Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje šablonu, která je k dispozici pro přírůstkové načtení nových nebo aktualizovaných řádků z databázové tabulky do Azure pomocí tabulky externího ovládacího prvku, která ukládá hodnotu s vysokou meze.
Tato šablona vyžaduje, aby schéma zdrojové databáze obsahovalo sloupec časového razítka nebo inkrementující klíč k identifikaci nových nebo aktualizovaných řádků.
Poznámka:
Pokud máte ve zdrojové databázi sloupec časového razítka k identifikaci nových nebo aktualizovaných řádků, ale nechcete vytvořit tabulku externího ovládacího prvku, která se má použít pro rozdílovou kopii, můžete k získání kanálu použít nástroj pro kopírování dat služby Azure Data Factory. Tento nástroj používá naplánovaný čas triggeru jako proměnnou ke čtení nových řádků ze zdrojové databáze.
O této šabloně řešení
Tato šablona nejprve načte starou hodnotu meze a porovná ji s aktuální hodnotou vodoznaku. Potom zkopíruje pouze změny ze zdrojové databáze na základě porovnání mezi dvěma hodnotami meze. Nakonec uloží novou hodnotu horní meze do tabulky externího ovládacího prvku pro další načtení rozdílových dat.
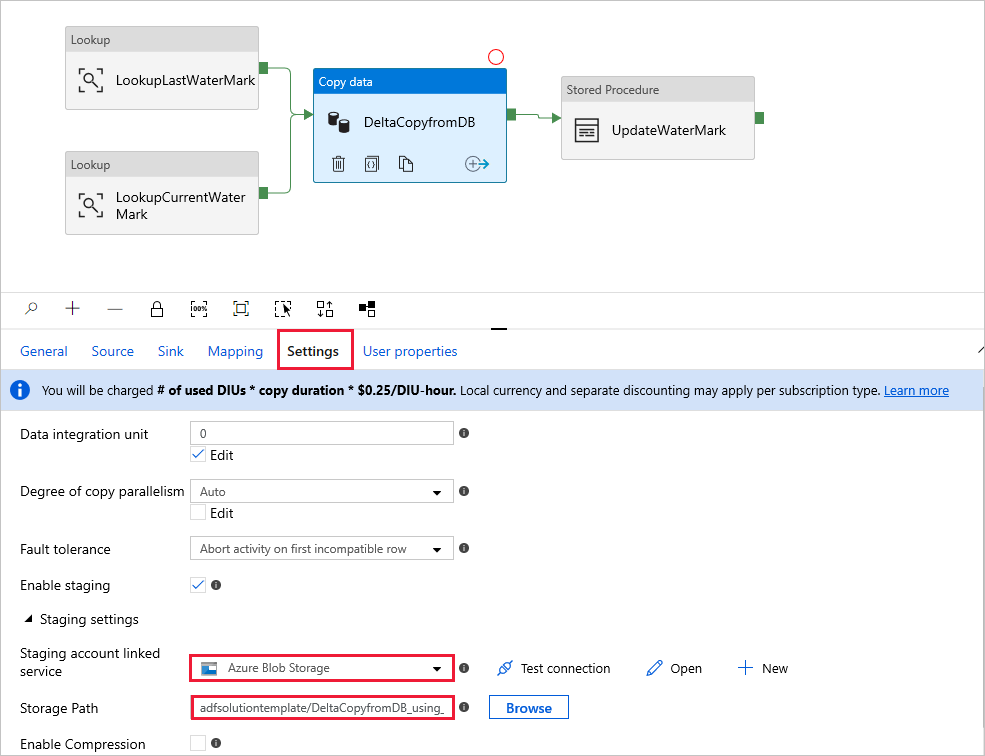
Šablona obsahuje čtyři aktivity:
- Vyhledávání načte starou hodnotu horní meze, která je uložená v tabulce externího ovládacího prvku.
- Další aktivita vyhledávání načte aktuální hodnotu horní meze ze zdrojové databáze.
- Zkopírujte pouze změny ze zdrojové databáze do cílového úložiště. Dotaz, který identifikuje změny ve zdrojové databázi, se podobá příkazu SELECT * FROM Data_Source_Table WHERE TIMESTAMP_Column > "poslední horní mez" a TIMESTAMP_Column <= "aktuální horní mez".
- SqlServerStoredProcedure zapíše aktuální hodnotu horní meze do tabulky externího ovládacího prvku pro rozdílovou kopii příště.
Šablona definuje následující parametry:
- Data_Source_Table_Name je tabulka ve zdrojové databázi, ze které chcete načíst data.
- Data_Source_WaterMarkColumn je název sloupce ve zdrojové tabulce, který slouží k identifikaci nových nebo aktualizovaných řádků. Typ tohoto sloupce je obvykle datetime, INT nebo podobný.
- Data_Destination_Container je kořenová cesta místa, kam se data zkopírují do cílového úložiště.
- Data_Destination_Directory je cesta k adresáři v kořenovém adresáři místa, kam se data zkopírují do cílového úložiště.
- Data_Destination_Table_Name je místo, kam se data zkopírují do cílového úložiště (platí pro výběr možnosti Azure Synapse Analytics jako cíl dat).
- Data_Destination_Folder_Path je místo, kam se data zkopírují do cílového úložiště (platí pro výběr systému souborů nebo Azure Data Lake Storage Gen1 jako cíl dat).
- Control_Table_Table_Name je tabulka externích ovládacích prvků, ve které je uložená hodnota horní meze.
- Control_Table_Column_Name je sloupec v tabulce externího ovládacího prvku, ve které je uložená hodnota horní meze.
Jak používat tuto šablonu řešení
Prozkoumejte zdrojovou tabulku, kterou chcete načíst, a definujte sloupec s vysokým vodoznakem, který se dá použít k identifikaci nových nebo aktualizovaných řádků. Typ tohoto sloupce může být datetime, INT nebo podobný. Při přidání nových řádků se hodnota tohoto sloupce zvýší. Z následující ukázkové zdrojové tabulky (data_source_table) můžeme jako sloupec s horní mezí použít sloupec LastModifytime .
PersonID Name LastModifytime 1 aaaa 2017-09-01 00:56:00.000 2 bbbb 2017-09-02 05:23:00.000 3 cccc 2017-09-03 02:36:00.000 4 dddd 2017-09-04 03:21:00.000 5 eeee 2017-09-05 08:06:00.000 6 fffffff 2017-09-06 02:23:00.000 7 gggg 2017-09-07 09:01:00.000 8 hhhh 2017-09-08 09:01:00.000 9 iiiiiiiii 2017-09-09 09:01:00.000Vytvořte řídicí tabulku v SQL Serveru nebo Azure SQL Database, do které se uloží hodnota horní meze pro načítání rozdílových dat. V následujícím příkladu je název řídicí tabulky vodoznaktable. V této tabulce je WatermarkValue sloupec, který ukládá hodnotu horní meze a jeho typ je datetime.
create table watermarktable ( WatermarkValue datetime, ); INSERT INTO watermarktable VALUES ('1/1/2010 12:00:00 AM')Vytvořte uloženou proceduru ve stejné instanci SQL Serveru nebo Azure SQL Database, kterou jste použili k vytvoření řídicí tabulky. Uložená procedura slouží k zápisu nové hodnoty horní meze do tabulky externích ovládacích prvků pro další načtení rozdílových dat.
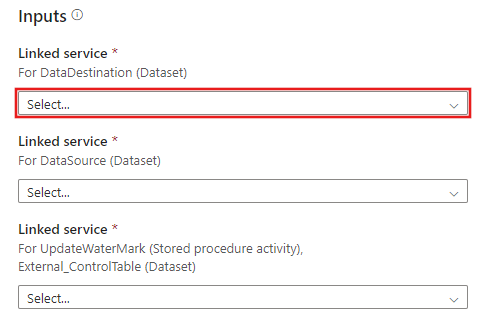
CREATE PROCEDURE update_watermark @LastModifiedtime datetime AS BEGIN UPDATE watermarktable SET [WatermarkValue] = @LastModifiedtime ENDPřejděte na rozdílovou kopii ze šablony databáze . Vytvořte nové připojení ke zdrojové databázi, ze které chcete kopírovat data.
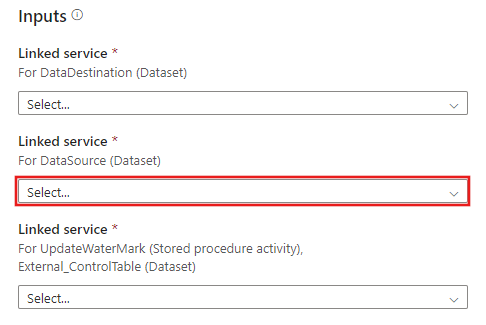
Vytvořte nové připojení k cílovému úložišti dat, do kterého chcete data zkopírovat.
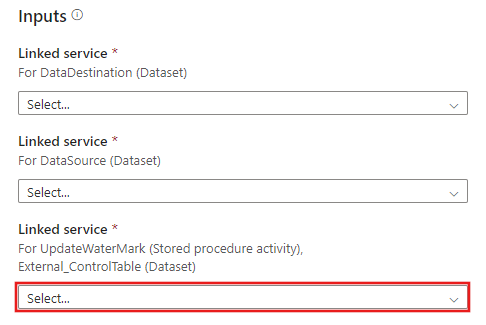
Vytvořte nové připojení k tabulce externího ovládacího prvku a uložené procedury, kterou jste vytvořili v krocích 2 a 3.
Vyberte Použít tuto šablonu.
Zobrazí se dostupný kanál, jak je znázorněno v následujícím příkladu:
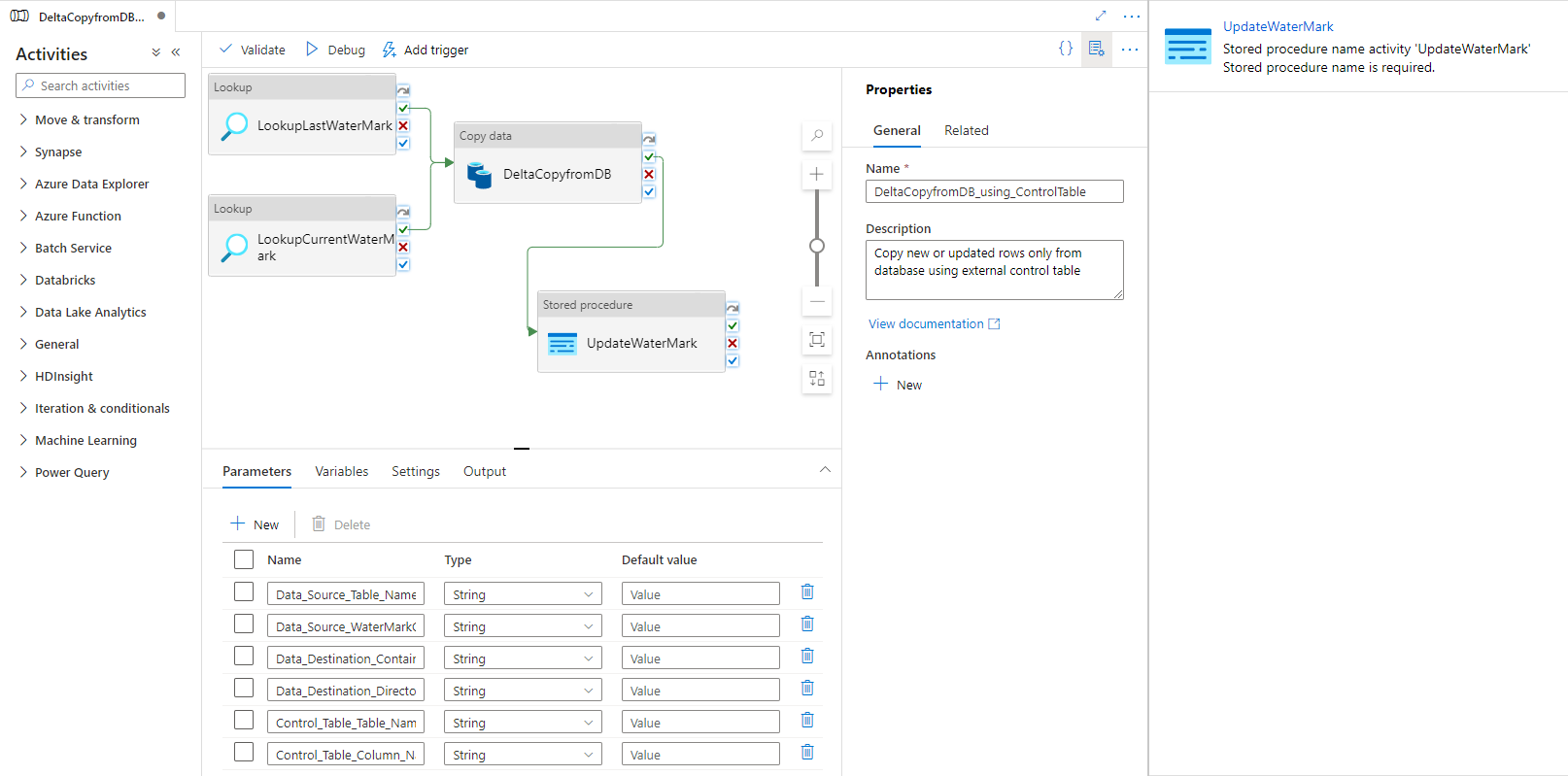
Vyberte uloženou proceduru. Jako název uložené procedury zvolte [dbo].[ update_watermark]. Vyberte Importovat parametr a pak vyberte Přidat dynamický obsah.
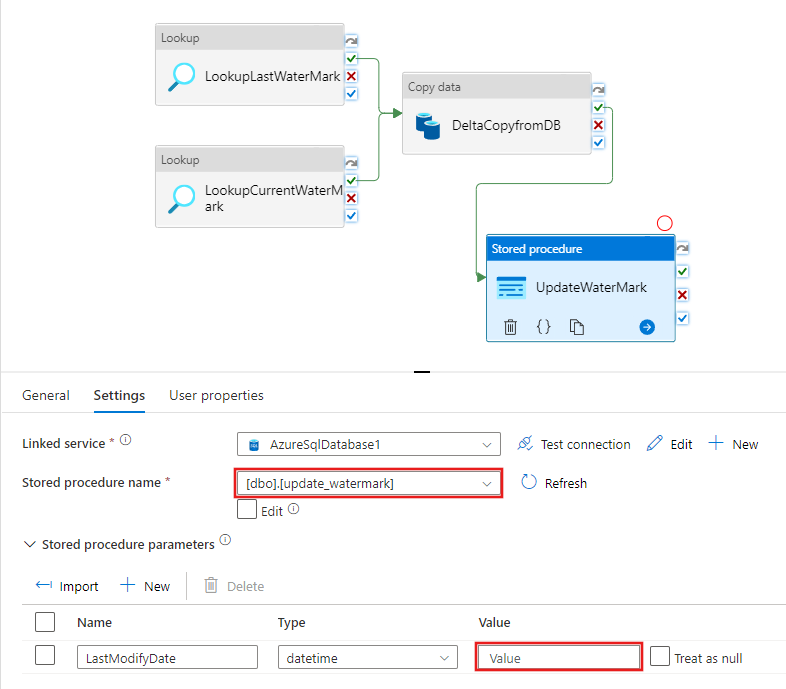
Napište obsah @{activity('LookupCurrentWaterMark').output.firstRow.NewWatermarkValue} a pak vyberte Dokončit.
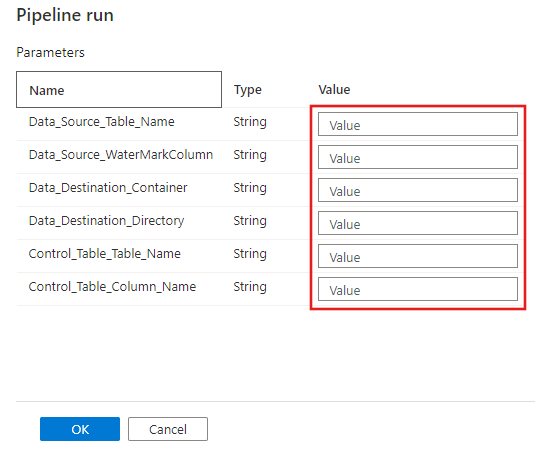
Vyberte Ladit, zadejte parametry a pak vyberte Dokončit.
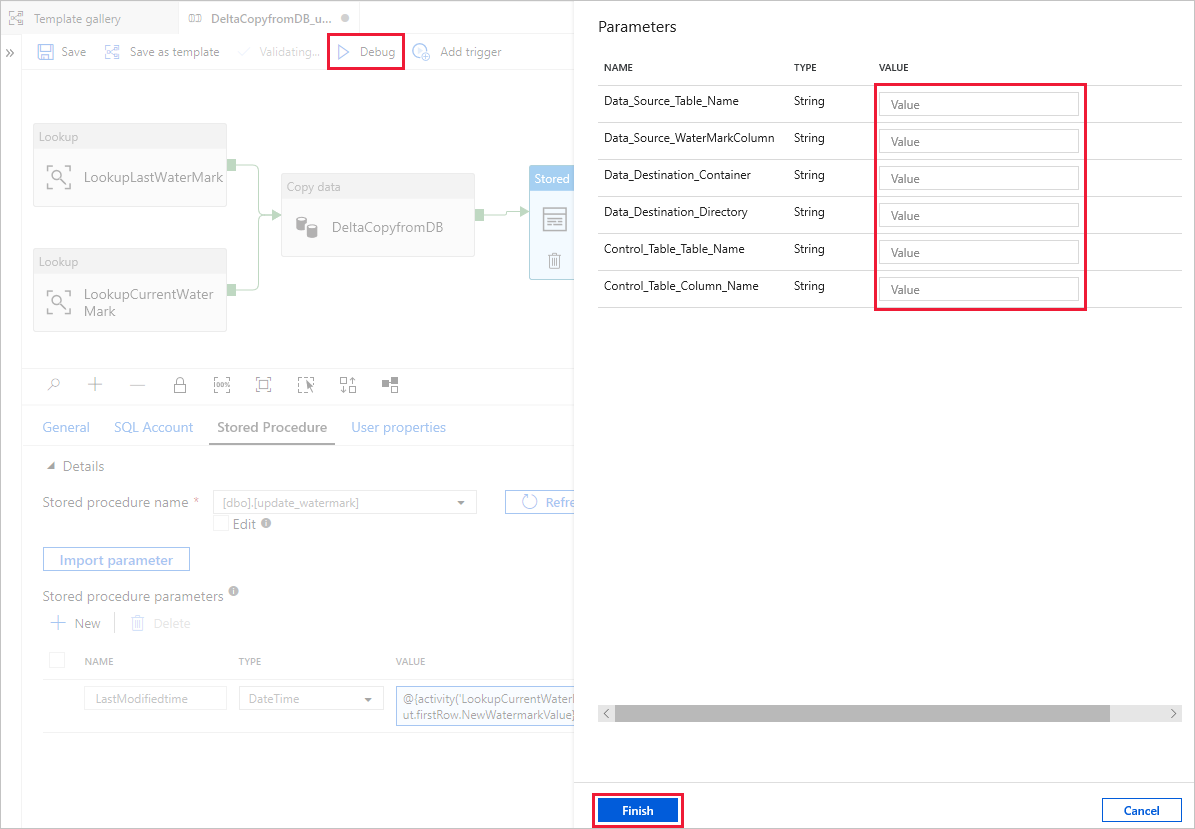
Zobrazí se výsledky podobné následujícímu příkladu:
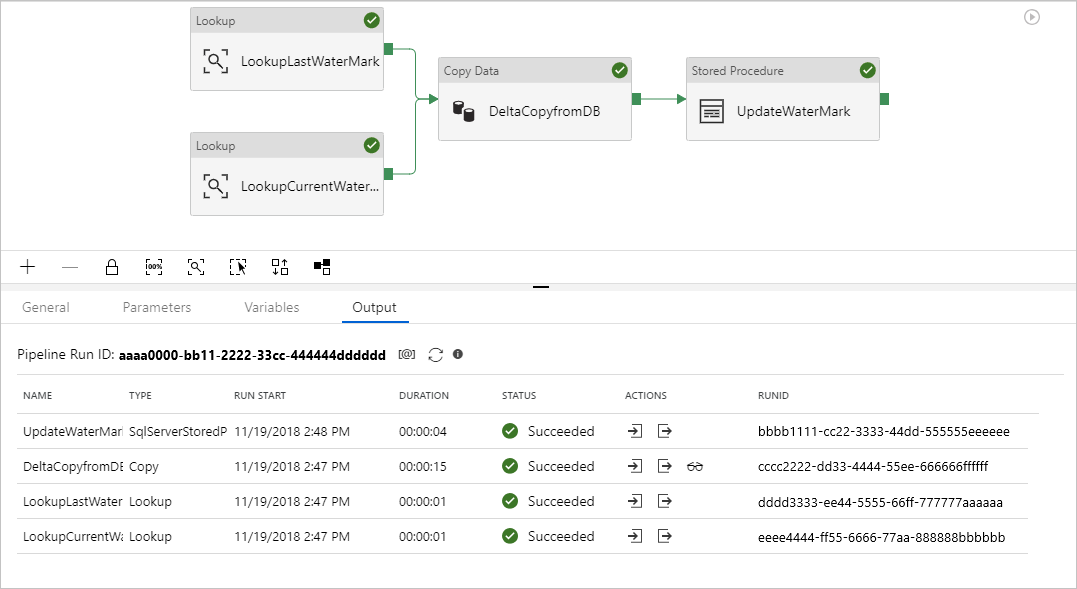
Ve zdrojové tabulce můžete vytvořit nové řádky. Tady je ukázkový jazyk SQL pro vytvoření nových řádků:
INSERT INTO data_source_table VALUES (10, 'newdata','9/10/2017 2:23:00 AM') INSERT INTO data_source_table VALUES (11, 'newdata','9/11/2017 9:01:00 AM')Pokud chcete kanál spustit znovu, vyberte Ladit, zadejte parametry a pak vyberte Dokončit.
Uvidíte, že do cíle byly zkopírovány pouze nové řádky.
(Volitelné:) Pokud jako cíl dat vyberete Azure Synapse Analytics, musíte také poskytnout připojení k úložišti objektů blob v Azure pro přípravu, které vyžaduje Azure Synapse Analytics Polybase. Šablona pro vás vygeneruje cestu ke kontejneru. Po spuštění kanálu zkontrolujte, jestli se kontejner vytvořil v úložišti objektů blob.