Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici v kanálech Azure Data Factory i v kanálech Azure Synapse Analytics. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toků dat.
Pomocí transformace výběru přejmenujte, přetáhněte nebo změňte pořadí sloupců. Tato transformace nemění data řádků, ale určuje, které sloupce se přenášejí dál.
Ve vybrané transformaci můžou uživatelé zadat pevná mapování, použít vzory k mapování založenému na pravidlech nebo povolit automatické mapování. Pevná mapování i mapování založená na pravidlech se dají použít ve stejné výběrové transformaci. Pokud sloupec neodpovídá některému z definovaných mapování, bude vyřazen.
Oprava mapování
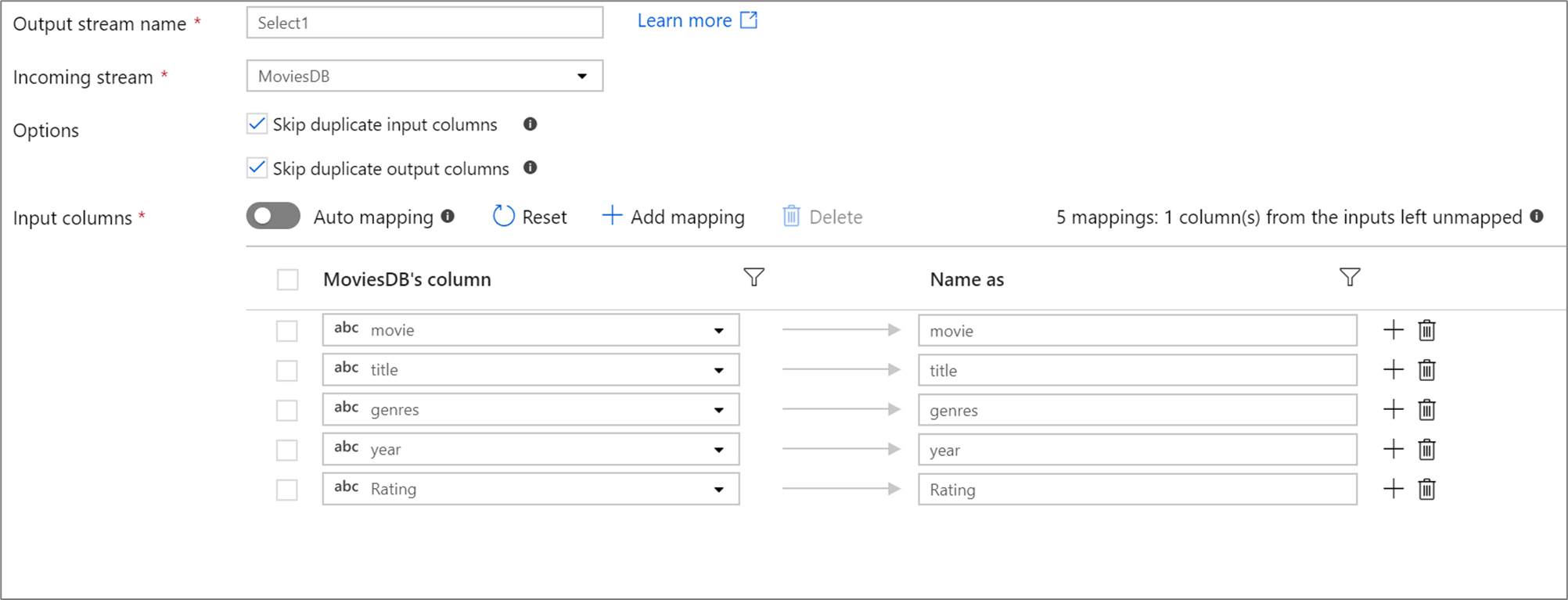
Pokud je v projekci definováno méně než 50 sloupců, budou mít všechny definované sloupce ve výchozím nastavení pevné mapování. Pevné mapování přebírá definovaný, příchozí sloupec a mapuje ho na přesný název.
Poznámka:
Nemůžete mapovat ani přejmenovat odchýlený sloupec pomocí pevného mapování.
Mapování hierarchických sloupců
Pevná přiřazení lze použít k přiřazení podsloupce hierarchického sloupce k sloupci nejvyšší úrovně. Pokud máte definovanou hierarchii, použijte rozevírací seznam k vyběru podsloupce. Transformace výběru vytvoří nový sloupec s hodnotou a datovým typem podsloupce.
Mapování založené na pravidlech
Pokud chcete namapovat mnoho sloupců najednou nebo předat podřízené sloupce, použijte mapování založené na pravidlech k definování mapování pomocí vzorů sloupců. Porovnání se provádí na základě sloupců name, type, stream a position. Můžete mít libovolnou kombinaci pevných mapování a mapování založených na pravidlech. Ve výchozím nastavení se u všech projekcí s více než 50 sloupci použije mapování založené na pravidlech, které odpovídá každému sloupci a použije vložený název.
Chcete-li přidat mapování založené na pravidlech, klepněte na tlačítko Přidat mapování a vyberte mapování založené na pravidlech.

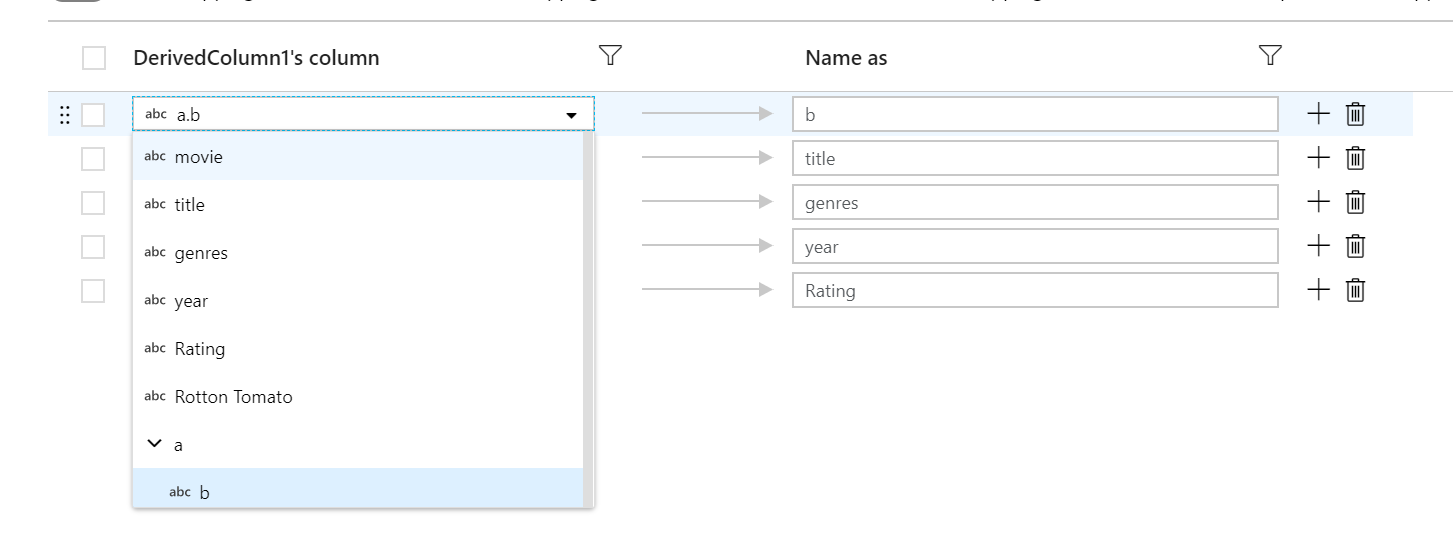
Každé mapování založené na pravidlech vyžaduje dva vstupy: podmínku, podle které se má shodovat, a název každého mapovaného sloupce. Obě hodnoty se zadávají prostřednictvím tvůrce výrazů. Do levého pole výrazu zadejte logickou podmínku shody. Do pravého pole výrazu zadejte, na co se má odpovídající sloupec přiřadit.

Pomocí $$ syntaxe můžete odkazovat na vstupní název odpovídajícího sloupce. Když použijete výše uvedený obrázek jako příklad, řekněme, že uživatel chce vybrat všechny řetězcové sloupce, jejichž názvy jsou kratší než šest znaků. Pokud byl pojmenován testjeden příchozí sloupec , výraz $$ + '_short' přejmenuje sloupec test_short. Pokud je to jediné mapování, které existuje, všechny sloupce, které nesplňují podmínku, se z výstupních dat zahodí.
Vzorce odpovídají jak posunutým, tak definovaným sloupcům. Pokud chcete zjistit, které definované sloupce jsou mapovány pravidlem, klikněte na ikonu brýlí vedle pravidla. Ověřte výstup pomocí náhledu dat.
Mapování regulárních výrazů
Pokud kliknete na ikonu šipky dolů, můžete zadat podmínku mapování regulárních výrazů. Podmínka mapování regulárních výrazů se shoduje se všemi názvy sloupců, které splňují specifikovanou podmínku regulárního výrazu. To lze použít v kombinaci se standardními mapováními založenými na pravidlech.

Výše uvedený příklad odpovídá vzoru regulárního výrazu (r) nebo libovolnému názvu sloupce, který obsahuje malé písmeno r. Podobně jako u standardního mapování založeného na pravidlech se všechny odpovídající sloupce mění podmínkou na pravé straně pomocí $$ syntaxe.
Pokud máte v názvu sloupce více shod regulárních výrazů, můžete odkazovat na konkrétní shody pomocí $n, kde 'n' odkazuje na konkrétní shodu. Například $2 odkazuje na druhou shodu v názvu sloupce.
Hierarchie založené na pravidlech
Pokud má definovaná projekce hierarchii, můžete k mapování podsloupců hierarchií použít mapování založené na pravidlech. Zadejte odpovídající podmínku a složitý sloupec, jehož podsloupce chcete mapovat. Každý odpovídající podsloupec se vypíše pomocí pravidla Name as zadaného na pravé straně.
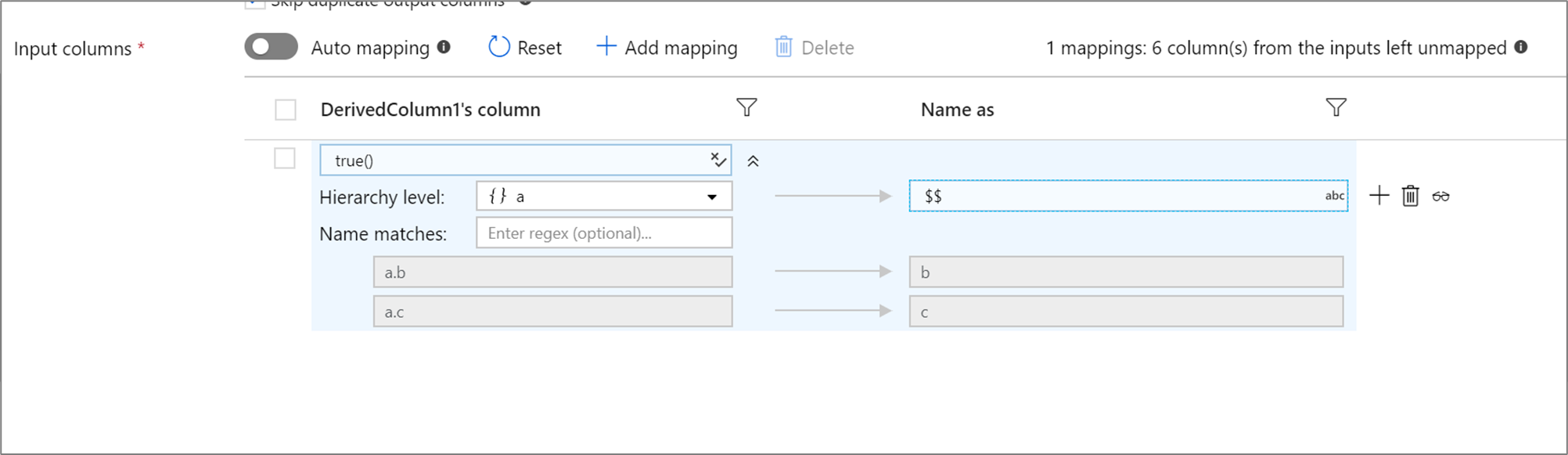
Výše uvedený příklad odpovídá všem dílčím sloupcům komplexního sloupce a.
a obsahuje dva podsloupce b a c. Výstupní schéma bude obsahovat dva sloupce b a c jako podmínku Name as je $$.
Parametrizace
Názvy sloupců můžete parametrizovat pomocí mapování založeného na pravidlech. Pomocí klíčového slova name můžete spárovat názvy příchozích sloupců s parametrem. Pokud máte například parametr mycolumntoku dat, můžete vytvořit pravidlo, které odpovídá názvu libovolného sloupce, který se rovná mycolumn. Odpovídající sloupec můžete přejmenovat na pevně zakódovaný řetězec, například "obchodní klíč", a odkazovat na něj explicitně. V tomto příkladu je name == $mycolumn odpovídající podmínka a podmínka názvu je "obchodní klíč".
Automatické mapování
Při přidávání výběrové transformace je možné automatické mapování povolit přepnutím posuvníku automatického mapování. Při automatickém mapování se při výběru transformací mapují všechny příchozí sloupce s výjimkou duplicit se stejným názvem jako jejich vstup. To bude zahrnovat posunované sloupce, což znamená, že výstupní data mohou obsahovat sloupce, které nejsou definovány ve vašem schématu. Další informace o neregulérních sloupcích najdete v tématu odchylka schématu.
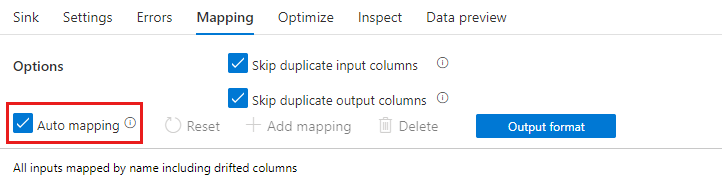
Při automatickém mapování bude výběr transformace respektovat přeskočení duplicitních nastavení a poskytnout nový alias pro existující sloupce. Aliasing je užitečný při provádění více spojení nebo vyhledávání ve stejném datovém proudu a ve scénářích s vlastním spojením.
Duplicitní sloupce
Ve výchozím nastavení výběrová transformace zahodí duplicitní sloupce ve vstupní i výstupní projekci. Duplicitní vstupní sloupce často pocházejí z transformací spojení a vyhledávání, kde se názvy sloupců duplikují na každé straně spojení. Duplicitní výstupní sloupce můžou nastat, pokud namapujete dva různé vstupní sloupce na stejný název. Vyberte, zda chcete odstranit nebo zachovat duplicitní sloupce zaškrtnutím nebo odškrtnutím políčka.
Řazení sloupců
Pořadí mapování určuje pořadí výstupních sloupců. Pokud je vstupní sloupec zmapován vícekrát, bude použito pouze první zmapování. Při vyřazení duplicitního sloupce bude zachována první shoda.
Skript toku dat
Syntaxe
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Příklad
Níže je příklad mapování výběru a skriptu toku dat:
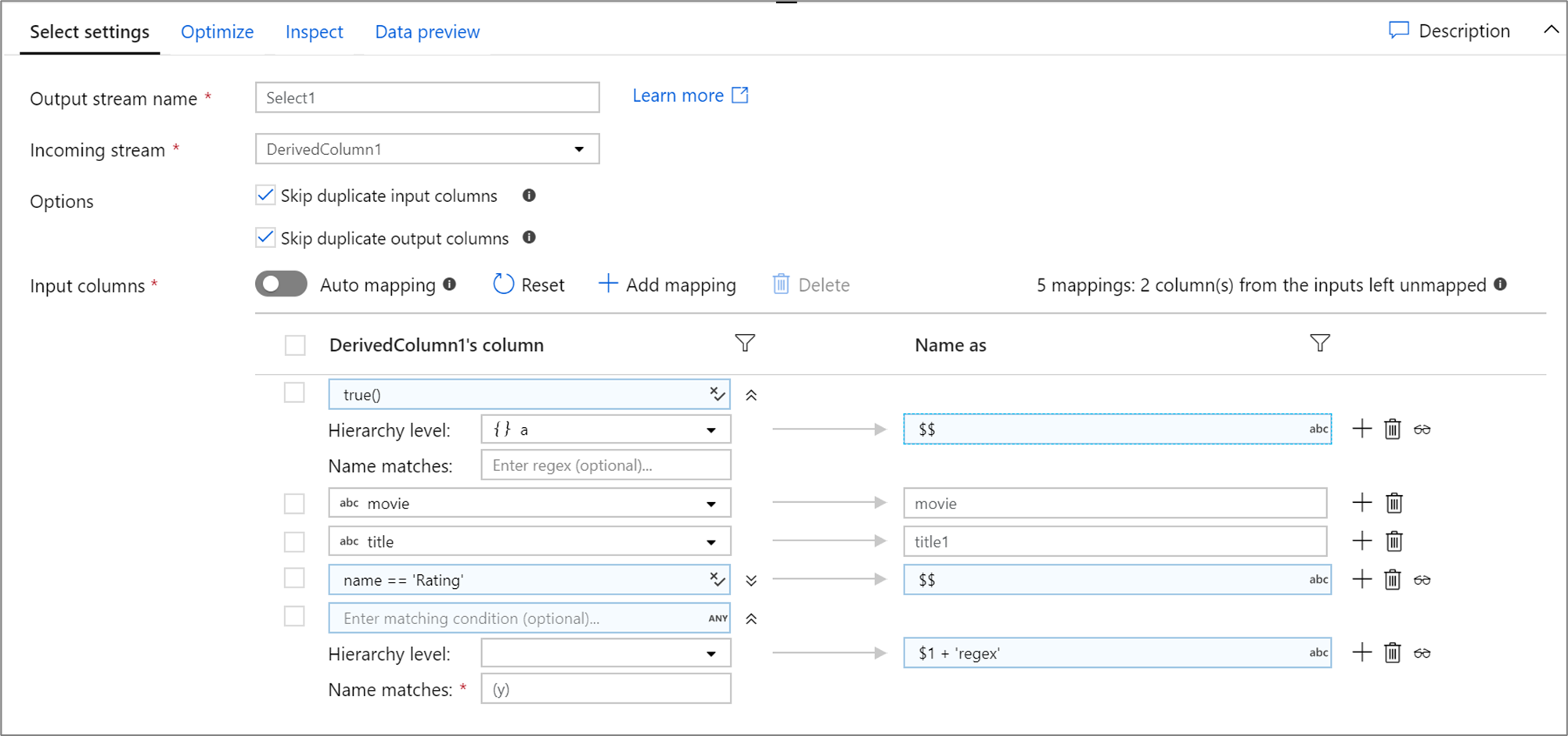
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Související obsah
- Po použití funkce Select k přejmenování, změně pořadí a aliasování sloupců použijte Sink transformation k uložení dat do úložiště dat.