Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
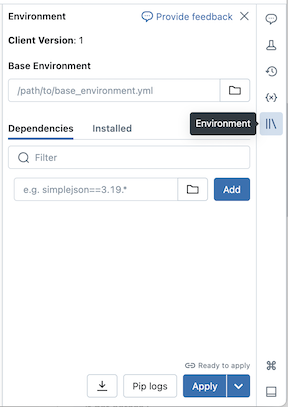
Tato stránka vysvětluje, jak pomocí bočního panelu Prostředí bez serveru konfigurovat závislosti, zásady použití bez serveru, paměť a základní prostředí. Tento panel poskytuje jediné místo pro správu nastavení bezserverového poznámkového bloku. Nastavení nakonfigurovaná na tomto panelu platí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.
Pokud chcete rozbalit boční panel Prostředí , klikněte na tlačítko ![]() napravo od poznámkového bloku.
napravo od poznámkového bloku.
Využijte běhové prostředí AI (GPU bez serveru)
Important
Prostředí pro AI je ve veřejné předběžné verzi.
Podle těchto kroků nakonfigurujte modul runtime AI, který využívá výpočetní prostředí GPU bez serveru, v poznámkovém bloku Databricks:
- V notebooku klikněte na rozevírací nabídku výpočet v horní části a vyberte bezserverové GPU.
- Kliknutím na
 otevřete boční panel Prostředí .
otevřete boční panel Prostředí . - V poli Akcelerátor vyberte A10.
- V části Základní prostředí vyberte Standard pro výchozí prostředí nebo AI pro prostředí optimalizované pro AI s předinstalovanými knihovnami strojového učení.
- Klikněte na Použít a poté potvrďte, že chcete použít AI Runtime pro vaše prostředí poznámkového bloku.
Další podrobnosti najdete na AI Runtime.
Použijte vysoce paměťově nenáročné bezserverové výpočetní kapacity
Important
Tato funkce je ve verzi Public Preview.
Pokud v poznámkovém bloku narazíte na chyby nedostatku paměti, můžete poznámkový blok nakonfigurovat tak, aby používal větší velikost paměti. Toto nastavení zvětší velikost paměti REPL použitou při spouštění kódu v poznámkovém bloku. Nemá vliv na velikost paměti relace Spark. Bezserverové využití s vysokou pamětí má vyšší rychlost emisí DBU než standardní paměť.
Dostupné možnosti paměti:
- Standard: celková paměť 16 GB.
- Vysoká: celková paměť 32 GB.
Chcete-li nakonfigurovat nastavení paměti poznámkového bloku:
- V uživatelském rozhraní poznámkového bloku klikněte na bočního panelu environmentprostředí.
- V části Paměťvyberte možnost Vysoká paměť.
- Klikněte na tlačítko Použit.
Toto nastavení platí také pro úlohy poznámkového bloku, které se spouštějí s využitím předvoleb paměti poznámkového bloku. Aktualizace předvoleb paměti v poznámkovém bloku ovlivní další spuštění úlohy.
Výběr zásady použití bez serveru
Important
Tato funkce je ve verzi Public Preview.
Zásady bezserverového využití umožňují vaší organizaci používat vlastní značky na bezserverové využití za účelem podrobného přiřazení fakturace.
Pokud váš pracovní prostor používá zásady použití bez serveru k atributu bezserverového využití, můžete pro poznámkový blok vybrat zásady použití bez serveru, které chcete použít. Pokud je uživatel přiřazený jenom k jedné zásadě použití bez serveru, je tato zásada ve výchozím nastavení vybraná.
Po připojení poznámkového bloku k bezserverovému výpočetnímu prostředí můžete vybrat zásady použití bez serveru pomocí bočního panelu Prostředí :
- V uživatelském rozhraní poznámkového bloku klikněte na bočního panelu environmentprostředí.
- V části Zásady použití bez serveru vyberte zásady bezserverového použití, které chcete použít pro poznámkový blok.
- Klikněte na tlačítko Použit.
Po dokončení tohoto nastavení zdědí všechna použití poznámkového bloku vlastní značky těchto zásad bezserverového využití.
Note
Pokud váš poznámkový blok pochází z úložiště Git nebo nemá přiřazenou žádnou zásadu použití bez serveru, automaticky se použije poslední vámi zvolená zásada použití bez serveru, jakmile bude poznámkový blok znovu připojen k bezserverovému výpočetnímu prostředí.
