Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tato stránka popisuje, jak číst data sdílená s vámi pomocí otevřeného protokolu sdílení Delta s nosnými tokeny. Obsahuje pokyny ke čtení sdílených dat pomocí následujících nástrojů:
- Databricks
- Apache Spark
- Pandas
- Power BI
- Tablo
- Klienti Icebergu
V tomto otevřeném modelu sdílení použijete soubor přihlašovacích údajů sdílený s členem vašeho týmu poskytovatelem dat, abyste získali zabezpečený přístup ke čtení sdílených dat. Přístup přetrvává, dokud jsou přihlašovací údaje platné a poskytovatel bude dál sdílet data. Zprostředkovatelé spravují vypršení platnosti a obměnu přihlašovacích údajů. Aktualizace dat jsou k dispozici téměř v reálném čase. Můžete číst a vytvářet kopie sdílených dat, ale nemůžete upravovat zdrojová data.
Poznámka:
Pokud s vámi někdo sdílí data pomocí sdílení Databricks-to-Databricks Delta, nepotřebujete pro přístup k datům soubor přihlašovacích údajů a tato stránka se na vás nevztahuje. Místo toho si přečtěte informace o čtení dat sdílených pomocí sdílení Databricks-to-Databricks Delta (pro příjemce).
Následující části popisují, jak používat klienty Azure Databricks, Apache Spark, pandas, Power BI a Iceberg pro přístup ke sdíleným datům a ke čtení sdílených dat pomocí souboru přihlašovacích údajů. Úplný seznam konektorů Delta Sharing a informace o tom, jak je používat, najdete v opensourcové dokumentaci Delta Sharing. Pokud narazíte na potíže s přístupem ke sdíleným datům, obraťte se na poskytovatele dat.
Než začnete
Člen vašeho týmu musí stáhnout soubor přihlašovacích údajů sdílený poskytovatelem dat. Viz Získání přístupu v otevřeném modelu sdílení.
Měli by použít zabezpečený kanál ke sdílení daného souboru nebo umístění souboru s vámi.
Azure Databricks: Čtení sdílených dat pomocí otevřených konektorů pro sdílení
Tato část popisuje, jak importovat zprostředkovatele a jak dotazovat sdílená data v Průzkumníku katalogu nebo v poznámkovém bloku Pythonu:
Pokud je pro katalog Unity povolený váš pracovní prostor Azure Databricks, použijte uživatelské rozhraní zprostředkovatele importu v Průzkumníku katalogu. Můžete provést následující kroky, aniž byste museli ukládat nebo zadávat soubor s přihlašovacími údaji:
- Pomocí kliknutí na tlačítko můžete vytvářet katalogy ze sdílených složek.
- Pomocí řízení přístupu k katalogu Unity udělte přístup ke sdíleným tabulkám.
- Dotazování sdílených dat pomocí standardní syntaxe katalogu Unity
Pokud váš pracovní prostor Azure Databricks není pro Katalog Unity povolený, jako příklad použijte pokyny k poznámkovému bloku Pythonu.
Průzkumník katalogu
požadovaná oprávnění: Správce metastore nebo uživatel, který má oprávnění CREATE PROVIDER i USE PROVIDER pro Unity Catalog metastore.
V pracovním prostoru Azure Databricks klikněte na
 Klikněte na Katalog pro otevření Průzkumníka katalogu.
Klikněte na Katalog pro otevření Průzkumníka katalogu.V horní části podokna Katalog klikněte na
 Vyberte možnost Delta Sharing.
Vyberte možnost Delta Sharing.Případně na stránce Rychlý přístup klikněte na tlačítko Delta Sharing>.
Na kartě Sdíleno se mnou klikněte na Importovat data.
Zadejte název zprostředkovatele.
Název nesmí obsahovat mezery.
Nahrajte soubor přihlašovacích údajů, který s vámi sdílel poskytovatel.
Řada poskytovatelů má své vlastní sítě Delta Sharing, ze kterých můžete přijímat podíly. Další informace naleznete v tématu Konfigurace specifické pro poskytovatele.
(Volitelné) Zadejte komentář.
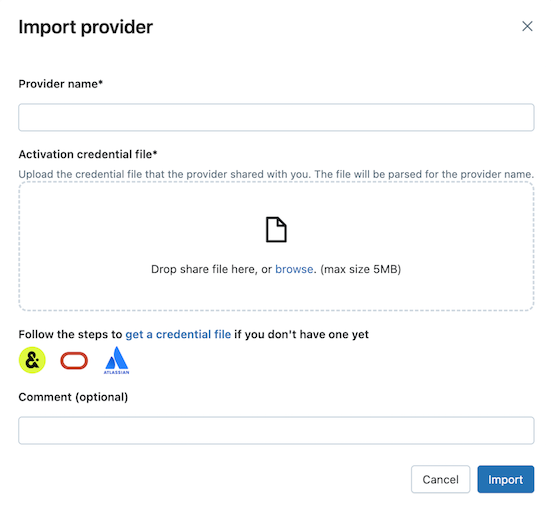
Klepněte na tlačítko Import.
Umožňuje vytvářet katalogy ze sdílených dat.
Na kartě Sdílené složky klikněte na Vytvořit katalog na řádku sdílené položky.
Informace o použití SQL nebo rozhraní příkazového řádku Databricks k vytvoření katalogu ze sdílené složky najdete v tématu Vytvoření katalogu ze sdílené složky.
Udělte přístup k katalogům.
Viz Jak zpřístupním sdílená data mému týmu? a Spravovat oprávnění pro schémata, tabulky a svazky v katalogu Delta Sharing.
Přečtěte si sdílené datové objekty stejně jako jakýkoli datový objekt zaregistrovaný v katalogu Unity.
Podrobnosti a příklady najdete v sekci Přístup k datům ve sdílené tabulce nebo svazku.
Python
Tato část popisuje, jak pomocí otevřeného konektoru pro sdílení přistupovat ke sdíleným datům pomocí poznámkového bloku v pracovním prostoru Azure Databricks. Vy nebo jiný člen vašeho týmu uložíte soubor přihlašovacích údajů v Azure Databricks a pak ho použijete k ověření v účtu Azure Databricks poskytovatele dat a přečtete si data, která s vámi sdílí poskytovatel dat.
Poznámka:
Tyto pokyny předpokládají, že pro katalog Unity není povolený váš pracovní prostor Azure Databricks. Pokud používáte katalog Unity, nemusíte při čtení ze sdílené složky odkazovat na soubor přihlašovacích údajů. Ze sdílených tabulek můžete číst stejně jako v libovolné tabulce zaregistrované v katalogu Unity. Databricks doporučuje místo pokynů uvedených zde použít uživatelské rozhraní zprostředkovatele importu v Průzkumníku katalogu.
Nejprve uložte soubor přihlašovacích údajů jako soubor pracovního prostoru Azure Databricks, aby uživatelé ve vašem týmu mohli přistupovat ke sdíleným datům.
Pokud chcete importovat soubor přihlašovacích údajů v pracovním prostoru Azure Databricks, přečtěte si téma Import souboru.
Dalším uživatelům udělte oprávnění pro přístup k souboru kliknutím na
 Vedle souboru a potom na Sdílet (Oprávnění). Zadejte identity Azure Databricks, které by měly mít k souboru přístup.
Vedle souboru a potom na Sdílet (Oprávnění). Zadejte identity Azure Databricks, které by měly mít k souboru přístup.Další informace o oprávněních k souborům najdete v tématu Seznamy ACL souborů.
Teď, když je soubor přihlašovacích údajů uložený, použijte poznámkový blok k výpisu a čtení sdílených tabulek.
V pracovním prostoru Azure Databricks klikněte na Nový > poznámkový blok.
Další informace o Azure Databricks noteboocích najdete v Databricks notebooks.
