Starší verze obsluhy modelů MLflow v Azure Databricks
Důležité
Tato funkce je ve verzi Public Preview.
Důležité
- Tato dokumentace byla vyřazena a nemusí být aktualizována. Produkty, služby nebo technologie uvedené v tomto obsahu se už nepodporují.
- Pokyny v tomto článku jsou určené pro službu starší verze modelu MLflow. Databricks doporučuje migrovat model obsluhující pracovní postupy do služby Model Obsluha pro vylepšené nasazení a škálovatelnost koncového bodu modelu. Další informace naleznete v tématu Nasazení modelů pomocí služby Mosaic AI Model Serving.
Starší verze obsluhy modelů MLflow umožňuje hostovat modely strojového učení z registru modelů jako koncové body REST, které se aktualizují automaticky na základě dostupnosti verzí modelu a jejich fází. Používá cluster s jedním uzlem, který běží pod vlastním účtem v rámci toho, co se teď nazývá klasická výpočetní rovina. Tato výpočetní rovina zahrnuje virtuální síť a přidružené výpočetní prostředky, jako jsou clustery pro poznámkové bloky a úlohy, pro a klasické služby SQL Warehouse a starší verze modelu obsluhující koncové body.
Když povolíte, aby model obsluhoval daný zaregistrovaný model, Azure Databricks automaticky vytvoří jedinečný cluster pro model a nasadí všechny nechivované verze modelu v daném clusteru. Azure Databricks restartuje cluster, pokud dojde k chybě a cluster ukončí, když zakážete model obsluhující model. Model obsluhující automaticky synchronizuje s registrem modelů a nasadí všechny nové registrované verze modelu. Nasazené verze modelu je možné dotazovat pomocí standardního požadavku rozhraní REST API. Azure Databricks ověřuje požadavky na model pomocí jeho standardního ověřování.
I když je tato služba ve verzi Preview, Databricks doporučuje její použití pro nízké propustnosti a nekritické aplikace. Cílová propustnost je 200 qps a cílová dostupnost je 99,5 %, i když se žádná záruka neprodá. Kromě toho platí limit velikosti datové části 16 MB na požadavek.
Každá verze modelu se nasadí pomocí nasazení modelu MLflow a spustí se v prostředí Conda určeném jeho závislostmi.
Poznámka:
- Cluster se udržuje, pokud je povolená obsluha, i když neexistuje žádná aktivní verze modelu. Chcete-li ukončit obslužný cluster, zakažte obsluhu modelu pro zaregistrovaný model.
- Cluster se považuje za celoúčelový cluster, na který se vztahují ceny všech úloh.
- Globální inicializační skripty se nespouštějí na modelech obsluhujících clustery.
Důležité
Anaconda Inc. aktualizoval své podmínky služby pro kanály anaconda.org. Na základě nových podmínek služby můžete vyžadovat komerční licenci, pokud spoléháte na balení a distribuci Anaconda. Další informace najdete v tématu Anaconda Commercial Edition – nejčastější dotazy . Vaše používání všech kanálů Anaconda se řídí jejich podmínkami služby.
Modely MLflow protokolované před verzí 1.18 (Databricks Runtime 8.3 ML nebo starší) byly ve výchozím nastavení protokolovány pomocí kanálu Conda defaults (https://repo.anaconda.com/pkgs/) jako závislosti. Kvůli této změně licence služba Databricks zastavila používání defaults kanálu pro modely protokolované pomocí MLflow verze 1.18 a vyšší. Výchozí protokolovaný kanál je nyní conda-forge, který odkazuje na komunitu spravovanou https://conda-forge.org/.
Pokud jste model zaprotokolovali před MLflow verze 1.18 bez vyloučení defaults kanálu z prostředí Conda pro model, může mít tento model závislost na defaults kanálu, který jste možná nezamýšleli.
Pokud chcete ručně ověřit, jestli má model tuto závislost, můžete prozkoumat channel hodnotu v conda.yaml souboru, který je zabalený s protokolovaným modelem. Model s závislostí conda.yaml kanálu může například defaults vypadat takto:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Protože Databricks nedokáže určit, jestli vaše použití úložiště Anaconda k interakci s vašimi modely je povoleno v rámci vašeho vztahu s Anaconda, Databricks nevynucuje svým zákazníkům provádět žádné změny. Pokud je vaše použití Anaconda.com úložiště prostřednictvím použití Databricks povolené podle podmínek Anaconda, nemusíte nic dělat.
Pokud chcete změnit kanál použitý v prostředí modelu, můžete model znovu zaregistrovat do registru modelů pomocí nového conda.yaml. Můžete to provést zadáním kanálu v parametru conda_env .log_model()
Další informace o log_model() rozhraní API najdete v dokumentaci MLflow pro variantu modelu, se kterou pracujete, například log_model pro scikit-learn.
Další informace o conda.yaml souborech najdete v dokumentaci K MLflow.
Požadavky
- Starší verze obsluhy modelů MLflow je k dispozici pro modely Python MLflow. Musíte deklarovat všechny závislosti modelu v prostředí conda. Viz závislosti modelu protokolu.
- Pokud chcete povolit obsluhu modelů, musíte mít oprávnění k vytvoření clusteru.
Model obsluhující z registru modelů
Obsluha modelů je dostupná v Azure Databricks z Registru modelů.
Povolení a zakázání obsluhy modelů
Model povolíte pro poskytování ze stránky zaregistrovaného modelu.
Klikněte na kartu Obsluha. Pokud model ještě není povolený pro obsluhu, zobrazí se tlačítko Povolit obsluhu.
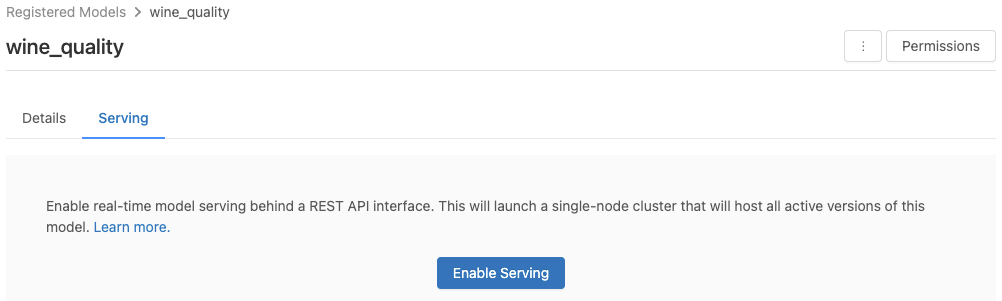
Klikněte na Povolit obsluhu. Zobrazí se karta Obsluha se stavem čekajícími na vyřízení. Po několika minutách se stav změní na Připraveno.
Chcete-li zakázat model pro obsluhu, klikněte na tlačítko Zastavit.
Ověření obsluhy modelu
Na kartě Obsluha můžete odeslat požadavek do obsluhovaného modelu a zobrazit odpověď.
