Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Tato funkce je beta a je k dispozici v následujících oblastech: us-east-1 a us-west-2.
Deklarativní rozhraní API datového úložiště funkcí umožňují definovat a vypočítat časově ohraničené agregační funkce ze zdrojů dat. Tato příručka se zabývá následujícími pracovními postupy:
- Pracovní postup vývoje funkcí
- Slouží
create_featurek definování objektů funkcí katalogu Unity, které lze použít při trénování modelu a obsluhování pracovních postupů.
- Slouží
- Pracovní postup trénování modelu
- Pro výpočet agregovaných atributů k určitému bodu v čase pro strojové učení použijte
create_training_set. Tím se vrátí objekt tréninkové sady, který může vrátit Spark DataFrame obsahující vypočítané vlastnosti přidané k datové sadě pozorování, určené pro trénování modelu. - Voláním
log_modeltéto trénovací sady uložíte tento model v katalogu Unity spolu s rodokmenem mezi objekty funkcí a modelu. -
score_batchpoužívá linii Katalogu Unity ke zpracování kódu definice funkce k provádění časově správných agregací funkcí přidaných k datové sadě pro inferenci při hodnocení modelu.
- Pro výpočet agregovaných atributů k určitému bodu v čase pro strojové učení použijte
-
Materializace vlastností a jejich poskytování procesu
- Po definování funkce pomocí
create_featurenebo jejího načtení pomocíget_featuremůžete použítmaterialize_featuresk materializaci funkce nebo sady funkcí do offline úložiště pro efektivní opakované použití, nebo do online úložiště pro online obsluhu. - Pomocí
create_training_setmaterializovaného zobrazení můžete připravit offline dávkovou trénovací datovou sadu.
- Po definování funkce pomocí
Podrobnou dokumentaci k log_model a score_batch najdete v části Použití funkcí k trénování modelů.
Požadavky
Klasický výpočetní cluster s modulem Databricks Runtime 17.0 ML nebo novějším.
Musíte nainstalovat vlastní balíček Pythonu. Při každém spuštění poznámkového bloku se musí spustit následující řádky kódu:
%pip install databricks-feature-engineering>=0.14.0 dbutils.library.restartPython()
Příklad rychlého startu
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering.entities import DeltaTableSource, Sum, Avg, ContinuousWindow, OfflineStoreConfig
from datetime import timedelta
CATALOG_NAME = "main"
SCHEMA_NAME = "feature_store"
TABLE_NAME = "transactions"
# 1. Create data source
source = DeltaTableSource(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name=TABLE_NAME,
entity_columns=["user_id"],
timeseries_column="transaction_time"
)
# 2. Define features
fe = FeatureEngineeringClient()
features = [
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
name="avg_transaction_30d",
source=source,
inputs=["amount"],
function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=30))
),
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
source=source,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
# name auto-generated: "amount_sum_continuous_7d"
),
]
# 3. Create training set using declarative features
`labeled_df` should have columns "user_id", "transaction_time", and "target". It can have other context features specific to the individual observations.
training_set = fe.create_training_set(
df=labeled_df,
features=features,
label="target",
)
training_set.load_df().display() # action: joins labeled_df with computed feature
# 4. Train model
with mlflow.start_run():
training_df = training_set.load_df()
# training code
fe.log_model(
model=model,
artifact_path="recommendation_model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=f"{CATALOG_NAME}.{SCHEMA_NAME}.recommendation_model",
)
# 5. (Optional) Materialize features for serving
fe.materialize_features(
features=features,
offline_config=OfflineStoreConfig(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name_prefix="customer_features"
),
pipeline_state="ACTIVE",
cron_schedule="0 0 * * * ?" # Hourly
)
Poznámka:
Po materializaci funkcí můžete modely nasadit pomocí CPU. Podrobnosti o online poskytování najdete v tématu Materialize a obsluha deklarativních funkcí.
Zdroje dat
DeltaTableSource
Poznámka:
Povolené datové typy pro timeseries_column: TimestampType, DateType. Jiné celočíselné datové typy mohou fungovat, ale způsobí ztrátu přesnosti pro agregace časových intervalů.
Následující kód ukazuje příklad použití main.analytics.user_events tabulky z katalogu Unity:
from databricks.feature_engineering.entities import DeltaTableSource
source = DeltaTableSource(
catalog_name="main", # Catalog name
schema_name="analytics", # Schema name
table_name="user_events", # Table name
entity_columns=["user_id"], # Join keys, used to look up features for an entity
timeseries_column="event_time" # Timestamp for time windows
)
Rozhraní API deklarativních funkcí
create_feature() Rozhraní api
FeatureEngineeringClient.create_feature() poskytuje komplexní ověřování a zajišťuje správnou konstrukci funkcí:
FeatureEngineeringClient.create_feature(
source: DataSource, # Required: DeltaTableSource
inputs: List[str], # Required: List of column names from the source
function: Union[Function, str], # Required: Aggregation function (Sum, Avg, Count, etc.)
time_window: TimeWindow, # Required: TimeWindow for aggregation
catalog_name: str, # Required: The catalog name for the feature
schema_name: str, # Required: The schema name for the feature
name: Optional[str], # Optional: Feature name (auto-generated if omitted)
description: Optional[str], # Optional: Feature description
filter_condition: Optional[str], # Optional: SQL WHERE clause to filter source data
) -> Feature
Parametry:
-
source: Zdroj dat použitý při výpočtu funkce -
inputs: Seznam názvů sloupců ze zdroje, které se mají použít jako vstup pro agregaci -
function: Agregační funkce (instance funkce nebo název řetězce). Seznam podporovaných funkcí najdete níže. -
time_window: Časové okno pro agregaci (instance TimeWindow nebo slovník s 'trváním' a volitelným 'posunem') -
catalog_name: Název katalogu pro funkci -
schema_name: Název schématu pro funkci -
name: Nepovinný název funkce (automaticky vygenerovaný, pokud je vynechán) -
description: Volitelný popis funkce -
filter_condition: Volitelná klauzule SQL WHERE pro filtrování zdrojových dat před agregací. Příklad:"status = 'completed'","transaction" = "Credit" AND "amount > 100"
Vrátí: Ověřená instance funkce
Vyvolává: ValueError, pokud selže jakékoli ověření
Automaticky generované názvy
Pokud name je vynechán, názvy se řídí vzorem: {column}_{function}_{window}. Například:
-
price_avg_continuous_1h(1hodinová průměrná cena) -
transaction_count_continuous_30d_1d(počet transakcí za 30 dní s jednodenním posunem od časového razítka události)
Podporované funkce
Poznámka:
Všechny funkce se použijí v agregačním časovém intervalu, jak je popsáno v části Časové intervaly níže.
| Funkce | Zkratka | Description | Příklad případu použití |
|---|---|---|---|
Sum() |
"sum" |
Součet hodnot | Denní využití aplikace pro jednotlivé uživatele v minutách |
Avg() |
"avg", "mean" |
Průměr hodnot | Střední částka transakce |
Count() |
"count" |
Počet záznamů | Počet přihlášení na jednoho uživatele |
Min() |
"min" |
Minimální hodnota | Nejnižší zaznamenaná srdeční frekvence nositelným zařízením |
Max() |
"max" |
Maximální hodnota | Maximální kapacita košíku počtu položek na relaci |
StddevPop() |
"stddev_pop" |
Směrodatná odchylka základního souboru | Variabilita denních objemů transakcí ve všech zákaznících |
StddevSamp() |
"stddev_samp" |
Vzorová směrodatná odchylka | Proměnlivost prokliků reklamních kampaní |
VarPop() |
"var_pop" |
Rozptyl populace | Šíření čtení snímačů pro zařízení IoT v továrně |
VarSamp() |
"var_samp" |
Výběrový rozptyl | Rozložení hodnocení filmů ve vzorkované skupině |
ApproxCountDistinct(relativeSD=0.05) |
"approx_count_distinct"* |
Přibližný jedinečný počet | Jedinečný počet zakoupených položek |
ApproxPercentile(percentile=0.95,accuracy=100) |
N/A | Přibližný percentil | Latence odpovědi p95 |
First() |
"first" |
První hodnota | Časové razítko prvního přihlášení |
Last() |
"last" |
Poslední hodnota | Poslední nákupní částka |
*Funkce s parametry používají výchozí hodnoty při použití zkrácené syntaxe řetězce.
Následující příklad ukazuje funkce agregace oken definované ve stejném zdroji dat.
from databricks.feature_engineering.entities import Sum, Avg, Count, Max, ApproxCountDistinct
fe = FeatureEngineeringClient()
sum_feature = fe.create_feature(source=source, inputs=["amount"], function=Sum(), ...)
avg_feature = fe.create_feature(source=source, inputs=["amount"], function=Avg(), ...)
distinct_count = fe.create_feature(
source=source,
inputs=["product_id"],
function=ApproxCountDistinct(relativeSD=0.01),
...
)
Funkce s podmínkami filtru
Rozhraní API deklarativních funkcí také podporují použití filtru SQL, který se používá jako WHERE klauzule v agregacích. Filtry jsou užitečné při práci s velkými zdrojovými tabulkami, které obsahují nadmnožinu dat potřebných pro výpočty funkcí, a minimalizuje potřebu vytváření samostatných zobrazení nad těmito tabulkami.
from databricks.feature_engineering.entities import Sum, Count, ContinuousWindow
from datetime import timedelta
# Only aggregate high-value transactions
high_value_sales = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=transactions,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=30)),
filter_condition="amount > 100" # Only transactions over $100
)
# Multiple conditions using SQL syntax
completed_orders = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=orders,
inputs=["order_id"],
function=Count(),
time_window=ContinuousWindow(window_duration=timedelta(days=7)),
filter_condition="status = 'completed' AND payment_method = 'credit_card'"
)
Časová okna
Deklarativní rozhraní API pro přípravu funkcí podporují tři různé typy oken pro řízení chování zpětného vyhledávání pro agregace založené na časových osách: průběžné, přeskakující a posuvné.
- Průběžná okna se zpětně dívají od času události. Doba trvání a posun jsou explicitně definovány.
- Okna typu 'tumbling' jsou pevná, nepřekrývající se časová okna. Každý datový bod patří přesně do jednoho okna.
- Posuvná okna se překrývají, jsou to posunovací časová okna s konfigurovatelným intervalem posunu.
Následující obrázek ukazuje, jak fungují.
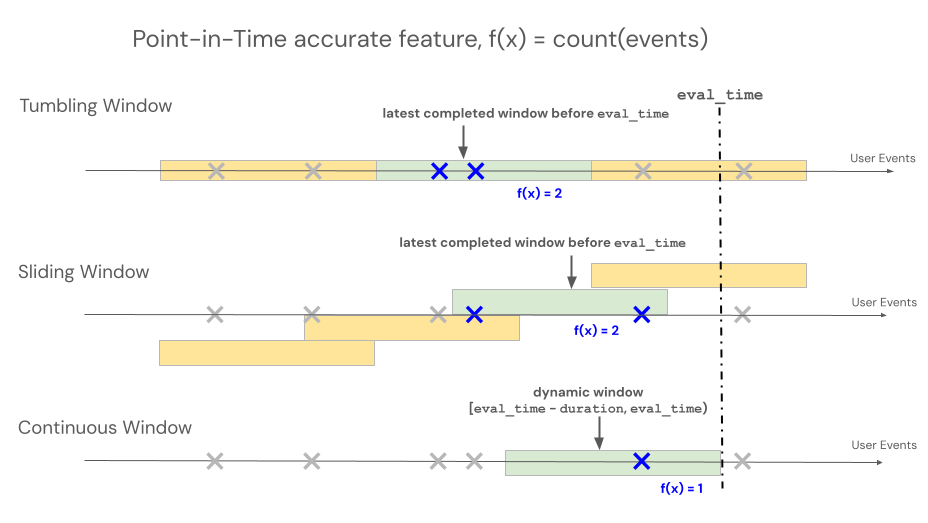
Průběžné okno
Kontinuální okna jsou aktuální a agregáty v reálném čase, obvykle se používají přes streamovaná data. Ve streamovacích kanálech vygeneruje nepřetržité okno nový řádek pouze v případě, že se obsah pevně definovaného okna změní, například když událost vstoupí nebo odejde. Pokud se v trénovacích kanálech používá průběžná funkcionalita okna, provádí se přesný výpočet funkce k určitému okamžiku v čase na zdrojových datech pomocí časového okna s pevnou délkou, ihned před časovou značkou konkrétní události. To pomáhá zabránit nesouladu mezi online a offline daty nebo úniku dat. Funkce v čase T agregují události od [T − doba trvání, T).
class ContinuousWindow(TimeWindow):
window_duration: datetime.timedelta
offset: Optional[datetime.timedelta] = None
Následující tabulka uvádí parametry pro souvislé okno. Počáteční a koncové časy okna jsou založené na těchto parametrech:
- Čas zahájení:
evaluation_time - window_duration + offset(včetně) - Koncový čas:
evaluation_time + offset(výhradní)
| Parameter | Constraints |
|---|---|
offset (volitelné) |
Musí být ≤ 0 (posunuje okno zpět v čase od koncového časového razítka). Používá offset se k zohlednění jakéhokoli zpoždění systému mezi časem vytvoření události a časovým razítkem události, aby se zabránilo budoucímu úniku událostí do trénovacích datových sad. Pokud je například mezi časem vytvoření událostí zpoždění o jednu minutu a tyto události se nakonec přidají do zdrojové tabulky, kde je jim přiřazen časový údaj, bude timedelta(minutes=-1)posun. |
window_duration |
Musí být > 0. |
from databricks.feature_engineering.entities import ContinuousWindow
from datetime import timedelta
# Look back 7 days from evaluation time
window = ContinuousWindow(window_duration=timedelta(days=7))
Definujte souvislé okno s posunem pomocí následujícího kódu.
# Look back 7 days, but end 1 day ago (exclude most recent day)
window = ContinuousWindow(
window_duration=timedelta(days=7),
offset=timedelta(days=-1)
)
Příklady průběžných oken
window_duration=timedelta(days=7), offset=timedelta(days=0): Vytvoří se 7denní okno pro zpětný pohled, které končí v okamžiku aktuálního vyhodnocení. U události v 2:00 dne 7 se to týká všech událostí od 2:00 v den 0 až do (ale ne) 2:00 dne 7.window_duration=timedelta(hours=1), offset=timedelta(minutes=-30): Vytvoří se 1hodinový interval zpětného vyhledávání, který končí 30 minut před časem vyhodnocení. U události v 17:00 to zahrnuje všechny události od 13:30 do (ale ne) 2:30 pm. To je užitečné při zohlednění zpoždění příjmu dat.
Přeskakující okno
U funkcí definovaných pomocí pohybujících se oken se agregace počítají přes předem určené okno s pevnou délkou, které postupuje posuvným intervalem a vytváří nepřekrývající se okna, která plně rozdělují čas. V důsledku toho každá událost ve zdroji patří přesně do jednoho okna. Funkce v čase t agregují data z oken končících na nebo před t (výhradní). Systém Windows se spouští v unixové epochě.
class TumblingWindow(TimeWindow):
window_duration: datetime.timedelta
Následující tabulka uvádí parametry pro přeskakující okno.
| Parameter | Constraints |
|---|---|
window_duration |
Musí být > 0. |
from databricks.feature_engineering.entities import TumblingWindow
from datetime import timedelta
window = TumblingWindow(
window_duration=timedelta(days=7)
)
Příklad přeskakujícího okna
-
window_duration=timedelta(days=5): Vytvoří se předem určená okna s pevnou délkou 5 dní. Příklad: Okno č. 1 zahrnuje den 0 až den 4, okno #2 zahrnuje 5. den až 9, okno č. 3 zahrnuje 10. den a další. Konkrétně okno č. 1 obsahuje všechny události s časovými razítky začínajícími dne 0 na00:00:00.00až (ale ne včetně) jakékoli události s časovým razítkem00:00:00.00dne 5. Každá událost patří přesně do jednoho okna.
Posuvné okno
U funkcí definovaných pomocí posuvných oken se agregace počítají přes předem určené okno s pevnou délkou, které postupuje posunovým intervalem a okna se překrývají. Každá událost ve zdroji může přispět k agregaci funkcí pro více oken. Funkce v čase t agregují data z oken končících na nebo před t (výhradní). Systém Windows se spouští v unixové epochě.
class SlidingWindow(TimeWindow):
window_duration: datetime.timedelta
slide_duration: datetime.timedelta
Následující tabulka uvádí parametry posuvného okna.
| Parameter | Constraints |
|---|---|
window_duration |
Musí být > 0. |
slide_duration |
Musí být > 0 a <window_duration |
from databricks.feature_engineering.entities import SlidingWindow
from datetime import timedelta
window = SlidingWindow(
window_duration=timedelta(days=7),
slide_duration=timedelta(days=1)
)
Příklad posuvného okna
-
window_duration=timedelta(days=5), slide_duration=timedelta(days=1): Tím se vytvoří překrývající se 5denní intervaly, které se posunou každý den o 1 den. Příklad: Okno č. 1 zahrnuje den 0 až den 4, okno č. 2 zahrnuje 1. den až den 5, okno č. 3 zahrnuje 2. den až den 6 atd. Každé okno obsahuje události od00:00:00.00na počátku až po (ale nepokryje)00:00:00.00na konci dne. Vzhledem k tomu, že se okna překrývají, může jedna událost patřit do více oken (v tomto příkladu každá událost patří až do 5 různých oken).
Metody rozhraní API
create_training_set()
Připojte se k funkcím s označenými daty pro trénování ML:
FeatureEngineeringClient.create_training_set(
df: DataFrame, # DataFrame with training data
features: Optional[List[Feature]], # List of Feature objects
label: Union[str, List[str], None], # Label column name(s)
exclude_columns: Optional[List[str]] = None, # Optional: columns to exclude
# API continues to support creating training set using materialized feature tables and functions
) -> TrainingSet
Volání TrainingSet.load_df pro získání původních trénovacích dat spojených s dynamicky vypočítanými funkcemi k určitému bodu v čase
Požadavky pro df argument:
- Musí obsahovat všechny
entity_columnsdatové zdroje funkcí. - Musí obsahovat
timeseries_columnzdroje dat pro funkce. - Měly by obsahovat sloupce popisků.
Správnost k určitému bodu v čase: Funkce se počítají pouze se zdrojovými daty dostupnými před časovým razítkem každého řádku, aby se zabránilo budoucímu úniku dat do trénování modelu. Výpočty využívají funkce oken Sparku k zajištění efektivity.
log_model()
Záznam modelu s metadaty vlastností pro stopování původu a automatické vyhledávání vlastností během predikce.
FeatureEngineeringClient.log_model(
model, # Trained model object
artifact_path: str, # Path to store model artifact
flavor: ModuleType, # MLflow flavor module (e.g., mlflow.sklearn)
training_set: TrainingSet, # TrainingSet used for training
registered_model_name: Optional[str], # Optional: register model in Unity Catalog
)
Parametr flavor určuje modul příchuť modelu MLflow , který se má použít, například mlflow.sklearn nebo mlflow.xgboost.
Modely zaznamenané pomocí TrainingSet automaticky sledují vztah k funkcím používaným při trénování. Podrobnou dokumentaci najdete v tématu Použití funkcí k trénování modelů.
score_batch()
Provedení dávkového odvozování pomocí automatického vyhledávání funkcí:
FeatureEngineeringClient.score_batch(
model_uri: str, # URI of logged model
df: DataFrame, # DataFrame with entity keys and timestamps
) -> DataFrame
score_batch používá metadata funkcí uložená s modelem k automatickému výpočtu správných funkcí k určitému bodu v čase pro odvozování, což zajišťuje konzistenci s trénováním. Podrobnou dokumentaci najdete v tématu Použití funkcí k trénování modelů.
Osvědčené postupy
Pojmenování funkcí
- Používejte popisné názvy pro důležité obchodní funkce.
- Dodržujte konzistentní konvence vytváření názvů napříč týmy.
- Nechte automatické generování zpracovávat zkušební funkce.
Časová okna
- Pomocí posunů vyloučíte nestabilní nedávná data.
- Zarovnejte hranice oken s obchodními cykly (denně, týdně).
- Vezměte v úvahu aktuálnost dat vs. kompromisy stability funkcí.
Performance
- Seskupte funkce podle zdroje dat, abyste minimalizovali prohledávání dat.
- Pro váš případ použití použijte vhodné velikosti oken.
Testing
- Otestování hranic časových intervalů se známými datovými scénáři
Obvyklé scénáře
Analýzy zákazníků
fe = FeatureEngineeringClient()
features = [
# Recency: Number of transactions in the last day
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=1))),
# Frequency: transaction count over the last 90 days
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=90))),
# Monetary: total spend in the last month
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["amount"],
function=Sum(), time_window=ContinuousWindow(window_duration=timedelta(days=30)))
]
Rozbor tendence
# Compare recent vs. historical behavior
fe = FeatureEngineeringClient()
recent_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
)
historical_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7), offset=timedelta(days=-7))
)
Sezónní vzory
# Same day of week, 4 weeks ago
fe = FeatureEngineeringClient()
weekly_pattern = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=1), offset=timedelta(weeks=-4))
)
Omezení
- Názvy sloupců entit a časových období se musí shodovat mezi trénovací (označenou) datovou sadou a zdrojovými tabulkami, pokud se používají v
create_training_setrozhraní API. - Název sloupce použitý jako
labelsloupec v trénovací datové sadě by neměl existovat ve zdrojových tabulkách používaných k definováníFeature. - Rozhraní
create_featureAPI podporuje omezený seznam funkcí (UDAF).