dbscan_fl()
Funkce dbscan_fl() je definovaná uživatelem (uživatelem definovaná funkce), která clusterizuje datovou sadu pomocí algoritmu DBSCAN.
Požadavky
- Modul plug-in Pythonu musí být v clusteru povolený. To se vyžaduje pro vložený Python použitý ve funkci.
- Modul plug-in Pythonu musí být v databázi povolený. To se vyžaduje pro vložený Python použitý ve funkci.
Syntaxe
T | invoke dbscan_fl(funkce, cluster_col, metric_params, ,metrik min_samples epsilon, )
Přečtěte si další informace o konvencích syntaxe.
Parametry
| Název | Type | Požadováno | Popis |
|---|---|---|---|
| features | dynamic |
✔️ | Pole obsahující názvy sloupců funkcí, které se mají použít pro clustering. |
| cluster_col | string |
✔️ | Název sloupce pro uložení ID výstupního clusteru pro každý záznam. |
| epsilon | real |
✔️ | Maximální vzdálenost mezi dvěma vzorky, které se mají považovat za sousedy. |
| min_samples | int |
Počet vzorků v okolí pro bod, který se má považovat za základní bod. | |
| metrický | string |
Metrika, která se má použít při výpočtu vzdálenosti mezi body. | |
| metric_params | dynamic |
Nadbytečné argumenty klíčových slov pro funkci metriky. |
- Podrobný popis parametrů najdete v dokumentaci k DBSCAN.
- Seznam metrik zobrazuje výpočty vzdálenosti.
Definice funkce
Funkci můžete definovat vložením jejího kódu jako funkce definovanou dotazem nebo vytvořením jako uložené funkce v databázi následujícím způsobem:
Definujte funkci pomocí následujícího příkazu let. Nejsou vyžadována žádná oprávnění.
Důležité
Příkaz let nemůže běžet samostatně. Musí následovat příkaz tabulkového výrazu. Pokud chcete spustit funkční příklad kmeans_fl(), podívejte se na příklad.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Příklad
Následující příklad používá operátor invoke ke spuštění funkce.
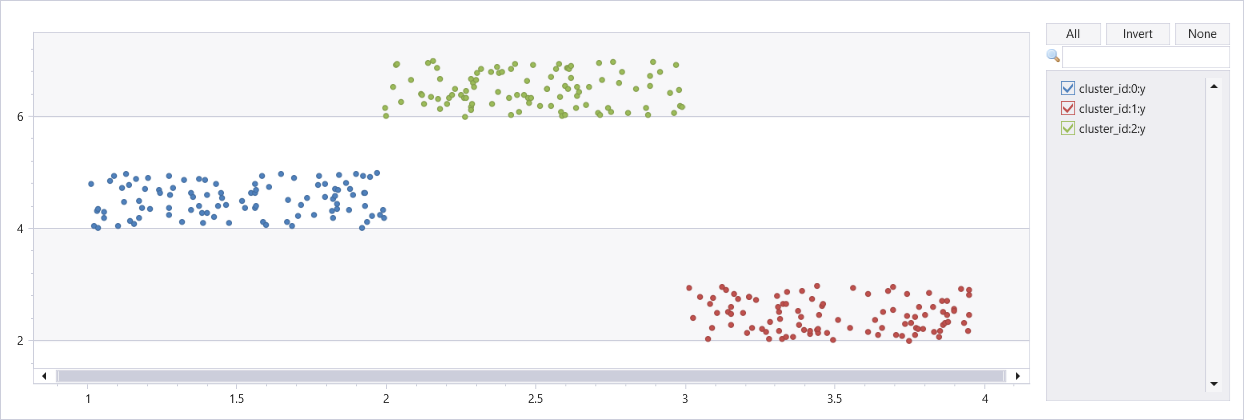
Clustering umělé datové sady se třemi clustery
Pokud chcete použít funkci definovanou dotazem, vyvoláte ji po definici vložené funkce.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)
Tato funkce není podporovaná.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro