dcount() (agregační funkce)
Vypočítá odhad počtu jedinečných hodnot přijatých skalárním výrazem ve skupině souhrnu.
Hodnoty Null se ignorují a nefaktorují do výpočtu.
Poznámka:
Agregační dcount() funkce je primárně užitečná pro odhad kardinality obrovských sad. Obchoduje přesnost za výkon a může vrátit výsledek, který se mezi provedeními liší. Pořadí vstupů může mít vliv na jeho výstup.
Syntaxe
dcount(výraz[, přesnost])
Přečtěte si další informace o konvencích syntaxe.
Parametry
| Název | Type | Požadováno | Popis |
|---|---|---|---|
| výraz | string |
✔️ | Vstup, jehož jedinečné hodnoty se mají spočítat. |
| přesnost | int |
Hodnota, která definuje požadovanou přesnost odhadu. Výchozí hodnota je 1. Viz přesnost odhadu podporovaných hodnot. |
Návraty
Vrátí odhad počtu jedinečných hodnot výrazu ve skupině.
Příklad
Tento příklad ukazuje, kolik typů událostí stormu proběhlo v jednotlivých stavech.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
Zobrazená tabulka výsledků obsahuje pouze prvních 10 řádků.
| State | DifferentEvents |
|---|---|
| TEXAS | 27 |
| KALIFORNIE | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| MARYLAND | 23 |
| NORTH CAROLINA | 23 |
| MICHIGAN | 22 |
| FLORIDA | 22 |
| OREGON | 21 |
| KANSAS | 21 |
| ... | ... |
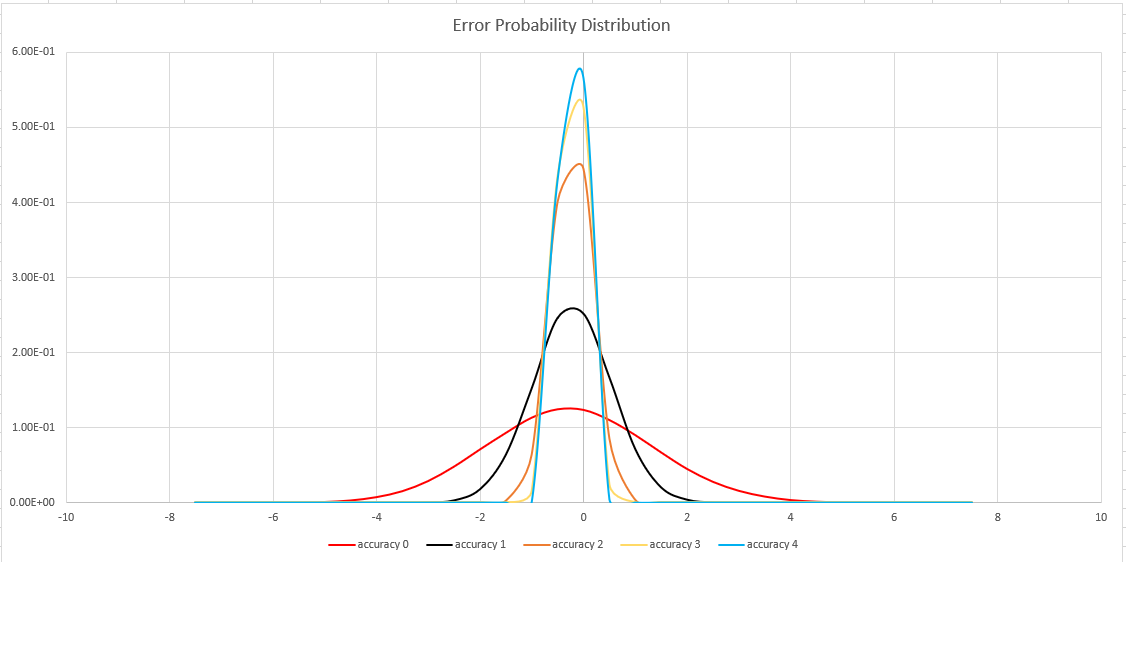
Přesnost odhadu
Tato funkce používá variantu algoritmu HyperLogLog (HLL), který provede stochastický odhad kardinality sady. Algoritmus poskytuje "knoflík", který lze použít k vyvážení přesnosti a doby provádění na velikost paměti:
| Přesnost | Chyba (%) | Počet položek |
|---|---|---|
| 0 | 1.6 | 212 |
| 0 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Poznámka:
Sloupec "entry count" je počet čítačů 1 bajtů v implementaci HLL.
Algoritmus obsahuje některá ustanovení pro dosažení dokonalého počtu (nula chyb), pokud je nastavená kardinalita dostatečně malá:
- Pokud je
1úroveň přesnosti , vrátí se 1 000 hodnot. - Pokud je
2úroveň přesnosti , vrátí se 8 000 hodnot.
Svázaná chyba je pravděpodobnostní, nikoli teoretická mez. Hodnota je směrodatná odchylka rozdělení chyb (sigma) a 99,7 % odhadů bude mít relativní chybu pod 3 x sigma.
Následující obrázek znázorňuje funkci rozdělení pravděpodobnosti relativní chyby odhadu v procentech pro všechna podporovaná nastavení přesnosti:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro