Zapisování, načítání a registrace modelů MLflow
Model MLflow je standardní formát pro balení modelů strojového učení, které je možné použít v různých podřízených nástrojích – například dávkové odvozování v Apache Sparku nebo obsluhování v reálném čase prostřednictvím rozhraní REST API. Formát definuje konvenci, která umožňuje uložit model v různých příchutích (python-function, pytorch, sklearn atd.), které je možné pochopit různými platformami pro obsluhu a odvozování modelů.
Informace o tom, jak protokolovat a ohodnotit model streamování, najdete v tématu Jak uložit a načíst model streamování.
Protokolování a načítání modelů
Při protokolování modelu MLflow automaticky protokoluje requirements.txt a conda.yaml soubory. Tyto soubory můžete použít k opětovnému vytvoření vývojového prostředí modelu a přeinstalaci závislostí pomocí virtualenv (doporučeno) nebo conda.
Důležité
Anaconda Inc. aktualizoval své podmínky služby pro kanály anaconda.org. Na základě nových podmínek služby můžete vyžadovat komerční licenci, pokud spoléháte na balení a distribuci Anaconda. Další informace najdete v tématu Anaconda Commercial Edition – nejčastější dotazy . Vaše používání všech kanálů Anaconda se řídí jejich podmínkami služby.
Modely MLflow protokolované před verzí 1.18 (Databricks Runtime 8.3 ML nebo starší) byly ve výchozím nastavení protokolovány pomocí kanálu Conda defaults (https://repo.anaconda.com/pkgs/) jako závislosti. Kvůli této změně licence služba Databricks zastavila používání defaults kanálu pro modely protokolované pomocí MLflow verze 1.18 a vyšší. Výchozí protokolovaný kanál je nyní conda-forge, který odkazuje na komunitu spravovanou https://conda-forge.org/.
Pokud jste model zaprotokolovali před MLflow verze 1.18 bez vyloučení defaults kanálu z prostředí Conda pro model, může mít tento model závislost na defaults kanálu, který jste možná nezamýšleli.
Pokud chcete ručně ověřit, jestli má model tuto závislost, můžete prozkoumat channel hodnotu v conda.yaml souboru, který je zabalený s protokolovaným modelem. Model s závislostí conda.yaml kanálu může například defaults vypadat takto:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Protože Databricks nedokáže určit, jestli vaše použití úložiště Anaconda k interakci s vašimi modely je povoleno v rámci vašeho vztahu s Anaconda, Databricks nevynucuje svým zákazníkům provádět žádné změny. Pokud je vaše použití Anaconda.com úložiště prostřednictvím použití Databricks povolené podle podmínek Anaconda, nemusíte nic dělat.
Pokud chcete změnit kanál použitý v prostředí modelu, můžete model znovu zaregistrovat do registru modelů pomocí nového conda.yaml. Můžete to provést zadáním kanálu v parametru conda_env .log_model()
Další informace o log_model() rozhraní API najdete v dokumentaci MLflow pro variantu modelu, se kterou pracujete, například log_model pro scikit-learn.
Další informace o conda.yaml souborech najdete v dokumentaci K MLflow.
Příkazy rozhraní API
Chcete-li protokolovat model na sledovací server MLflow
Pokud chcete načíst dříve protokolovaný model pro odvozování nebo další vývoj, použijte mlflow.<model-type>.load_model(modelpath), kde modelpath je jedna z následujících možností:
- relativní cesta spuštění (například
runs:/{run_id}/{model-path}) - cesta ke svazkům v systému Unity Catalog (například
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - Cesta úložiště artefaktů spravovaná MLflow od
dbfs:/databricks/mlflow-tracking/ - registrovanou cestu modelu (například
models:/{model_name}/{model_stage}).
Úplný seznam možností načítání modelů MLflow najdete v tématu Odkazování na artefakty v dokumentaci MLflow.
U modelů Python MLflow je další možností načtení mlflow.pyfunc.load_model() modelu jako obecné funkce Pythonu.
K načtení modelu a skóre datových bodů můžete použít následující fragment kódu.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Jako alternativu můžete model exportovat jako UDF Apache Sparku, který se použije k vyhodnocování v clusteru Spark, a to buď jako dávkovou úlohu, nebo jako úlohu streamování Sparku v reálném čase.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Závislosti modelu protokolů
Pokud chcete model přesně načíst, měli byste se ujistit, že jsou závislosti modelu načtené se správnými verzemi do prostředí poznámkového bloku. V Databricks Runtime 10.5 ML a novějším vás MLflow upozorní, pokud se zjistí neshoda mezi aktuálním prostředím a závislostmi modelu.
Další funkce pro zjednodušení obnovování závislostí modelu jsou součástí Databricks Runtime 11.0 ML a vyšší. Ve službě Databricks Runtime 11.0 ML a novějších můžete pro pyfunc modely variant volat mlflow.pyfunc.get_model_dependencies načtení a stažení závislostí modelu. Tato funkce vrátí cestu k souboru závislostí, který pak můžete nainstalovat pomocí %pip install <file-path>. Při načítání modelu jako PySpark UDF zadejte env_manager="virtualenv" ve mlflow.pyfunc.spark_udf volání. Tím se obnoví závislosti modelu v kontextu PySpark UDF a neovlivní vnější prostředí.
Tuto funkci můžete použít také v Databricks Runtime 10.5 nebo níže ruční instalací MLflow verze 1.25.0 nebo vyšší:
%pip install "mlflow>=1.25.0"
Další informace o tom, jak protokolovat závislosti modelu (Python a jiné než Python) a artefakty, najdete v tématu Závislosti modelu protokolu.
Zjistěte, jak protokolovat závislosti modelu a vlastní artefakty pro obsluhu modelu:
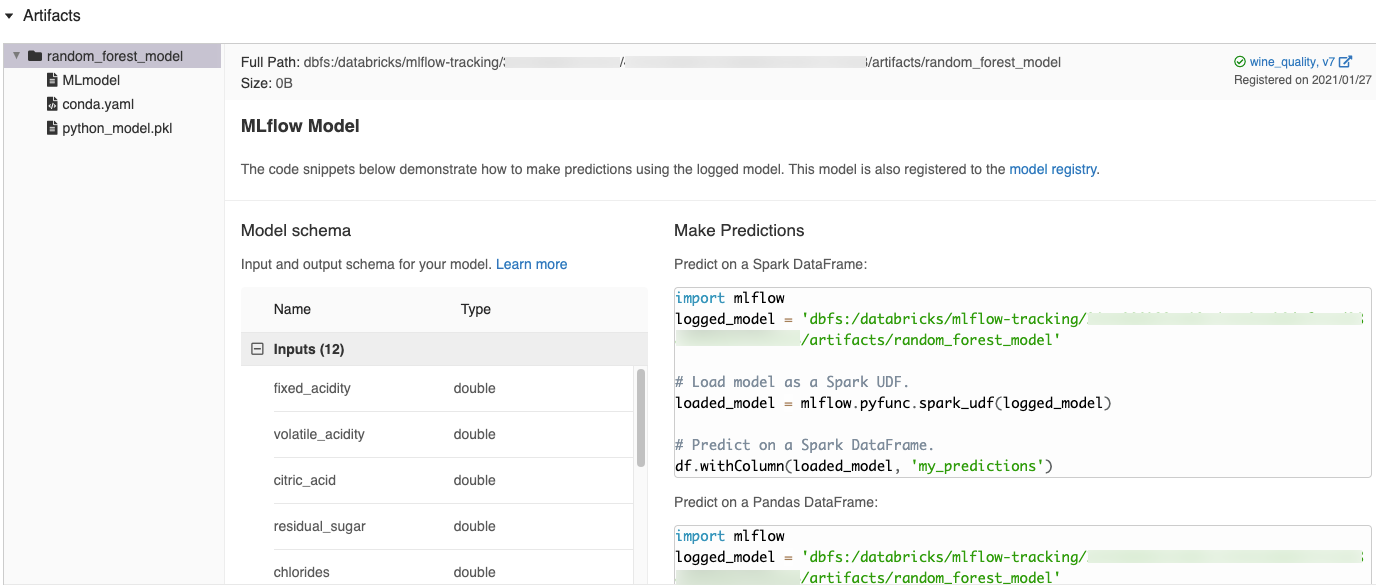
Automaticky generované fragmenty kódu v uživatelském rozhraní MLflow
Když do poznámkového bloku Azure Databricks zapíšete model, Azure Databricks automaticky vygeneruje fragmenty kódu, které můžete kopírovat a používat k načtení a spuštění modelu. Zobrazení těchto fragmentů kódu:
- Přejděte na obrazovku Spuštění pro spuštění, které model vygeneroval. (Viz Zobrazení experimentu poznámkového bloku pro zobrazení obrazovky Spuštění.)
- Posuňte se do části Artefakty .
- Klikněte na název protokolovaného modelu. Otevře se panel napravo zobrazující kód, pomocí kterého můžete načíst protokolovaný model a vytvářet předpovědi v datových rámcích Spark nebo pandas.
Příklady
Příklady modelů protokolování najdete v příkladech sledování trénovacích běhů strojového učení.
Registrace modelů v registru modelů
Modely můžete zaregistrovat v registru modelů MLflow, centralizované úložiště modelů, které poskytuje uživatelské rozhraní a sadu rozhraní API pro správu celého životního cyklu modelů MLflow. Pokyny k používání registru modelů ke správě modelů v katalogu Unity Databricks najdete v tématu Správa životního cyklu modelu v katalogu Unity. Pokud chcete použít registr modelů pracovního prostoru, přečtěte si téma Správa životního cyklu modelu pomocí registru modelů pracovního prostoru (starší verze).
K registraci modelu pomocí rozhraní API použijte mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}").
Ukládání modelů do svazků katalogu Unity
Pokud chcete model uložit místně, použijte mlflow.<model-type>.save_model(model, modelpath).
modelpath musí být svazky katalogu Unity cestu. Například pokud používáte umístění svazků v katalogu Unity dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models k uložení práce na projektu, měli byste použít cestu modelu /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Pro modely MLlib využijte kanály ML.
Stažení artefaktů modelu
Artefakty zaznamenaného modelu (například soubory modelu, grafy a metriky) si můžete stáhnout pro zaregistrovaný model s různými rozhraními API.
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Příklad příkazu rozhraní příkazového řádku:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Nasazení modelů pro online obsluhu
Poznámka
Před nasazením modelu je vhodné ověřit, že je model schopný být obsluhován. Informace o použití mlflow.models.predict k ověřování modelů přednasazení najdete v dokumentaci MLflow.
K hostování modelů strojového učení registrovaných v registru modelu Unity jako koncových bodů REST použijte Mosaic AI Model Serving. Tyto koncové body se aktualizují automaticky na základě dostupnosti verzí modelu.