Pokročilá témata k SAP CDC
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Přečtěte si o pokročilých tématech konektoru SAP CDC, jako je integrace dat řízených metadaty, ladění a další.
Parametrizace toku dat mapování SAP CDC
Jednou z klíčových silných stránek kanálů a mapování toků dat ve službě Azure Data Factory a Azure Synapse Analytics je podpora integrace dat řízených metadaty. Pomocí této funkce je možné navrhnout jeden (nebo málo) parametrizovaný kanál, který lze použít ke zpracování integrace potenciálně stovek nebo dokonce tisíců zdrojů. Konektor SAP CDC byl navržen s ohledem na tento princip: všechny relevantní vlastnosti, ať už se jedná o zdrojový objekt, režim spuštění, klíčové sloupce atd., lze poskytnout prostřednictvím parametrů, aby se maximalizovala flexibilita a opakovaně používal potenciál mapování toků dat SAP CDC.
Abyste porozuměli základním konceptům parametrizace mapování toků dat, přečtěte si o parametrizaci mapování toků dat.
V galerii šablon Azure Data Factory a Azure Synapse Analytics najdete kanál šablony a tok dat, který ukazuje, jak parametrizovat příjem dat SAP CDC.
Parametrizace zdrojového a režimu spuštění
Mapování toků dat nemusí nutně vyžadovat artefakt datové sady: transformace zdroje i jímky nabízejí vložený typ zdroje (nebo typ jímky). V tomto případě lze všechny vlastnosti zdroje, jinak definované v datové sadě ADF, nakonfigurovat v možnostech zdroje transformace zdroje (nebo na kartě Nastavení transformace jímky). Použití vložené datové sady poskytuje lepší přehled a zjednodušuje parametrizaci toku dat mapování, protože se na jednom místě udržuje kompletní konfigurace zdroje (nebo jímky).
U SAP CDC se vlastnosti, které jsou nejčastěji nastavené prostřednictvím parametrů, nacházejí na kartách Možnosti Zdroje a Optimalizace. Pokud je typ Zdroj vložený, mohou být v možnostech zdroje parametrizovány následující vlastnosti.
- Kontext ODP: Platné hodnoty parametrů jsou
- ABAP_CDS pro zobrazení základních datových služeb ABAP
- BW pro SAP BW nebo SAP BW/4HANA InfoProviders
- HANA pro zobrazení informací o SAP HANA
- SAPI pro SAP DataSources/Extractors
- Pokud se jako zdroj používá server SLT (SAP Landscape Transformation Replication Server), název kontextu ODP je SLT~<Alias> fronty. Hodnotu Alias fronty najdete v části Data správy v konfiguraci SLT v kokpitu SLT (transakce SAP LTRC).
- ODP_SELF a RANDOM jsou kontexty ODP používané pro technické ověřování a testování a obvykle nejsou relevantní.
- Název ODP: zadejte název ODP, ze kterého chcete extrahovat data.
- Režim spuštění: Platné hodnoty parametrů jsou
- fullAndIncrementalLoad pro Full při prvním spuštění, pak přírůstkové, který zahájí proces zachycení dat změn a extrahuje aktuální úplný snímek dat.
- fullLoad for Full on every run, which extracts a current full data snapshot without iniciing a change data capture process.
- incrementalLoad pouze pro přírůstkové změny, které zahájí proces zachytávání dat změn bez extrahování aktuálního úplného snímku.
- Klíčové sloupce: klíčové sloupce jsou k dispozici jako pole řetězců (s dvojitými uvozovými) řetězci. Například při práci s tabulkou SAP VBAP (položky prodejní objednávky) musí být definice klíče ["VBELN", "POSNR"] (nebo ["MANDT","VBELN","POSNR"] v případě, že se bere v úvahu i klientské pole).
Parametrizace podmínek filtru pro dělení zdroje
Na kartě Optimalizace lze schéma dělení zdroje (viz optimalizace výkonu pro úplné nebo počáteční načtení) definovat prostřednictvím parametrů. Obvykle se vyžadují dva kroky:
- Definujte schéma dělení na zdrojové oddíly.
- Ingestování parametru dělení do toku dat mapování
Definování schématu dělení na zdrojové oddíly
Formát v kroku 1 se řídí standardem JSON, který se skládá z pole definic oddílů, z nichž každý sám je polem jednotlivých podmínek filtru. Tyto podmínky jsou samotné objekty JSON se strukturou zarovnanou s takzvanými možnostmi výběru v SAP. Ve skutečnosti je formát vyžadovaný architekturou SAP ODP v podstatě stejný jako dynamické filtry DTP v SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Například
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
odpovídá klauzuli SQL WHERE ... WHERE "VBELN" = '0000001000', nebo
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
odpovídá klauzuli SQL WHERE ... WHERE "VBELN" BETWEEN '000000000' AND '0000001000'
Definice json schématu dělení obsahujícího dva oddíly tak vypadá takto:
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
kde první oddíl obsahuje fiskální roky (GJAHR) 2011 až 2015 a druhý oddíl obsahuje fiskální roky 2016 až 2020.
Poznámka:
Azure Data Factory neprovádí žádné kontroly těchto podmínek. Je například zodpovědností uživatele, aby se podmínky oddílů nepřekrývaly.
Podmínky oddílů můžou být složitější, které se skládají z několika samotných podmínek základního filtru. Neexistují žádné logické spojení, které explicitně definují, jak kombinovat více základních podmínek v rámci jednoho oddílu. Implicitní definice v SAP je následující:
- včetně podmínek ("znaménko": "I") pro stejný název pole jsou kombinovány s OR (mentálně, vložte závorky kolem výsledné podmínky).
- s výjimkou podmínek ("znaménko": "E") pro stejný název pole se zkombinují s or (opět, mentálně, vložte závorky kolem výsledné podmínky).
- výsledné podmínky kroků 1 a 2 jsou
- v kombinaci s A pro zahrnutí podmínek,
- v kombinaci s A NOT pro vyloučení podmínek.
Například podmínka oddílu
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
odpovídá klauzuli SQL WHERE ... WHERE ("BUKRS" = '1000' OR "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' AND '2025') AND NOT ("GJAHR" = '2021' nebo "GJARH" = '2023')
Poznámka:
Nezapomeňte použít interní formát SAP pro nízké a vysoké hodnoty, zahrnout počáteční nuly a vyjádřit kalendářní data jako osmiznakový řetězec s formátem RRRRMMDD.
Ingestování parametru dělení na mapování toku dat
Pokud chcete ingestovat schéma dělení na mapování toku dat, vytvořte parametr toku dat (například sapPartitions). Pokud chcete předat formát JSON tomuto parametru, musí být převeden na řetězec pomocí funkce @string( ):
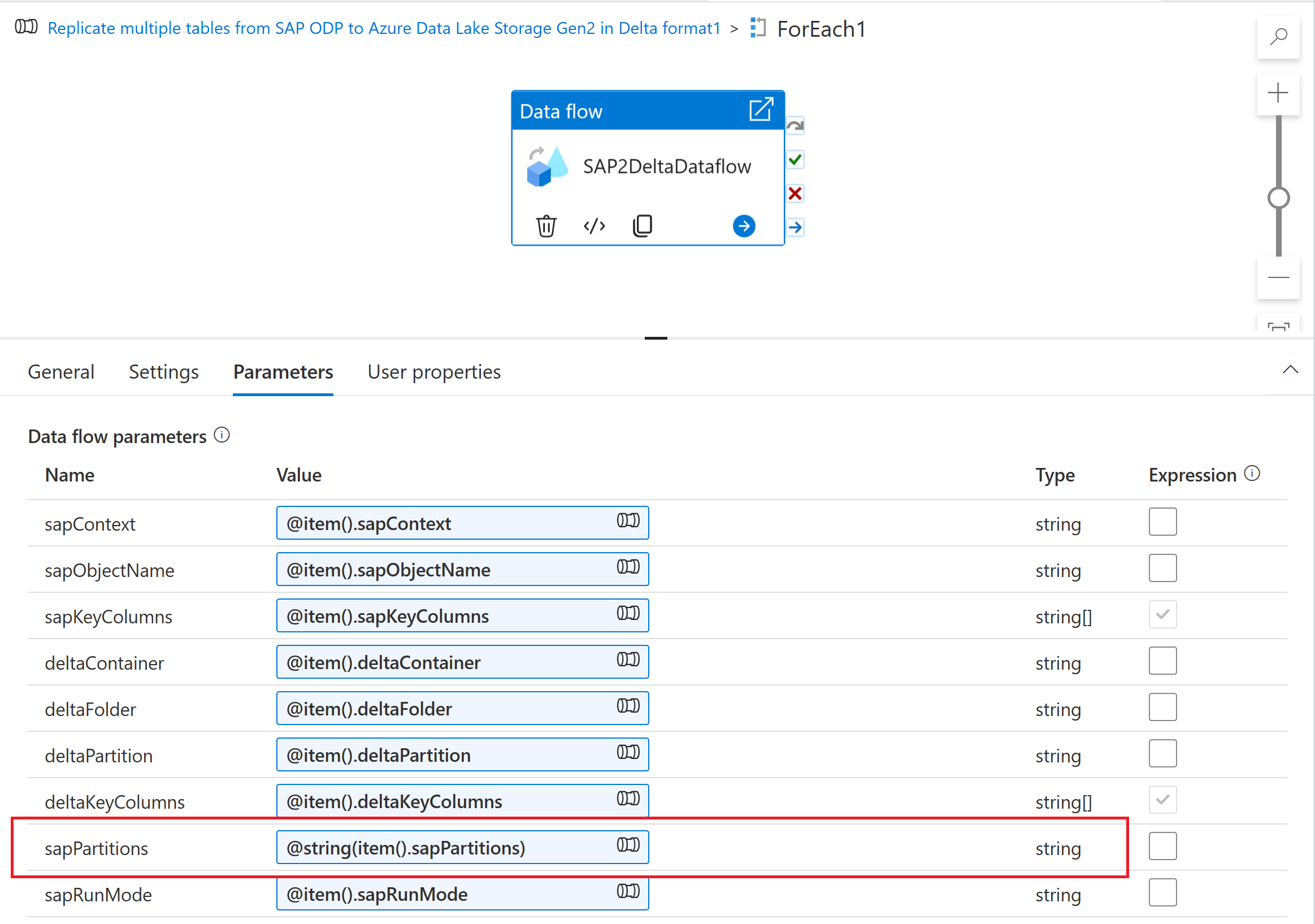
Nakonec na kartě optimalizace transformace zdroje v toku dat mapování vyberte Typ oddílu "Zdroj" a do vlastnosti Podmínky oddílu zadejte parametr toku dat.

Parametrizace klíče kontrolního bodu
Při použití parametrizovaného toku dat k extrakci dat z více zdrojů SAP CDC je důležité parametrizovat klíč kontrolního bodu v aktivitě toku dat ve vašem kanálu. Klíč kontrolního bodu používá Azure Data Factory ke správě stavu procesu zachytávání dat změn. Aby se zabránilo tomu, že stav jednoho procesu CDC přepíše stav jiného procesu, ujistěte se, že jsou hodnoty klíče kontrolního bodu jedinečné pro každou sadu parametrů použitou v toku dat.
Poznámka:
Osvědčeným postupem pro zajištění jedinečnosti klíče kontrolního bodu je přidání hodnoty klíče kontrolního bodu do sady parametrů pro váš tok dat.
Další informace o klíči kontrolního bodu najdete v tématu Transformace dat pomocí konektoru SAP CDC.
Ladění
Kanály služby Azure Data Factory je možné spouštět prostřednictvím aktivovaných nebo ladicích spuštění. Základním rozdílem mezi těmito dvěma možnostmi je, že ladicí spuštění spouští tok dat a kanál založený na aktuální verzi modelované v uživatelském rozhraní, zatímco aktivovaná spuštění spouštějí poslední publikovanou verzi toku dat a kanálu.
U SAP CDC je potřeba pochopit ještě jeden aspekt: aby se zabránilo dopadu spuštění ladění na existující proces zachytávání dat změn, ladicí běhy používají jinou hodnotu "proces odběratele" (viz Monitorování toků dat SAP CDC) než aktivovaná spuštění. Proto vytvářejí samostatná předplatná (tj. procesy zachytávání dat změn) v rámci systému SAP. Hodnota proces odběratele pro spuštění ladění má navíc omezenou dobu životnosti na relaci uživatelského rozhraní prohlížeče.
Poznámka:
Pokud chcete otestovat stabilitu procesu zachytávání dat změn pomocí SAP CDC po delší dobu (například několik dní), je potřeba publikovat tok dat a kanál a spustit spuštění .