Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Vývoj schématu označuje schopnost systému přizpůsobit se změnám struktury dat v průběhu času. Tyto změny jsou běžné při práci s částečně strukturovanými daty, datovými proudy událostí nebo zdroji třetích stran, kde se přidávají nová pole, posun datových typů nebo vnořené struktury se vyvíjejí.
Mezi běžné změny patří:
- Nové sloupce: Další datová pole, která nebyla dříve definována, někdy s vlastní hodnotou pro vyplnění.
-
Přejmenování sloupce: Změna názvu sloupce, například z
namenafull_name. - Vyřazené sloupce: Odebrání sloupců ze schématu tabulky
-
Rozšíření typu: Změna typu sloupce na širší typ Například pole
INTse stáváDOUBLE. -
Jiné změny typu: Změna typu sloupce Například pole
INTse stáváSTRING.
Podpora vývoje schématu je důležitá pro vytváření odolných dlouhotrvajících kanálů, které mohou pojmout měnící se data bez častých ručních aktualizací.
Components
Vývoj schématu Azure Databricks zahrnuje čtyři hlavní kategorie komponent, přičemž každá zpracovává změny schématu nezávisle:
- Konektory: Komponenty, které ingestují data z externích zdrojů. Patří mezi ně konektory Auto Loader, Kafka, Kinesis a Lakeflow.
-
Analyzátory formátu: Funkce, které dekódují nezpracované formáty, včetně
from_json,from_avro,from_xmlafrom_protobuf. - Stroje: Zpracovávací stroje, které spouštějí dotazy, včetně strukturovaného streamování.
- Datové sady: Streamované tabulky, materializovaná zobrazení, tabulky Delta a zobrazení, která uchovávají a obsluhuje data.
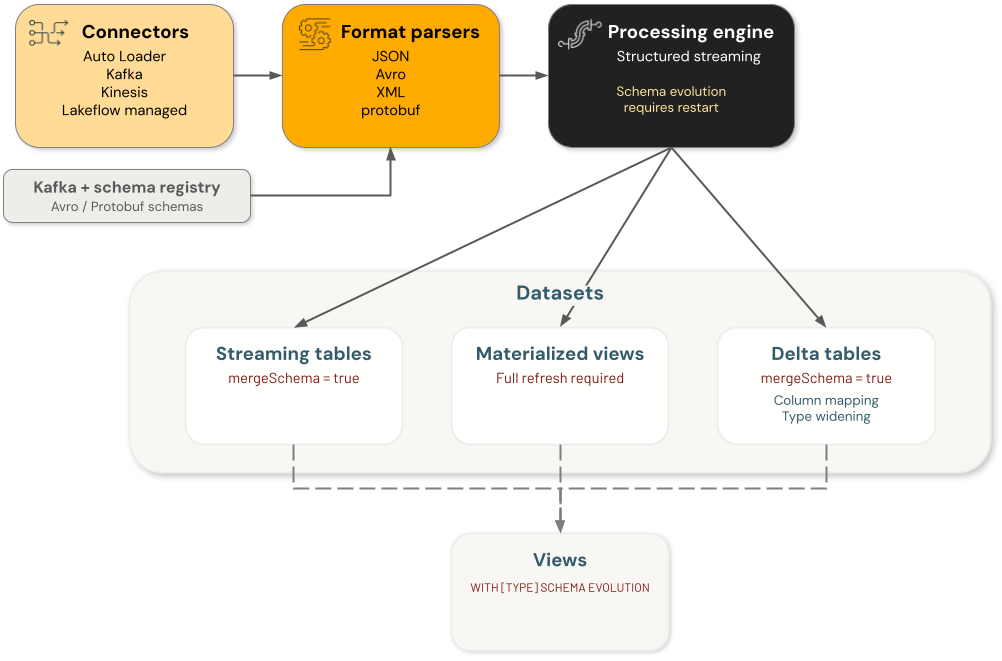
Každá komponenta vývoje schématu architektury přípravy dat je nezávislá. Zodpovídáte za konfiguraci vývoje schématu v jednotlivých komponentách, abyste dosáhli požadovaného chování v toku zpracování dat.
Například při použití Auto Loaderu ke vkládání dat do tabulky Delta existují dvě trvalá schémata – jedno je spravováno Auto Loaderem ve svém umístění schématu a druhé je schéma cílové tabulky Delta. Ve stabilním stavu jsou tyto dva stejné. Když auto loader vyvíjí své schéma na základě příchozích dat, musí tabulka Delta také vyvíjet své schéma nebo dotaz selže. V takovém případě můžete (a) aktualizovat cílové schéma tabulky Delta povolením vývoje schématu nebo použitím přímého příkazu DDL nebo (b) provést úplné přepsání cílové tabulky Delta.
Podpora vývoje schématu konektorem
Následující části podrobně popisuje, jak jednotlivé komponenty Azure Databricks zpracovávají různé typy změn schématu.
Automatický nakladač
Auto Loader podporuje změny sloupců a rozšíření datového typu. Konfigurace automatického vývoje schématu pomocí cloudFiles.schemaEvolutionMode a rescuedDataColumn. Můžete ručně nastavit schemaHints nebo neměnný schema. Při automatické evoluci schématu proud zpočátku selže. Při restartování se použije vyvíjené schéma. Podívejte se jak funguje změna schématu automatického zavaděče.
-
Nové sloupce: Podporováno v závislosti na vybraném sloupci
schemaEvolutionMode. Selhání s ručním restartováním vyžadovaným pro přidání nových sloupců do schématu -
Přejmenování sloupců: Podporováno v závislosti na vybraném
schemaEvolutionMode. Přejmenovaný sloupec se považuje za nový přidaný sloupec, zatímco starý sloupec se naplníNULL, pokud jde o nové řádky. Selhání, které vyžaduje ruční restartování pro aktualizaci schématu. -
Odebrané sloupce: Podporováno. Považuje se za soft delete, kdy jsou nové řádky pro odstraněný sloupec nastaveny na
NULL. -
Rozšíření typu: Podporováno v Databricks Runtime 16.4 a vyšší, kde je
schemaEvolutionModenastaveno naaddNewColumnsWithTypeWidening. Podporované změny datového typu jsou automaticky rozšířeny. Změny nepodporovaného typu jsou zaznamenány v souborurescuedDataColumn. Viz Automatické rozšíření typů pomocí Auto Loaderu. -
Jiné změny typu: Nepodporuje se. Změny typu jsou zaznamenány v
rescuedDataColumn, pokud jerescueDataColumnnastaveno aschemaEvolutionModenastaveno narescue. V opačném případě vyžaduje ruční změnu schématu.
Spojnice Delta
Konektor Delta může podporovat vývoj schématu. Pokud čtete z tabulky Delta s povoleným mapováním sloupců a schemaTrackingLocation, podporuje se vývoj schématu pro přejmenování a vyřazení sloupců. Je nutné nastavit správnou konfiguraci Sparku pro každou z těchto příslušných změn, aby se schéma vyvinulo bez zastavení datového proudu. V opačném případě stream vyvíjí své sledované schéma pokaždé, když se zjistí změna, a pak se zastaví. Potom je nutné ručně restartovat streamovací dotaz, aby se obnovilo zpracování.
-
Nové sloupce: Podporováno. Když je
mergeSchematato možnost povolená, přidají se nové sloupce automaticky. V opačném případě dotaz selže a je nutné restartovat datový proud, aby se do schématu přidaly nové sloupce, ale tabulka Delta nevyžaduje přepsání. -
Přejmenování sloupců: Podporováno. Při
mergeSchemapovoleném přejmenování se zpracovává automaticky. V opačném případě můžete vyvíjet schéma v rámci streamovacího dotazu s konfiguracíspark.databricks.delta.streaming.allowSourceColumnRenameSparku . -
Odebrané sloupce: Podporováno. Pokud je
mergeSchemapovoleno, zpracování zahozovaných sloupců je automatické. V opačném případě můžete vyvíjet schéma v rámci streamovacího dotazu s konfiguracíspark.databricks.delta.streaming.allowSourceColumnDropSparku . -
Rozšíření typu: Podporováno v Databricks Runtime 16.4 LTS a všech novějších verzích. S povolenou funkcí
mergeSchemaa rozšířením typu v cílové tabulce se změny typu zpracovávají automaticky. Můžete povolit rozšíření typu pomocítype wideningvlastnosti tabulky. - Jiné změny typu: Nepodporuje se.
Konektory SaaS a CDC
Konektory SaaS a CDC automaticky upravují schéma při změně sloupců. To se zpracovává prostřednictvím automatického restartování při zjištění změny. Změny typu vyžadují úplnou aktualizaci.
- Nové sloupce: Podporováno. Dotaz se automaticky restartuje, aby se vyřešila neshoda schématu.
- Přejmenování sloupců: Podporováno. Dotaz se automaticky restartuje, aby se vyřešila neshoda schématu. Přejmenovaný sloupec se považuje za přidaný nový sloupec.
-
Odebrané sloupce: Podporováno. Vyřazené sloupce jsou považovány za obnovitelné odstranění, kde jsou nové řádky odstraněného sloupce nastaveny na
NULL. - Rozšíření typu: Není podporováno. Aktualizace schématu vyžaduje úplnou aktualizaci.
- Jiné změny typu: Nepodporuje se. Aktualizace schématu vyžaduje úplnou aktualizaci.
Kinesis, Kafka, Pub/Sub a Pulsar konektory
Nepodporuje se žádný vývoj nativního schématu. Každá z funkcí konektoru vrátí binární blob. Vývoj schématu se zpracovává analyzátorem formátu.
- Nové sloupce: Zpracovává se analyzátorem formátu.
- Přejmenování sloupce: Zpracovává se analyzátorem formátu.
- Odstraněné sloupce: Jsou zpracovávány analyzátorem formátu.
- Rozšíření typu: Zpracovává se analyzátorem formátu.
- Jiné změny typu: Zpracovává se analyzátorem formátu.
Podpora vývoje schématu analyzátorem formátu
from_json syntaktický analyzátor
Analyzátor from_json nepodporuje vývoj schématu. Schéma musíte aktualizovat ručně. Při použití from_json v deklarativních kanálech Sparku Lakeflow je možné povolit automatický vývoj schématu s schemaLocationKey a schemaEvolutionMode.
- Nové sloupce: Pokud je povolen automatický vývoj schématu, chová se jako Auto Loader.
- Přejmenování sloupců: Pokud je povolen automatický vývoj schématu, chová se jako Auto Loader.
- Vyřazené sloupce: Pokud je povolen automatický vývoj schématu, chová se jako Auto Loader.
- Rozšíření typu: Když je povolen automatický vývoj schématu, chová se jako Auto Loader.
- Jiné změny typu: Pokud je povolen automatický vývoj schématu, chová se jako Auto Loader.
from_avro a from_protobuf analyzátory
Analyzátory from_avro a from_protobuf se chovají stejně. Schéma lze načíst z registru schématu Confluent nebo uživatel může zadat schéma a musí schéma aktualizovat ručně. Koncepce vývoje schématu neexistuje v rámci funkce from_avro nebo from_protobuf; musí ji zpracovat prováděcí modul a registr schémat.
- Nové sloupce: Podporováno v registru schématu Confluent. Jinak musí uživatel aktualizovat schéma ručně.
- Přejmenování sloupců: Podporováno v registru schématu Confluent. Jinak musí uživatel aktualizovat schéma ručně.
- Odstraněné sloupce: Podporováno s registrem schémat Confluent. Jinak musí uživatel aktualizovat schéma ručně.
- Rozšíření typu: Podporováno v Confluent Schema Registry. Jinak musí uživatel aktualizovat schéma ručně.
- Jiné změny typu: Podporováno v registru schématu Confluent. Jinak musí uživatel aktualizovat schéma ručně.
from_csv a from_xml analyzátory
from_csv a from_xml parsery nepodporují evoluci schémat.
- Nové sloupce: Nepodporováno
- Přejmenování sloupců: Nepodporuje se
- Vyřazené sloupce: Nepodporováno
- Rozšíření typu: Není podporováno
- Jiné změny typu: Nepodporováno
Podpora vývoje schématu podle enginu
Strukturované streamování
Schéma streamovacího dotazu je uzamčeno během fáze plánování a všechny mikrodávky tento plán používají bez opětovného plánování. Pokud se zdrojové schéma změní uprostřed spuštění, dotaz selže a uživatel musí restartovat streamovací dotaz, aby Spark mohl znovu naplánovat nové schéma.
Datová sada, do které datový proud zapisuje, musí také podporovat vývoj schématu.
- Nové sloupce: Podporováno. Dotaz selže a pokud chcete vyřešit neshodu schématu, musíte datový proud restartovat.
- Přejmenování sloupců: Podporováno. Dotaz selže a pokud chcete vyřešit neshodu schématu, musíte datový proud restartovat.
- Odebrané sloupce: Podporováno. Dotaz selže a pokud chcete vyřešit neshodu schématu, musíte datový proud restartovat.
- Rozšíření typu: Podporováno. Dotaz selže a pokud chcete vyřešit neshodu schématu, musíte datový proud restartovat.
- Jiné změny typu: Podporováno. Dotaz selže a pokud chcete vyřešit neshodu schématu, musíte datový proud restartovat.
Vývoj schématu podle datové sady
Tabulky streamování
Streamované tabulky ve výchozím nastavení podporují evoluci slučovacího schématu. Aktualizace schématu nevyžaduje ruční restartování, ale libovolné změny schématu vyžadují úplnou aktualizaci.
- Nové sloupce: Podporováno. Dotaz se automaticky restartuje, aby se vyřešila neshoda schématu.
- Přejmenování sloupců: Podporováno. Dotaz se restartuje, aby se vyřešila neshoda schématu. Přejmenovaný sloupec se považuje za přidaný nový sloupec.
- Odebrané sloupce: Podporováno. Vyřazené sloupce se považují za obnovitelné odstranění, kde jsou nové řádky odstraněného sloupce nastaveny na hodnotu NULL.
- Rozšíření typu: Podporováno. Rozšíření typu musí být povoleno buď na úrovni kanálu, nebo přímo v tabulce. Viz rozšíření typu v Lakeflow Sparkových deklarativních potrubích.
- Jiné změny typu: Nepodporuje se. Aktualizace schématu vyžaduje úplnou aktualizaci.
Materializované pohledy
Jakákoli aktualizace schématu nebo definování dotazu aktivuje úplné překompiování materializovaného zobrazení.
- Nové sloupce: Aktivované úplné překomputování
- Přejmenování sloupce: Bylo spuštěno úplné přepočítání.
- Vyřazené sloupce: Probíhá úplné přepočítání.
- Rozšíření typu: Je aktivováno úplné překomputování.
- Jiné změny typu: Aktivovalo se úplné opětovné dokončování.
Tabulky Delta
Tabulky Delta podporují řadu konfigurací pro aktualizaci schématu tabulky, včetně přejmenování, vyřazení a rozšíření typu sloupců bez přepisování dat tabulky. Mezi podporované konfigurace patří evoluce schématu sloučení, mapování sloupců, rozšíření typu a přepsání schématu.
- Nové sloupce: Podporováno. Při vývoji schématu sloučení se automaticky vyvíjí, aniž by bylo nutné přepisovat tabulku Delta. Pokud vývoj schématu sloučení není povolený, aktualizace selžou.
-
Přejmenování sloupců: Podporováno. Lze přejmenovat pomocí ručních příkazů
ALTER TABLE DDLs povoleným mapováním sloupců. Nevyžaduje přepsání tabulky Delta. -
Odebrané sloupce: Podporováno. Sloupce můžete odstranit pomocí ručních
ALTER TABLE DDLpříkazů s povoleným mapováním sloupců. Nevyžaduje přepsání tabulky Delta. -
Rozšíření typu: Podporováno. Automaticky použije změnu typu při povolení rozšíření typu a vývoje schématu sloučení. Sloupce můžete rozšířit pomocí ručních
ALTER TABLE DDLpříkazů, pokud je povoleno rozšíření typu. Bez konfigurace obou možností operace selžou. Viz rozšíření typů s automatickým vývojem schématu. -
Jiné změny typu: Podporováno, ale vyžaduje úplné přepsání tabulky Delta. Musíte povolit
overwriteSchema, což umožňuje úplné přepsání tabulky Delta. Jinak operace selžou.
Views
Pokud má zobrazení column_list , které neodpovídá novému schématu, nebo má dotaz, který nelze analyzovat, zobrazení bude neplatné. Pokud tomu tak není, můžete povolit vývoj schématu pro změny typů pomocí SCHEMA TYPE EVOLUTION a pro změny typů, stejně jako pro nové, přejmenované a vyřazené sloupce pomocí SCHEMA EVOLUTION (což je nadmnožina vývoje schématu).
-
Nové sloupce: Podporováno. V
SCHEMA EVOLUTIONrežimu se zobrazení automaticky vyvíjí bez ručního zásahu, pokud neexistuje explicitnícolumn_list. V opačném případě může být zobrazení neplatné a uživatel se na něj nemůže dotazovat. -
Přejmenování sloupců: Podporováno. V
SCHEMA EVOLUTIONrežimu se zobrazení automaticky vyvíjí bez ručního zásahu, pokud neexistuje explicitnícolumn_list. V opačném případě může být zobrazení neplatné. -
Odebrané sloupce: Podporováno. V
SCHEMA EVOLUTIONrežimu se zobrazení automaticky vyvíjí bez ručního zásahu, pokud neexistuje explicitnícolumn_list. V opačném případě může být zobrazení neplatné. -
Rozšíření typu: Podporováno. V
SCHEMA TYPE EVOLUTIONrežimu se zobrazení automaticky vyvíjí pro všechny změny typu. VSCHEMA EVOLUTIONrežimu se zobrazení automaticky vyvíjí bez ručního zásahu, pokud neexistuje explicitnícolumn_list. V opačném případě může být zobrazení neplatné. -
Jiné změny typu: Podporováno. V
SCHEMA TYPE EVOLUTIONrežimu se zobrazení automaticky vyvíjí pro všechny změny typu. VSCHEMA EVOLUTIONrežimu se zobrazení automaticky vyvíjí bez ručního zásahu, pokud neexistuje explicitnícolumn_list. V opačném případě může být zobrazení neplatné.
Example
Následující příklad ukazuje, jak importovat téma v Kafce se zprávami kódovanými pomocí Avro, které jsou zaregistrované v Confluent Schema Registry, a zapisovat je do spravované tabulky Delta s povoleným vývojem schématu.
Klíčové body znázorněné:
- Integrace s konektorem Kafka
- Dekódujte záznamy Avro pomocí from_avro s registrem schémat Kafka.
- Zpracujte vývoj schématu nastavením
avroSchemaEvolutionMode. - Zápis do tabulky Delta s aktivovaným
mergeSchemapro umožnění sčítání změn
Kód předpokládá, že máte Kafka téma, které využívá Confluent schema registry a poskytuje data kódovaná ve formátu Avro.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)