Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V oblasti přípravy dat se backfilling týká procesu zpětného zpracování historických dat prostřednictvím datového kanálu určeného ke zpracování aktuálních nebo streamovaných dat.
Obvykle se jedná o samostatný tok odesílající data do existujících tabulek. Následující obrázek znázorňuje tok zpětného doplňování, který odesílá historická data do bronzových tabulek v datovém toku.
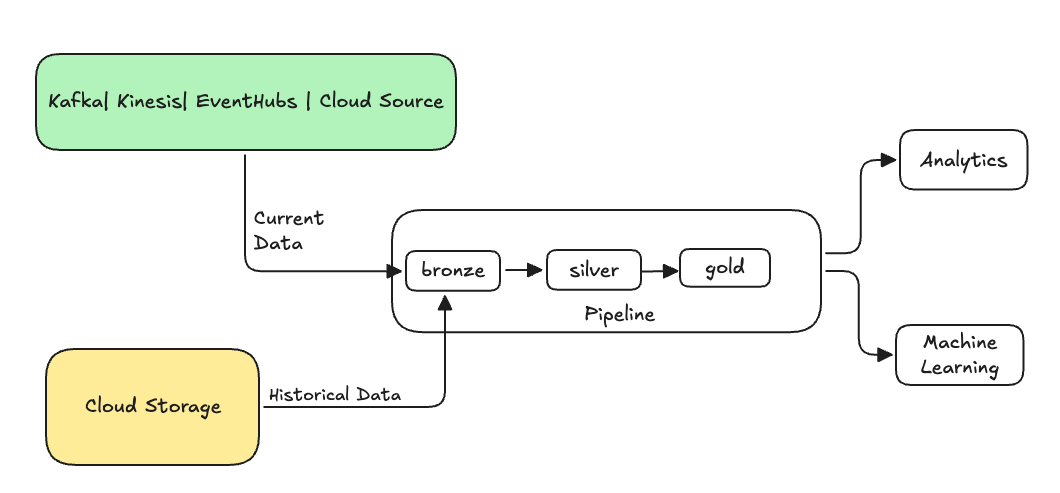
Některé scénáře, které mohou vyžadovat doplnění:
- Zpracování historických dat ze staršího systému za účelem trénování modelu strojového učení (ML) nebo vytvoření řídicího panelu analýzy historického trendu
- Znovu zpracuje podmnožinu dat kvůli problému s kvalitou dat u nadřazených zdrojů dat.
- Vaše obchodní požadavky se změnily a potřebujete znovu vyplňovat data za jiné časové období, které počáteční kanál nepokrýval.
- Vaše obchodní logika se změnila a potřebujete znovu zpracovat historická i aktuální data.
Backfill v deklarativních kanálech Sparku Lakeflow je podporovaný specializovaným doplňovacím tokem, který tuto ONCE možnost používá. Další informace o možnosti najdete v append_flow nebo v ONCE.
Úvahy při doplňování historických dat do streamované tabulky
- Obvykle připojte data k bronzové streamovací tabulce. Druhé vrstvy stříbra a zlata naberou nová data z bronzové vrstvy.
- Ujistěte se, že váš kanál dokáže řádně zpracovávat duplicitní data v případě, že se stejná data připojí vícekrát.
- Ujistěte se, že schéma historických dat je kompatibilní s aktuálním schématem dat.
- Zvažte velikost objemu dat a požadovanou dobu zpracování SLA a odpovídajícím způsobem nakonfigurujte velikost clusteru a dávek.
Příklad: Přidání backfillu do existujícího kanálu
V tomto příkladu řekněme, že máte kanál, který ingestuje nezpracovaná registrační data událostí ze zdroje cloudového úložiště od 1. ledna 2025. Později si uvědomíte, že chcete doplnit předchozí tři roky historických dat pro následné sestavy a analýzy v případě použití. Všechna data jsou v jednom umístění rozdělená podle roku, měsíce a dne ve formátu JSON.
Počáteční kanál
Tady je počáteční kód kanálu, který přírůstkově ingestuje nezpracovaná registrační data událostí z cloudového úložiště.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Použijeme možnost modifiedAfter Auto Loader, abychom zajistili, že nezpracováváme všechna data z cesty cloudového úložiště. Přírůstkové zpracování je na této hranici zastaveno.
Návod
Jiné zdroje dat, jako jsou Kafka, Kinesis a Azure Event Hubs, mají ekvivalentní možnosti čtečky pro dosažení stejného chování.
Vyplnění dat z předchozích 3 let
Teď chcete přidat jeden nebo více toků k obnovení předchozích dat. V tomto příkladu proveďte následující kroky:
- Použijte tok
append once. Tím se provede jednorázové obnovení, které nebude pokračovat po tomto prvním obnovení. Kód zůstane ve vašem potrubí, a pokud se potrubí někdy plně obnoví, znovu se spustí doplňování datových mezer. - Vytvořte tři doplňovací toky, jeden pro každý rok (v tomto případě jsou data v cestě členěna podle roku). V Pythonu parametrizujeme vytváření toků, ale v SQL kód opakujeme třikrát, jednou pro každý tok.
Pokud pracujete na vlastním projektu a nepoužíváte bezserverové výpočetní prostředky, možná budete chtít aktualizovat maximální počet pracovníků pro pipeline. Zvýšení maximálního počtu pracovníků zajišťuje, že máte k dispozici prostředky ke zpracování historických dat a zároveň pokračujete ve zpracování aktuálních streamovaných dat v rámci očekávané úrovně SLA.
Návod
Pokud používáte bezserverové výpočetní prostředky s vylepšeným automatickým škálováním (výchozí nastavení), cluster se při nárůstu zatížení automaticky zvětšuje.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Tato implementace zdůrazňuje několik důležitých vzorů.
Oddělení oblastí zájmu
- Přírůstkové zpracování je nezávislé na operacích doplnění dat.
- Každý tok má vlastní nastavení konfigurace a optimalizace.
- Mezi operacemi přírůstkového a doplňovacího existuje jasný rozdíl.
Řízené spouštění
-
ONCEPoužitím této možnosti zajistíte, že se každé doplnění dat spustí přesně jednou. - Tok backfillu zůstane v grafu kanálu, ale po dokončení se stane nečinný. Je připraven k použití při úplné aktualizaci automaticky.
- V definici kanálu je jasný záznam auditu operací backfillu.
Optimalizace zpracování
- Velký backfill můžete rozdělit na několik menších backfillů pro rychlejší zpracování nebo efektivnější kontrolu nad zpracováním.
- Použití vylepšeného automatického škálování dynamicky škáluje velikost clusteru na základě aktuálního zatížení clusteru.
Vývoj schématu
- Použití
schemaEvolutionMode="addNewColumns"elegantně zpracovává změny schématu. - Máte konzistentní odvozování schématu napříč historickými a aktuálními daty.
- V novějších datech je bezpečné zpracování nových sloupců.