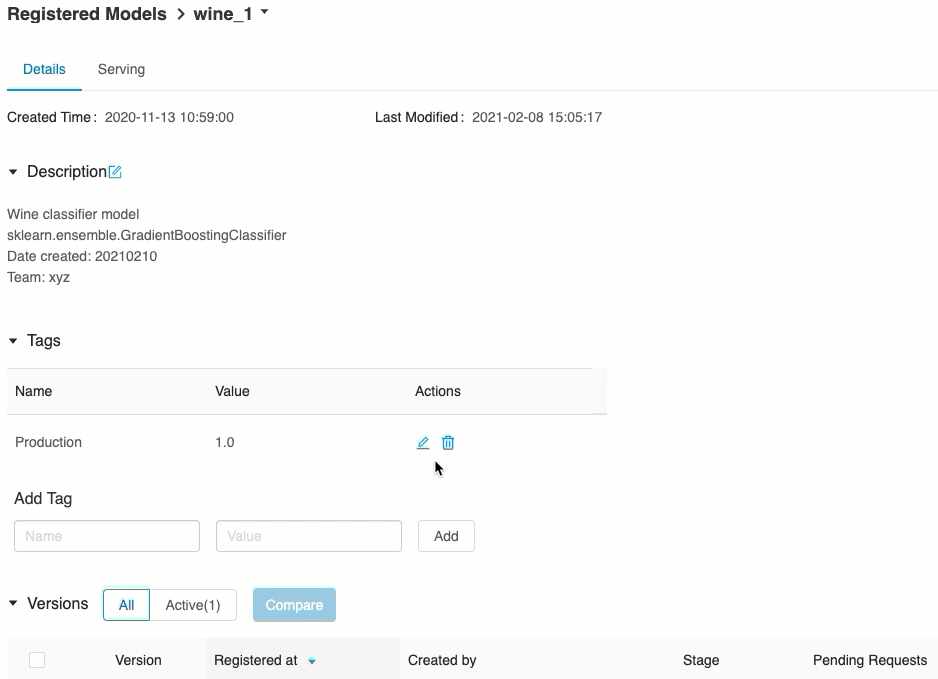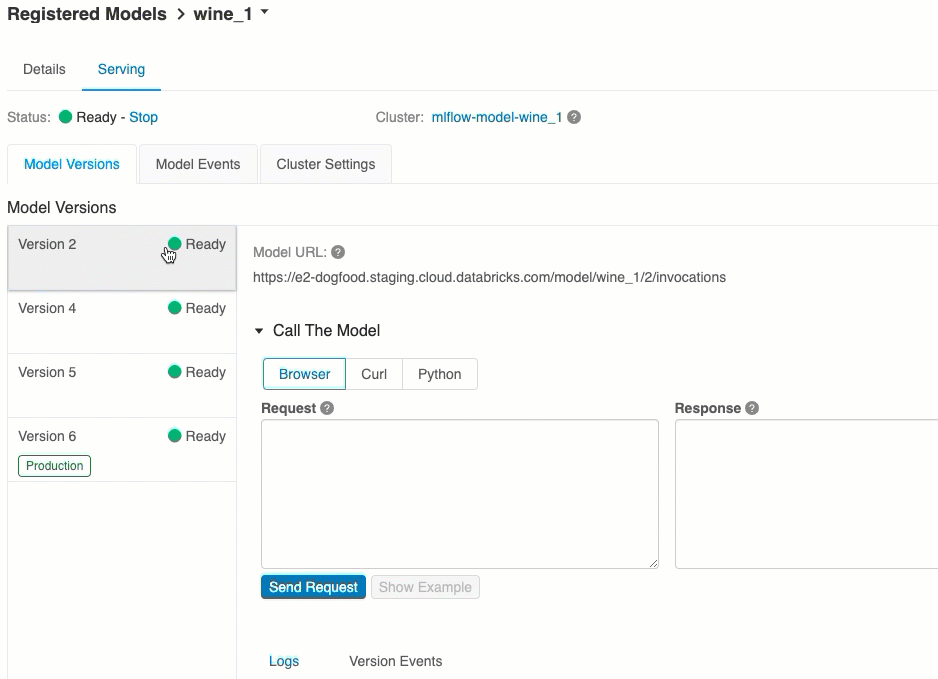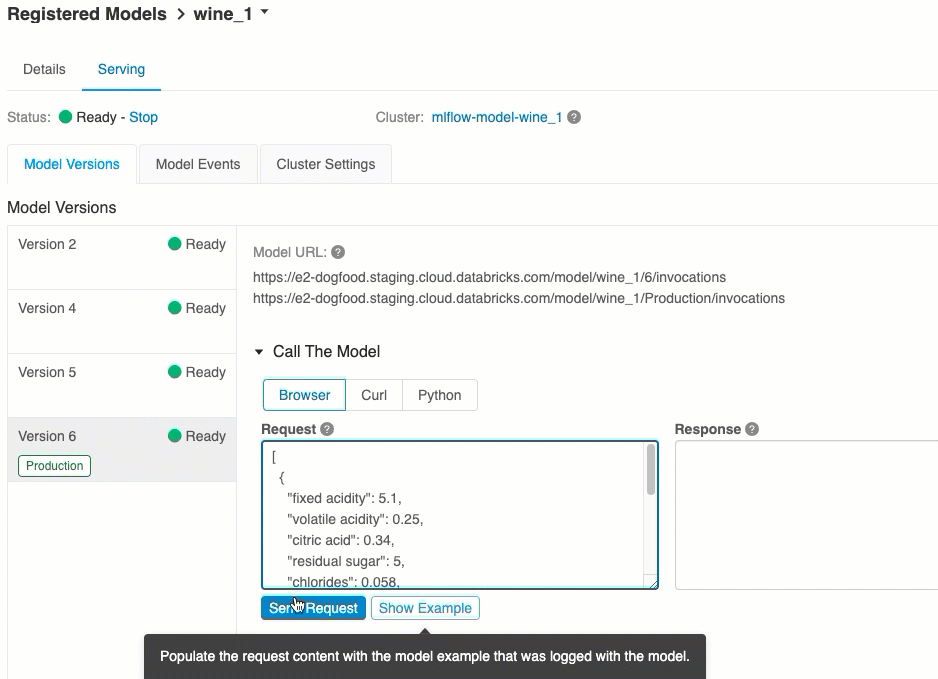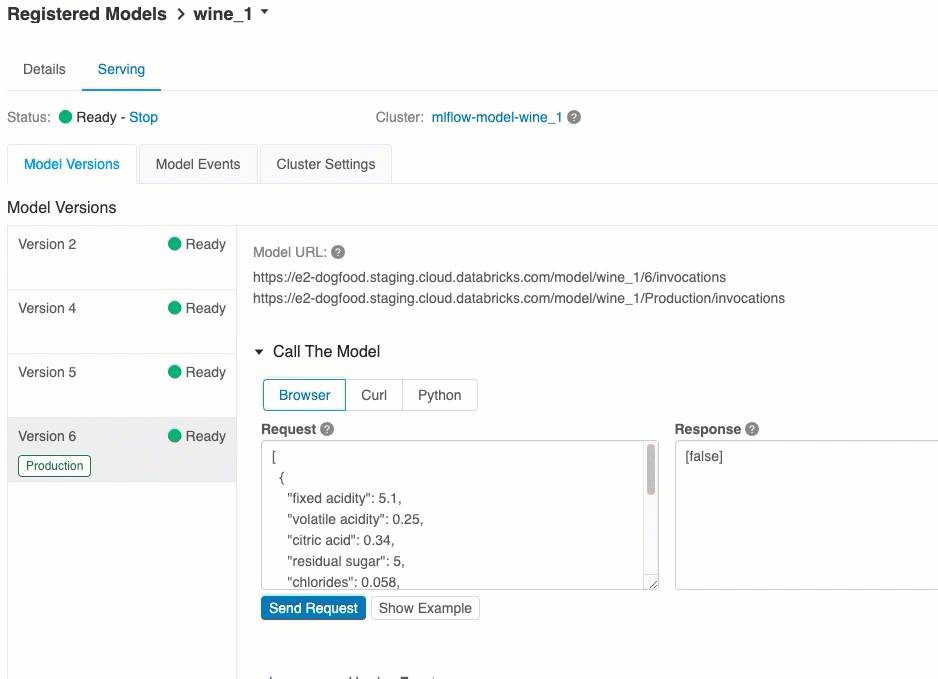
Identifikátory URI verze modelu
Každá nasazená verze modelu má přiřazenou jednu nebo několik jedinečných identifikátorů URI. Každá verze modelu má minimálně přiřazený identifikátor URI vytvořený následujícím způsobem:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Pokud například chcete volat verzi 1 modelu zaregistrovaného jako iris-classifier, použijte tento identifikátor URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
Verzi modelu můžete také volat podle fáze. Pokud je například verze 1 v produkční fázi, můžete ji také získat skóre pomocí tohoto identifikátoru URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Seznam dostupných identifikátorů URI modelů se zobrazí v horní části karty Verze modelu na stránce obsluhy.
Správa obsluhované verze
Nasadí se všechny aktivní (nearchivované) verze modelu a můžete je dotazovat pomocí identifikátorů URI. Azure Databricks automaticky nasadí nové verze modelu při jejich registraci a automaticky odebere staré verze při jejich archivaci.
Poznámka:
Všechny nasazené verze registrovaného modelu sdílejí stejný cluster.
Správa přístupových práv modelu
Přístupová práva modelu se dědí z registru modelů. Povolení nebo zakázání funkce obsluhy vyžaduje oprávnění ke správě registrovaného modelu. Každý, kdo má práva ke čtení, může určit skóre kterékoli z nasazených verzí.
Určení skóre nasazených verzí modelu
K určení skóre nasazeného modelu můžete použít uživatelské rozhraní nebo odeslat požadavek rozhraní REST API na identifikátor URI modelu.
Skóre přes uživatelské rozhraní
Jedná se o nejjednodušší a nejrychlejší způsob, jak model otestovat. Vstupní data modelu můžete vložit ve formátu JSON a kliknout na Odeslat požadavek. Pokud byl model zaprotokolován pomocí vstupního příkladu (jak je znázorněno na obrázku výše), klikněte na načíst příklad pro načtení vstupního příkladu.
Skóre prostřednictvím požadavku rozhraní REST API
Žádost o bodování můžete odeslat prostřednictvím rozhraní REST API pomocí standardního ověřování Databricks. Následující příklady ukazují ověřování pomocí tokenu pat s MLflow 1.x.
Poznámka:
Osvědčeným postupem při ověřování pomocí automatizovaných nástrojů, systémů, skriptů a aplikací doporučuje Databricks místo uživatelů pracovního prostoru používat tokeny patního přístupu, které patří instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Vzhledem k MODEL_VERSION_URI, podobně jako https://<databricks-instance>/model/iris-classifier/Production/invocations (kde <databricks-instance> je název vaší instance Databricks) a nazývaný token REST API Databricks DATABRICKS_API_TOKENnásledující příklady ukazují, jak dotazovat obsluhovaný model.
Následující příklady odrážejí formát bodování pro modely vytvořené pomocí MLflow 1.x. Pokud raději používáte MLflow 2.0, musíte aktualizovat formát datové části požadavku.
Bash
Fragment kódu pro dotazování modelu, který přijímá vstupy datového rámce
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Fragment kódu pro dotazování modelu, který přijímá vstupy tensoru Vstupy Tensoru by měly být formátované, jak je popsáno v dokumentaci k rozhraní API služby TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Power BI
Datovou sadu v Power BI Desktopu můžete ohodnocet pomocí následujícího postupu:
Otevřete datovou sadu, kterou chcete skóre.
Přejděte na Transformovat data.
Klikněte pravým tlačítkem na levý panel a vyberte Vytvořit nový dotaz.
Přejděte do zobrazení > Rozšířený editor.
Po vyplnění příslušného
DATABRICKS_API_TOKENkódu nahraďte text dotazu následujícím fragmentem kódu aMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionPojmenujte dotaz požadovaným názvem modelu.
Otevřete rozšířený editor dotazů pro datovou sadu a použijte funkci modelu.
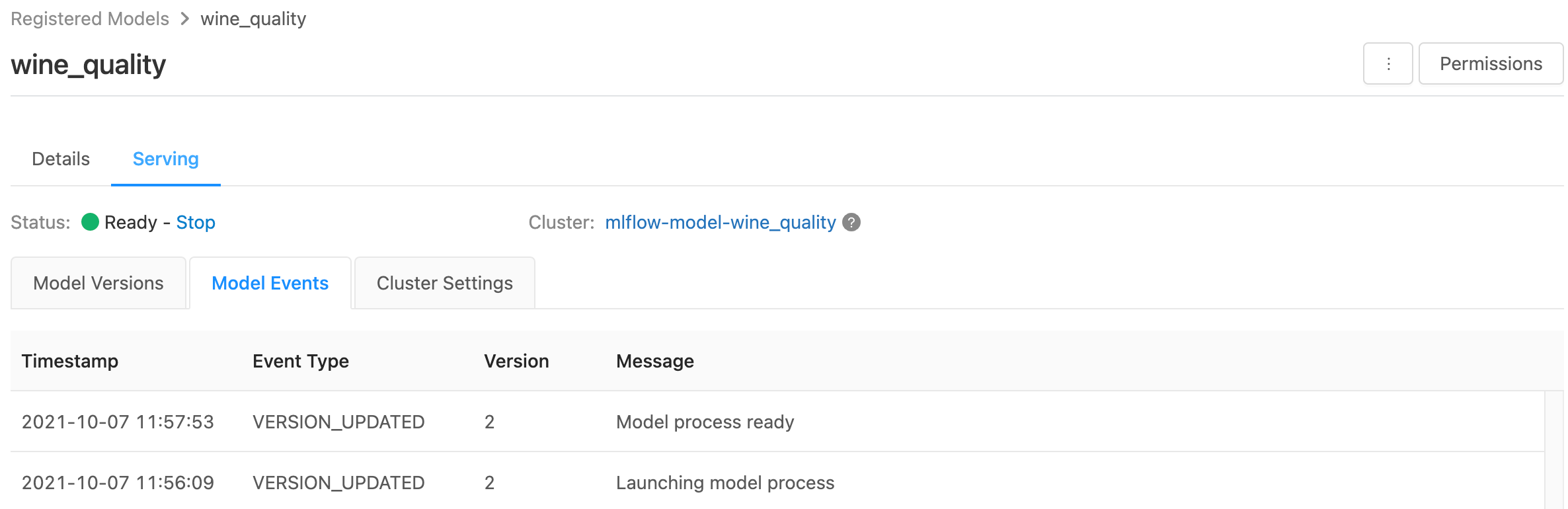
Monitorování obsluhované modely
Na stránce obsluhy se zobrazují indikátory stavu obsluhujícího clusteru a také jednotlivé verze modelu.
- Ke kontrole stavu obsluhujícího clusteru použijte kartu Události modelu, která zobrazuje seznam všech obslužných událostí pro tento model.
- Pokud chcete zkontrolovat stav jedné verze modelu, klikněte na kartu Verze modelu a posuňte se a zobrazte karty Protokoly nebo Události verzí.
Přizpůsobení obslužného clusteru
Chcete-li přizpůsobit obslužný cluster, použijte kartu Nastavení clusteru na kartě Obsluha .
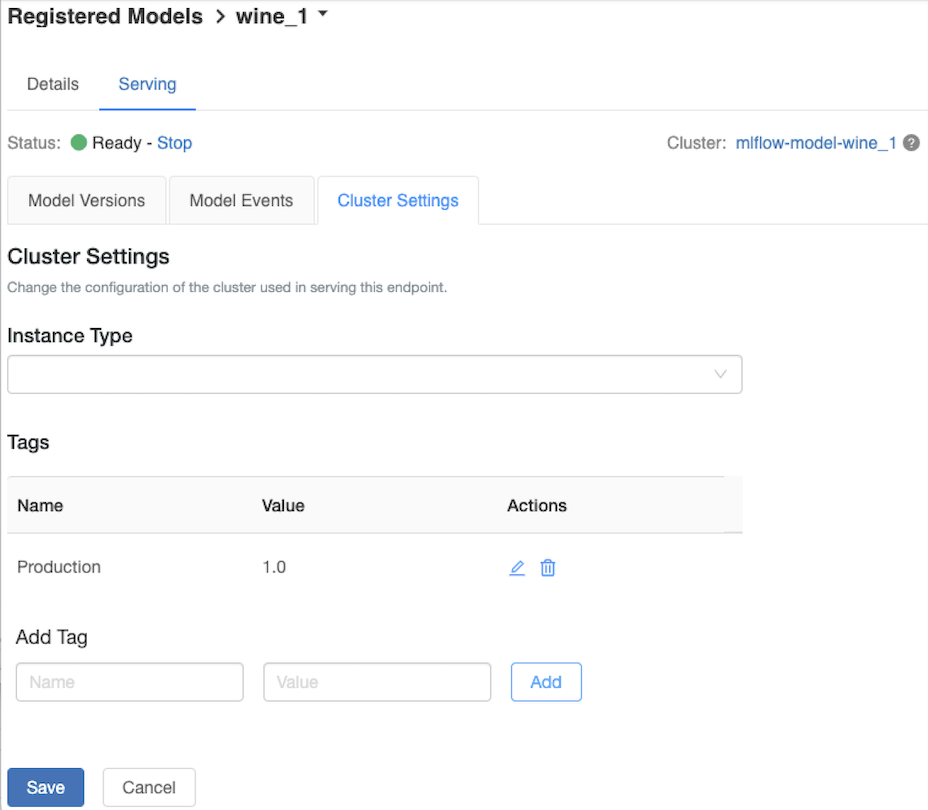
- Pokud chcete upravit velikost paměti a počet jader obslužného clusteru, vyberte požadovanou konfiguraci clusteru pomocí rozevírací nabídky Typ instance. Po kliknutí na tlačítko Uložit se existující cluster ukončí a vytvoří se nový cluster se zadaným nastavením.
- Pokud chcete přidat značku, zadejte název a hodnotu do polí Přidat značku a klikněte na Přidat.
- Pokud chcete upravit nebo odstranit existující značku, klikněte na některou z ikon ve sloupci Akce tabulky Značky.
Integrace úložiště funkcí
Služby pro starší modely mohou automaticky vyhledat hodnoty atributů ze zveřejněných online obchodů.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Známé chyby
ResolvePackageNotFound: pyspark=3.1.0
K této chybě může dojít, pokud model závisí na pyspark a je protokolován pomocí Databricks Runtime 8.x.
Pokud se zobrazí tato chyba, pomocí parametru pysparkexplicitně zadejte conda_env verzi.
Unrecognized content type parameters: format
K této chybě může dojít v důsledku nového formátu protokolu bodování MLflow 2.0. Pokud se tato chyba zobrazuje, pravděpodobně používáte zastaralý formát žádosti o bodování. Pokud chcete chybu vyřešit, můžete:
Aktualizujte formát žádosti o bodování na nejnovější protokol.
Poznámka:
Následující příklady odrážejí formát bodování zavedený v MLflow 2.0. Pokud raději používáte MLflow 1.x, můžete upravit
log_model()volání rozhraní API tak, aby zahrnovala požadovanou závislost verze MLflow do parametruextra_pip_requirements. Tím zajistíte, že se použije vhodný formát bodování.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Dotazování modelu, který přijímá vstupy datového rámce pandas
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Dotazování modelu, který přijímá vstupy tensoru Vstupy Tensoru by měly být formátované, jak je popsáno v dokumentaci k rozhraní API služby TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Power BI
Datovou sadu v Power BI Desktopu můžete ohodnocet pomocí následujícího postupu:
Otevřete datovou sadu, kterou chcete skóre.
Přejděte na Transformovat data.
Klikněte pravým tlačítkem na levý panel a vyberte Vytvořit nový dotaz.
Přejděte do zobrazení > Rozšířený editor.
Po vyplnění příslušného
DATABRICKS_API_TOKENkódu nahraďte text dotazu následujícím fragmentem kódu aMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionPojmenujte dotaz požadovaným názvem modelu.
Otevřete rozšířený editor dotazů pro datovou sadu a použijte funkci modelu.
Pokud váš požadavek na hodnocení používá klienta MLflow, například
mlflow.pyfunc.spark_udf()upgrade klienta MLflow na verzi 2.0 nebo vyšší, aby používal nejnovější formát. Přečtěte si další informace o aktualizovaném protokolu bodování modelů MLflow v MLflow 2.0.
Další informace o formátech vstupních dat přijatých serverem (například rozdělený formát pandas) najdete v dokumentaci K MLflow.