Vytvoření a dotazování indexu vektorového vyhledávání
Tento článek popisuje, jak vytvořit a dotazovat index vektorového vyhledávání pomocí funkce Databricks Vector Search.
Pomocí uživatelského rozhraní, sady Python SDK nebo rozhraní REST API můžete vytvářet a spravovat komponenty vektorového vyhledávání, jako jsou koncové body vektorového vyhledávání a indexy vektorového vyhledávání.
Požadavky
- Pracovní prostor s povoleným katalogem Unity
- Bezserverové výpočetní prostředky jsou povolené.
- Zdrojová tabulka musí mít povolenou změnu datového kanálu.
- Pokud chcete vytvořit index, musíte mít oprávnění CREATE TABLE ke schématům katalogu, abyste mohli vytvářet indexy. Pokud chcete dotazovat index vlastněný jiným uživatelem, musíte mít další oprávnění. Viz Dotaz na koncový bod vektorového vyhledávání.
- Pokud chcete použít osobní přístupové tokeny (nedoporučuje se pro produkční úlohy), zkontrolujte, jestli jsou povolené osobní přístupové tokeny. Pokud chcete místo toho použít token instančního objektu, předejte ho explicitně pomocí sady SDK nebo volání rozhraní API.
Pokud chcete použít sadu SDK, musíte ji nainstalovat do poznámkového bloku. Použijte následující kód:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Vytvoření koncového bodu vektorového vyhledávání
Koncový bod vektorového vyhledávání můžete vytvořit pomocí uživatelského rozhraní Databricks, sady Python SDK nebo rozhraní API.
Vytvoření koncového bodu vektorového vyhledávání pomocí uživatelského rozhraní
Pomocí těchto kroků vytvořte koncový bod vektorového vyhledávání pomocí uživatelského rozhraní.
Na levém bočním panelu klikněte na Compute.
Klikněte na kartu Vektorové hledání a potom klikněte na Vytvořit.

Otevře se formulář Vytvořit koncový bod. Zadejte název tohoto koncového bodu.
Klikněte na tlačítko Potvrdit.
Vytvoření koncového bodu vektorového vyhledávání pomocí sady Python SDK
Následující příklad používá funkci sady create_endpoint() SDK k vytvoření koncového bodu vektorového vyhledávání.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Vytvoření koncového bodu vektorového vyhledávání pomocí rozhraní REST API
Viz POST /api/2.0/vector-search/endpoints.
(Volitelné) Vytvoření a konfigurace koncového bodu pro obsluhu modelu vkládání
Pokud se rozhodnete databricks vypočítat vkládání, musíte nastavit koncový bod obsluhující model, který bude sloužit modelu vkládání. Pokyny najdete v tématu Vytvoření základního modelu obsluhující koncové body . Například poznámkové bloky najdete v příkladech poznámkového bloku pro volání modelu vkládání.
Když konfigurujete koncový bod vkládání, Databricks doporučuje odebrat výchozí výběr škálování na nulu. Obsluha koncových bodů může trvat několik minut, než se zahřeje, a počáteční dotaz na index s horizontálním snížením kapacity koncového bodu může dojít k vypršení časového limitu.
Poznámka:
Inicializace indexu vektorového vyhledávání může vypršela, pokud koncový bod pro vložení není pro datovou sadu správně nakonfigurovaný. Koncové body procesoru byste měli používat jenom pro malé datové sady a testy. U větších datových sad použijte koncový bod GPU pro optimální výkon.
Vytvoření indexu vektorového vyhledávání
Index vektorového vyhledávání můžete vytvořit pomocí uživatelského rozhraní, sady Python SDK nebo rozhraní REST API. Uživatelské rozhraní je nejjednodušší přístup.
Existují dva typy indexů:
- Rozdílový synchronizační index se automaticky synchronizuje se zdrojovou tabulkou Delta a automaticky a přírůstkově aktualizuje index, protože se změní podkladová data v tabulce Delta.
- Index direct vector accessu podporuje přímé čtení a zápis vektorů a metadat. Uživatel zodpovídá za aktualizaci této tabulky pomocí rozhraní REST API nebo sady Python SDK. Tento typ indexu nelze vytvořit pomocí uživatelského rozhraní. Musíte použít rozhraní REST API nebo sadu SDK.
Vytvoření indexu pomocí uživatelského rozhraní
Na levém bočním panelu kliknutím na Katalog otevřete uživatelské rozhraní Průzkumníka katalogů.
Přejděte do tabulky Delta, kterou chcete použít.
Klikněte na tlačítko Vytvořit v pravém horním rohu a v rozevírací nabídce vyberte Index vektorového vyhledávání.
Ke konfiguraci indexu použijte selektory v dialogovém okně.
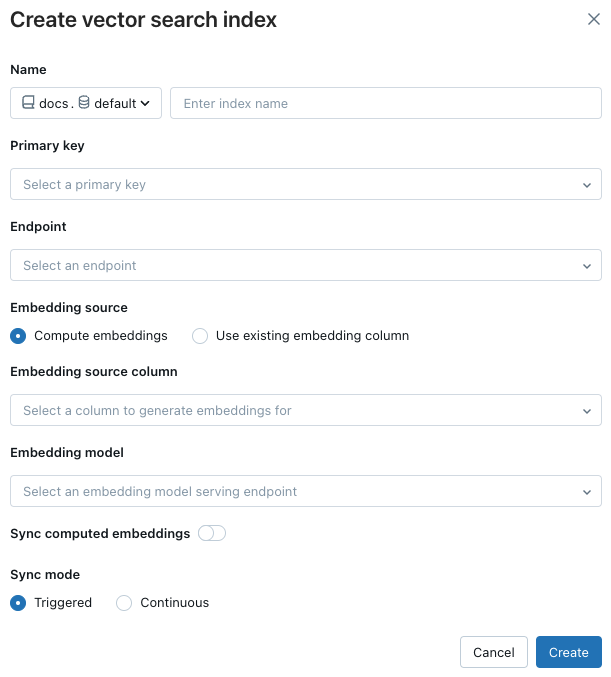
Název: Název, který se má použít pro online tabulku v katalogu Unity. Název vyžaduje tříúrovňový obor názvů .
<catalog>.<schema>.<name>Jsou povoleny pouze alfanumerické znaky a podtržítka.Primární klíč: Sloupec, který se má použít jako primární klíč.
Koncový bod: Vyberte model obsluhující koncový bod, který chcete použít.
Zdroj vkládání: Označuje, jestli chcete, aby Databricks počítal vkládání textového sloupce do tabulky Delta (vkládání výpočetních prostředků) nebo jestli tabulka Delta obsahuje předem vypočítané vkládání (použijte existující sloupec pro vložení).
- Pokud jste vybrali vkládání výpočetních prostředků, vyberte sloupec, pro který chcete vložit, a koncový bod, který obsluhuje model vkládání. Podporují se jenom textové sloupce.
- Pokud jste vybrali Možnost Použít existující sloupec pro vložení, vyberte sloupec, který obsahuje předem vypočítané vložené hodnoty a dimenzi vložení. Formát předpočítaného sloupce vkládání by měl být
array[float].
Synchronizovat počítaná vkládání: Přepněte toto nastavení a uložte vygenerované vkládání do tabulky katalogu Unity. Další informace najdete v tématu Uložení vygenerované vložené tabulky.
Režim synchronizace: Nepřetržitě udržuje index synchronizovaný s sekundami latence. Má ale vyšší náklady, protože je zřízený výpočetní cluster pro spuštění kanálu průběžné synchronizace streamování. Aktivované je nákladově efektivnější, ale musíte ho spustit ručně pomocí rozhraní API. Pro průběžné i aktivované aktualizace je přírůstková – pouze data, která se od poslední synchronizace změnila.
Po dokončení konfigurace indexu klikněte na Vytvořit.
Vytvoření indexu pomocí sady Python SDK
Následující příklad vytvoří rozdílový synchronizační index s vloženými funkcemi vypočítanými službou Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type='TRIGGERED',
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
Následující příklad vytvoří index direct vector accessu.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "str",
"field3": "float",
"text_vector": "array<float>"}
)
Vytvoření indexu pomocí rozhraní REST API
Viz POST /api/2.0/vector-search/indexes.
Uložení vygenerované vložené tabulky
Pokud Databricks vygeneruje vkládání, můžete vygenerované vkládání uložit do tabulky v katalogu Unity. Tato tabulka se vytvoří ve stejném schématu jako vektorový index a je propojena ze stránky indexu vektoru.
Název tabulky je název indexu vektorového vyhledávání, který je připojen ._writeback_table Název nelze upravit.
K tabulce můžete přistupovat a dotazovat se na ji stejně jako na jakoukoli jinou tabulku v katalogu Unity. Tabulku byste ale neměli odstraňovat ani upravovat, protože není určená k ruční aktualizaci. Pokud se index odstraní, tabulka se odstraní automaticky.