Pokud chcete používat Python nebo
pandaspro přístup ke sdíleným datům, nainstalujte Python konektor Delta-sharing. V editoru poznámkových bloků vložte následující příkaz:%sh pip install delta-sharingSpusťte buňku.
Knihovna
delta-sharingPythonu se nainstaluje do clusteru, pokud ještě není nainstalovaná.Pomocí Pythonu vypište tabulky ve sdílené složce.
Do nové buňky vložte následující příkaz. Cestu k pracovnímu prostoru nahraďte cestou k souboru přihlašovacích údajů.
Když se kód spustí, Python přečte soubor přihlašovacích údajů.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Spusťte buňku.
Výsledkem je pole tabulek spolu s metadaty pro každou tabulku. Následující výstup ukazuje dvě tabulky:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Pokud je výstup prázdný nebo neobsahuje očekávané tabulky, obraťte se na poskytovatele dat.
Dotaz na sdílenou tabulku
Použití Scaly:
Do nové buňky vložte následující příkaz. Po spuštění kódu se soubor přihlašovacích údajů načte ze souboru pracovního prostoru.
Proměnné nahraďte následujícím způsobem:
-
<profile-path>: cesta k pracovnímu prostoru souboru přihlašovacích údajů. Například/Workspace/Users/user.name@email.com/config.share. -
<share-name>: hodnotashare=pro tabulku. -
<schema-name>: hodnotaschema=pro tabulku. -
<table-name>: hodnotaname=pro tabulku.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Spusťte buňku. Při každém načtení sdílené tabulky se zobrazí nová data ze zdroje.
-
Pomocí SQL:
Pokud chcete dotazovat data pomocí SQL, vytvoříte v pracovním prostoru místní tabulku ze sdílené tabulky a pak se dotazujete na místní tabulku. Sdílená data nejsou uložena ani v mezipaměti v místní tabulce. Pokaždé, když se dotazujete na místní tabulku, uvidíte aktuální stav sdílených dat.
Do nové buňky vložte následující příkaz.
Proměnné nahraďte následujícím způsobem:
-
<local-table-name>: název místní tabulky. -
<profile-path>: umístění souboru přihlašovacích údajů. -
<share-name>: hodnotashare=pro tabulku. -
<schema-name>: hodnotaschema=pro tabulku. -
<table-name>: hodnotaname=pro tabulku.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Při spuštění příkazu se sdílená data dotazují přímo. Jako test se na tabulku dotazuje a vrátí se prvních 10 výsledků.
-
Pokud je výstup prázdný nebo neobsahuje očekávaná data, obraťte se na poskytovatele dat.
Apache Spark: Čtení sdílených dat
Pokud chcete získat přístup ke sdíleným datům pomocí Sparku 3.x nebo novějšího, postupujte takto.
Tyto pokyny předpokládají, že máte přístup k souboru přihlašovacích údajů, který sdílel poskytovatel dat. Viz Získání přístupu v otevřeném modelu sdílení.
Důležité
Zajistěte, aby byl soubor přihlašovacích údajů přístupný apache Sparkem pomocí absolutní cesty. Cesta může odkazovat na cloudový objekt nebo svazek katalogu Unity.
Poznámka:
Pokud používáte Spark v pracovním prostoru Azure Databricks, který je povolený pro Katalog Unity, a použili jste uživatelské rozhraní zprostředkovatele importu k importu poskytovatele a sdílení, pokyny v této části se na vás nevztahují. Ke sdíleným tabulkám můžete přistupovat stejně jako k jakékoli jiné tabulce, která je zaregistrovaná v katalogu Unity. Není nutné instalovat konektor delta-sharing Python nebo zadat cestu k souboru přihlašovacích údajů. Viz Azure Databricks: Čtení sdílených dat pomocí otevřených konektorů pro sdílení.
Instalace konektorů pro Delta Sharing v Pythonu a Sparku
Pokud chcete získat přístup k metadatům souvisejícím se sdílenými daty, jako je seznam tabulek, které s vámi někdo sdílí, postupujte takto. V tomto příkladu se používá Python.
Nainstalujte Python konektor pro delta-sharing. Informace o omezeních konektorů Pythonu najdete v tématu Omezení konektoru Pythonu pro sdílení Delta.
pip install delta-sharingNainstalujte konektor Apache Spark.
Výpis sdílených tabulek pomocí Sparku
Zobrazí seznam tabulek ve sdílené složce. V následujícím příkladu nahraďte <profile-path> umístěním souboru přihlašovacích údajů.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Výsledkem je pole tabulek spolu s metadaty pro každou tabulku. Následující výstup ukazuje dvě tabulky:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Pokud je výstup prázdný nebo neobsahuje očekávané tabulky, obraťte se na poskytovatele dat.
Přístup ke sdíleným datům pomocí Sparku
Spusťte následující příkaz a nahraďte tyto proměnné:
-
<profile-path>: umístění souboru přihlašovacích údajů. -
<share-name>: hodnotashare=pro tabulku. -
<schema-name>: hodnotaschema=pro tabulku. -
<table-name>: hodnotaname=pro tabulku. -
<version-as-of>:volitelný. Verze tabulky, která se použije pro načtení dat. Funguje pouze v případě, že poskytovatel dat sdílí historii tabulky. Vyžadujedelta-sharing-sparkverzi 0.5.0 nebo vyšší. -
<timestamp-as-of>:volitelný. Načtěte data ve verzi, která je před nebo k danému časovému razítku. Funguje pouze v případě, že poskytovatel dat sdílí historii tabulky. Vyžadujedelta-sharing-sparkverzi 0.6.0 nebo vyšší.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Přístup ke sdílenému datovému kanálu změn pomocí Sparku
Pokud s vámi byla sdílena historie tabulek a datový kanál změn (CDF) je povolen na zdrojové tabulce, přistupte k datovému kanálu změn spuštěním následujícího příkazu a nahraďte tyto proměnné. Vyžaduje delta-sharing-spark verzi 0.5.0 nebo vyšší.
Je nutné zadat jeden počáteční parametr.
-
<profile-path>: umístění souboru přihlašovacích údajů. -
<share-name>: hodnotashare=pro tabulku. -
<schema-name>: hodnotaschema=pro tabulku. -
<table-name>: hodnotaname=pro tabulku. -
<starting-version>:volitelný. Počáteční verze dotazu včetně. Určete jako Long. -
<ending-version>:volitelný. Koncová verze dotazu včetně. Pokud koncová verze není k dispozici, rozhraní API použije nejnovější verzi tabulky. -
<starting-timestamp>:volitelný. Počáteční časové razítko dotazu se převede na verzi vytvořenou větší nebo rovnou tomuto časovému razítku. Zadejte jako řetězec ve formátuyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>:volitelný. Koncové časové razítko dotazu je převedeno na verzi vytvořenou dříve nebo rovnající se tomuto časovému razítku. Uveďte jako řetězec ve formátuyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Pokud je výstup prázdný nebo neobsahuje očekávaná data, obraťte se na poskytovatele dat.
Přístup ke sdílené tabulce pomocí strukturovaného streamování Sparku
Pokud se s vámi sdílí historie tabulek, můžete streamovat čtení sdílených dat. Vyžaduje delta-sharing-spark verzi 0.6.0 nebo vyšší.
Podporované možnosti:
-
ignoreDeletes: Ignorujte transakce, které odstraňují data. -
ignoreChanges: Znovu zpracujte aktualizace, pokud byly soubory přepsány ve zdrojové tabulce z důvodu operace změny dat, jako jeUPDATE,MERGE INTO,DELETE(v rámci oddílů) neboOVERWRITE. Nezměněné řádky je možné přesto emitovat. Proto by podřízení příjemci měli být schopni zpracovat duplicity. Odstranění se nepřenáší dále do systému.ignoreChangeszahrnujeignoreDeletes. Proto pokud použijeteignoreChanges, stream se nenaruší odstraněním nebo aktualizacemi zdrojové tabulky. -
startingVersion: Verze sdílené tabulky, od které se má začít. Všechny změny tabulky od této verze (včetně) jsou čteny streamovacím zdrojem. -
startingTimestamp: Časové razítko, od které se má začít. Všechny změny tabulky potvrzené v daném časovém razítku nebo po něm (včetně) jsou čteny zdrojem streamování. Příklad:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Počet nových souborů, které je třeba zvážit v každé mikrosadě. -
maxBytesPerTrigger: Množství dat, která se zpracovávají v každé mikrodávce. Tato možnost nastaví "soft max", což znamená, že dávkové procesy zpracovávají přibližně toto množství dat a mohou zpracovávat více než je tento limit, aby streamovací dotaz pokračoval v případech, kdy je nejmenší vstupní jednotka větší než tento limit. -
readChangeFeed: Stream čte datový kanál změn sdílené tabulky.
Nepodporované možnosti:
Trigger.availableNow
Ukázkové dotazy strukturovaného streamování
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Viz také koncepty strukturovaného streamování.
Čtení tabulek s povolenými vektory mazání nebo mapováním sloupců
Důležité
Tato funkce je ve verzi Public Preview.
Vektory odstranění jsou funkce optimalizace úložiště, kterou může váš poskytovatel povolit u sdílených tabulek Delta. Podívejte se na vektory odstranění v Databricks.
Azure Databricks podporuje také mapování sloupců pro tabulky Delta. Viz Přejmenování a vyřazení sloupců s mapováním sloupců v Delta Lake.
Pokud váš poskytovatel nasdílel tabulku s povolenými vektory odstranění nebo mapováním sloupců, můžete si tabulku přečíst pomocí výpočetních prostředků, na kterých běží delta-sharing-spark verze 3.1 nebo vyšší. Pokud používáte clustery Databricks, můžete provádět dávkové čtení pomocí clusteru se spuštěným modulem Databricks Runtime 14.1 nebo novějším. Dotazy CDF a streamování vyžadují Databricks Runtime 14.2 nebo vyšší.
Dávkové dotazy můžete provádět bez změn, protože se dají automaticky vyřešit responseFormat na základě vlastností sdílené tabulky.
Pokud chcete číst datový kanál změn (CDF) nebo provádět streamované dotazy na sdílené tabulky s povolenými vektory odstranění nebo mapováním sloupců, musíte nastavit další možnost responseFormat=delta.
Následující příklady ukazují dávkové, CDF a streamovací dotazy:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas: Čtení sdílených dat
Pokud chcete získat přístup ke sdíleným datům ve pandas verzi 0.25.3 nebo novější, postupujte takto.
Tyto pokyny předpokládají, že máte přístup k souboru přihlašovacích údajů, který sdílel poskytovatel dat. Viz Získání přístupu v otevřeném modelu sdílení.
Poznámka:
Pokud používáte pandas pracovní prostor Azure Databricks, který je povolený pro katalog Unity, a použili jste uživatelské rozhraní zprostředkovatele importu k importu poskytovatele a sdílení, pokyny v této části se na vás nevztahují. Ke sdíleným tabulkám můžete přistupovat stejně jako k jakékoli jiné tabulce, která je zaregistrovaná v katalogu Unity. Není nutné instalovat konektor delta-sharing Python nebo zadat cestu k souboru přihlašovacích údajů. Viz Azure Databricks: Čtení sdílených dat pomocí otevřených konektorů pro sdílení.
Instalace konektoru Delta Sharing Python
Pokud chcete získat přístup k metadatům souvisejícím se sdílenými daty, jako je seznam tabulek sdílených s vámi, musíte nainstalovat Python konektor pro delta-sharing. Informace o omezeních konektorů Pythonu najdete v tématu Omezení konektoru Pythonu pro sdílení Delta.
pip install delta-sharing
Výpis sdílených tabulek pomocí pandas
Pokud chcete zobrazit seznam tabulek ve sdílené složce, spusťte následující příkaz a nahraďte <profile-path>/config.share umístěním souboru přihlašovacích údajů.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Pokud je výstup prázdný nebo neobsahuje očekávané tabulky, obraťte se na poskytovatele dat.
Přístup ke sdíleným datům pomocí pandas
Pokud chcete přistupovat ke sdíleným datům v pandas Pythonu, spusťte následující příkaz a nahraďte proměnné následujícím způsobem:
-
<profile-path>: umístění souboru přihlašovacích údajů. -
<share-name>: hodnotashare=pro tabulku. -
<schema-name>: hodnotaschema=pro tabulku. -
<table-name>: hodnotaname=pro tabulku.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Přístup ke sdílenému datovému kanálu změn pomocí pandas
Pokud chcete získat přístup ke kanálu změn dat pro sdílenou tabulku v pandas Pythonu, spusťte následující příkaz a nahraďte proměnné následujícím způsobem. Datový kanál změn nemusí být k dispozici v závislosti na tom, jestli poskytovatel dat sdílel datový kanál změn pro tabulku nebo ne.
-
<starting-version>:volitelný. Počáteční verze dotazu včetně. -
<ending-version>:volitelný. Koncová verze dotazu včetně. -
<starting-timestamp>:volitelný. Počáteční časové razítko dotazu. Převádí se na verzi vytvořenou ve stejný nebo větší čas než toto časové razítko. -
<ending-timestamp>:volitelný. Koncový čas dotazu. Tato hodnota se převede na verzi vytvořenou dříve nebo rovna tomuto časovému razítku.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Pokud je výstup prázdný nebo neobsahuje očekávaná data, obraťte se na poskytovatele dat.
Power BI: Čtení sdílených dat
Konektor Rozdílového sdílení Power BI umožňuje zjišťovat, analyzovat a vizualizovat datové sady sdílené s vámi prostřednictvím otevřeného protokolu Delta Sharing.
Požadavky
- Power BI Desktop 2.99.621.0 nebo novější
- Přístup k souboru přihlašovacích údajů, který sdílel poskytovatel dat. Viz Získání přístupu v otevřeném modelu sdílení.
Připojení k Databricks
Pokud se chcete připojit k Azure Databricks pomocí konektoru Delta Sharing, postupujte takto:
- Otevřete sdílený soubor přihlašovacích údajů pomocí textového editoru, abyste získali adresu URL koncového bodu a token.
- Otevřete Power BI Desktop.
- Na nabídce Načíst data vyhledejte Delta Sharing.
- Vyberte konektor a klikněte na Připojit.
- Zadejte adresu URL koncového bodu, kterou jste zkopírovali ze souboru s přihlašovacími údaji, do pole adresa URL serveru Delta Sharing Server.
- Volitelně můžete na kartě Upřesnit možnosti nastavit limit řádků pro maximální počet řádků, které si můžete stáhnout. Ve výchozím nastavení je tato hodnota nastavená na 1 milion řádků.
- Klikněte na OK.
- V případě ověřování zkopírujte token, který jste získali ze souboru s přihlašovacími údaji, do nosné tokeny.
- Klepněte na tlačítko Připojit.
Omezení konektoru Power BI Delta Sharing
Konektor Delta Sharing v Power BI má následující omezení:
- Data, která konektor načte, se musí vejít do paměti vašeho počítače. Pokud chcete tento požadavek spravovat, omezí konektor počet importovaných řádků na limit řádků, který jste nastavili na kartě Upřesnit možnosti v Power BI Desktopu.
Tableau: Čtení sdílených dat
Konektor Tableau Delta Sharing umožňuje zjišťovat, analyzovat a vizualizovat datové sady, které s vámi někdo sdílí prostřednictvím otevřeného protokolu Delta Sharing.
Požadavky
- Tableau Desktop a Tableau Server 2024.1 nebo novější
- Přístup k souboru přihlašovacích údajů, který sdílel poskytovatel dat. Viz Získání přístupu v otevřeném modelu sdílení.
Připojení k Azure Databricks
Pokud se chcete připojit k Azure Databricks pomocí konektoru Delta Sharing, postupujte takto:
- Přejděte na Tableau Exchange, podle pokynů stáhněte konektor Delta Sharing Connector a vložte ho do příslušné složky plochy.
- Otevřete Tableau Desktop.
- Na stránce Konektory vyhledejte "Delta Sharing by Databricks".
- Vyberte Nahrát soubor sdílené složky a zvolte soubor přihlašovacích údajů, který sdílel poskytovatel.
- Klikněte na Získat data.
- V Průzkumníku dat vyberte tabulku.
- Volitelně můžete přidat filtry SQL nebo limity řádků.
- Klikněte na Získat data tabulky.
omezení
Konektor pro sdílení tabulky Tableau Delta má následující omezení:
- Data, která konektor načte, se musí vejít do paměti vašeho počítače. Pokud chcete tento požadavek spravovat, omezí konektor počet importovaných řádků na limit řádků, který jste nastavili v Tableau.
- Všechny sloupce jsou vráceny jako typ
String. - Filtr SQL funguje jenom pokud váš Delta Sharing server podporuje predicateHint.
- Vektory odstranění nejsou podporovány.
- Mapování sloupců není podporováno.
Klienti Iceberg: Čtení sdílených tabulek Delta
Důležité
Tato funkce je ve verzi Public Preview.
Pomocí externích klientů Icebergu, jako jsou Snowflake, Trino, Flink a Spark, můžete číst sdílené datové prostředky s přístupem bez kopírování prostřednictvím REST rozhraní API katalogu Apache Iceberg.
Pokud používáte Snowflake, můžete pomocí souboru přihlašovacích údajů vygenerovat příkaz SQL, který umožňuje číst sdílené tabulky Delta.
Získání přihlašovacích údajů pro připojení
Před přístupem ke sdíleným datovým prostředkům s externími klienty Icebergu shromážděte následující přihlašovací údaje:
- Koncový bod katalogu Iceberg REST
- Platný nosný token
- Název sdílené složky
- (Volitelné) Název jmenného prostoru nebo schématu
- (Volitelné) Název tabulky
Koncový bod REST a nosný token jsou v souboru přihlašovacích údajů poskytovaných vaším poskytovatelem dat. Název sdílené složky, obor názvů a název tabulky lze zjistit programově pomocí rozhraní Delta Sharing API.
Následující příklady ukazují, jak získat další přihlašovací údaje. V případě potřeby zadejte koncový bod, koncový bod Iceberg a nosný token ze souboru přihlašovacích údajů:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Poznámka:
Tato metoda vždy načte nejaktuálnější seznam prostředků. Vyžaduje ale přístup k internetu a může být obtížnější integrovat do prostředí bez kódu.
Konfigurace katalogu Iceberg
Po získání potřebných přihlašovacích údajů pro připojení nakonfigurujte klienta tak, aby k vytváření a dotazování tabulek používal koncové body katalogu Iceberg REST Catalog.
Pro každou sdílenou složku vytvořte integraci katalogu.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Volitelně můžete přidat
REFRESH_INTERVAL_SECONDS, aby byla metadata aktuální. Nastavte hodnotu na základě frekvence aktualizace katalogu.REFRESH_INTERVAL_SECONDS = 30Po nakonfigurování katalogu vytvořte z katalogu databázi. Tím se automaticky vytvoří všechna schémata a tabulky v tomto katalogu.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Pokud chcete ověřit, že sdílení proběhlo úspěšně, zadejte dotaz z tabulky v databázi. Měla by se zobrazit sdílená data z Azure Databricks.
Pokud je výsledek prázdný nebo dojde k chybě, postupujte podle těchto běžných kroků pro řešení potíží:
- Pečlivě zkontrolujte oprávnění, stav generování snímků a přihlašovací údaje REST.
- Obraťte se na svého poskytovatele dat.
- Prohlédněte si dokumentaci týkající se vašeho klienta Iceberg.
Příklad: Čtení sdílených tabulek Delta ve Snowflake pomocí příkazu SQL
Pokud chcete číst sdílené datové prostředky ve Snowflake, nahrajte soubor přihlašovacích údajů, který jste stáhli, a vygenerujte potřebný příkaz SQL:
Na odkazu pro aktivaci Delta Sharing klikněte na ikonu Snowflake.
Na stránce integrace Snowflake nahrajte soubor přihlašovacích údajů, který jste obdrželi od zprostředkovatele dat.
Po načtení přihlašovacích údajů zvolte sdílenou složku, ke které chcete mít přístup ve Snowflake.
Po výběru požadovaných položek klikněte na Generovat SQL.
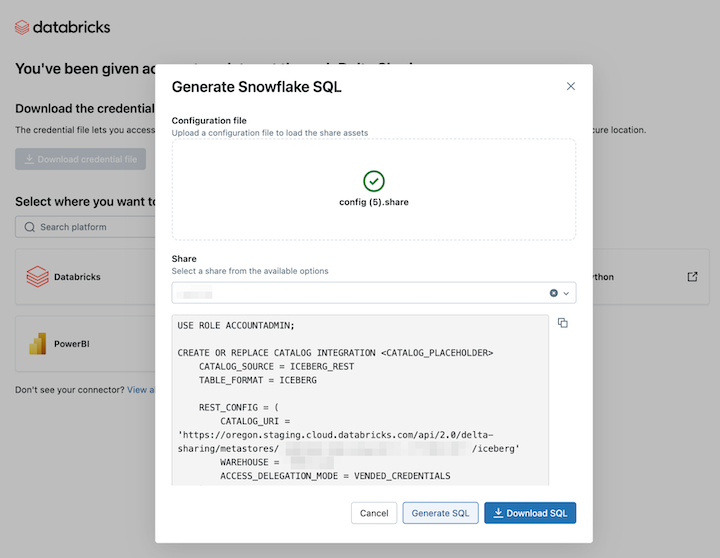
Zkopírujte a vložte vygenerovaný SQL do listu Snowflake. Nahraďte
CATALOG_PLACEHOLDERnázvem katalogu, který chcete použít, aDATABASE_PLACEHOLDERnázvem databáze, kterou chcete použít.
Omezení Snowflake
Připojení k katalogu Iceberg REST v Snowflake má následující omezení:
- Soubor metadat se automaticky neaktualizuje pomocí nejnovějšího snímku. Musíte spoléhat na automatické aktualizace nebo ruční aktualizace.
- R2 se nepodporuje.
- Platí všechna omezení klienta Icebergu .
Omezení klienta Icebergu
Při dotazování dat Delta Sharing z klientů Iceberg platí následující omezení:
- Při zobrazování tabulek v jmenném prostoru, pokud jmenný prostor obsahuje více než 100 sdílených zobrazení, je odpověď omezena na prvních 100 zobrazení.
Omezení konektoru Pythonu pro Delta Sharing
Tato omezení jsou specifická pro delta sdílení konetoru pro Python:
- Konektor Delta Sharing Python 1.1.0+ podporuje dotazy na snímky tabulek s mapováním sloupců, ale dotazy CDF na tabulky s mapováním sloupců se nepodporují.
- Konektor pro Delta Sharing v Pythonu selže u CDF dotazů s
use_delta_format=True, pokud se schéma změnilo během rozsahu dotazovaných verzí.
Žádost o nové přihlašovací údaje
Pokud dojde ke ztrátě, poškození, ohrožení vašich přihlašovacích údajů nebo pokud vyprší jejich platnost, aniž by vám poskytovatel zaslal nové, obraťte se na svého poskytovatele a požádejte o nové přihlašovací údaje.