Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Potrubí mohou obsahovat mnoho datových sad s mnoha toky, aby je udržovaly aktuální. Pipelines automaticky spravují aktualizace a clustery, aby se efektivně aktualizovaly. Při správě velkého počtu toků ale dochází k určitým režijním nákladům a v některých případech to může vést k větší než očekávané inicializaci nebo dokonce režii správy během zpracování.
Pokud dochází ke zpožděním při čekání na inicializaci aktivovaných datových kanálů, například pokud inicializace trvá déle než pět minut, zvažte rozdělení zpracování do několika datových kanálů, i když datové sady používají stejná zdrojová data.
Poznámka:
Aktivované kanály provádějí kroky inicializace pokaždé, když se aktivují. Průběžné kanály provádějí kroky inicializace pouze při jejich zastavení a restartování. Tato část je nejvíce užitečná pro optimalizaci inicializace spuštěného procesu.
Kdy zvážit rozdělení kanálu
Existuje několik případů, kdy rozdělení kanálu může být výhodné z důvodů výkonu.
- Fáze
INITIALIZINGaSETTING_UP_TABLEStrvají déle, než byste si přáli, což ovlivňuje celkovou dobu řetězce. Pokud to trvá více než 5 minut, často se zlepší rozdělením zpracovatelského řetězce. - Ovladač, který spravuje cluster, se může stát kritickým bodem při spouštění mnoha (více než 30–40) streamovaných tabulek v rámci jednoho kanálu. Pokud ovladač nereaguje, doba trvání dotazů streamování se zvýší, což má vliv na celkovou dobu aktualizace.
- Aktivovaný kanál s několika toky tabulky streamování nemusí být schopen paralelně provádět všechny paralelizovatelné aktualizace datových proudů.
Podrobnosti o problémech s výkonem
Tato část popisuje některé problémy s výkonem, které mohou vzniknout z mnoha tabulek a toků v jednom kanálu.
Úzká místa ve fázích INICIALIZACE a NASTAVENÍ_TABULEK
Počáteční fáze spuštění můžou být kritickým bodem výkonu v závislosti na složitosti kanálu.
FÁZE INICIALIZACE
Během této fáze se vytvoří logické plány, včetně plánů pro vytvoření grafu závislostí a určení pořadí aktualizací tabulek.
fáze NASTAVENÍ_TABULEK
Během této fáze se na základě plánů vytvořených v předchozí fázi provádějí následující procesy:
- Ověřování a rozlišení schématu pro všechny tabulky definované v datovém toku.
- Sestavte graf závislostí a určíte pořadí provádění tabulek.
- Zkontrolujte, jestli je každá datová sada v kanálu aktivní nebo jestli je od předchozí aktualizace nová.
- Vytvořte streamované tabulky v první aktualizaci a pro materializovaná zobrazení vytvořte dočasná zobrazení nebo záložní tabulky potřebné při každé aktualizaci pipeline.
Proč inicializování a nastavování tabulek může trvat déle
Velké kanály s mnoha toky pro mnoho datových sad mohou trvat déle z několika důvodů:
- U kanálů s mnoha toky a složitými závislostmi mohou tyto fáze trvat delší dobu kvůli množství práce.
- Složité transformace, včetně
Auto CDCtransformací, můžou způsobit kritický bod výkonu kvůli operacím potřebným k materializaci tabulek na základě definovaných transformací. - Existuje také situace, kdy velký počet toků může způsobit zpomalení, i když tyto toky nejsou součástí aktualizace. Představte si například kanál, který má více než 700 toků, z nichž méně než 50 se aktualizuje pro každou aktivační událost na základě konfigurace. V tomto příkladu musí každé spuštění projít některé kroky pro všechny tabulky 700, získat datové rámce a pak vybrat ty, které chcete spustit.
Úzká místa v ovladači
Ovladač spravuje aktualizace během běhu. Musí pro každou tabulku spustit určitou logiku, aby se rozhodly, které instance v clusteru by měly zpracovávat jednotlivé toky. Při spouštění několika (více než 30 až 40) streamovaných tabulek v rámci jednoho kanálu se ovladač může stát kritickým bodem pro prostředky procesoru, protože zpracovává práci napříč clusterem.
Ovladač může mít také problémy s pamětí. K tomu může dojít častěji, když je počet paralelních toků 30 nebo více. Neexistuje konkrétní počet toků nebo datových sad, které můžou způsobit problémy s pamětí ovladače, ale závisí na složitosti úloh, které běží paralelně.
Toky streamování můžou běžet paralelně, ale to vyžaduje, aby ovladač používal paměť a procesor pro všechny streamy současně. V aktivovaném kanálu může ovladač zpracovávat podmnožinu datových proudů paralelně, aby se zabránilo omezením paměti a procesoru.
Ve všech těchto případech může rozdělení kanálů tak, aby v každém z nich byla optimální sada toků, urychlit inicializaci a dobu zpracování.
Kompromisy s rozdělením kanálů
Pokud jsou všechny vaše toky ve stejném potrubí, Lakeflow Spark deklarativní kanály spravují závislosti za vás. Pokud existuje více kanálů, musíte spravovat závislosti mezi kanály.
Závislosti Možná máte podřízený kanál, který závisí na několika nadřazených kanálech (místo jednoho). Pokud máte například tři kanály,
pipeline_A,pipeline_Bapipeline_C, apipeline_Czávisí na oboupipeline_Aapipeline_B, chcetepipeline_Caktualizovat pouze poté, co obapipeline_Aapipeline_Bdokončí své příslušné aktualizace. Jedním ze způsobů, jak tento problém řešit, je orchestraci závislostí provést tak, že každý pipeline bude úkolem v úloze, přičemž závislosti budou správně modelovány. Takžepipeline_Cse aktualizuje až po dokončení jakpipeline_A, takpipeline_B.Souběžnost V rámci kanálu můžete mít různé toky, které vyžadují velmi různé množství času na dokončení, například pokud
flow_Ase aktualizuje za 15 sekund, zatímcoflow_Btrvá několik minut. Před rozdělením kanálů může být užitečné podívat se na časy dotazů a seskupit kratší dotazy.
Plánování rozdělení kanálů
Před zahájením můžete vizualizovat rozdělení vaší pipeline. Tady je graf zdrojového kanálu, který zpracovává 25 tabulek. Jeden kořenový zdroj dat je rozdělený na 8 segmentů, z nichž každý má 2 zobrazení.
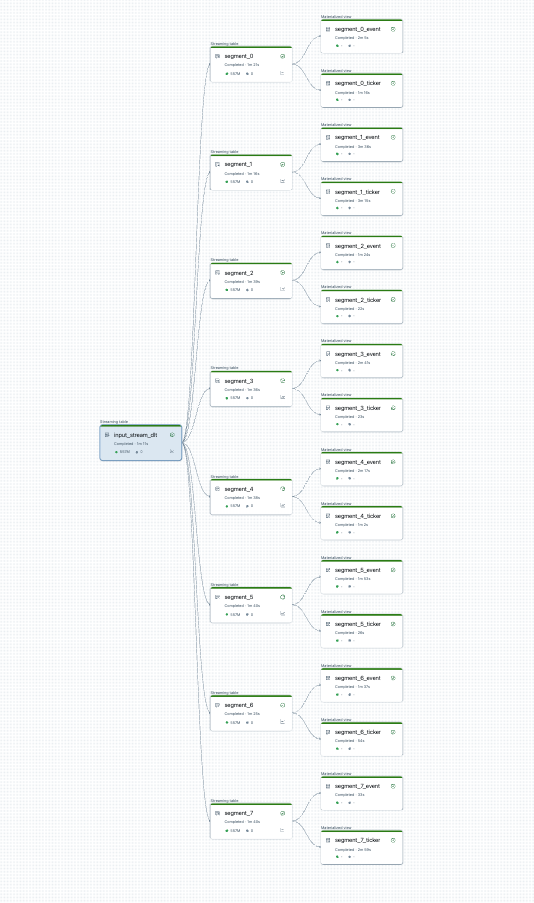
Po rozdělení kanálu existují dva kanály. Jeden zpracovává jeden kořenový zdroj dat a 4 segmenty a přidružená zobrazení. Druhé potrubí zpracovává 4 zbývající segmenty a jejich přidružená zobrazení. Druhý kanál spoléhá na první aktualizaci kořenového zdroje dat.
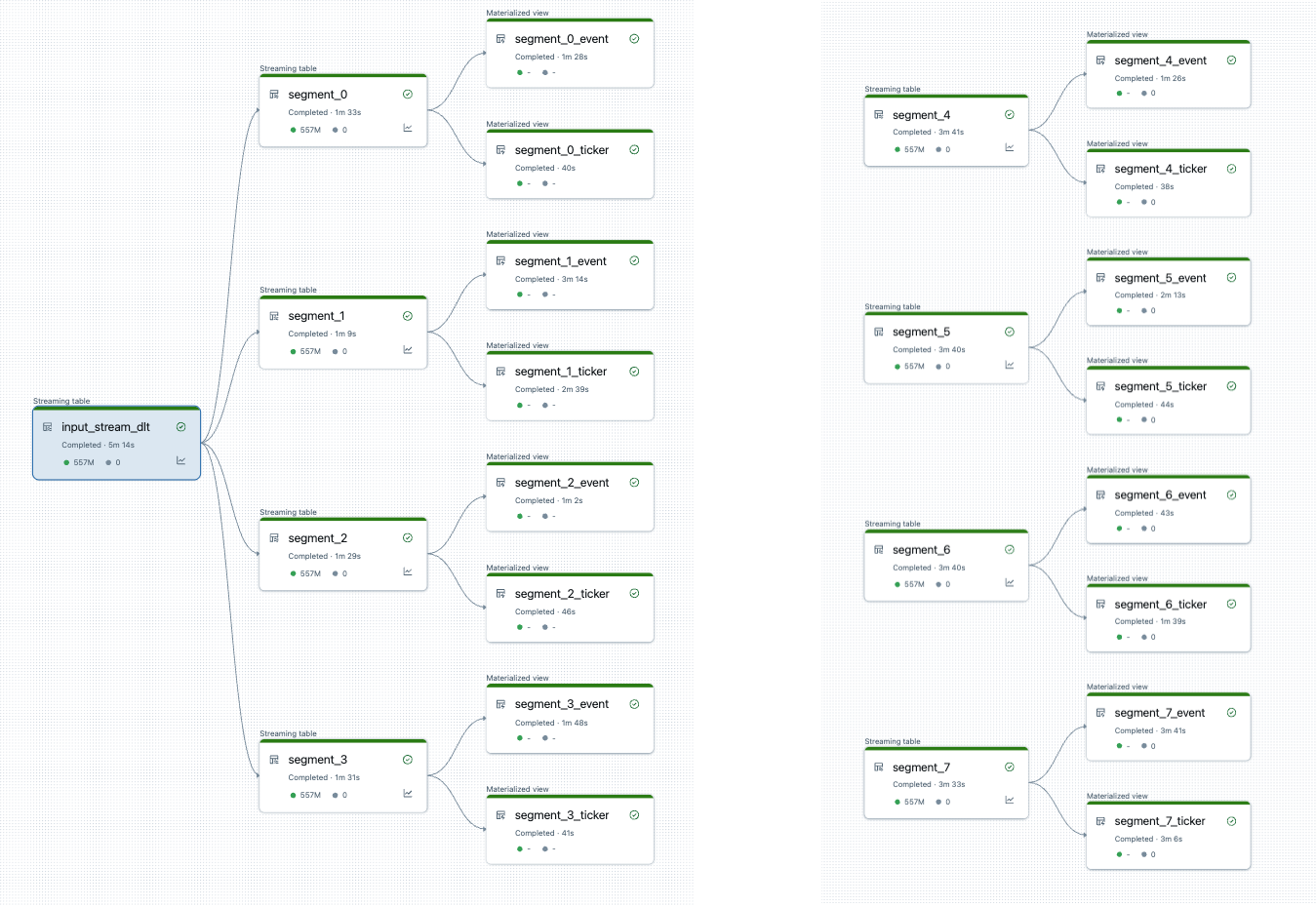
Rozdělení datového toku bez úplné aktualizace
Po naplánování rozdělení kanálu vytvořte všechny potřebné nové kanály a přesuňte tabulky mezi kanály za účelem vyrovnávání zatížení kanálu. Tabulky můžete přesouvat bez nutnosti úplné aktualizace.
Podrobnosti najdete v tématu Přesun tabulek mezi kanály.
Tento přístup má určitá omezení:
- Kanály musí být v katalogu Unity.
- Zdrojové a cílové kanály musí být ve stejném pracovním prostoru. Přesuny mezi pracovními prostory se nepodporují.
- Cílový kanál se musí vytvořit a spustit jednou (i když selže) před přesunem.
- Tabulku nelze přesunout z kanálu, který používá výchozí režim publikování, na tabulku, která používá starší režim publikování. Další informace najdete v LIVE schéma (starší verze).