series_mv_if_anomalies_fl()
Tato funkce series_mv_if_anomalies_fl() je uživatelem definovaná funkce (UDF), která detekuje vícevariátní anomálie v řadě použitím modelu doménové struktury izolace ze scikit-learn. Funkce přijímá sadu řad jako číselných dynamických polí, názvy sloupců funkcí a očekávané procento anomálií mimo celou řadu. Funkce vytvoří pro každou řadu soubor izolovaných stromů a označí body, které jsou rychle izolované jako anomálie.
Požadavky
- Modul plug-in Pythonu musí být v clusteru povolený. To se vyžaduje pro vložený Python použitý ve funkci.
- Modul plug-in Pythonu musí být v databázi povolený. To se vyžaduje pro vložený Python použitý ve funkci.
Syntaxe
T | invoke series_mv_if_anomalies_fl(features_cols anomaly_col [, score_col [, anomalies_pct [, num_trees [ , samples_pct ]]], )
Přečtěte si další informace o konvencích syntaxe.
Parametry
| Název | Type | Požadováno | Popis |
|---|---|---|---|
| features_cols | dynamic |
✔️ | Pole obsahující názvy sloupců, které se používají pro vícevariátový model detekce anomálií. |
| anomaly_col | string |
✔️ | Název sloupce pro uložení detekovaných anomálií. |
| score_col | string |
Název sloupce pro uložení skóre anomálií. | |
| anomalies_pct | real |
Reálné číslo v rozsahu [0–50] určující očekávané procento anomálií v datech. Výchozí hodnota: 4 %. | |
| num_trees | int |
Počet stromů izolace, které se mají vytvořit pro každou časnou řadu. Výchozí hodnota: 100. | |
| samples_pct | real |
Reálné číslo v rozsahu [0–100] určující procento vzorků použitých k sestavení jednotlivých stromů. Výchozí hodnota: 100 %, tj. použít celou řadu. |
Definice funkce
Funkci můžete definovat vložením jejího kódu jako funkce definovanou dotazem nebo vytvořením jako uložené funkce v databázi následujícím způsobem:
Definujte funkci pomocí následujícího příkazu let. Nejsou vyžadována žádná oprávnění.
Důležité
Příkaz let nemůže běžet samostatně. Musí následovat příkaz tabulkového výrazu. Pokud chcete spustit funkční příklad, podívejte se na příkladseries_mv_if_anomalies_fl().
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
Příklad
Následující příklad používá operátor invoke ke spuštění funkce.
Pokud chcete použít funkci definovanou dotazem, vyvoláte ji po definici vložené funkce.
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores', anomalies_pct=8, num_trees=1000)
| extend anomalies=series_multiply(40, anomalies)
| render timechart
Výstup
Tabulka normal_2d_with_anomalies obsahuje sadu tří časových řad. Každá časová řada má dvojrozměrné normální rozdělení s denními anomáliemi přidanými o půlnoci, 8:00 a 4:00. Tuto ukázkovou datovou sadu můžete vytvořit pomocí ukázkového dotazu.
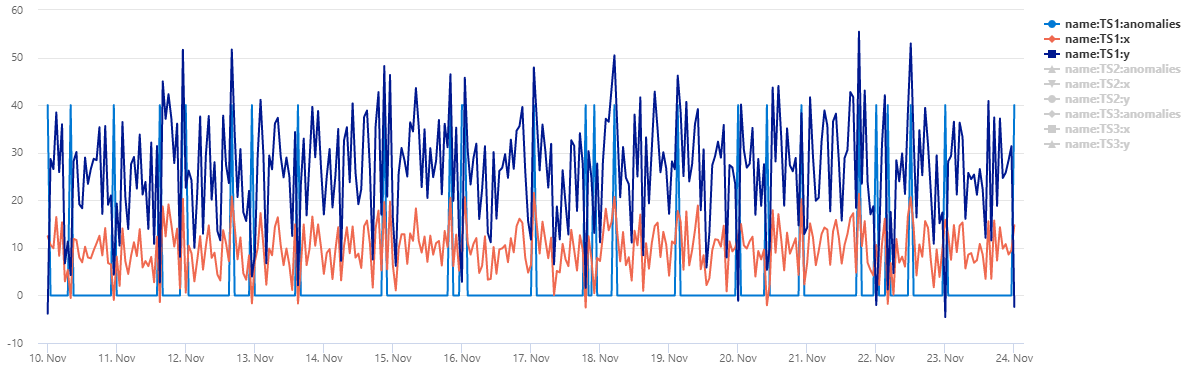
Pokud chcete zobrazit data jako bodový graf, nahraďte kód použití následujícím kódem:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
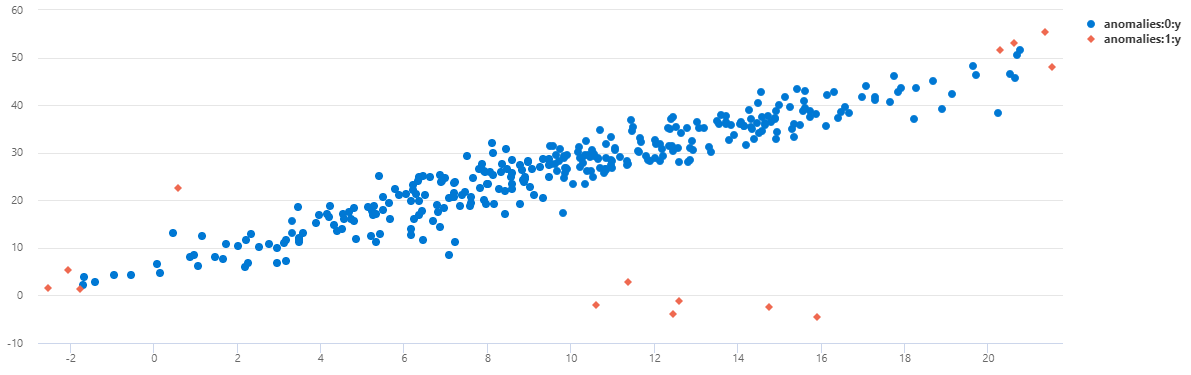
Na webu TS2 se většina anomálií, ke kterým dochází v 8:00, zjistila pomocí tohoto multivariátního modelu.
Tato funkce není podporovaná.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro