Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Vytvoříte novou pipeline Lakeflow pro orchestraci dat pomocí Auto Loaderu a poté rozšíříte ukázkovou pipeline vyčištěním těchto dat a vytvořením dotazu k nalezení 100 nejlepších uživatelů.
V tomto kurzu se naučíte používat Editor kanálů Lakeflow k:
- Vytvořte nový kanál s výchozí strukturou složek a začněte sadou ukázkových souborů.
- Definujte omezení kvality dat pomocí očekávání.
- Pomocí funkcí editoru můžete kanál rozšířit o novou transformaci, která provede analýzu dat.
Požadavky
Než začnete s tímto kurzem, musíte:
- Přihlaste se k pracovnímu prostoru Azure Databricks.
- Povolte pro svůj pracovní prostor katalog Unity.
- Máte oprávnění k vytvoření výpočetního prostředku nebo přístupu k výpočetnímu prostředku.
- Máte oprávnění k vytvoření nového schématu v katalogu. Požadovaná oprávnění jsou
ALL PRIVILEGESneboUSE CATALOGaCREATE SCHEMA. - Úplnou sadu oprávnění potřebných k vytvoření, spuštění, aktualizaci a zobrazení kanálů a jejich výstupu najdete v tématu Správa identit, oprávnění a oprávnění pro kanály.
Krok 1: Vytvoření kanálu
V tomto kroku vytvoříte kanál s použitím výchozí struktury složek a ukázek kódu. Ukázky kódu odkazují na users tabulku ve zdroji wanderbricks ukázkových dat.
V pracovním prostoru Azure Databricks klikněte na
 Nový, potom
Nový, potom  ETL pipeline. Otevře se editor kanálu s výchozím názvem kanálu, například
ETL pipeline. Otevře se editor kanálu s výchozím názvem kanálu, například New Pipeline <date> <time>.(Volitelné) Vyberte název a zadejte popisný název kanálu.
(Volitelné) Napravo od názvu klikněte na katalog a schéma a nastavte jiné výchozí hodnoty.
(Volitelné) Ve zdrojovém souboru
my_transformationvytvořeném pro vás vyberte Python nebo SQL v rozevíracím seznamu jazyků a nastavte jazyk souboru.Klikněte na
 Použijte vzorový kód.
Použijte vzorový kód.Ukázkový kód ve vybraném jazyce se zobrazí ve zdrojovém
my_transformationtransformationssouboru ve složce. Výstupní datové sady ještě nebyly vytvořeny a graf kanálu na pravé straně obrazovky je prázdný.Pokud chcete spustit kód kanálu (kód ve
transformationssložce), klikněte na Spustit kanál v pravé horní části obrazovky.Po dokončení spuštění se v dolní části pracovního prostoru zobrazí dvě nové tabulky, které byly vytvořeny,
sample_users_<date_time>asample_aggregation_<date_time>. Graf kanálu na pravé straně pracovního prostoru nyní zobrazuje dvě tabulky, včetně toho, žesample_usersje zdrojem prosample_aggregation. Poznamenejte si úplnýsample_users_<date_time>název tabulky, na který odkazujete v dalším kroku.
Krok 2: Použití kontrol kvality dat
V tomto kroku přidáte do sample_users tabulky kontrolu kvality dat. K omezení dat použijete očekávání kanálu . V tomto případě odstraníte všechny záznamy uživatelů, které nemají platnou e-mailovou adresu, a vypíšete vyčištěnou tabulku jako users_cleaned.
V prohlížeči prostředků kanálu na levé straně klikněte na
a vyberte Transformovat.V dialogovém okně Vytvořit nový transformační soubor proveďte následující výběry:
- Zvolte Python nebo SQL pro Language. Nemusí se shodovat s předchozím výběrem.
- Pojmenujte soubor. V tomto případě zvolte
users_cleaned. - V části Cílová cesta ponechte výchozí hodnotu.
- U typu datové sady buď ponechte vybranou možnost Žádná , nebo zvolte Materializované zobrazení. Pokud vyberete materializované zobrazení, vygeneruje vám vzorový kód.
Kliknutím na Vytvořit vytvoříte soubor kódu transformace.
V novém souboru kódu upravte kód tak, aby odpovídal následujícímu kódu (na základě výběru na předchozí obrazovce použijte SQL nebo Python). Nahraďte
sample_users_<date_time>úplným názvemsample_userstabulky z předchozí části.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Kliknutím na Spustit kanál aktualizujte kanál. Teď by měla mít tři tabulky.
Krok 3: Analýza hlavních uživatelů
Dále získejte prvních 100 uživatelů podle počtu rezervací, které vytvořili. Spojte tabulku wanderbricks.bookings s materializovaným zobrazením users_cleaned.
V prohlížeči prostředků kanálu na levé straně klikněte na
a vyberte Transformovat.V dialogovém okně Vytvořit nový transformační soubor proveďte následující výběry:
- Zvolte Python nebo SQL pro Language. Není nutné, aby se shodoval s vašimi předchozími výběry.
- Pojmenujte soubor. V tomto případě zvolte
users_and_bookings. - V části Cílová cesta ponechte výchozí hodnotu.
- U typu datové sady ponechte vybranou možnost Žádné.
Kliknutím na Vytvořit vytvoříte soubor kódu transformace.
V novém souboru kódu upravte kód tak, aby odpovídal následujícímu kódu (na základě výběru na předchozí obrazovce použijte SQL nebo Python).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Kliknutím na Spustit kanál aktualizujte datové sady. Po dokončení spuštění uvidíte v Pipeline Graph čtyři tabulky, včetně nové
users_and_bookings.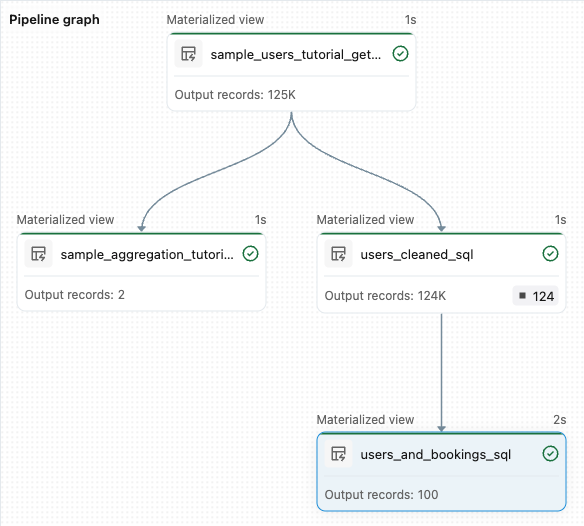
Další zdroje informací
Teď, když jste se dozvěděli, jak používat některé funkce editoru kanálů Lakeflow a vytvořit kanál, tady jsou některé další funkce, o kterých se dozvíte víc:
Nástroje pro práci s transformacemi a ladění při tvorbě pipeline:
- Selektivní spuštění
- Náhledy dat
- Interaktivní graf kanálu (graf datových sad v kanálu)
Integrovaná integrace deklarativních balíčků automatizace pro efektivní spolupráci, správu verzí a integraci CI/CD přímo z editoru: