Diagnostika anomálií pro analýzu původní příčiny
dotazovací jazyk Kusto (KQL) má integrované funkce pro detekci anomálií a prognózování, které kontrolují neobvyklé chování. Jakmile je takový vzor zjištěn, je možné spustit analýzu původní příčiny (RCA), která anomálii zmírní nebo vyřeší.
Proces diagnostiky je složitý a zdlouhavý a provádí ho odborníci na danou oblast. Tento proces zahrnuje:
- Načítání a spojování dalších dat z různých zdrojů ve stejném časovém rámci
- Hledání změn v rozdělení hodnot ve více dimenzích
- Graf dalších proměnných
- Další techniky založené na znalostech domény a intuitivně
Vzhledem k tomu, že tyto scénáře diagnostiky jsou běžné, jsou k dispozici moduly plug-in strojového učení, které usnadňují fázi diagnostiky a zkracují dobu trvání analýzy RCA.
Všechny tři následující moduly plug-in Machine Learning implementují algoritmy clusteringu: autocluster, basketa diffpatterns. Moduly autocluster plug-in a basket seskupují jednu sadu záznamů a diffpatterns moduly plug-in clusterují rozdíly mezi dvěma sadami záznamů.
Seskupování jedné sady záznamů
Mezi běžné scénáře patří datová sada vybraná podle konkrétních kritérií, například:
- Časové okno, které zobrazuje neobvyklé chování
- Odečty vysokoteplotní zařízení
- Příkazy s dlouhou dobou trvání
- Uživatelé s nejvyšší útratou: Chcete mít rychlý a snadný způsob, jak v datech najít běžné vzory (segmenty). Vzory jsou podmnožinou datové sady, jejíž záznamy sdílejí stejné hodnoty ve více dimenzích (sloupce kategorií).
Následující dotaz sestaví a zobrazí časovou řadu výjimek služeb za období týdne v desetiminutových intervalech:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
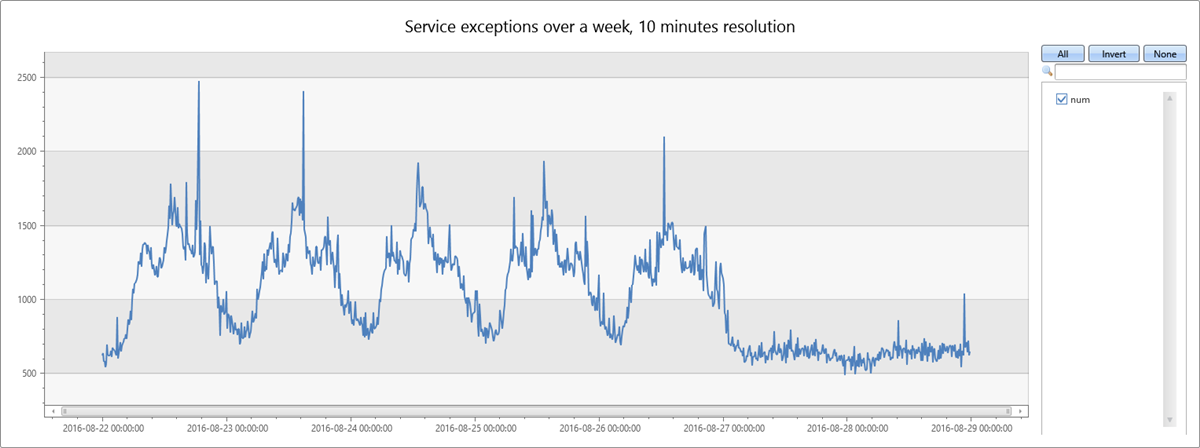
Počet výjimek služby koreluje s celkovým provozem služby. Můžete jasně vidět denní vzor pro pracovní dny, od pondělí do pátku. V polovině dne dochází k nárůstu počtu výjimek služeb a poklesu počtu výjimek v noci. Nízké počty ploch jsou viditelné během víkendu. Špičky výjimek lze detekovat pomocí detekce anomálií časových řad.
K druhému nárůstu dat dochází v úterý odpoledne. Následující dotaz slouží k další diagnostice a ověření, jestli se jedná o ostrý nárůst. Dotaz překreslí graf kolem špičky ve vyšším rozlišení 8 hodin v minutových intervalech. Pak můžete studovat jeho hranice.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
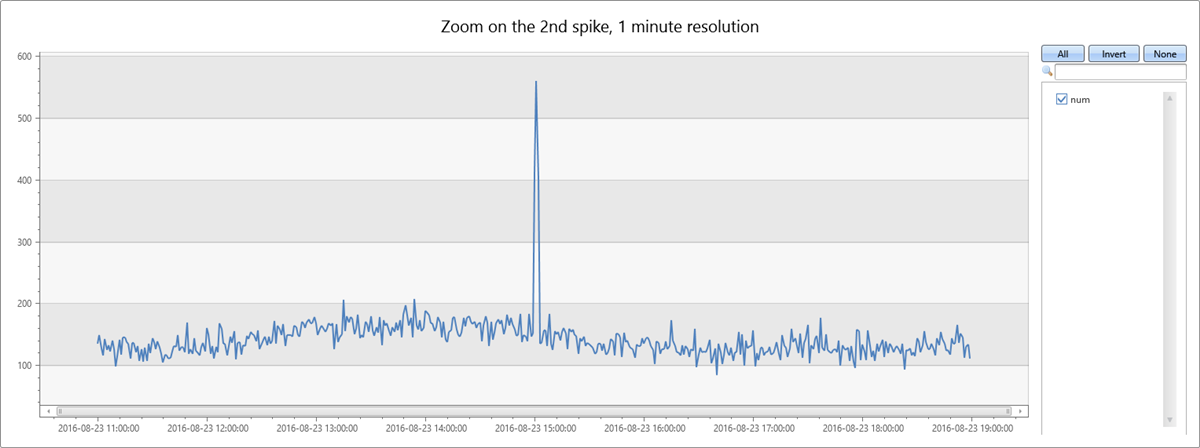
Od 15:00 do 15:02 uvidíte úzký dvouminutový nárůst. V následujícím dotazu spočítejte výjimky v tomto dvouminutovém intervalu:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Počet |
|---|
| 972 |
V následujícím dotazu ukázka 20 výjimek z 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Oblast | ScaleUnit | Id nasazení | Trasovací bod | Servicehost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | Su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | Su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | Su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8eee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | Su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Použití autocluster() pro clustering s jednou sadou záznamů
I když existuje méně než tisíc výjimek, je stále těžké najít běžné segmenty, protože v každém sloupci je více hodnot. Pomocí modulu plug-in můžete autocluster() okamžitě extrahovat krátký seznam běžných segmentů a najít zajímavé clustery během dvou minut špičky, jak je vidět v následujícím dotazu:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| Id segmentu | Počet | Procento | Oblast | Jednotka škálování | Id nasazení | Servicehost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | Su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | Zeu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Z výše uvedených výsledků můžete vidět, že nejvíce dominantní segment obsahuje 65,74 % z celkového počtu záznamů výjimek a sdílí čtyři dimenze. Další segment je mnohem méně běžný. Obsahuje pouze 9,67 % záznamů a má tři rozměry. Ostatní segmenty jsou ještě méně časté.
Autocluster používá proprietární algoritmus pro dolování více dimenzí a extrakci zajímavých segmentů. "Zajímavé" znamená, že každý segment má významné pokrytí jak sady záznamů, tak sady funkcí. Segmenty jsou také rozbíhající, což znamená, že každý z nich se liší od ostatních. Jeden nebo více těchto segmentů může být pro proces ANALÝZY RCA relevantní. Pokud chcete minimalizovat kontrolu a hodnocení segmentů, autocluster extrahuje jenom malý seznam segmentů.
Použití basket() pro clustering s jednou sadou záznamů
Můžete také použít modul plug-in basket() , jak je vidět v následujícím dotazu:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| Id segmentu | Počet | Procento | Oblast | ScaleUnit | Id nasazení | Trasovací bod | Servicehost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | Zeu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Košík implementuje algoritmus "Apriori" pro dolování sad položek. Extrahuje všechny segmenty, jejichž pokrytí sady záznamů překračuje prahovou hodnotu (výchozí hodnota je 5 %). Můžete vidět, že se extrahovaly další segmenty s podobnými segmenty, například segmenty 0, 1 nebo 2, 3.
Oba moduly plug-in jsou výkonné a snadno použitelné. Jejich omezení spočívá v tom, že bez dohledu seskupí jednu sadu záznamů bez popisků. Není jasné, jestli extrahované vzory charakterizují vybranou sadu záznamů, neobvyklé záznamy nebo globální sadu záznamů.
Seskupování rozdílu mezi dvěma sadami záznamů
Modul diffpatterns() plug-in překonává omezení a basketautocluster . Diffpatterns vezme dvě sady záznamů a extrahuje hlavní segmenty, které se liší. Jedna sada obvykle obsahuje neobvyklou sadu záznamů, která se zkoumá. Jeden je analyzován pomocí autocluster a basket. Druhá sada obsahuje referenční sadu záznamů, směrný plán.
V následujícím dotazu diffpatterns najde zajímavé clustery během dvou minut špičky, které se liší od clusterů v rámci směrného plánu. Okno směrného plánu je definováno jako osm minut před 15:00, kdy začal špička. Rozšíříte o binární sloupec (AB) a určíte, jestli konkrétní záznam patří ke směrnému plánu nebo k neobvyklé množině. Diffpatterns implementuje algoritmus učení pod dohledem, kde byly dva popisky tříd generovány anomálií a příznakem standardního plánu (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| Id segmentu | CountA | Počet B | PercentA | PercentB | PercentDiffAB | Oblast | ScaleUnit | Id nasazení | Trasovací bod |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | Zeu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Nejvíce dominantní segment je stejný segment, který byl extrahován nástrojem autocluster. Jeho pokrytí ve dvouminutovém intervalu je také 65,74 %. Jeho pokrytí v osmiminutovém intervalu směrného plánu je však pouze 1,7 %. Rozdíl je 64,04 %. Zdá se, že tento rozdíl souvisí s anomální špičkou. Pro ověření tohoto předpokladu rozdělí následující dotaz původní graf na záznamy, které patří do tohoto problematického segmentu, a záznamy z ostatních segmentů.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
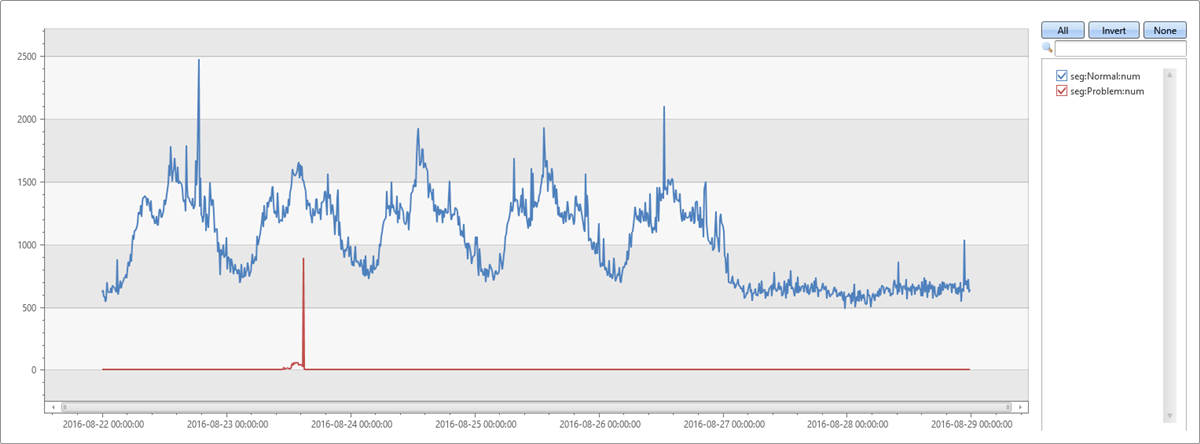
Tento graf nám umožňuje vidět, že špička v úterý odpoledne byla způsobená výjimkami z tohoto konkrétního segmentu, které byly zjištěny pomocí modulu plug-in diffpatterns .
Souhrn
Moduly plug-in služby Machine Learning jsou užitečné pro mnoho scénářů. Implementujte autocluster a basket implementujte algoritmus učení bez dohledu a snadno se používají. Diffpatterns implementuje algoritmus učení pod dohledem, a i když je složitější, je výkonnější pro extrakci segmentů diferenciace pro ANALÝZU RCA.
Tyto moduly plug-in se používají interaktivně v ad hoc scénářích a v automatických monitorovacích službách téměř v reálném čase. Po detekci anomálií časových řad následuje proces diagnostiky. Proces je vysoce optimalizovaný tak, aby splňoval nezbytné standardy výkonu.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro