Zotavení po havárii
Jasný model zotavení po havárii je kritický pro platformu pro analýzu dat nativní pro cloud, jako je Azure Databricks. Je důležité, aby vaše datové týmy mohly používat platformu Azure Databricks i ve výjimečných případech výpadku poskytovatele cloudových služeb pro celou oblast, ať už způsobené regionální katastrofou, jako je hurikán nebo zemětřesení, nebo jiný zdroj.
Azure Databricks je často základní součástí celkového ekosystému dat, který zahrnuje mnoho služeb, včetně upstreamových služeb pro příjem dat (batch/streaming), nativního cloudového úložiště, jako je ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage), podřízené nástroje a služby, jako jsou aplikace business intelligence a nástroje pro orchestraci. Některé z vašich případů použití můžou být obzvláště citlivé na výpadek na úrovni regionální služby.
Tento článek popisuje koncepty a osvědčené postupy pro úspěšné řešení zotavení po havárii pro platformu Databricks.
Záruky vysoké dostupnosti v rámci oblasti
I když se zbytek tohoto tématu zaměřuje na implementaci zotavení po havárii mezi oblastmi, je důležité pochopit záruky vysoké dostupnosti, které Azure Databricks poskytuje v rámci jedné oblasti. Záruky vysoké dostupnosti v jednotlivých oblastech pokrývají následující komponenty:
Dostupnost řídicí roviny Azure Databricks
- Většina služeb řídicí roviny běží v clusterech Kubernetes a zpracuje ztrátu virtuálních počítačů v konkrétním az automaticky.
- Data pracovního prostoru se ukládají v databázích se službou Premium Storage, která se replikují v celé oblasti. Úložiště databáze (jednoúčelového serveru) se nereplikuje v různých zónách AZ ani oblastech. Pokud výpadek zóny ovlivní úložiště databáze, databáze se obnoví tak, že ze zálohy vyvolá novou instanci.
- Účty úložiště používané k obsluhování imagí DBR jsou také redundantní uvnitř oblasti a všechny oblasti mají sekundární účty úložiště, které se používají, když je primární server mimo provoz. Viz oblasti Azure Databricks.
- Obecně platí, že funkce řídicí roviny by se měly obnovit do ~15 minut po obnovení zóny dostupnosti.
Dostupnost výpočetní roviny
- Dostupnost pracovního prostoru závisí na dostupnosti řídicí roviny (jak je popsáno výše).
- Data v kořenovém adresáři DBFS nejsou ovlivněná, pokud je účet úložiště pro kořen DBFS nakonfigurovaný se ZRS nebo GZRS (výchozí hodnota je GRS).
- Uzly pro clustery se načítají z různých zón dostupnosti vyžádáním uzlů od poskytovatele výpočetních prostředků Azure (za předpokladu dostatečné kapacity ve zbývajících zónách pro splnění požadavku). Pokud dojde ke ztrátě uzlu, správce clusteru požádá o náhradní uzly od poskytovatele výpočetních prostředků Azure, který je načítá z dostupných zón AZ. Jedinou výjimkou je ztráta uzlu ovladače. V takovém případě je úloha nebo správce clusteru restartuje.
Přehled zotavení po havárii
Zotavení po havárii zahrnuje sadu zásad, nástrojů a postupů, které umožňují zotavení nebo pokračování klíčové technologické infrastruktury a systémů po přírodní nebo lidské havárii. Velká cloudová služba, jako je Azure, obsluhuje mnoho zákazníků a má integrovanou ochranu před jedním selháním. Oblast je například skupina budov připojených k různým zdrojům napájení, aby se zajistilo, že jedna ztráta napájení nevypne oblast. K selháním cloudové oblasti ale může dojít a může se lišit stupeň přerušení a jeho dopad na vaši organizaci.
Před implementací plánu zotavení po havárii je důležité pochopit rozdíl mezi zotavením po havárii (DR) a vysokou dostupností (HA).
Vysoká dostupnost je charakteristické pro systém odolnost. Vysoká dostupnost zajišťuje minimální úroveň provozního výkonu, která se obvykle definuje z hlediska konzistentní doby provozu nebo procenta provozuschopnosti. Vysoká dostupnost se implementuje na místě (ve stejné oblasti jako primární systém) tak, že ji navrhnete jako funkci primárního systému. Například cloudové služby, jako je Azure, mají služby s vysokou dostupností, jako je ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage). Vysoká dostupnost nevyžaduje od zákazníka Azure Databricks významnou explicitní přípravu.
Naproti tomu plán zotavení po havárii vyžaduje rozhodnutí a řešení, která ve vaší konkrétní organizaci pracují, aby zvládla větší regionální výpadek kritických systémů. Tento článek popisuje běžnou terminologii zotavení po havárii, běžná řešení a některé osvědčené postupy pro plány zotavení po havárii pomocí Azure Databricks.
Terminologie
Terminologie oblastí
Tento článek používá následující definice pro oblasti:
Primární oblast: Geografická oblast, ve které uživatelé provozují typické každodenní interaktivní a automatizované úlohy analýzy dat.
Sekundární oblast: Geografická oblast, ve které IT týmy dočasně přesunují úlohy analýzy dat během výpadku v primární oblasti.
Geograficky redundantní úložiště: Azure má geograficky redundantní úložiště napříč oblastmi pro trvalé úložiště pomocí asynchronního procesu replikace úložiště.
Důležité
V případě procesů zotavení po havárii doporučuje Databricks nespoléhat na geograficky redundantní úložiště pro duplikaci dat mezi oblastmi, jako je ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage), které Azure Databricks vytvoří pro každý pracovní prostor ve vašem předplatném Azure. Obecně platí, že pro tabulky Delta použijte hloubkový klon a převeďte data do formátu Delta, pokud je to možné pro jiné formáty dat.
Terminologie stavu nasazení
Tento článek používá následující definice stavu nasazení:
Aktivní nasazení: Uživatelé se můžou připojit k aktivnímu nasazení pracovního prostoru Azure Databricks a spouštět úlohy. Úlohy se plánují pravidelně pomocí plánovače Azure Databricks nebo jiného mechanismu. Datové proudy je možné spouštět i v tomto nasazení. Některé dokumenty můžou odkazovat na aktivní nasazení jako horké nasazení.
Pasivní nasazení: Procesy se nespouštějí v pasivním nasazení. IT týmy můžou nastavit automatizované postupy pro nasazení kódu, konfigurace a dalších objektů Azure Databricks do pasivního nasazení. Nasazení se aktivuje jenom v případě, že je aktuální aktivní nasazení neaktivní. Některé dokumenty můžou odkazovat na pasivní nasazení jako studené nasazení.
Důležité
Projekt může volitelně obsahovat několik pasivních nasazení v různých oblastech, aby poskytoval další možnosti pro řešení regionálních výpadků.
Obecně řečeno, tým má současně pouze jedno aktivní nasazení v tom, co se nazývá strategie zotavení po havárii typu aktivní-pasivní . Existuje méně běžná strategie řešení zotavení po havárii označovaná jako aktivní-aktivní, ve které existují dvě souběžná aktivní nasazení.
Terminologie odvětví zotavení po havárii
Existují dva důležité oborové termíny, kterým musíte porozumět a definovat pro váš tým:
Cíl bodu obnovení: Cíl bodu obnovení (RPO) je maximální cílová doba, ve které může dojít ke ztrátě dat (transakcí) ze služby IT kvůli závažnému incidentu. Vaše nasazení Azure Databricks neukládá hlavní zákaznická data. To se ukládá v samostatných systémech, jako je ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage) nebo v jiných zdrojích dat pod vaší kontrolou. Řídicí rovina Azure Databricks ukládá některé objekty částečně nebo v plném rozsahu, jako jsou úlohy a poznámkové bloky. V Případě Azure Databricks je cíl bodu obnovení definovaný jako maximální cílové období, ve kterém můžou být ztraceny objekty, jako jsou úlohy a změny poznámkového bloku. Kromě toho zodpovídáte za definování cíle bodu obnovení pro vaše vlastní zákaznická data v ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage) nebo jiné zdroje dat pod vaší kontrolou.
Cíl doby obnovení: Cíl doby obnovení (RTO) je cílová doba trvání času a úroveň služby, ve které je třeba po havárii obnovit obchodní proces.
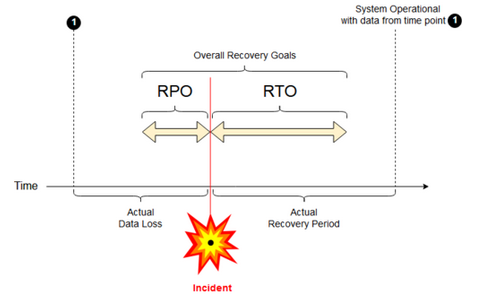
Zotavení po havárii a poškození dat
Řešení zotavení po havárii nezmírní poškození dat. Poškozená data v primární oblasti se replikují z primární oblasti do sekundární oblasti a jsou poškozená v obou oblastech. Existují další způsoby, jak tento druh selhání zmírnit, například rozdílové časové cesty.
Typický pracovní postup obnovení
Scénář zotavení po havárii Azure Databricks se obvykle provádí následujícím způsobem:
V kritické službě, kterou používáte v primární oblasti, dojde k selhání. Může to být služba zdroje dat nebo síť, která má vliv na nasazení Azure Databricks.
Prozkoumáte situaci u poskytovatele cloudu.
Pokud dojde k závěru, že vaše společnost nemůže počkat na vyřešení problému v primární oblasti, můžete se rozhodnout, že budete potřebovat převzetí služeb při selhání do sekundární oblasti.
Ověřte, že stejný problém nemá vliv také na vaši sekundární oblast.
Převzetí služeb při selhání do sekundární oblasti
- Zastavte všechny aktivity v pracovním prostoru. Uživatelé zastavují úlohy. Uživatelé nebo správci jsou vyzváni, aby v případě potřeby vytvořili zálohu nedávných změn. Úlohy se vypínají, pokud se ještě nepodařilo kvůli výpadku.
- Spusťte proceduru obnovení v sekundární oblasti. Postup obnovení aktualizuje směrování a přejmenování připojení a síťového provozu do sekundární oblasti.
- Po testování deklarujte provozní sekundární oblast. Produkční úlohy teď můžou pokračovat. Uživatelé se můžou přihlásit k aktivnímu nasazení. Naplánované nebo zpožděné úlohy můžete opakovat.
Podrobné kroky v kontextu Azure Databricks najdete v tématu Testovací převzetí služeb při selhání.
V určitém okamžiku se problém v primární oblasti zmírní a potvrdíte tento fakt.
Obnovení (navrácení služeb po obnovení) do primární oblasti
- Zastavte veškerou práci v sekundární oblasti.
- Spusťte proceduru obnovení v primární oblasti. Postup obnovení zpracovává směrování a přejmenování připojení a síťového provozu zpět do primární oblasti.
- Podle potřeby replikujte data zpět do primární oblasti. Pokud chcete snížit složitost, možná minimalizujte množství dat, které je potřeba replikovat. Pokud jsou například některé úlohy při spuštění v sekundárním nasazení jen pro čtení, nemusíte tato data replikovat zpět do primárního nasazení v primární oblasti. Můžete však mít jednu produkční úlohu, která je potřeba spustit a může potřebovat replikaci dat zpět do primární oblasti.
- Otestujte nasazení v primární oblasti.
- Deklarujte provozní oblast vaší primární oblasti a že se jedná o vaše aktivní nasazení. Obnovení produkčních úloh
Další informace o obnovení do primární oblasti najdete v tématu Otestování obnovení (navrácení služeb po obnovení).
Důležité
Během těchto kroků může dojít ke ztrátě dat. Vaše organizace musí definovat, kolik ztráty dat je přijatelné a co můžete udělat, abyste tuto ztrátu zmírnit.
Krok 1: Vysvětlení obchodních potřeb
Prvním krokem je definování a pochopení obchodních potřeb. Definujte, které datové služby jsou kritické a jaké jsou očekávané cíle bodu obnovení (RPO) a RTO.
Prozkoumáte skutečnou odolnost každého systému a mějte na paměti, že převzetí služeb při selhání po havárii a navrácení služeb po obnovení může být nákladné a nese další rizika. Mezi další rizika můžou patřit poškození dat, duplikovaná data, pokud zapíšete do nesprávného umístění úložiště, a uživatelé, kteří se přihlásí a změní na nesprávných místech.
Namapujte všechny integrační body Azure Databricks, které ovlivňují vaši firmu:
- Potřebuje vaše řešení zotavení po havárii pojmout interaktivní procesy, automatizované procesy nebo obojí?
- Které datové služby používáte? Některé můžou být místní.
- Jak se vstupní data dostanou do cloudu?
- Kdo tato data využívá? Jaké procesy ho využívají v podřízené fázi?
- Existují integrace třetích stran, které potřebují vědět o změnách zotavení po havárii?
Určete nástroje nebo komunikační strategie, které můžou podporovat váš plán zotavení po havárii:
- Jaké nástroje použijete k rychlé úpravě konfigurací sítě?
- Můžete předdefinovat konfiguraci a nastavit ji jako modulární, aby vyhovovala řešením zotavení po havárii přirozeným a udržovatelným způsobem?
- Které komunikační nástroje a kanály budou informovat interní týmy a třetí strany (integrace, podřízené uživatele) o převzetí služeb při selhání po havárii a o změnách navrácení služeb po obnovení? A jak potvrdíte jejich potvrzení?
- Jaké nástroje nebo zvláštní podpora budou potřeba?
- Jaké služby se v případě, že se některá služba vypne, dokud nebude dokončené obnovení?
Krok 2: Volba procesu, který vyhovuje vašim obchodním potřebám
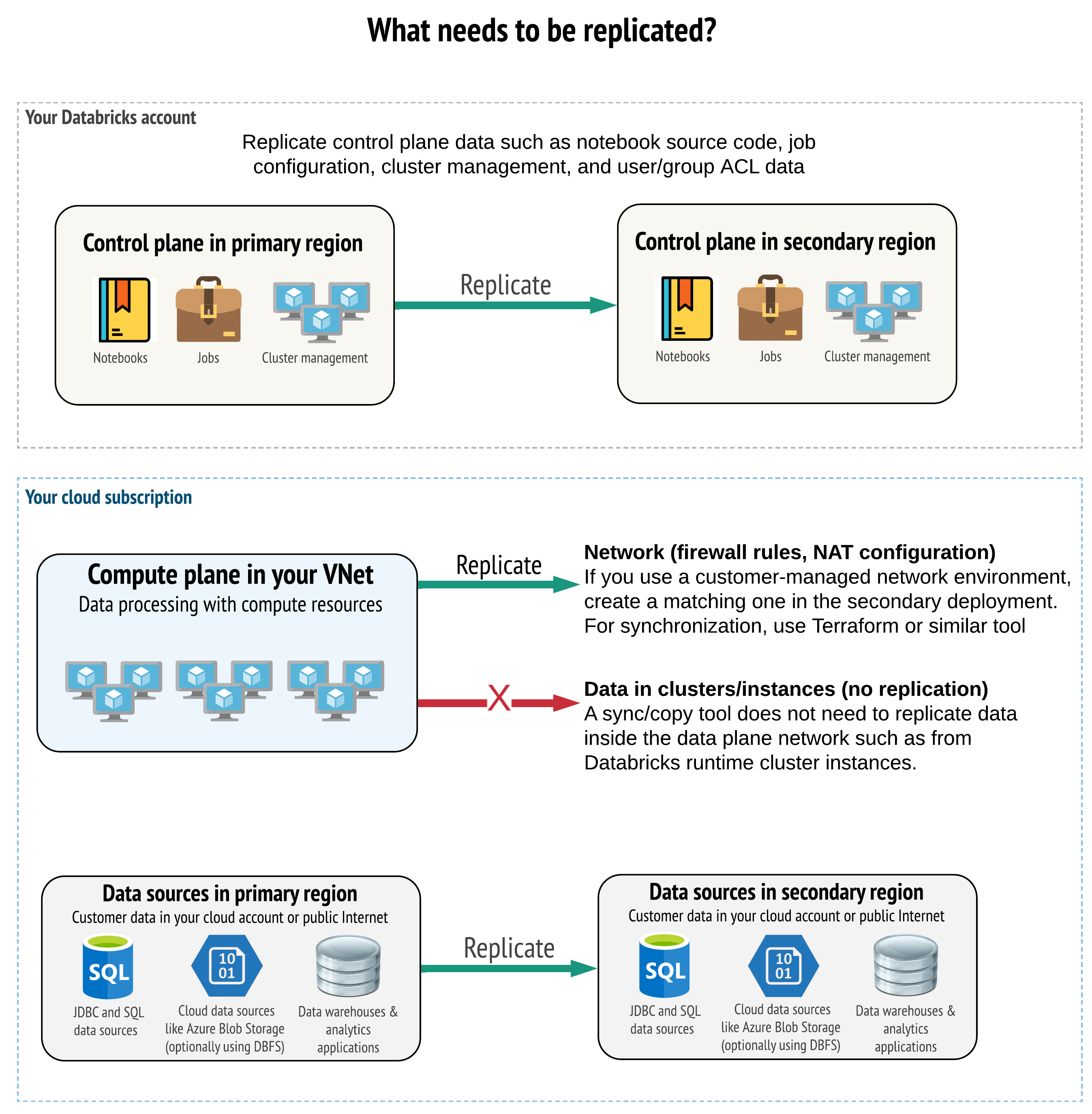
Vaše řešení musí replikovat správná data v řídicí rovině, výpočetní rovině a zdrojích dat. Redundantní pracovní prostory pro zotavení po havárii musí být mapované na různé řídicí roviny v různých oblastech. Tato data musíte udržovat v synchronizaci pravidelně pomocí řešení založeného na skriptech, a to buď synchronizačním nástrojem, nebo pracovním postupem CI/CD. Není nutné synchronizovat data ze samotné sítě výpočetní roviny, například z pracovních procesů Databricks Runtime.
Pokud používáte funkci injektáže virtuální sítě (není dostupná u všech typů předplatného a nasazení), můžete tyto sítě konzistentně nasazovat v obou oblastech pomocí nástrojů založených na šablonách, jako je Terraform.
Kromě toho je potřeba zajistit, aby se zdroje dat replikovaly podle potřeby napříč oblastmi.
Obecné osvědčené postupy
Mezi obecné osvědčené postupy pro úspěšný plán zotavení po havárii patří:
Zjistěte, které procesy jsou pro firmu důležité a které musí běžet při zotavení po havárii.
Jasně určete, které služby jsou zapojeny, které data se zpracovávají, jaké jsou toky dat a kde jsou uloženy.
Co nejvíce izolujte služby a data. Můžete například vytvořit speciální kontejner cloudového úložiště pro data pro zotavení po havárii nebo přesunout objekty Azure Databricks potřebné během havárie do samostatného pracovního prostoru.
Je vaší zodpovědností udržovat integritu mezi primárním a sekundárním nasazením pro jiné objekty, které nejsou uložené v řídicí rovině Databricks.
Upozorňující
Osvědčeným postupem není ukládat data v kořenové službě ADLS Gen2 (pro pracovní prostory vytvořené před 6. březnem 2023, Azure Blob Storage), které se používají pro kořenový přístup DBFS pro pracovní prostor. Kořenové úložiště DBFS není podporováno pro produkční zákaznická data. Databricks také nedoporučuje ukládat knihovny, konfigurační soubory ani inicializační skripty v tomto umístění.
Pokud je to možné, doporučujeme pro replikaci a redundanci použít nativní nástroje Azure pro replikaci a redundanci k replikaci dat do oblastí zotavení po havárii.
Volba strategie řešení obnovení
Typická řešení zotavení po havárii zahrnují dva (nebo možná více) pracovních prostorů. Můžete zvolit několik strategií. Vezměte v úvahu potenciální délku přerušení (hodiny nebo dokonce i den), úsilí o zajištění plného provozu pracovního prostoru a úsilí o obnovení (navrácení služeb po obnovení) do primární oblasti.
Strategie řešení aktivní-pasivní
Nejobvyklejším a nejjednodušším řešením je aktivní-pasivní řešení a tento typ řešení je zaměřen na tento článek. Aktivní-pasivní řešení synchronizuje změny dat a objektů z aktivního nasazení do pasivního nasazení. Pokud chcete, můžete mít více pasivních nasazení v různých oblastech, ale tento článek se zaměřuje na jeden pasivní přístup k nasazení. Během události zotavení po havárii se pasivní nasazení v sekundární oblasti stane aktivním nasazením.
Existují dvě hlavní varianty této strategie:
- Jednotné (podnikové) řešení: Přesně jedna sada aktivních a pasivních nasazení, která podporují celou organizaci.
- Řešení podle oddělení nebo projektu: Každé oddělení nebo doména projektu udržuje samostatné řešení zotavení po havárii. Některé organizace chtějí oddělit podrobnosti o zotavení po havárii mezi odděleními a používat pro každý tým různé primární a sekundární oblasti na základě jedinečných potřeb každého týmu.
Existují i jiné varianty, například použití pasivního nasazení pro případy použití jen pro čtení. Pokud máte úlohy, které jsou jen pro čtení, například dotazy uživatelů, můžou běžet na pasivním řešení kdykoli, pokud neupravují data nebo objekty Azure Databricks, jako jsou poznámkové bloky nebo úlohy.
Strategie řešení aktivní-aktivní
V řešení aktivní-aktivní spustíte všechny procesy dat v obou oblastech paralelně. Provozní tým musí zajistit, aby byl proces dat, jako je úloha, označený jako dokončený, pouze když se úspěšně dokončí v obou oblastech. Objekty nelze v produkčním prostředí změnit a musí dodržovat striktní povýšení CI/CD z vývoje nebo přípravy do produkčního prostředí.
Nejsložitější strategií je aktivní-aktivní řešení, a protože úlohy běží v obou oblastech, jsou další finanční náklady.
Stejně jako u strategie aktivní-pasivní můžete tuto strategii implementovat jako jednotné řešení organizace nebo podle oddělení.
V závislosti na vašem pracovním postupu možná nebudete potřebovat ekvivalentní pracovní prostor v sekundárním systému pro všechny pracovní prostory. Například pracovní prostor pro vývoj nebo přípravu nemusí potřebovat duplikát. S dobře navrženým vývojovým kanálem můžete v případě potřeby tyto pracovní prostory snadno rekonstruovat.
Volba nástrojů
Existují dva hlavní přístupy k nástrojům, které umožňují udržovat data co nejblíže mezi pracovními prostory v primární a sekundární oblasti:
- Synchronizační klient, který kopíruje z primární do sekundární: Synchronizační klient odesílá produkční data a prostředky z primární oblasti do sekundární oblasti. Obvykle se to spouští podle plánu.
- Nástroje CI/CD pro paralelní nasazení: Pro produkční kód a prostředky použijte nástroje CI/CD, které současně do obou oblastí odesílají změny do produkčních systémů. Když například nasdílíte kód a prostředky z přípravného/vývojového prostředí do produkčního prostředí, systém CI/CD ho zpřístupní současně v obou oblastech. Základní myšlenkou je zacházet se všemi artefakty v pracovním prostoru Azure Databricks jako s infrastrukturou jako kódem. Většina artefaktů může být společně nasazena do primárních i sekundárních pracovních prostorů, zatímco některé artefakty může být potřeba nasadit až po události zotavení po havárii. Nástroje najdete v tématu Automatizační skripty, ukázky a prototypy.
Následující diagram tyto dva přístupy kontrastuje.
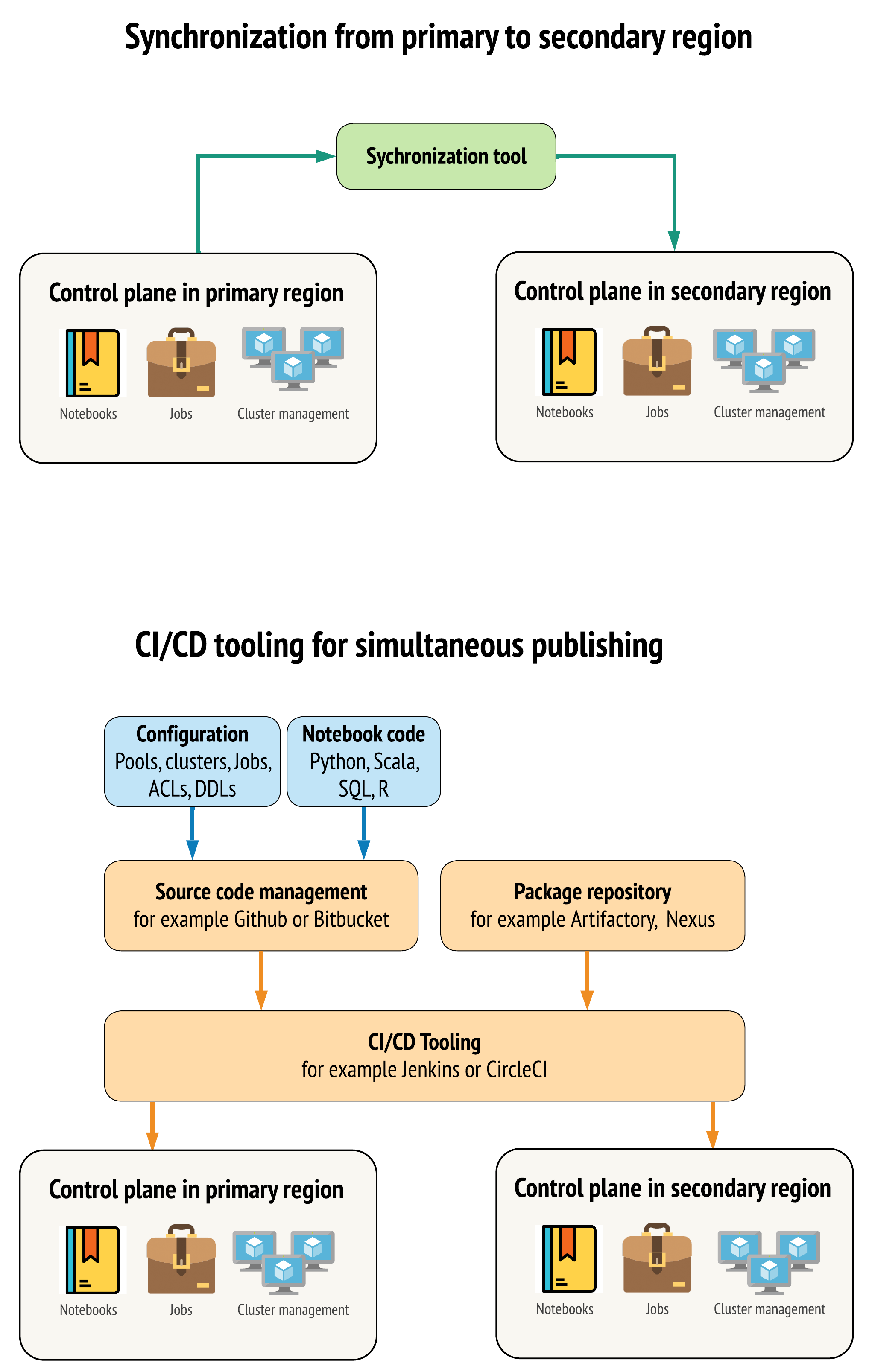
V závislosti na vašich potřebách byste mohli tyto přístupy kombinovat. Použijte například CI/CD pro zdrojový kód poznámkového bloku, ale použijte synchronizaci pro konfiguraci, jako jsou fondy a řízení přístupu.
Následující tabulka popisuje, jak zpracovávat různé typy dat s každou možností nástrojů.
| Popis | Zpracování pomocí nástrojů CI/CD | Zpracování pomocí synchronizačního nástroje |
|---|---|---|
| Zdrojový kód: Export zdroje poznámkového bloku a zdrojový kód pro zabalené knihovny | Spolusousaďte primární i sekundární. | Synchronizujte zdrojový kód z primárního do sekundárního. |
| Uživatelé a skupiny | Správa metadat jako konfigurace v Gitu Případně pro oba pracovní prostory použijte stejného zprostředkovatele identity (IdP). Spolusaďte data uživatelů a skupin do primárního a sekundárního nasazení. | Pro obě oblasti použijte SCIM nebo jinou automatizaci. Ruční vytvoření se nedoporučuje , ale pokud se používá současně pro oba. Pokud použijete ruční nastavení, vytvořte naplánovaný automatizovaný proces pro porovnání seznamu uživatelů a skupin mezi dvěma nasazeními. |
| Konfigurace fondů | Může to být šablony v Gitu. Spolusousaďte do primárního a sekundárního prostředí. V sekundárním prostředí však musí být nula, min_idle_instances dokud nedojde k události zotavení po havárii. |
Fondy vytvořené s libovolnou min_idle_instances synchronizací do sekundárního pracovního prostoru pomocí rozhraní API nebo rozhraní příkazového řádku. |
| Konfigurace úloh | Může to být šablony v Gitu. V případě primárního nasazení nasaďte definici úlohy tak, jak je. Pro sekundární nasazení nasaďte úlohu a nastavte konměnu na nulu. Tím zakážete úlohu v tomto nasazení a zabráníte dalším spuštěním. Po aktivním nasazení sekundárního nasazení změňte hodnotu konměnu. | Pokud se úlohy spouštějí z nějakého důvodu na existujících <interactive> clusterech, musí se synchronizační klient namapovat na odpovídající cluster_id v sekundárním pracovním prostoru. |
| Seznamy ACL | Může to být šablony v Gitu. Spolusaďte do primárního a sekundárního nasazení pro poznámkové bloky, složky a clustery. Data pro úlohy však uchovávají až do události zotavení po havárii. | Rozhraní API pro oprávnění může nastavit řízení přístupu pro clustery, úlohy, fondy, poznámkové bloky a složky. Synchronizační klient musí namapovat na odpovídající ID objektů pro každý objekt v sekundárním pracovním prostoru. Databricks doporučuje vytvořit mapu ID objektů z primárního do sekundárního pracovního prostoru při synchronizaci těchto objektů před replikací řízení přístupu. |
| Knihovny | Zahrňte zdrojový kód a šablony úloh nebo clusteru. | Synchronizovat vlastní knihovny z centralizovaných úložišť, DBFS nebo cloudového úložiště (je možné je připojit). |
| Inicializační skripty clusteru | Pokud chcete, zahrňte do zdrojového kódu. | Pro jednodušší synchronizaci uložte inicializační skripty v primárním pracovním prostoru do společné složky nebo do malé sady složek, pokud je to možné. |
| Přípojné body | Zahrnout do zdrojového kódu, pokud se vytváří jenom prostřednictvím úloh založených na poznámkových blocích nebo rozhraní API příkazů. | Použijte úlohy, které je možné spustit jako aktivity služby Azure Data Factory (ADF). Mějte na paměti, že koncové body úložiště se můžou změnit vzhledem k tomu, že pracovní prostory budou v různých oblastech. To závisí také na strategii zotavení po havárii dat. |
| Metadata tabulky | Zahrnout se zdrojovým kódem, pokud se vytváří jenom prostřednictvím úloh založených na poznámkových blocích nebo rozhraní API příkazů. Týká se to interního metastoru Azure Databricks nebo externího nakonfigurovaného metastoru. | Porovnejte definice metadat mezi metastory pomocí rozhraní API katalogu Sparku nebo zobrazení tabulky pomocí poznámkového bloku nebo skriptů. Všimněte si, že tabulky pro podkladové úložiště můžou být založené na oblastech a budou se mezi instancemi metastoru lišit. |
| Tajné kódy | Zahrnout do zdrojového kódu, pokud je vytvořen pouze prostřednictvím rozhraní API příkazů. Všimněte si, že mezi primárním a sekundárním obsahem může být potřeba změnit obsah tajných kódů. | Tajné kódy se vytvářejí v obou pracovních prostorech prostřednictvím rozhraní API. Všimněte si, že mezi primárním a sekundárním obsahem může být potřeba změnit obsah tajných kódů. |
| Konfigurace clusterů | Může to být šablony v Gitu. Spolusousazení do primárního a sekundárního nasazení, i když by se měly ukončit, dokud se událost zotavení po havárii neukončí. | Clustery se vytvoří po jejich synchronizaci do sekundárního pracovního prostoru pomocí rozhraní API nebo rozhraní příkazového řádku. Pokud chcete, můžete je explicitně ukončit v závislosti na nastavení automatického ukončení. |
| Oprávnění k poznámkovému bloku, úloze a složce | Může to být šablony v Gitu. Spolusaďte do primárního a sekundárního nasazení. | Replikace pomocí rozhraní API pro oprávnění |
Volba oblastí a více sekundárních pracovních prostorů
Potřebujete úplnou kontrolu nad triggerem zotavení po havárii. Můžete se rozhodnout tuto událost kdykoliv nebo z jakéhokoli důvodu aktivovat. Před restartováním režimu navrácení služeb po obnovení operace (normální produkční) musíte převzít odpovědnost za stabilizaci zotavení po havárii. Obvykle to znamená, že potřebujete vytvořit několik pracovních prostorů Azure Databricks, které budou sloužit potřebám produkčního prostředí a zotavení po havárii, a zvolit sekundární oblast převzetí služeb při selhání.
V Azure zkontrolujte replikaci dat a dostupnost typů produktů a virtuálních počítačů.
Krok 3: Příprava pracovních prostorů a jednorázové kopírování
Pokud je pracovní prostor již v produkčním prostředí, je typické spustit jednorázovou operaci kopírování pro synchronizaci pasivního nasazení s aktivním nasazením. Tato jednorázová kopie zpracovává následující:
- Replikace dat: Replikace pomocí cloudového řešení replikace nebo operace Delta Deep Clone
- Generování tokenů: Použití generování tokenů k automatizaci replikace a budoucích úloh
- Replikace pracovního prostoru: Použijte replikaci pracovního prostoru pomocí metod popsaných v kroku 4: Příprava zdrojů dat.
- Ověření pracovního prostoru: – otestujte, jestli se pracovní prostor a proces úspěšně spustí, a poskytne očekávané výsledky.
Po počáteční jednorázové operaci kopírování jsou následné akce kopírování a synchronizace rychlejší a veškeré protokolování z vašich nástrojů je také protokol toho, co se změnilo a kdy se změnilo.
Krok 4: Příprava zdrojů dat
Azure Databricks může zpracovávat velké množství zdrojů dat pomocí dávkového zpracování nebo datových proudů.
Dávkové zpracování ze zdrojů dat
Při dávkovém zpracování se data obvykle nacházejí ve zdroji dat, který lze snadno replikovat nebo doručit do jiné oblasti.
Data se například můžou pravidelně nahrávat do cloudového úložiště. V režimu zotavení po havárii pro sekundární oblast musíte zajistit, aby se soubory nahrály do úložiště sekundární oblasti. Úlohy musí číst úložiště sekundární oblasti a zapisovat do úložiště sekundární oblasti.
Datové streamy
Zpracování datového proudu je větší výzvou. Streamovaná data je možné ingestovat z různých zdrojů a zpracovávat a odesílat do řešení streamování:
- Fronta zpráv, jako je Kafka
- Stream zachytávání dat změn databáze
- Průběžné zpracování založené na souborech
- Naplánované zpracování založené na souborech, označované také jako trigger jednou
Ve všech těchto případech musíte zdroje dat nakonfigurovat tak, aby zpracovávaly režim zotavení po havárii a používaly sekundární nasazení v sekundární oblasti.
Zapisovač streamu ukládá kontrolní bod s informacemi o zpracovaných datech. Tento kontrolní bod může obsahovat umístění dat (obvykle cloudové úložiště), které je potřeba upravit na nové místo, aby se zajistilo úspěšné restartování datového proudu. Podsložka pod kontrolním bodem může například source ukládat cloudovou složku založenou na souborech.
Tento kontrolní bod se musí včas replikovat. Zvažte synchronizaci intervalu kontrolního bodu s jakýmkoli novým řešením cloudové replikace.
Aktualizace kontrolního bodu je funkcí zapisovače, a proto se vztahuje na příjem nebo zpracování datových proudů a ukládání do jiného zdroje streamování.
U úloh streamování se ujistěte, že jsou kontrolní body nakonfigurované v úložišti spravovaném zákazníkem, aby se mohly replikovat do sekundární oblasti pro obnovení úloh z bodu posledního selhání. Můžete se také rozhodnout spustit sekundární proces streamování paralelně s primárním procesem.
Krok 5: Implementace a testování řešení
Pravidelně testujte nastavení zotavení po havárii, abyste měli jistotu, že funguje správně. Pokud řešení zotavení po havárii nemůžete použít, pokud ho nemůžete použít, když ho potřebujete, neexistuje žádná hodnota. Některé společnosti přecházejí mezi oblastmi každých několik měsíců. Přepínání oblastí podle pravidelného plánu testuje předpoklady a procesy a zajišťuje, aby splňovaly vaše požadavky na obnovení. Tím zajistíte, že vaše organizace bude znát zásady a postupy pro mimořádné situace.
Důležité
Pravidelně testujte své řešení zotavení po havárii v reálných podmínkách.
Pokud zjistíte, že chybí objekt nebo šablona a stále potřebujete spoléhat na informace uložené v primárním pracovním prostoru, upravte plán tak, aby tyto překážky odstranil, replikujte tyto informace v sekundárním systému nebo je zpřístupněte jiným způsobem.
Otestujte všechny požadované organizační změny vašich procesů a obecně konfiguraci. Váš plán zotavení po havárii ovlivňuje váš kanál nasazení a je důležité, aby váš tým věděl, co je potřeba udržovat synchronizované. Po nastavení pracovních prostorů zotavení po havárii musíte zajistit, aby vaše infrastruktura (ruční nebo kód), úlohy, poznámkové bloky, knihovny a další objekty pracovního prostoru byly dostupné v sekundární oblasti.
Promluvte si se svým týmem o tom, jak rozšířit standardní pracovní procesy a kanály konfigurace a nasadit změny do všech pracovních prostorů. Správa identit uživatelů ve všech pracovních prostorech Nezapomeňte nakonfigurovat nástroje, jako je automatizace úloh a monitorování pro nové pracovní prostory.
Plánování a testování změn v nástroji konfigurace:
- Příjem dat: Zjistěte, kde jsou zdroje dat a kde tyto zdroje získávají data. Pokud je to možné, parametrizujte zdroj a ujistěte se, že máte samostatnou šablonu konfigurace pro práci se sekundárními nasazeními a sekundárními oblastmi. Připravte plán pro převzetí služeb při selhání a otestujte všechny předpoklady.
- Změny provádění: Pokud máte plánovač pro aktivaci úloh nebo jiných akcí, možná budete muset nakonfigurovat samostatný plánovač, který funguje se sekundárním nasazením nebo jeho zdroji dat. Připravte plán pro převzetí služeb při selhání a otestujte všechny předpoklady.
- Interaktivní připojení: Zvažte, jak může mít konfigurace, ověřování a síťová připojení vliv na regionální přerušení pro jakékoli použití rozhraní REST API, nástrojů rozhraní příkazového řádku nebo jiných služeb, jako je JDBC/ODBC. Připravte plán pro převzetí služeb při selhání a otestujte všechny předpoklady.
- Změny automatizace: Pro všechny automatizační nástroje připravte plán pro převzetí služeb při selhání a otestujte všechny předpoklady.
- Výstupy: Pro všechny nástroje, které generují výstupní data nebo protokoly, připravte plán pro převzetí služeb při selhání a otestujte všechny předpoklady.
Testovací převzetí služeb při selhání
Zotavení po havárii může aktivovat mnoho různých scénářů. Může se aktivovat neočekávaným přerušením. Některé základní funkce můžou být mimo provoz, včetně cloudové sítě, cloudového úložiště nebo jiné základní služby. Nemáte přístup k řádnému vypnutí systému a musíte se pokusit obnovit. Tento proces ale může být aktivován vypnutím nebo plánovaným výpadkem nebo pravidelným přepínáním aktivních nasazení mezi dvěma oblastmi.
Při testování převzetí služeb při selhání se připojte k systému a spusťte proces vypnutí. Ujistěte se, že jsou všechny úlohy dokončené a clustery jsou ukončené.
Synchronizační klient (nebo nástroje CI/CD) může replikovat relevantní objekty a prostředky Azure Databricks do sekundárního pracovního prostoru. Pokud chcete aktivovat sekundární pracovní prostor, může váš proces obsahovat některé nebo všechny tyto možnosti:
- Spuštěním testů ověřte, že je platforma aktuální.
- Zakažte fondy a clustery v primární oblasti, aby pokud služba, která selhala, vrátila online, primární oblast nespustí zpracování nových dat.
- Proces obnovení:
- Zkontrolujte datum nejnovějších synchronizovaných dat. Viz terminologie odvětví zotavení po havárii. Podrobnosti tohoto kroku se liší podle toho, jak synchronizujete data a vaše jedinečné obchodní potřeby.
- Stabilizujte zdroje dat a ujistěte se, že jsou všechny dostupné. Zahrňte všechny externí zdroje dat, jako je Azure Cloud SQL, a také soubory Delta Lake, Parquet nebo jiné soubory.
- Vyhledejte bod obnovení streamování. Nastavte proces, který se má odsud restartovat, a mít proces připravený k identifikaci a odstranění potenciálních duplicit (Delta Lake Lake to usnadňuje).
- Dokončete proces toku dat a informujte uživatele.
- Spusťte relevantní fondy (nebo zvyšte počet relevantních
min_idle_instances). - Spusťte relevantní clustery (pokud není ukončeno).
- Změňte souběžné spuštění úloh a spusťte relevantní úlohy. Může se jednat o jednorázová spuštění nebo pravidelná spuštění.
- Pro jakýkoli vnější nástroj, který používá adresu URL nebo název domény pro váš pracovní prostor Azure Databricks, aktualizujte konfigurace tak, aby zohlednily novou řídicí rovinu. Například aktualizujte adresy URL pro rozhraní REST API a připojení JDBC/ODBC. Adresa URL webové aplikace Azure Databricks zobrazená zákazníkem se změní, když se řídicí rovina změní, takže uživatelům vaší organizace upozorněte na novou adresu URL.
Testovací obnovení (navrácení služeb po obnovení)
Navrácení služeb po obnovení je jednodušší a dá se provést v časovém období údržby. Tento plán může zahrnovat některé nebo všechny následující položky:
- Získejte potvrzení, že se obnovila primární oblast.
- Zakažte fondy a clustery v sekundární oblasti, aby se nezačla zpracovávat nová data.
- Synchronizujte všechny nové nebo upravené prostředky v sekundárním pracovním prostoru zpět s primárním nasazením. V závislosti na návrhu skriptů převzetí služeb při selhání můžete spustit stejné skripty pro synchronizaci objektů ze sekundární oblasti (zotavení po havárii) do primární (produkční) oblasti.
- Synchronizujte všechny nové aktualizace dat zpět do primárního nasazení. Záznamy auditu protokolů a tabulek Delta můžete použít k zajištění žádné ztráty dat.
- Vypněte všechny úlohy v oblasti zotavení po havárii.
- Změňte adresu URL úloh a uživatelů na primární oblast.
- Spuštěním testů ověřte, že je platforma aktuální.
- Zahajte relevantní fondy (nebo zvyšte
min_idle_instanceshodnotu na příslušné číslo). - Spusťte relevantní clustery (pokud není ukončeno).
- Změňte souběžné spuštění úloh a spusťte relevantní úlohy. Může se jednat o jednorázová spuštění nebo pravidelná spuštění.
- Podle potřeby znovu nastavte sekundární oblast pro budoucí zotavení po havárii.
Automatizační skripty, ukázky a prototypy
Skripty pro automatizaci, které je potřeba zvážit pro vaše projekty zotavení po havárii:
- Databricks doporučuje, abyste k vývoji vlastního procesu synchronizace použili zprostředkovatele Terraformu Databricks.
- Ukázkové a prototypové skripty najdete také v nástrojích pro migraci pracovních prostorů Databricks. Kromě objektů Azure Databricks replikujte všechny relevantní kanály Azure Data Factory, aby odkazovaly na propojenou službu , která je namapovaná na sekundární pracovní prostor.
- Projekt Databricks Sync (DBSync) je nástroj pro synchronizaci objektů, který zálohuje, obnovuje a synchronizuje pracovní prostory Databricks.