Aktualizace indexu vektorového vyhledávání
Aktualizace indexu rozdílové synchronizace
Indexy vytvořené pomocí režimu průběžné synchronizace se automaticky aktualizují, když se změní zdrojová tabulka Delta. Pokud používáte režim aktivované synchronizace, můžete synchronizaci spustit pomocí sady Python SDK nebo rozhraní REST API.
Python SDK
index.sync()
Rozhraní REST API
Viz rozhraní REST API (POST /api/2.0/vector-search/indexes/{index_name}/sync).
Aktualizace indexu přímého vektoru
Sadu Python SDK nebo rozhraní REST API můžete použít k vložení, aktualizaci nebo odstranění dat z indexu Direct Vector Access.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
Rozhraní REST API
Viz rozhraní REST API (POST /api/2.0/vector-search/indexes).
Dotazování koncového bodu vektorového vyhledávání
Koncový bod vektorového vyhledávání můžete dotazovat pouze pomocí sady Python SDK nebo rozhraní REST API.
Poznámka:
Pokud uživatel dotazující se na koncový bod není vlastníkem indexu vektorového vyhledávání, musí mít uživatel následující oprávnění UC:
- POUŽÍT KATALOG v katalogu, který obsahuje index vektorového vyhledávání.
- USE SCHEMA on the schema that contains the vector search index.
- SELECT v indexu vektorového vyhledávání.
Python SDK
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
results
Rozhraní REST API
Viz POST /api/2.0/vector-search/indexes/{index_name}/query.
Použití filtrů u dotazů
Dotaz může definovat filtry na základě libovolného sloupce v tabulce Delta. similarity_search vrátí pouze řádky, které odpovídají zadaným filtrům. Podporují se následující filtry:
| Operátor filtru | Chování | Příklady |
|---|---|---|
NOT |
Neguje filtr. Klíč musí končit textem NOT. Například "barva NE" s hodnotou "červená" odpovídá dokumentům, kde barva není červená. | {"id NOT": 2} {“color NOT”: “red”} |
< |
Zkontroluje, jestli je hodnota pole menší než hodnota filtru. Klíč musí končit " <. Například "price <" s hodnotou 100 odpovídá dokumentům, kde je cena menší než 100. | {"id <": 200} |
<= |
Zkontroluje, jestli je hodnota pole menší nebo rovna hodnotě filtru. Klíč musí končit znakem " <=". Například "price <=" s hodnotou 100 odpovídá dokumentům, kde je cena menší nebo rovna 100. | {"id <=": 200} |
> |
Zkontroluje, jestli je hodnota pole větší než hodnota filtru. Klíč musí končit " >. Například "price >" s hodnotou 100 odpovídá dokumentům, kde je cena větší než 100. | {"id >": 200} |
>= |
Zkontroluje, jestli je hodnota pole větší nebo rovna hodnotě filtru. Klíč musí končit znakem " >=". Například "price >=" s hodnotou 100 odpovídá dokumentům, kde je cena větší nebo rovna 100. | {"id >=": 200} |
OR |
Zkontroluje, jestli hodnota pole odpovídá některé z hodnot filtru. Klíč musí obsahovat OR k oddělení více podklíčů. color1 OR color2 Například s hodnotou ["red", "blue"] odpovídá dokumentům, kde je color1red nebo color2 je blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Odpovídá částečným řetězcům. | {"column LIKE": "hello"} |
| Nebyl zadán žádný operátor filtru. | Filtr hledá přesnou shodu. Pokud je zadáno více hodnot, odpovídá některé z těchto hodnot. | {"id": 200} {"id": [200, 300]} |
Podívejte se na následující příklady kódu:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]}
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]}
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"}
num_results=2
)
Rozhraní REST API
Viz POST /api/2.0/vector-search/indexes/{index_name}/query.
Ukázkové poznámkové bloky
Příklady v této části ukazují použití sady Python SDK pro vektorové vyhledávání.
Příklady jazyka LangChain
Podívejte se, jak používat LangChain s Databricks Vector Search pro použití Databricks Vector Search jako v integraci s balíčky LangChain.
Následující poznámkový blok ukazuje, jak převést výsledky hledání podobnosti na dokumenty LangChain.
Vektorové vyhledávání pomocí poznámkového bloku sady Python SDK
Příklady poznámkových bloků pro volání modelu vkládání
Následující poznámkové bloky ukazují, jak nakonfigurovat koncový bod Služby modelu Databricks pro generování vkládání.
Volání modelu vkládání OpenAI pomocí poznámkového bloku obsluhy modelu Databricks
Volání modelu vkládání BGE pomocí poznámkového bloku služby Databricks Model Obsluha
Registrace a obsluha poznámkového bloku modelu pro vložení operačního systému
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro