Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Azure Data Factory a Synapse Analytics podporují iterativní vývoj a ladění kanálů. Tyto funkce umožňují otestovat změny před vytvořením žádosti o přijetí změn nebo jejich publikováním do služby.
V osmiminutovém úvodu a ukázce této funkce se podívejte na následující video:
Ladění potrubí
Při vytváření na plátně pipeline můžete své aktivity testovat pomocí ladicí funkce. Při testovacích spuštěních nemusíte před výběrem možnosti Ladit publikovat změny do služby. Tato funkce je užitečná ve scénářích, ve kterých chcete před aktualizací pracovního postupu zajistit, aby změny fungovaly podle očekávání.
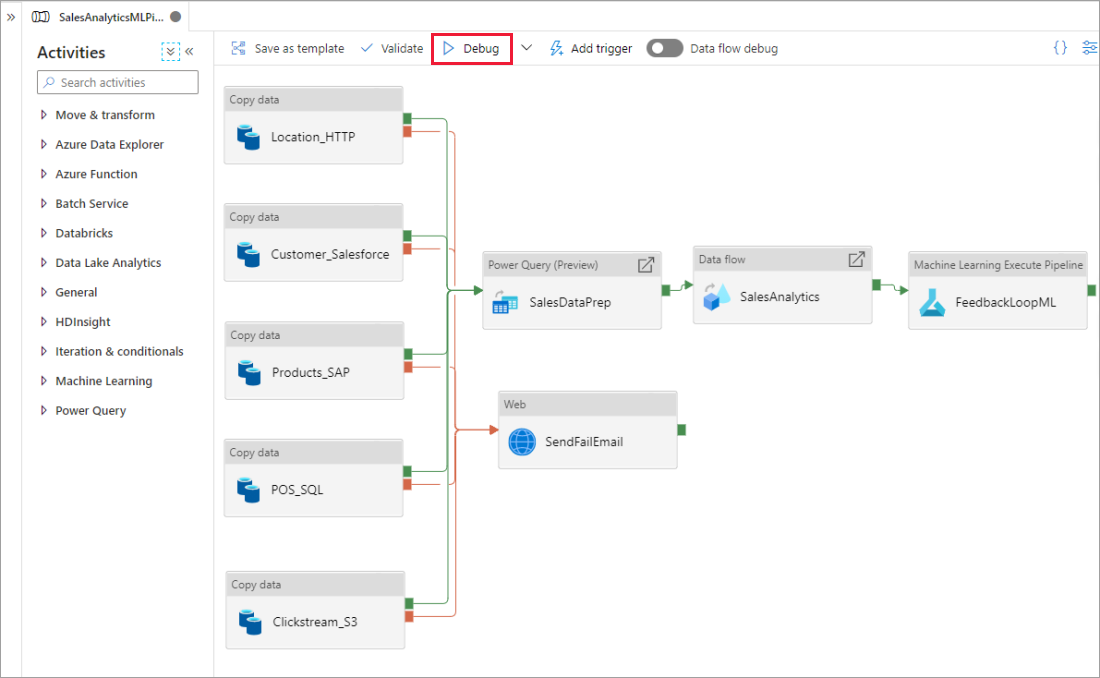
Při spuštění pipeline můžete výsledky jednotlivých aktivit zobrazit na kartě Výstup na plátně pipeline.
Výsledky testovacích provádění si můžete prohlédnout v okně Výstup na plátně pracovního postupu.
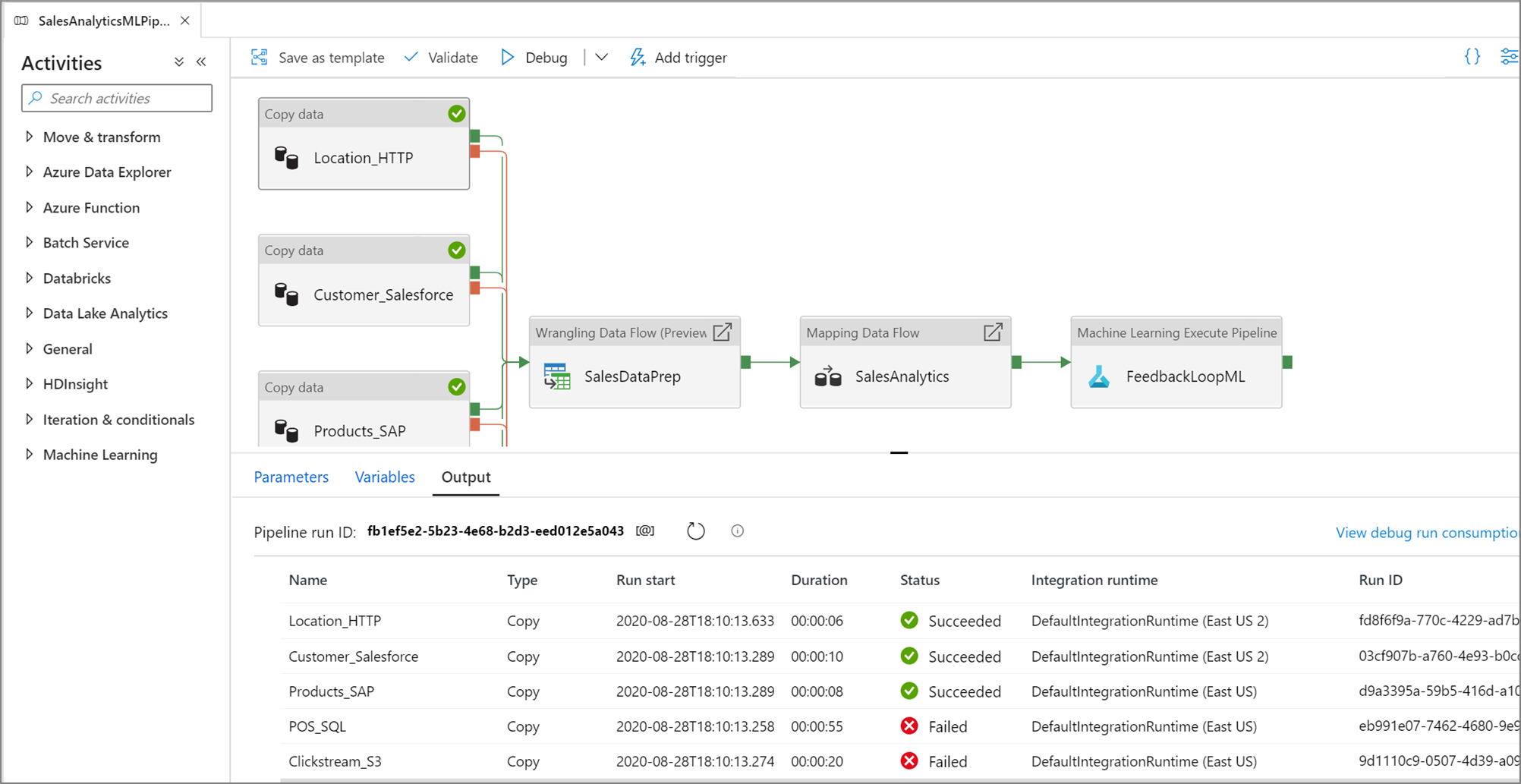
Po úspěšném testovacím spuštění přidejte do pipeplinu další aktivity a pokračujte v ladění iterativně. Během probíhajícího testovacího spuštění můžete také zrušit .
Důležité
Výběrem možnosti Ladění se skutečně spustí proces. Pokud například kanál obsahuje aktivitu kopírování, testovací spuštění kopíruje data ze zdroje do cíle. Proto doporučujeme při ladění používat testovací složky během kopírovacích a jiných aktivit. Po odlaďování potrubí přepněte na skutečné složky, které chcete použít v běžných operacích.
Nastavení zarážek
Služba umožňuje ladění procesního toku, dokud se nedostanete ke konkrétní aktivitě na pracovní ploše procesního toku. Umístěte zarážku na aktivitu, dokud ji nechcete testovat, a vyberte Ladit. Služba zajišťuje, že se test provádí pouze do bodu přerušení při činnosti zarážky v prostředí kanálu. Tato funkce Debug Until je užitečná, když nechcete testovat celý kanál, ale jenom podmnožinu aktivit uvnitř kanálu.
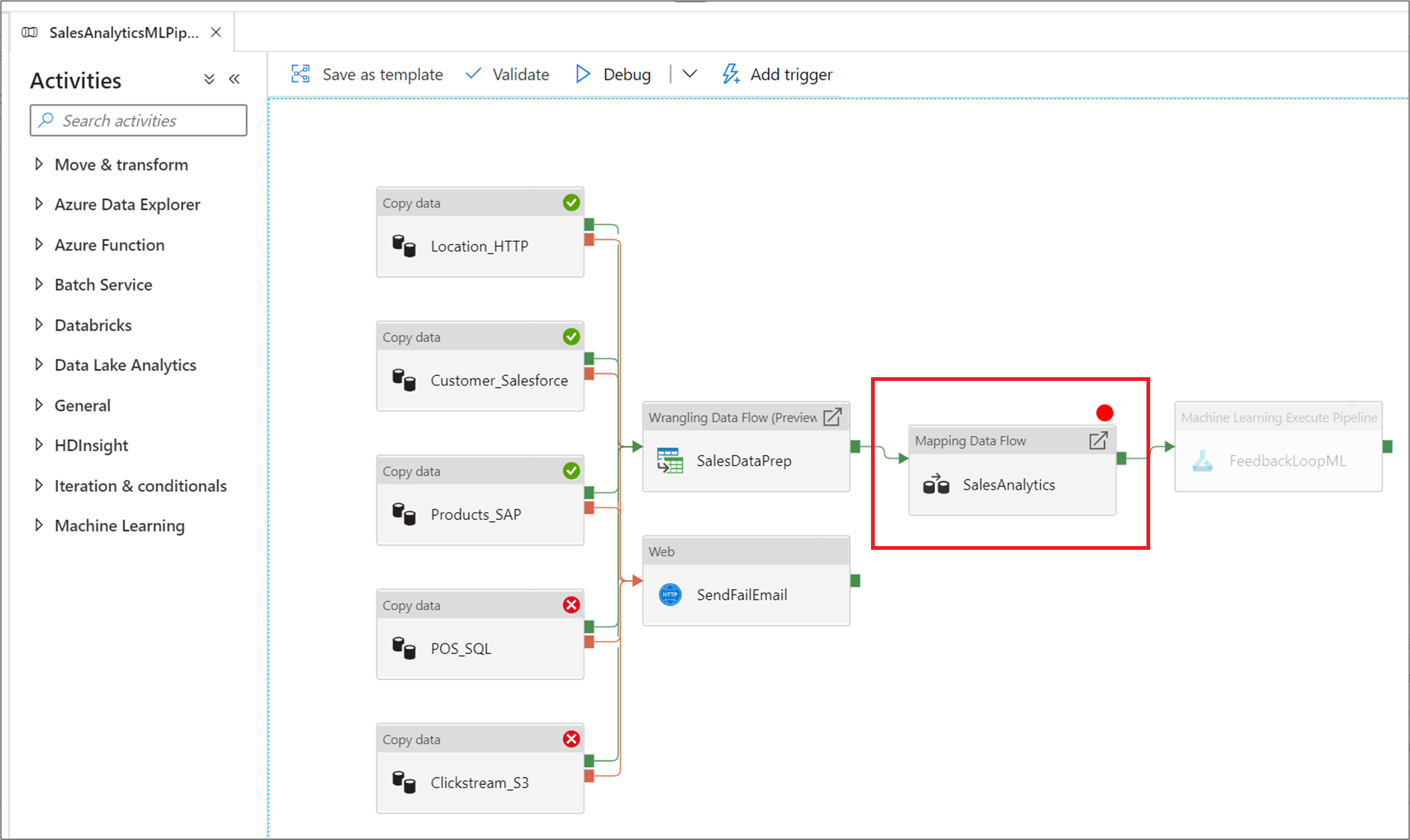
Pokud chcete nastavit bod přerušení, vyberte prvek na ploše potrubí. Možnost Ladit dokud se zobrazí jako prázdný červený kruh v pravém horním rohu prvku.

Jakmile vyberete možnost Ladit až do, změní se na vyplněný červený kruh, který označuje, že je zarážka aktivní.

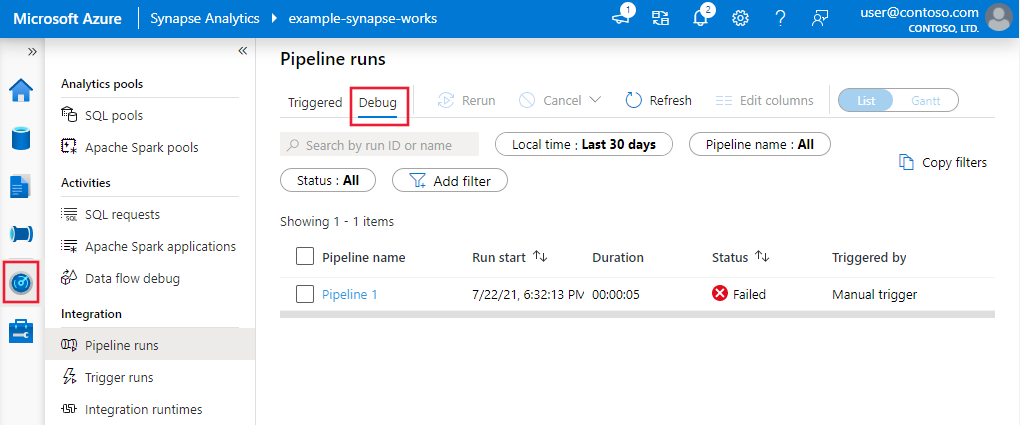
Monitorování běhu ladění
Když spustíte spuštění ladění kanálu, výsledky se zobrazí v okně Výstup na plátně kanálu. Karta Výstup bude obsahovat pouze poslední spuštění, ke kterému došlo během aktuální relace prohlížeče.
Pokud chcete zobrazit historické zobrazení ladících běhů nebo zobrazit seznam všech aktivních ladících běhů, můžete přejít do Monitor.
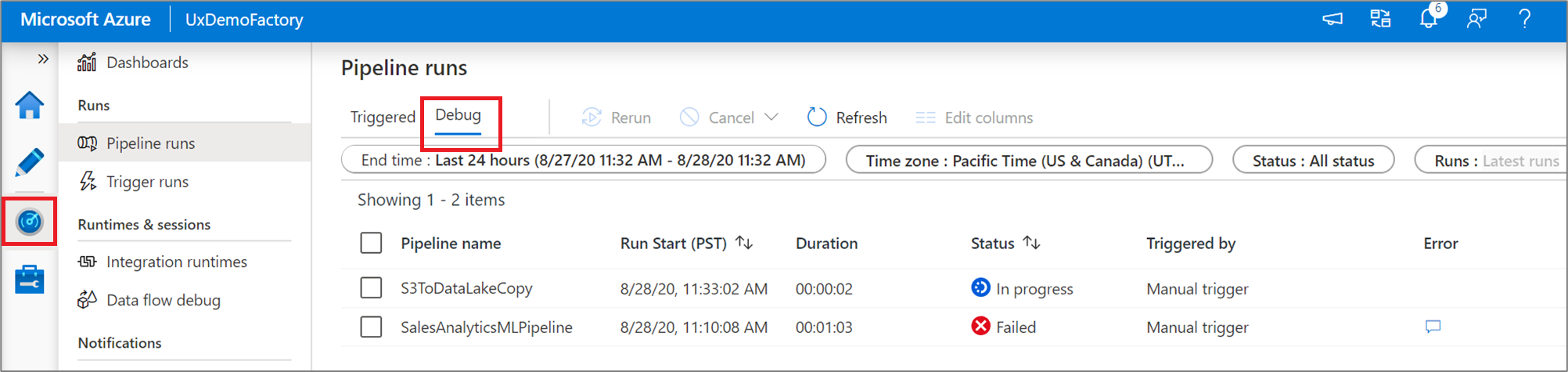
Poznámka:
Služba uchovává historii spuštění ladění jen po dobu 15 dnů.
Ladění mapování toků dat
Mapování toků dat umožňuje vytvářet logiku transformace dat bez kódu, která běží ve velkém měřítku. Při vytváření logiky můžete zapnout ladicí relace a interaktivně pracovat s daty pomocí živého Spark clusteru. Další informace najdete v tématu o režimu ladění toku dat mapování.
V prostředí Monitor můžete monitorovat aktivní ladicí relace toku dat.
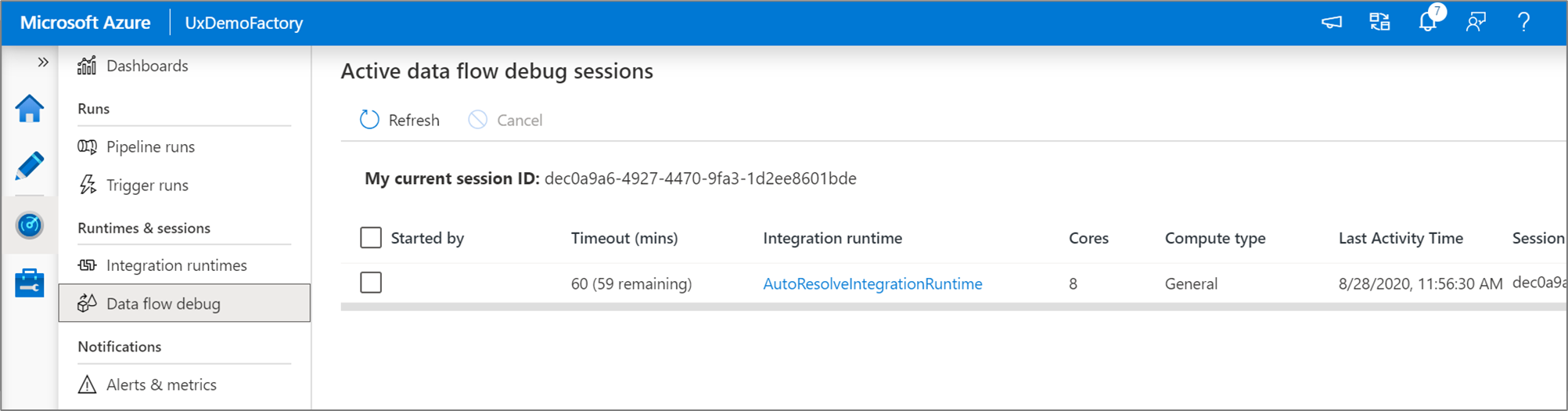
Náhled dat v návrháři toku dat a ladění potrubí toků dat mají fungovat nejlépe s malými vzorky dat. Pokud ale potřebujete otestovat logiku v kanálu nebo toku dat s velkým množstvím dat, zvětšete velikost Azure Integration Runtime, která se používá v ladicí relaci, s více jádry a minimálním výpočetním výkonem pro obecné účely.
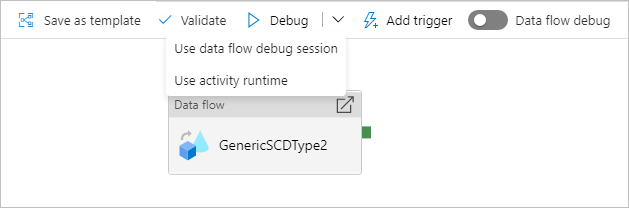
Ladění potrubí s aktivitou toku dat
Při spuštění běhu ladění pipeline s datovým tokem máte dvě možnosti, které můžete použít pro výpočet. Můžete použít existující ladicí cluster nebo spustit nový cluster 'just-in-time' pro vaše toky dat.
Použití existující relace ladění výrazně sníží dobu spuštění toku dat, protože cluster je již spuštěný, ale nedoporučuje se pro složité nebo paralelní úlohy, protože může selhat při spuštění více úloh najednou.
Použití modulu runtime aktivity vytvoří nový cluster s nastavením zadaným v modulu Integration Runtime každé aktivity toku dat. To umožňuje izolovat každou úlohu a měla by se používat pro složité úlohy nebo testování výkonu. Hodnotu TTL můžete také řídit v prostředí Azure IR, aby prostředky clusteru používané k ladění byly v daném časovém období k dispozici, aby mohly obsluhovat další žádosti o úlohy.
Poznámka:
Pokud máte kanál s toky dat spuštěnými paralelně nebo toky dat, které je potřeba testovat s velkými datovými sadami, zvolte Možnost Použít modul runtime aktivity, aby služba mohl použít Integration Runtime, které jste vybrali v aktivitě toku dat. To umožní, aby se toky dat spouštěly na několika clusterech a mohly by se přizpůsobit provádění paralelních toků dat.
Související obsah
Po otestování změn je zvyšte na vyšší prostředí pomocí kontinuální integrace a nasazování.