Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Monitor shromažďuje a agreguje metriky a protokoly z vašeho systému za účelem monitorování dostupnosti, výkonu a odolnosti a upozorní vás na problémy ovlivňující váš systém. K nastavení a zobrazení dat monitorování můžete použít Azure Portal, PowerShell, Azure CLI, ROZHRANÍ REST API nebo klientské knihovny.
Různé metriky a protokoly jsou k dispozici pro různé typy prostředků. Tento článek popisuje typy dat monitorování, která můžete pro tuto službu shromažďovat, a způsoby analýzy těchto dat.
Shromažďování dat pomocí služby Azure Monitor
Tato tabulka popisuje, jak můžete shromažďovat data pro monitorování služby a co můžete s daty dělat po shromáždění:
| Data ke shromažďování | Popis | Jak shromažďovat a směrovat data | Kde zobrazit data | Podporovaná data |
|---|---|---|---|---|
| Metrická data | Metriky jsou číselné hodnoty, které popisují aspekt systému v určitém časovém okamžiku. Agregujte metriky pomocí algoritmů, porovnejte metriky s jinými metrikami a analyzujte metriky pro trendy v průběhu času. | - Shromažďuje se automaticky v pravidelných intervalech.
– Některé metriky platformy můžete směrovat do pracovního prostoru služby Log Analytics a dotazovat se na jiná data. Zkontrolujte nastavení exportu |
průzkumník metrik | metriky Azure Data Exploreru podporované službou Azure Monitor |
| Data protokolu zdrojů | Protokoly jsou zaznamenané systémové události s časovým razítkem. Záznamy mohou obsahovat různé typy dat a mohou být strukturované nebo ve volném textu. Data protokolu prostředků můžete směrovat do pracovních prostorů služby Log Analytics pro dotazování a analýzu. | Vytvořte nastavení diagnostiky pro shromažďování a směrování dat protokolu prostředků. | Analýza protokolů | data protokolu prostředků Azure Data Exploreru podporovaná službou Azure Monitor |
| Záznamová data aktivit | Protokol aktivit služby Azure Monitor poskytuje přehled o událostech na úrovni předplatného. Protokol aktivit obsahuje informace, jako je změna prostředku nebo spuštění virtuálního počítače. | - Shromažďuje se automaticky.
- Vytvořit nastavení diagnostiky do pracovního prostoru služby Log Analytics bez poplatků. |
protokol aktivit |
Seznam všech dat podporovaných službou Azure Monitor najdete tady:
Integrované monitorování pro Azure Data Explorer
Azure Data Explorer nabízí metriky a protokoly pro monitorování služby.
Monitorování výkonu, stavu a využití Azure Data Exploreru pomocí metrik
Metriky Azure Data Exploreru poskytují klíčové ukazatele o stavu a výkonu prostředků clusteru Azure Data Exploreru. Pomocí metrik můžete monitorovat využití, stav a výkon clusteru Azure Data Exploreru ve vašem konkrétním scénáři jako samostatné metriky. Metriky můžete také použít jako základ pro provozní řídicí panely Azure a upozornění Azure .
Použití metrik k monitorování prostředků Azure Data Exploreru na webu Azure Portal:
- Přihlaste se na portál Azure.
- V levém podokně clusteru Azure Data Exploreru vyhledejte metriky .
- Výběrem Metriky otevřete podokno metrik a začněte analyzovat cluster.
V podokně metrik vyberte konkrétní metriky, které chcete sledovat, zvolte, jak agregovat data, a vytvořit grafy metrik pro zobrazení na řídicím panelu.
Pro váš cluster Azure Data Explorer jsou předem vybrány nástroje pro výběr prostředků a metriku oboru názvů . Čísla na následujícím obrázku odpovídají číslovaného seznamu. Provedou vás různými možnostmi při nastavování a prohlížení metrik.

- Chcete-li vytvořit metrický graf, vyberte název metriky a relevantní agregaci pro každou metrik. Další informace o různých metrikách najdete v tématu podporované metriky Azure Data Exploreru.
- Výběrem Přidat metriku zobrazíte více metrik vykreslených ve stejném grafu.
- Pokud chcete zobrazit více grafů v jednom zobrazení, vyberte + Nový graf.
- Pomocí nástroje pro výběr času můžete změnit časový rozsah (výchozí hodnota: posledních 24 hodin).
- Použijte apro přidání filtru a aplikujte rozdělení pro metriky, které mají dimenze.
- Vyberte Připnout na řídicí panel přidejte konfiguraci grafu do řídicích panelů, abyste ji mohli znovu zobrazit.
- Nastavte nové pravidlo upozornění pro vizualizaci metrik pomocí nastavených kritérií. Nové pravidlo upozornění zahrnuje cílový prostředek, metriku, rozdělení a filtrovací dimenze z grafu. Upravte tato nastavení v podokně vytváření pravidla upozornění .
Monitorování příjmu dat, příkazů, dotazů a tabulek Azure Data Exploreru pomocí diagnostických protokolů
Azure Data Explorer je rychlá plně spravovaná služba pro analýzu dat v reálném čase pro analýzu velkých objemů dat streamovaných z aplikací, webů, zařízení IoT a dalších. Protokoly prostředků Azure Monitoru poskytují data o provozu prostředků Azure. Azure Data Explorer používá diagnostické protokoly pro přehledy o příjmu dat, příkazech, dotazech a tabulkách. Protokoly operací můžete exportovat do služby Azure Storage, centra událostí nebo Log Analytics, abyste mohli monitorovat příjem dat, příkazy a stav dotazů. Protokoly ze služby Azure Storage a Azure Event Hubs je možné směrovat do tabulky v clusteru Azure Data Exploreru pro další analýzu.
Důležitý
Data diagnostického protokolu můžou obsahovat citlivá data. Omezte oprávnění cíle protokolů podle potřeb monitorování.
Poznámka
V Azure portálu jsou metriky na stránkách Metrics a Insights uloženy jako nezpracovaná data v Azure Monitoru. Dotazy na těchto stránkách dotazují nezpracovaná data metrik přímo tak, aby poskytovaly nejpřesnější výsledky. Při použití funkce nastavení diagnostiky můžete migrovat nezpracovaná data metrik do pracovního prostoru služby Log Analytics. Během migrace může dojít ke ztrátě určité přesnosti dat z důvodu zaokrouhlení; výsledky dotazu se proto mohou mírně lišit od původních dat. Okraj chyby je menší než jedno procento.
Diagnostické protokoly můžete použít ke konfiguraci shromažďování následujících protokolových dat:
Poznámka
- Protokoly záznamů o příjmu podporují příjem dat ve frontě do URI pro příjem dat pomocí klientských knihoven Kusto a datových konektorů.
- Protokoly příjmu dat nepodporují streamování příjmu dat, přímý příjem dat do URI clusteru, příjem dat z dotazu nebo příkazy
.set-or-append.
Poznámka
Protokoly o neúspěšném příjmu dat hlásí pouze konečný stav operace ingestování, na rozdíl od metriky výsledků ingestování, která se vygeneruje kvůli přechodným selháním, která jsou interně znovu zpracovávána.
- Úspěšné operace příjmu: Tyto protokoly obsahují informace o úspěšně dokončených operacích příjmu.
- Neúspěšné operace příjmu dat: Tyto protokoly obsahují podrobné informace o neúspěšných operacích příjmu dat, včetně podrobností o chybě.
- Operace dávkového příjmu dat: Tyto protokoly obsahují podrobné statistiky dávek připravených k příjmu dat, jako je trvání, velikost dávky, počet blobů a typy dávek).
Data protokolu můžete odeslat do pracovního prostoru služby Log Analytics, účtu úložiště nebo streamovat data do centra událostí.
Diagnostické protokoly jsou ve výchozím nastavení zakázané. Pomocí následujících kroků povolte diagnostické protokoly pro váš cluster:
Na Azure portáluvyberte clusterový prostředek, který chcete sledovat.
V části Monitorovánívyberte nastavení diagnostiky.
Vyberte Přidat nastavení diagnostiky.
V okně nastavení diagnostiky :
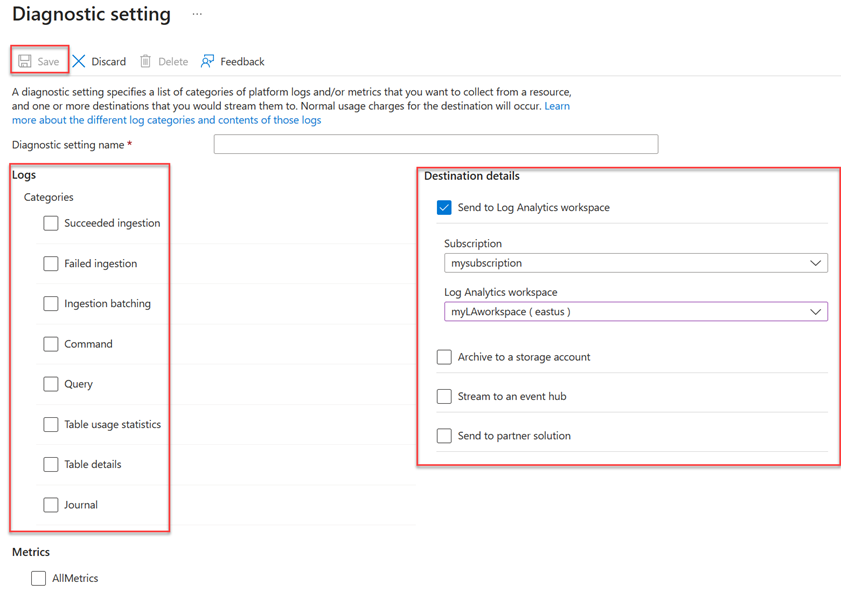
- Zadejte název nastavení diagnostiky .
- Vyberte jeden nebo více cílových cílů: pracovní prostor služby Log Analytics, účet úložiště nebo centrum událostí.
- Vyberte protokoly, které chcete shromáždit: úspěšný příjem dat, neúspěšný příjem dat, dávkování příjmu dat, příkaz, dotaz, statistika využití tabulek, podrobnosti o tabulce nebo deník.
- Vyberte metriky , které chcete shromáždit (volitelné).
- Vyberte Uložit a uložte nová nastavení diagnostických protokolů a metriky.



Po vytvoření nastavení se protokoly začnou zobrazovat v nakonfigurovaných cílových cílech: účet úložiště, centrum událostí nebo pracovní prostor služby Log Analytics.
Poznámka
Pokud odesíláte protokoly do pracovního prostoru služby Log Analytics, protokoly SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailsa Journal se ukládají v tabulkách Log Analytics s názvy: SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailsa ADXJournal.
Analýza dat pomocí nástrojů Azure Monitoru
Tyto nástroje Azure Monitoru jsou k dispozici na webu Azure Portal, které vám pomůžou analyzovat data monitorování:
Některé služby Azure mají integrovaný řídicí panel monitorování na webu Azure Portal. Tyto řídicí panely se nazývají přehledya najdete je v části Insights azure Monitoru na webu Azure Portal.
Průzkumník metrik umožňuje zobrazit a analyzovat metriky pro prostředky Azure. Další informace najdete v tématu Analýza metrik pomocí Průzkumníka metrik služby Azure Monitor.
Log Analytics umožňuje dotazovat a analyzovat data protokolu pomocí dotazovacího jazyka Kusto (KQL). Další informace najdete v tématu Začínáme s dotazy na protokoly ve službě Azure Monitor. Azure Portal má uživatelské rozhraní pro zobrazení a základní vyhledávání protokolu aktivit . Pokud chcete provádět podrobnější analýzu, nasměrujte data do protokolů služby Azure Monitor a spusťte složitější dotazy v Log Analytics.
Application Insights monitoruje dostupnost, výkon a využití webových aplikací, abyste mohli identifikovat a diagnostikovat chyby, aniž byste čekali, až je uživatel nahlásí.
Application Insights zahrnuje body připojení k různým vývojovým nástrojům a integruje se se sadou Visual Studio pro podporu procesů DevOps. Další informace najdete v tématu Monitorování aplikací pro službu App Service.
Mezi nástroje, které umožňují složitější vizualizaci, patří:
- řídicí panely, které umožňují kombinovat různé druhy dat do jednoho podokna na webu Azure Portal.
- Sešity, přizpůsobitelné sestavy, které můžete vytvořit na portálu Azure. Sešity mohou obsahovat text, metriky a dotazy na protokoly.
- Grafana, otevřený nástroj platformy, který exceluje v provozních řídicích panelech. Grafana umožňuje vytvářet řídicí panely, které obsahují data z více zdrojů, než je Azure Monitor.
- Power BI , služba obchodní analýzy, která poskytuje interaktivní vizualizace napříč různými zdroji dat. Power BI můžete nakonfigurovat tak, aby automaticky naimportovali data protokolů ze služby Azure Monitor, abyste mohli tyto vizualizace využívat.
Export dat Azure Monitoru
Data ze služby Azure Monitor můžete exportovat do jiných nástrojů pomocí:
Metriky : Pomocí rozhraní REST API pro metriky extrahujte data metrik z databáze metrik služby Azure Monitor. Další informace viz v referenční dokumentaci k rozhraní API služby Azure Monitor.
Logy: Využijte rozhraní REST API nebo přidružené klientské knihovny.
export dat pracovního prostoru Log Analytics.
Pokud chcete začít s rozhraním REST API pro Azure Monitor, přečtěte si průvodce k rozhraní REST API pro Azure Monitor.
Analýza dat protokolu pomocí dotazů Kusto
Data protokolu služby Azure Monitor můžete analyzovat pomocí dotazovacího jazyka Kusto (KQL). Další informace najdete v tématu dotazy protokolu ve službě Azure Monitor.
Upozorňování na problémy pomocí upozornění služby Azure Monitor
upozornění služby Azure Monitor umožňují identifikovat a řešit problémy ve vašem systému a proaktivně vás informovat, když se v datech monitorování nacházejí konkrétní podmínky, než si je zákazníci všimnou. Na libovolnou metriku nebo zdroj dat protokolu můžete upozornit na datové platformě Azure Monitoru. Existují různé typy upozornění služby Azure Monitor v závislosti na službách, které monitorujete, a na datech monitorování, která shromažďujete. Viz Volba správného typu pravidla upozornění.
Příklady běžných upozornění pro prostředky Azure viz Ukázkové dotazy na protokolové výstrahy.
Implementace výstrah ve velkém měřítku
U některých služeb můžete monitorovat škálování použitím stejného pravidla upozornění na metriku u více prostředků stejného typu, které existují ve stejné oblasti Azure. Azure Monitor Baseline Alerts (AMBA) poskytuje poloautomatickou metodu implementace důležitých alertů metrik platformy, řídicích panelů a pokynů ve velkém měřítku.
Získání přizpůsobených doporučení pomocí Azure Advisoru
U některých služeb se v případě, že během operací prostředků dojde k kritickým nebo bezprostředním změnám, zobrazí se na stránce přehledu služby
Další informace o službě Azure Advisor najdete v tématu PřehledAzure Advisor.