Výběr základního prostředí
Základní pracovní prostředí určuje již předinstalované knihovny a verzi pracovního prostředí dostupné pro váš bezserverový poznámkový blok. Selektor základního prostředí na bočním panelu Prostředí poskytuje jednotné rozhraní pro výběr prostředí. Podrobnosti o jednotlivých verzích prostředí najdete v tématu Bezserverové verze prostředí. Databricks doporučuje používat nejnovější verzi, aby bylo možné využívat nejnovější funkce poznámkového bloku.
Selektor základního prostředí obsahuje následující možnosti:
- Standard: Výchozí základní prostředí s knihovnami poskytovanými službou Databricks.
- AI: Základní prostředí optimalizované pro AI s předinstalovanými knihovnami strojového učení. Tato možnost se zobrazí pouze v případě, že je vybrán akcelerátor (GPU).
-
Další: Rozbalí a zobrazí další možnosti.
- Předchozí verze prostředí Standard a AI
- Vlastní: Umožňuje zadat vlastní prostředí pomocí souboru YAML.
- Prostředí pracovního prostoru: Zobrazí seznam všech kompatibilních základních prostředí nakonfigurovaných pro váš pracovní prostor správcem.
Výběr základního prostředí:
- V uživatelském rozhraní poznámkového bloku klikněte na bočního panelu environmentprostředí.
- V části Základní prostředí vyberte prostředí z rozevírací nabídky.
- Klikněte na tlačítko Použit.
Přidání závislostí do poznámkového bloku
Vzhledem k tomu, že bezserverová služba nepodporuje zásady výpočetních prostředků ani inicializační skripty, je nutné přidat vlastní závislosti pomocí bočního panelu Prostředí . Můžete přidat závislosti jednotlivě nebo použít sdílené základní prostředí k instalaci více závislostí.
Individuální přidání závislosti:
V uživatelském rozhraní poznámkového bloku klikněte na bočního panelu environmentprostředí.
V části Závislosti klepněte na tlačítko Přidat závislost a zadejte cestu závislosti do pole. Závislost můžete zadat v libovolném formátu, který je platný v souboru requirements.txt . Python soubory kol nebo projekty Python (například adresář obsahující
pyproject.tomlnebosetup.py) mohou být umístěny v souborech pracovního prostoru nebo ve svazcích katalogu Unity.- Pokud používáte soubor pracovního prostoru, měla by být cesta absolutní a začínat na
/Workspace/. - Pokud používáte soubor ve svazku katalogu Unity, měla by být cesta v následujícím formátu:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.
- Pokud používáte soubor pracovního prostoru, měla by být cesta absolutní a začínat na
Klikněte na tlačítko Použit. Tím se nainstalují závislosti ve virtuálním prostředí poznámkového bloku a restartuje proces Python.
Important
Neinstalujte PySpark ani žádnou knihovnu, která nainstaluje PySpark jako závislost na bezserverových poznámkových blocích. Pokud tak učiníte, zastavíte relaci a výsledkem bude chyba. Pokud k tomu dojde, odeberte knihovnu a resetujte prostředí.
Chcete-li zobrazit nainstalované závislosti, klepněte na kartu Nainstalováno na bočním panelu Prostředí . Protokoly instalace pip pro prostředí poznámkového bloku jsou k dispozici také kliknutím na protokoly pip v dolní části panelu.
Vytvoření vlastní specifikace prostředí
Můžete vytvářet a opakovaně používat vlastní specifikace prostředí.
- V prostředí serverless notebooku vyberte základní prostředí a přidejte závislosti, které chcete nainstalovat.
- Klikněte na ikonu nabídky
 v dolní části panelu prostředí a poté klikněte na Exportovat prostředí.
v dolní části panelu prostředí a poté klikněte na Exportovat prostředí. - Uložte specifikaci jako soubor Workspace nebo ve svazku katalogu Unity.
Pokud chcete v poznámkovém bloku použít specifikaci vlastního prostředí, vyberte v rozevírací nabídce Vlastní ze Základní prostředí a pak pomocí ![]() ikony složky vyberte svůj soubor YAML.
ikony složky vyberte svůj soubor YAML.
Vytvoření běžných nástrojů pro sdílení napříč pracovním prostorem
Následující příklad ukazuje, jak uložit běžný nástroj do souboru pracovního prostoru a přidat ho jako závislost do bezserverového poznámkového bloku:
Vytvořte složku s následující strukturou. Ověřte, že uživatelé projektu mají odpovídající přístup k cestě k souboru:
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlNaplnit
pyproject.tomltakto:[project] name = "common_utils" version = "0.1.0"Přidejte do
init.pysouboru funkci. Například:def greet(name: str) -> str: return f"Hello, {name}!"V uživatelském rozhraní notebooku klikněte na ikonu Prostředí na bočním panelu
.V části Závislosti klepněte na tlačítko Přidat závislost a zadejte cestu k souboru util. Například:
/Workspace/helper_utils.Klikněte na tlačítko Použit.
Teď můžete funkci použít v poznámkovém bloku:
from helpers import greet
print(greet('world'))
Tento výstup je následující:
Hello, world!
Resetování závislostí prostředí
Pokud je poznámkový blok připojený k bezserverovému výpočetnímu prostředí, Databricks automaticky ukládá obsah virtuálního prostředí poznámkového bloku do mezipaměti. To znamená, že při otevření existujícího poznámkového bloku nemusíte přeinstalovat Python závislosti zadané v bočním panelu Environment, i když byl kvůli nečinnosti odpojen.
Python ukládání do mezipaměti virtuálního prostředí platí také pro úlohy. Když se spustí úloha, jakýkoli úkol, který sdílí stejnou sadu závislostí jako dokončený úkol v tomto spuštění, probíhá rychleji, protože požadované závislosti jsou již k dispozici.
Note
Pokud změníte implementaci vlastního balíčku Python použitého v úloze na bezserverové verzi, musíte také aktualizovat číslo verze, aby úlohy mohly vyzvednout nejnovější implementaci.
Pokud chcete vymazat mezipaměť prostředí a provést novou instalaci závislostí zadaných v bočním panelu Prostředí poznámkového bloku připojeného k bezserverovému výpočetnímu prostředí, klikněte na šipku vedle Použít a potom klikněte na Obnovit výchozí nastavení.
Jestliže nainstalujete balíčky, které přeruší nebo změní základního poznámkového bloku nebo prostředí Apache Spark, odstraňte problematické balíčky a poté resetujte prostředí. Spuštění nové relace nevymaže celou mezipaměť prostředí.
Konfigurace výchozích úložišť balíčků Python
Správci pracovního prostoru mohou v rámci pracovních prostorů nakonfigurovat privátní či ověřená úložiště balíčků jako výchozí konfiguraci pip pro bezserverové poznámkové bloky a bezserverové úlohy. To umožňuje uživatelům instalovat balíčky z interních úložišť Python bez explicitního definování index-url nebo extra-index-url.
Správci pracovního prostoru si mohou přečíst pokyny v Konfigurovat výchozí úložiště balíčků Python.
Nastavení prostředí pro pracovní úkoly
U typů úloh úloh, jako jsou poznámkový blok, Python skript, Python kolečka, úlohy JAR nebo dbt, se závislosti knihovny dědí z verze bezserverového prostředí. Chcete-li zobrazit seznam nainstalovaných knihoven, přečtěte si část Instalované knihovny Python nebo Instalované Java a Scala knihovny verze prostředí, kterou používáte. Pokud úloha vyžaduje knihovnu, která není nainstalovaná, můžete knihovnu nainstalovat ze souborů pracovního prostoru, svazků katalogu Unity nebo veřejného úložiště balíčků.
U poznámkových bloků s existujícím prostředím poznámkového bloku můžete úlohu spustit pomocí prostředí poznámkového bloku nebo ji přepsat výběrem prostředí na úrovni úlohy.
Important
Použití bezserverového výpočetního prostředí pro úlohy JAR je ve verzi Public Preview.
Přidání knihovny při vytváření nebo úpravě úkolu úlohy:
V rozevírací nabídce Prostředí a knihovny klikněte na
 vedle výchozího prostředí nebo klikněte na + Přidat nové prostředí.
vedle výchozího prostředí nebo klikněte na + Přidat nové prostředí.
V rozevíracím seznamu Verze prostředí vyberte verzi prostředí. Viz verze bezserverového prostředí . Databricks doporučuje vybrat nejnovější verzi, abyste získali nejnovější funkce.
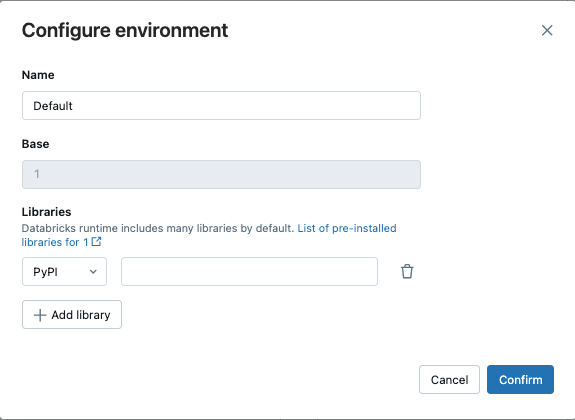
V dialogovém okně Konfigurovat prostředí klikněte na + Přidat knihovnu.
Vyberte typ závislosti z rozevírací nabídky pod Knihovny.
Do textového pole Cesta k souboru zadejte cestu ke knihovně.
- Pro Python Wheel v souboru pracovního prostoru by měla být cesta absolutní a začínat
/Workspace/. - Pro kolo Python ve svazku katalogu Unity by měla být cesta
/Volumes/<catalog>/<schema>/<volume>/<path>.whl. - U souboru
requirements.txtvyberte PyPi a zadejte-r /path/to/requirements.txt.
- Pro Python Wheel v souboru pracovního prostoru by měla být cesta absolutní a začínat
Klikněte na Potvrdit nebo + Přidat knihovnu, chcete-li přidat další knihovnu.
Pokud přidáváte úkol, klikněte na Vytvořit úkol. Pokud upravujete úkol, klikněte na Uložit úkol.
Základní prostředí pro pracovní úkoly
Bezserverové úlohy podporují vlastní základní prostředí definovaná soubory YAML pro Python, Python kolo a úlohy poznámkových bloků. U úloh v poznámkovém bloku můžete buď vybrat vlastní základní prostředí v konfiguraci prostředí úlohy, nebo použít nastavení prostředí samotného poznámkového bloku, která podporují jak pracovní prostředí, tak vlastní základní prostředí. Ve všech případech se za běhu nainstalují pouze závislosti požadované pro úlohu. Vlastní základní prostředí můžete vybrat přímo v nastavení prostředí úlohy. Pokud chcete vytvořit vlastní základní prostředí, přečtěte si téma Vytvoření vlastní specifikace prostředí.
Spravovaná základní prostředí v úkolech
Important
Tato funkce je v beta verzi. Správci pracovního prostoru můžou řídit přístup k této funkci ze stránky Previews . Viz Manage Azure Databricks preview.
Spravovaná základní prostředí můžete vybrat přímo v nastavení prostředí úlohy. To zahrnuje základní prostředí pracovního prostoru nakonfigurovaná správcem pracovního prostoru a základními prostředími poskytovanými Azure Databricks, například Standard a AI. Jedná se o stejná základní prostředí, která jsou k dispozici ve výběru prostředí poznámkového bloku. Informace o vytváření a správě základních prostředí pracovního prostoru najdete v tématu Správa základních prostředí pracovního prostoru.
Spravovaná základní prostředí jsou podporovaná pro úlohy poznámkového bloku, Python skriptu a Python kolečka. Nejsou podporovány pro úlohy JAR.
Kompatibilita prostředí a výpočetních prostředků
Vybrané základní prostředí musí být kompatibilní s typem výpočetních prostředků úlohy. Například prostředí vytvořené pro výpočetní výkon GPU není kompatibilní s výpočetními prostředky procesoru. V uživatelském rozhraní úloh jsou nekompatibilní prostředí v rozevíracím seznamu základního prostředí neaktivní.
Při konfiguraci úlohy v poznámkovém bloku může typ výpočetních prostředků (CPU nebo GPU) a základní prostředí pocházet buď z nastavení úlohy, nebo z nastavení poznámkového bloku.
- Pokud nastavíte hardwarový akcelerátor (GPU) na úrovni úlohy, musíte také vybrat základní prostředí na úrovni úlohy. Nelze použít prostředí notebooku s akcelerátorem na úrovni úlohy.
- Pokud po vytvoření úlohy, která na ni odkazuje, změníte typ výpočetního objektu poznámkového bloku (například z procesoru na GPU), můžou být stávající úkoly nekompatibilní s nakonfigurovaným prostředím. Po změně konfigurace výpočtů poznámkového bloku zkontrolujte nastavení prostředí úlohy.
- Pro uživatele rozhraní API platí, že pokud je základní prostředí nastaveno na úrovni úlohy, ale typ výpočetních prostředků je zděděný z poznámkového bloku, je kompatibilita ověřena za běhu místo při vytváření úlohy. Pokud je konfigurace nekompatibilní, spuštění selže s chybou.