Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
TensorBoard je sada vizualizačních nástrojů pro ladění, optimalizaci a pochopení TensorFlow, PyTorch, Hugging Face Transformers a dalších programů strojového učení.
Použití TensorBoardu
Spuštění TensorBoardu v Azure Databricks se nijak neliší od jeho spuštění v Jupyter notebooku na vašem místním počítači.
Načtěte magický příkaz
%tensorboarda definujte adresář protokolu.%load_ext tensorboard experiment_log_dir = <log-directory>Vyvolejte magický příkaz
%tensorboard.%tensorboard --logdir $experiment_log_dirServer TensorBoard se spustí a zobrazí uživatelské rozhraní v poznámkovém bloku. Obsahuje také odkaz, který umožňuje otevření TensorBoardu na nové kartě.
Následující snímek obrazovky ukazuje uživatelské rozhraní TensorBoard spuštěné v adresáři se záznamy.
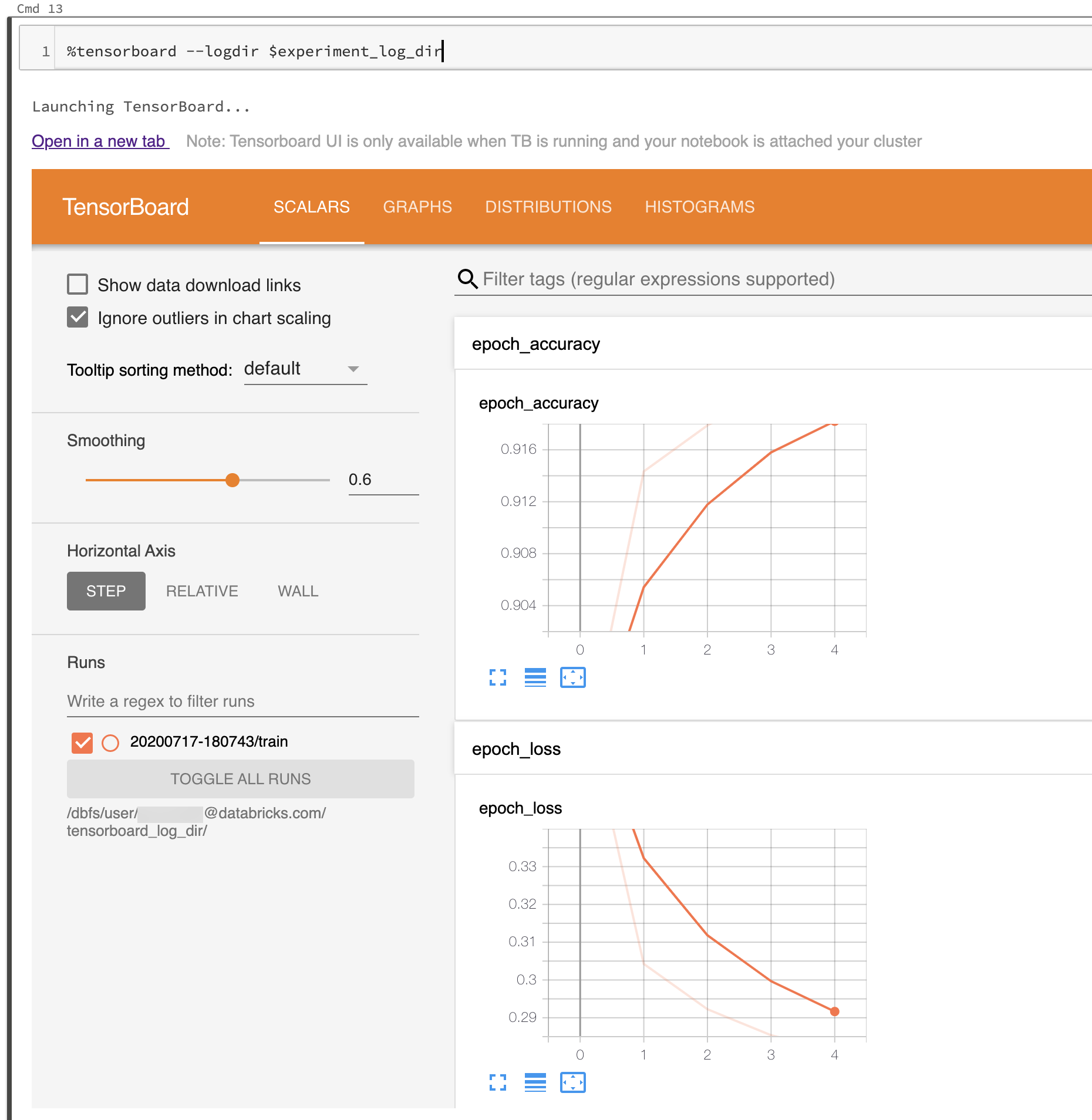
TensorBoard můžete také spustit přímo pomocí modulu poznámkového bloku TensorBoardu.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
Adresáře a protokoly TensorBoardu
TensorBoard vizualizuje programy strojového učení čtením protokolů generovaných zpětnými voláními a funkcemi TensorBoardu v TensorBoardu nebo PyTorchu. Pokud chcete generovat protokoly pro jiné knihovny strojového učení, můžete přímo zapisovat protokoly pomocí zapisovačů souborů TensorFlow (viz modul : tf.summary pro TensorFlow 2.x a viz modul : tf.compat.v1.summary pro starší rozhraní API v TensorFlow 1.x).
Aby se zajistilo spolehlivé ukládání protokolů experimentů, doporučuje Databricks místo dočasného systému souborů clusteru zapisovat protokoly do cloudového úložiště. Pro každý experiment spusťte TensorBoard v jedinečném adresáři. Pro každé spuštění kódu strojového učení v experimentu, který generuje protokoly, nastavte TensorBoard callback nebo zapisovač souborů tak, aby zapisoval do podadresáře adresáře experimentu. Tímto se data v uživatelském rozhraní TensorBoard rozdělí na běhy.
Přečtěte si oficiální dokumentaci TensorBoard, abyste mohli začít používat TensorBoard k protokolování informací pro váš program strojového učení.
Správa procesů TensorBoardu
Procesy TensorBoard spuštěné v poznámkovém bloku Azure Databricks se neukončí, když je poznámkový blok odpojený nebo se restartuje REPL (například když vymažete stav poznámkového bloku). Chcete-li ručně ukončit proces TensorBoard, odešlete ho signál ukončení pomocí %sh kill -15 pid. Nesprávně ukončené procesy TensorBoard mohou poškodit notebook.list().
Pokud chcete zobrazit seznam serverů TensorBoard aktuálně spuštěných v clusteru s odpovídajícími adresáři protokolů a ID procesů, spusťte notebook.list() z modulu poznámkového bloku TensorBoard.
Známé problémy
- Vložené uživatelské rozhraní TensorBoardu je uvnitř prvku iframe. Funkce zabezpečení prohlížeče brání fungování externích odkazů v uživatelském rozhraní, pokud odkaz neotevřete na nové kartě.
- Možnost
--window_titleTensorBoardu se přepíše v Azure Databricks. - Ve výchozím nastavení TensorBoard prohledá rozsah portů a vybere port, který se má naslouchat. Pokud v clusteru běží příliš mnoho procesů TensorBoard, nemusí být všechny porty v rozsahu portů dostupné. Toto omezení můžete obejít zadáním čísla portu s argumentem
--port. Zadaný port by měl být mezi 6006 a 6106. - Aby odkazy pro stažení fungovaly, je nutné otevřít TensorBoard v záložce.
- Při použití TensorBoardu 1.15.0 je karta Projektor prázdná. Alternativním řešením, jak navštívit stránku projektoru přímo, je nahradit
#projectorv adrese URL zadata/plugin/projector/projector_binary.html. - TensorBoard 2.4.0 má známý problém , který může mít vliv na vykreslování TensorBoardu při upgradu.
- Pokud protokolujete data související s TensorBoardem do svazků DBFS nebo UC, může se zobrazit chyba typu
No dashboards are active for the current data set. Chcete-li tuto chybu překonat, je vhodné volatwriter.flush()awriter.close()poté, co pomocíwriterzaznamenáte data. Tím zajistíte, že se všechna protokolovaná data správně zapisují a jsou k dispozici pro vykreslení TensorBoardu.