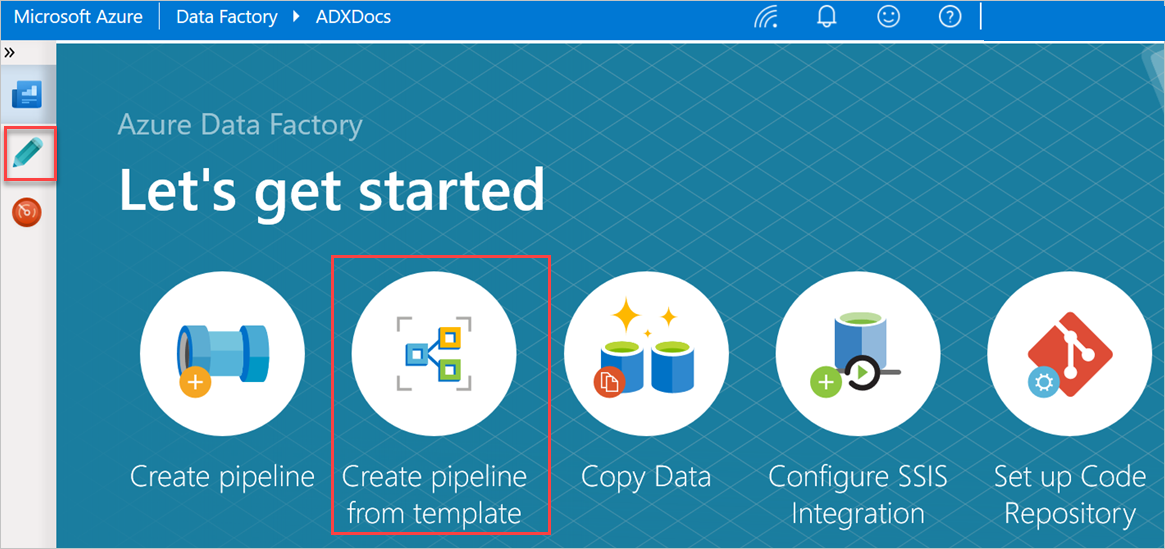
Vyberte šablonu Hromadné kopírování z databáze do Azure Data Exploreru.
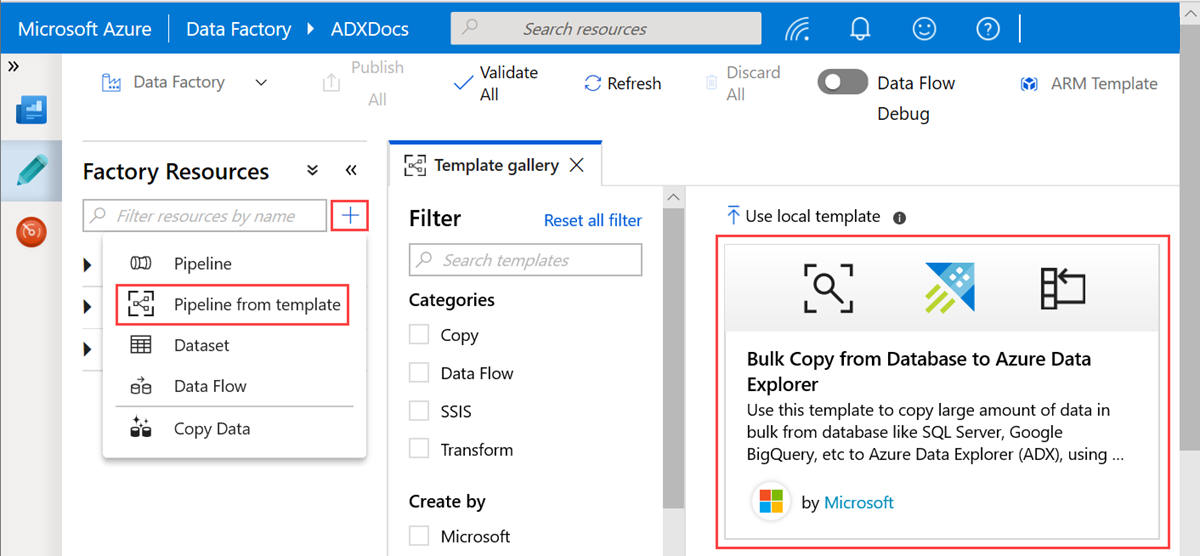
V podokně Hromadné kopírování z databáze do Azure Data Exploreru v části Vstupy uživatelů zadejte datové sady následujícím způsobem:
a. V rozevíracím seznamu ControlTableDataset vyberte propojenou službu s řídicí tabulkou, která označuje, jaká data se zkopírují ze zdroje do cíle a kam se umístí do cíle.
b. V rozevíracím seznamu SourceDataset vyberte propojenou službu se zdrojovou databází.
c. V rozevíracím seznamu AzureDataExplorerTable vyberte tabulku Azure Data Exploreru. Pokud datová sada neexistuje, vytvořte propojenou službu Azure Data Exploreru a přidejte datovou sadu.
d. Vyberte Použít tuto šablonu.
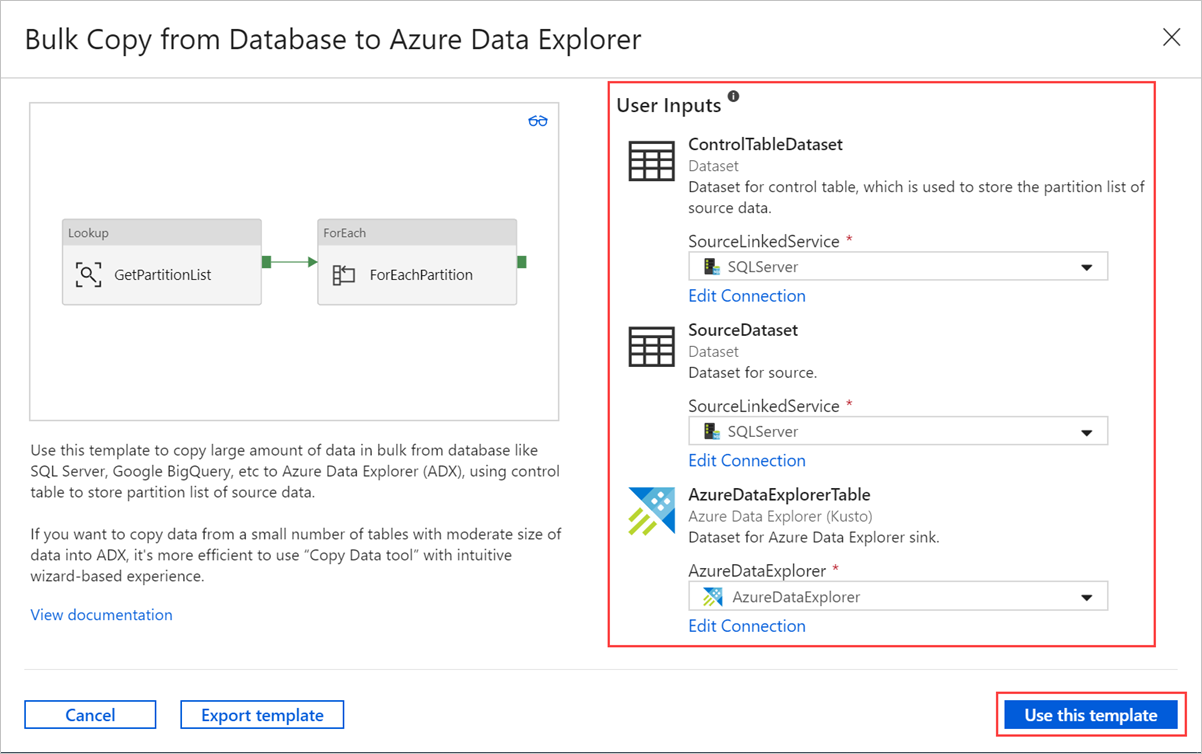
Pokud chcete získat přístup k kanálu šablony, vyberte oblast na plátně mimo aktivity. Vyberte kartu Parametry a zadejte parametry tabulky, včetně názvu tabulky (název řídicí tabulky) a výchozí hodnoty (názvy sloupců).
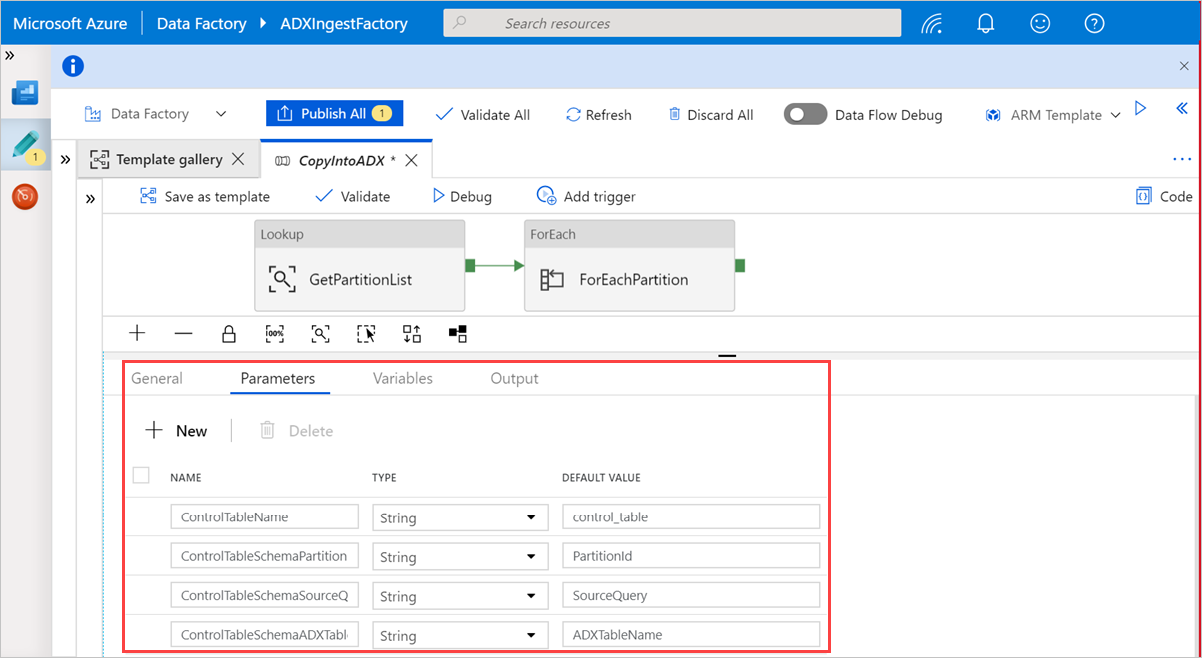
V části Vyhledat vyberte GetPartitionList a zobrazte výchozí nastavení. Dotaz se vytvoří automaticky.
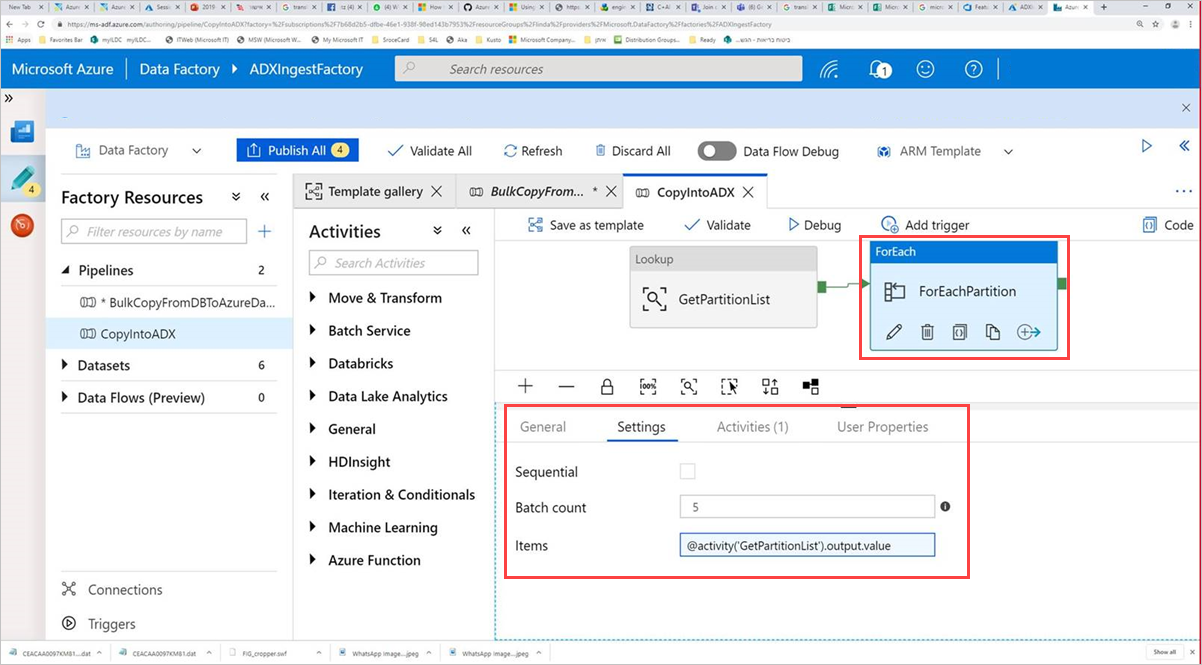
Vyberte aktivitu command, ForEachPartition, vyberte kartu Nastavení a pak udělejte toto:
a. Do pole Počet dávek zadejte číslo od 1 do 50. Tento výběr určuje počet kanálů, které se spouští paralelně, dokud nedosáhnete počtu řádků ControlTableDataset .
b. Chcete-li zajistit, aby dávky kanálu běžely paralelně, nevybírejte políčko Sekvenční .
Tip
Osvědčeným postupem je paralelně spouštět mnoho kanálů, aby bylo možné data zkopírovat rychleji. Pokud chcete zvýšit efektivitu, rozdělte data ve zdrojové tabulce a přidělte jeden oddíl na kanál podle data a tabulky.
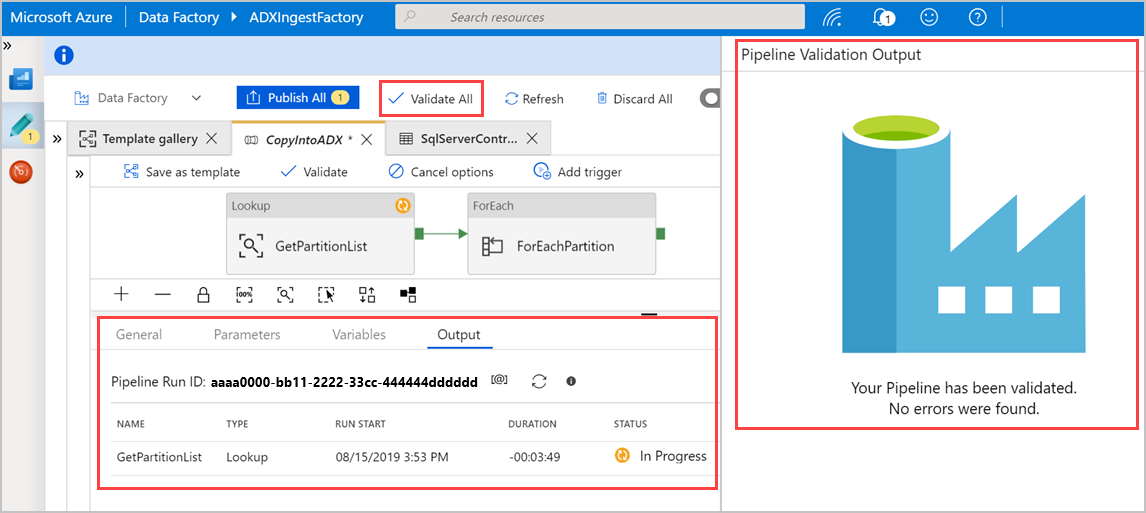
Výběrem možnosti Ověřit vše ověřte kanál Služby Azure Data Factory a pak zobrazte výsledek v podokně Výstup ověření kanálu.
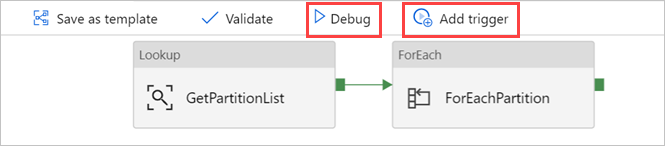
V případě potřeby vyberte Ladit a pak vyberte Přidat aktivační událost pro spuštění kanálu.
Pomocí šablony teď můžete efektivně kopírovat velké objemy dat z databází a tabulek.
Související obsah
- Přečtěte si o konektoru Azure Data Exploreru pro Azure Data Factory.
- Upravte propojené služby, datové sady a kanály v uživatelském rozhraní služby Data Factory.
- Dotazování dat ve webovém uživatelském rozhraní Azure Data Exploreru
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro