Transformace kontingenční tabulky při mapování toku dat
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Pomocí transformace kontingenční tabulky můžete vytvořit více sloupců z jedinečných hodnot řádků jednoho sloupce. Pivot je transformace agregace, ve které vyberete seskupení podle sloupců a vygenerujete kontingenční sloupce pomocí agregačních funkcí.
Konfigurace
Transformace kontingenční tabulky vyžaduje tři různé vstupy: seskupení podle sloupců, klíč kontingenční tabulky a způsob generování kontingenčních sloupců.
Seskupit podle
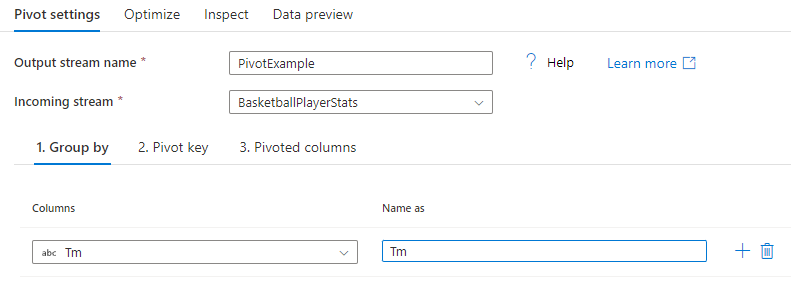
Vyberte sloupce, které se mají agregovat v kontingenčních sloupcích. Výstupní data seskupí všechny řádky se stejnou skupinou podle hodnot do jednoho řádku. Agregace provedená v kontingenčním sloupci bude probíhat v každé skupině.
Tato část je nepovinná. Pokud nejsou vybrány žádné sloupce, bude agregovaný celý datový proud a výstupem bude pouze jeden řádek.
Pivot key
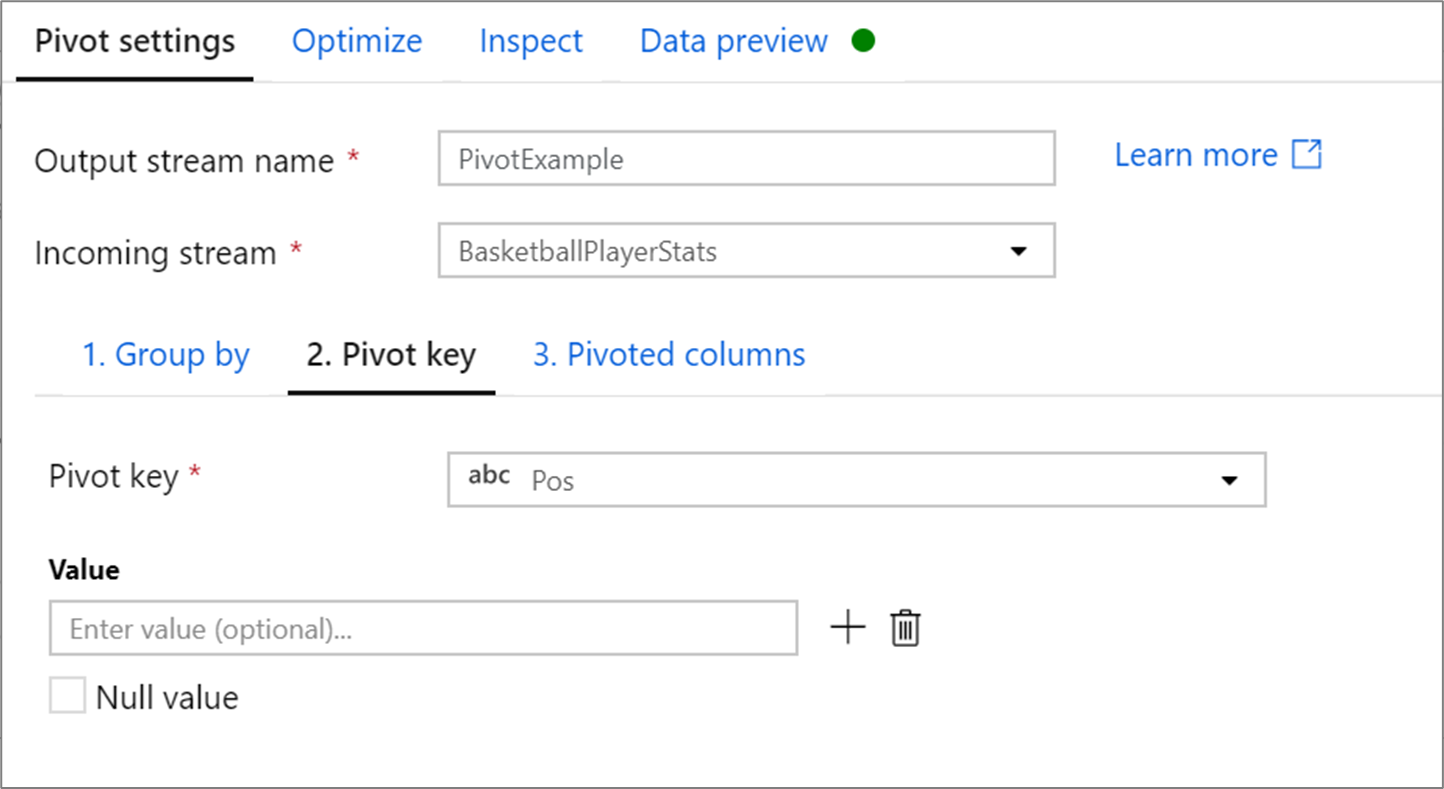
Pivot key je sloupec, jehož hodnoty řádků se přetáhly do nových sloupců. Ve výchozím nastavení transformace kontingenční tabulky vytvoří nový sloupec pro každou jedinečnou hodnotu řádku.
V oddílu s popiskem Hodnota můžete zadat konkrétní hodnoty řádků, které se mají převést. V tomto oddílu budou převedeny pouze hodnoty řádků zadané v tomto oddílu. Povolení hodnoty Null vytvoří kontingenční sloupec pro hodnoty null ve sloupci.
Kontingenční sloupce
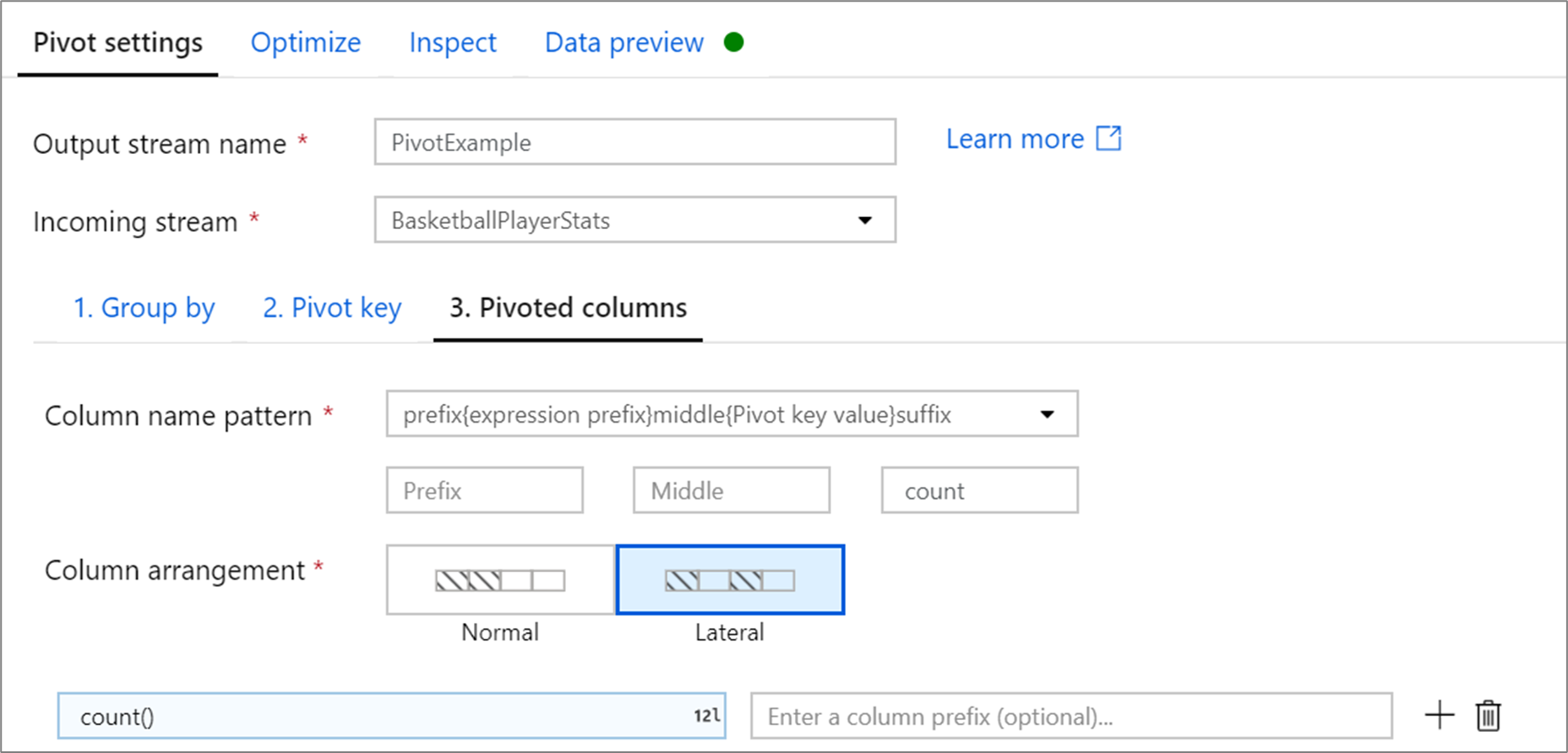
Pro každou jedinečnou hodnotu klíče kontingenční tabulky, která se stane sloupcem, vygenerujte pro každou skupinu agregovanou hodnotu řádku. Na klíč kontingenční tabulky můžete vytvořit více sloupců. Každý kontingenční sloupec musí obsahovat aspoň jednu agregační funkci.
Vzor názvu sloupce: Vyberte, jak formátovat název sloupce každého kontingenčního sloupce. Název výstupního sloupce bude kombinací hodnoty klíče kontingenční tabulky, předpony sloupce a volitelné předpony, přípony, prostředních znaků.
Uspořádání sloupců: Pokud pro klíč kontingenční tabulky vygenerujete více než jeden kontingenční sloupec, zvolte, jak chcete sloupce uspořádat.
Předpona sloupce: Pokud pro každý klíč kontingenční tabulky vygenerujete více než jeden kontingenční sloupec, zadejte předponu sloupce pro každý sloupec. Toto nastavení je volitelné, pokud máte jenom jeden kontingenční sloupec.
Obrázek nápovědy
Následující obrázek nápovědy ukazuje, jak různé kontingenční komponenty vzájemně spolupracují.
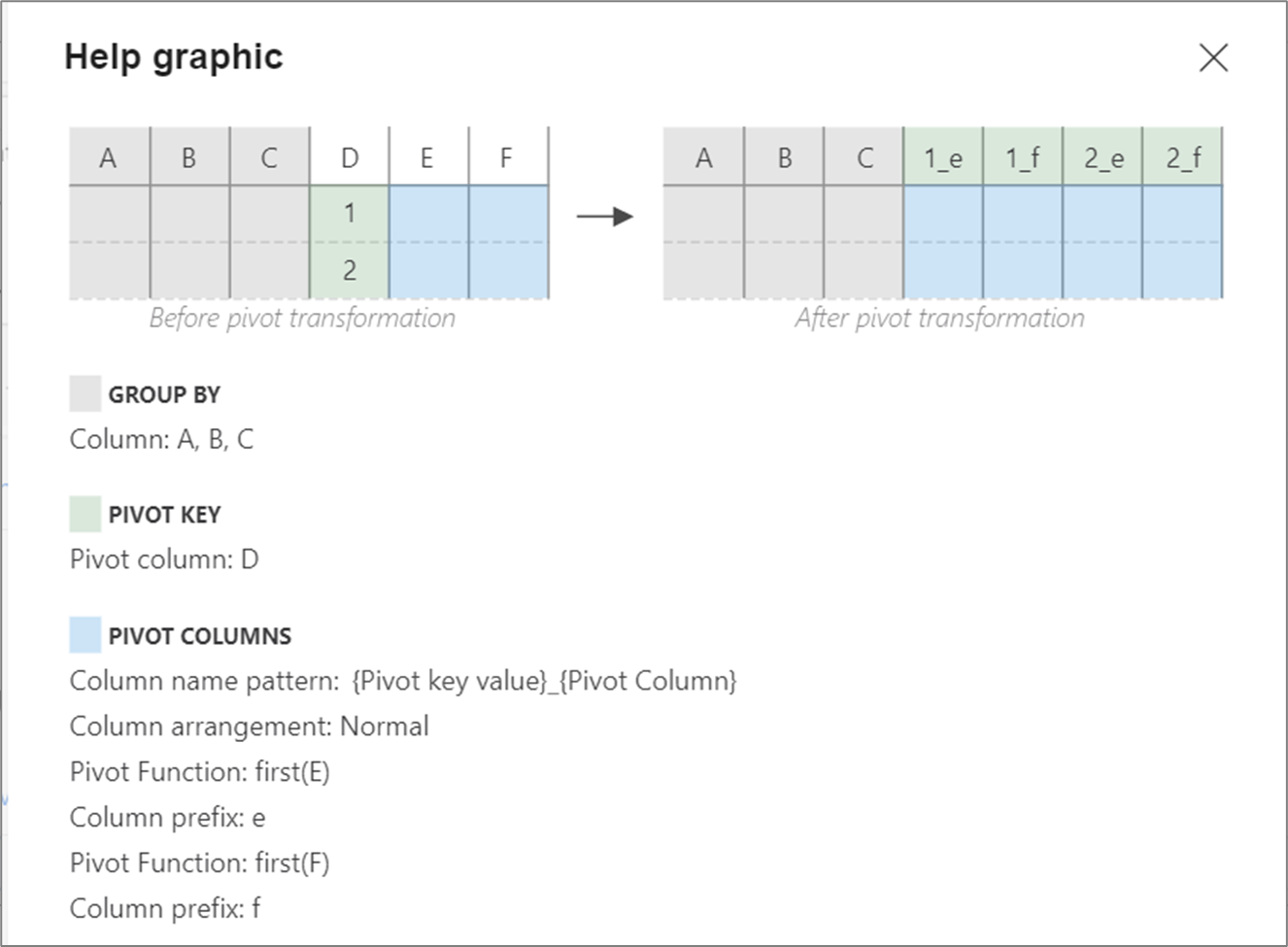
Metadata kontingenční tabulky
Pokud nejsou v konfiguraci kontingenčního klíče zadány žádné hodnoty, budou se kontingenční sloupce dynamicky generovat za běhu. Počet kontingenčních sloupců se rovná počtu jedinečných hodnot klíče kontingenční tabulky vynásobené počtem kontingenčních sloupců. Vzhledem k tomu, že se jedná o měnící se číslo, uživatelské rozhraní nezobrazí metadata sloupců na kartě Kontrola a nebude se šířit žádný sloupec. K transformaci těchto sloupců použijte možnosti vzoru sloupců mapování toku dat.
Pokud jsou nastavené konkrétní hodnoty kontingenčních klíčů, zobrazí se v metadatech kontingenční sloupce. Názvy sloupců budou k dispozici v mapování Kontrola a jímka.
Generování metadat z posunovaných sloupců
Pivot dynamicky generuje nové názvy sloupců na základě hodnot řádků. Tyto nové sloupce můžete přidat do metadat, na která můžete později v toku dat odkazovat. K tomu použijte rychlou akci posunutou mapou v náhledu dat.
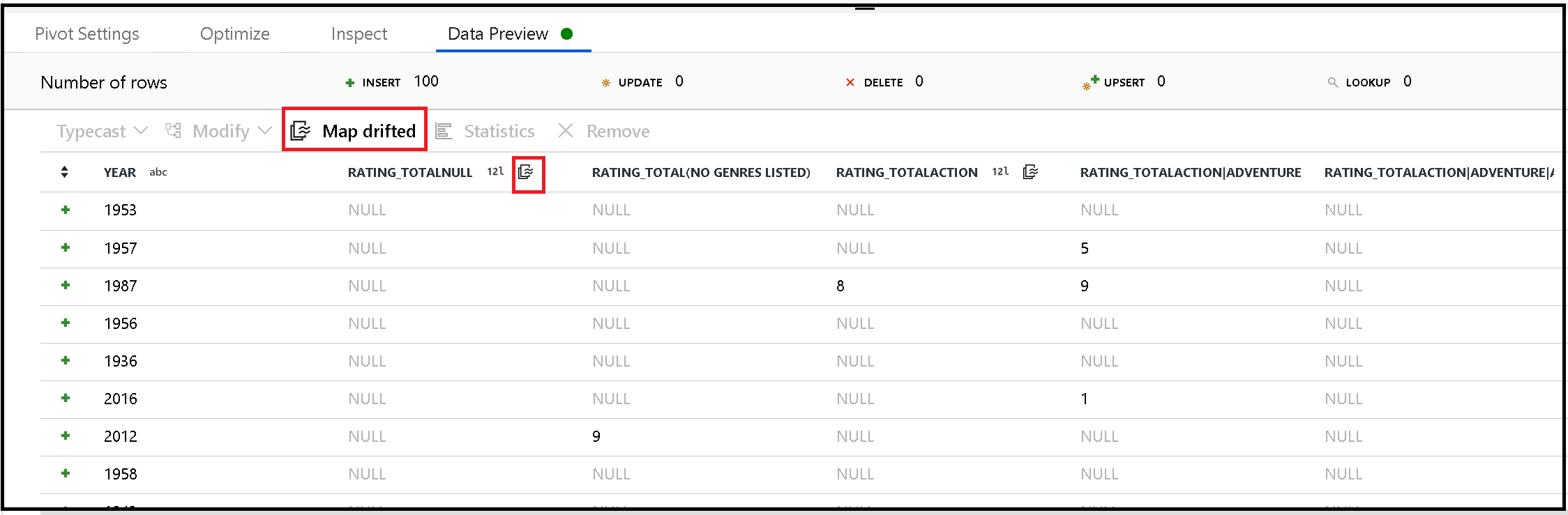
Jímka kontingenčních sloupců
I když jsou kontingenční sloupce dynamické, dají se pořád zapsat do cílového úložiště dat. Povolte v nastavení jímky odchylku schématu. To vám umožní psát sloupce, které nejsou zahrnuté v metadatech. V metadatech sloupců se nezobrazí nové dynamické názvy, ale možnost posunu schématu vám umožní přistát data.
Znovu se připojit k původním polím
Transformace kontingenční tabulky bude projektovat pouze skupinu podle a kontingenčních sloupců. Pokud chcete, aby výstupní data obsahovala další vstupní sloupce, použijte vzor samospojování .
Skript toku dat
Syntaxe
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Příklad
Obrazovky zobrazené v části konfigurace mají následující skript toku dat:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample