Spuštění projektů MLflow v Azure Databricks
Upozorňující
Projekty MLflow se už nepodporují.
Projekt MLflow je formát pro balení kódu datové vědy opakovaně použitelným a reprodukovatelným způsobem. Komponenta MLflow Projects zahrnuje rozhraní API a nástroje příkazového řádku pro spouštění projektů, které se také integrují s komponentou Sledování, aby se automaticky zaznamenávaly parametry a potvrzení Gitu zdrojového kódu pro reprodukovatelnost.
Tento článek popisuje formát projektu MLflow a způsob vzdáleného spuštění projektu MLflow v clusterech Azure Databricks pomocí rozhraní příkazového řádku MLflow, což usnadňuje vertikální škálování kódu datové vědy.
Formát projektu MLflow
Jakýkoli místní adresář nebo úložiště Git je možné považovat za projekt MLflow. Následující konvence definují projekt:
- Název projektu je název adresáře.
- V případě přítomnosti je zadané
python_env.yamlsoftwarové prostředí. Pokud neexistuje žádnýpython_env.yamlsoubor, MLflow při spuštění projektu používá prostředí virtualenv obsahující pouze Python (konkrétně nejnovější Python dostupný pro virtualenv). - Libovolný
.pynebo.shsoubor v projektu může být vstupním bodem bez explicitně deklarovaných parametrů. Když spustíte takový příkaz se sadou parametrů, MLflow předá každý parametr na příkazovém řádku pomocí--key <value>syntaxe.
Další možnosti zadáte přidáním souboru MLproject, což je textový soubor v syntaxi YAML. Ukázkový soubor MLproject vypadá takto:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
V případě Databricks Runtime 13.0 ML a novějších nejde úspěšně spustit projekty MLflow v rámci clusteru typů úloh Databricks. Pokud chcete migrovat existující projekty MLflow do Databricks Runtime 13.0 ML a vyšší, přečtěte si formát projektu úlohy MLflow Databricks Spark.
Formát projektu úlohy Spark v MLflow Databricks
Projekt úlohy MLflow Databricks Spark je typ projektu MLflow zavedený v MLflow 2.14. Tento typ projektu podporuje spouštění projektů MLflow z clusteru úloh Sparku a dá se spustit jenom pomocí back-endu databricks .
Projekty úloh Databricks Spark musí nastavit buď databricks_spark_job.python_file nebo entry_points. Nezadání ani zadání obou nastavení vyvolá výjimku.
Následuje příklad MLproject souboru, který toto nastavení používá databricks_spark_job.python_file . Toto nastavení zahrnuje použití pevně zakódované cesty pro soubor spuštění Pythonu a jeho argumenty.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Následuje příklad MLproject souboru, který používá entry_points nastavení:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
Toto entry_points nastavení umožňuje předávat parametry, které používají parametry příkazového řádku, například:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Pro projekty úloh Databricks Spark platí následující omezení:
- Tento typ projektu nepodporuje zadání následujících částí v
MLprojectsouboru:docker_env,python_envneboconda_env. - Závislosti pro váš projekt musí být zadány v
python_librariespoli oddíludatabricks_spark_job. Verze Pythonu nelze přizpůsobit pomocí tohoto typu projektu. - Spuštěné prostředí musí používat hlavní prostředí modulu runtime ovladače Spark ke spouštění v clusterech úloh, které používají Databricks Runtime 13.0 nebo vyšší.
- Stejně tak musí být všechny závislosti Pythonu definované podle potřeby pro projekt nainstalovány jako závislosti clusteru Databricks. Toto chování se liší od chování při spuštění předchozího projektu, kdy je potřeba nainstalovat knihovny v samostatném prostředí.
Spuštění projektu MLflow
Pokud chcete spustit projekt MLflow v clusteru Azure Databricks ve výchozím pracovním prostoru, použijte tento příkaz:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
kde <uri> je identifikátor URI úložiště Git nebo složka obsahující projekt MLflow a <json-new-cluster-spec> je dokument JSON obsahující strukturu new_cluster. Identifikátor URI Gitu by měl být ve formátu: https://github.com/<repo>#<project-folder>.
Příkladem specifikace clusteru je:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Pokud potřebujete nainstalovat knihovny do pracovního procesu, použijte formát specifikace clusteru. Všimněte si, že soubory kol Pythonu se musí nahrát do DBFS a zadat jako pypi závislosti. Příklad:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Důležité
.egga.jarzávislosti nejsou podporovány pro projekty MLflow.- Spouštění projektů MLflow s prostředími Dockeru se nepodporuje.
- Při spuštění projektu MLflow v Databricks musíte použít novou specifikaci clusteru. Spouštění projektů s existujícími clustery se nepodporuje.
Použití SparkR
Aby bylo možné použít SparkR ve spuštění projektu MLflow, musí kód projektu nejprve nainstalovat a importovat SparkR následujícím způsobem:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Váš projekt pak může inicializovat relaci SparkR a používat SparkR jako normální:
sparkR.session()
...
Příklad
Tento příklad ukazuje, jak vytvořit experiment, spustit projekt kurzu MLflow v clusteru Azure Databricks, zobrazit výstup spuštění úlohy a zobrazit spuštění v experimentu.
Požadavky
- Nainstalujte MLflow pomocí
pip install mlflow. - Nainstalujte a nakonfigurujte rozhraní příkazového řádku Databricks. K spouštění úloh v clusteru Azure Databricks se vyžaduje mechanismus ověřování rozhraní příkazového řádku Databricks.
Krok 1: Vytvoření experimentu
V pracovním prostoru vyberte Vytvořit > experiment MLflow.
Do pole Název zadejte
Tutorial.Klikněte na Vytvořit. Poznamenejte si ID experimentu. V tomto příkladu je to
14622565.
Krok 2: Spuštění projektu kurzu MLflow
Následující kroky nastaví MLFLOW_TRACKING_URI proměnnou prostředí a spustí projekt, zaznamená parametry trénování, metriky a trénovaný model do experimentu, který jste si poznamenali v předchozím kroku:
Nastavte proměnnou
MLFLOW_TRACKING_URIprostředí na pracovní prostor Azure Databricks.export MLFLOW_TRACKING_URI=databricksSpusťte projekt kurzu MLflow a trénujte model vína. Nahraďte
<experiment-id>ID experimentu, které jste si poznamenali v předchozím kroku.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Zkopírujte adresu URL
https://<databricks-instance>#job/<job-id>/run/1na posledním řádku výstupu spuštění MLflow.
Krok 3: Zobrazení spuštění úlohy Azure Databricks
Otevřete adresu URL, kterou jste zkopírovali v předchozím kroku v prohlížeči, a zobrazte výstup spuštění úlohy Azure Databricks:

Krok 4: Zobrazení podrobností o spuštění experimentu a MLflow
Přejděte k experimentu v pracovním prostoru Azure Databricks.

Klikněte na experiment.
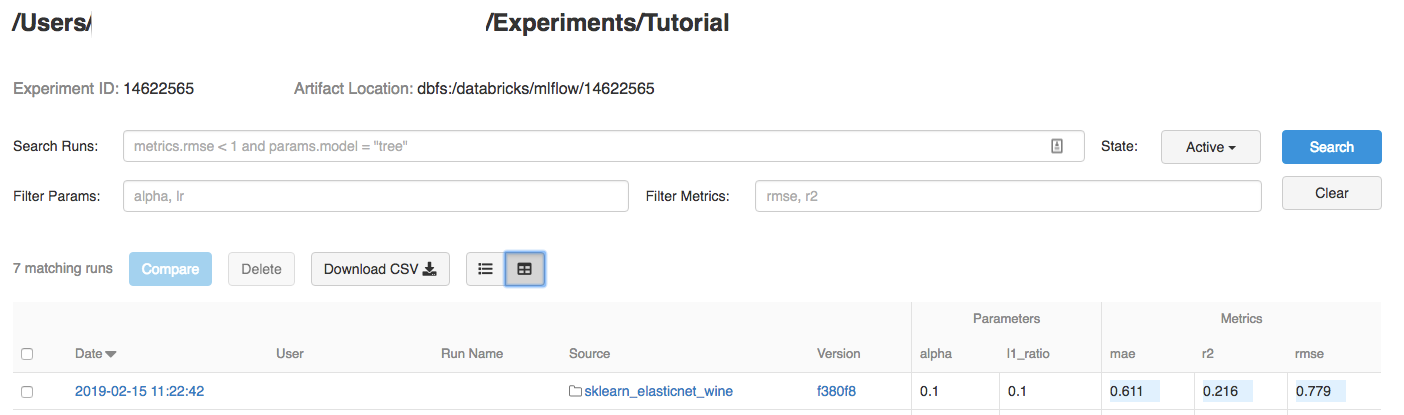
Pokud chcete zobrazit podrobnosti o spuštění, klikněte na odkaz ve sloupci Datum.
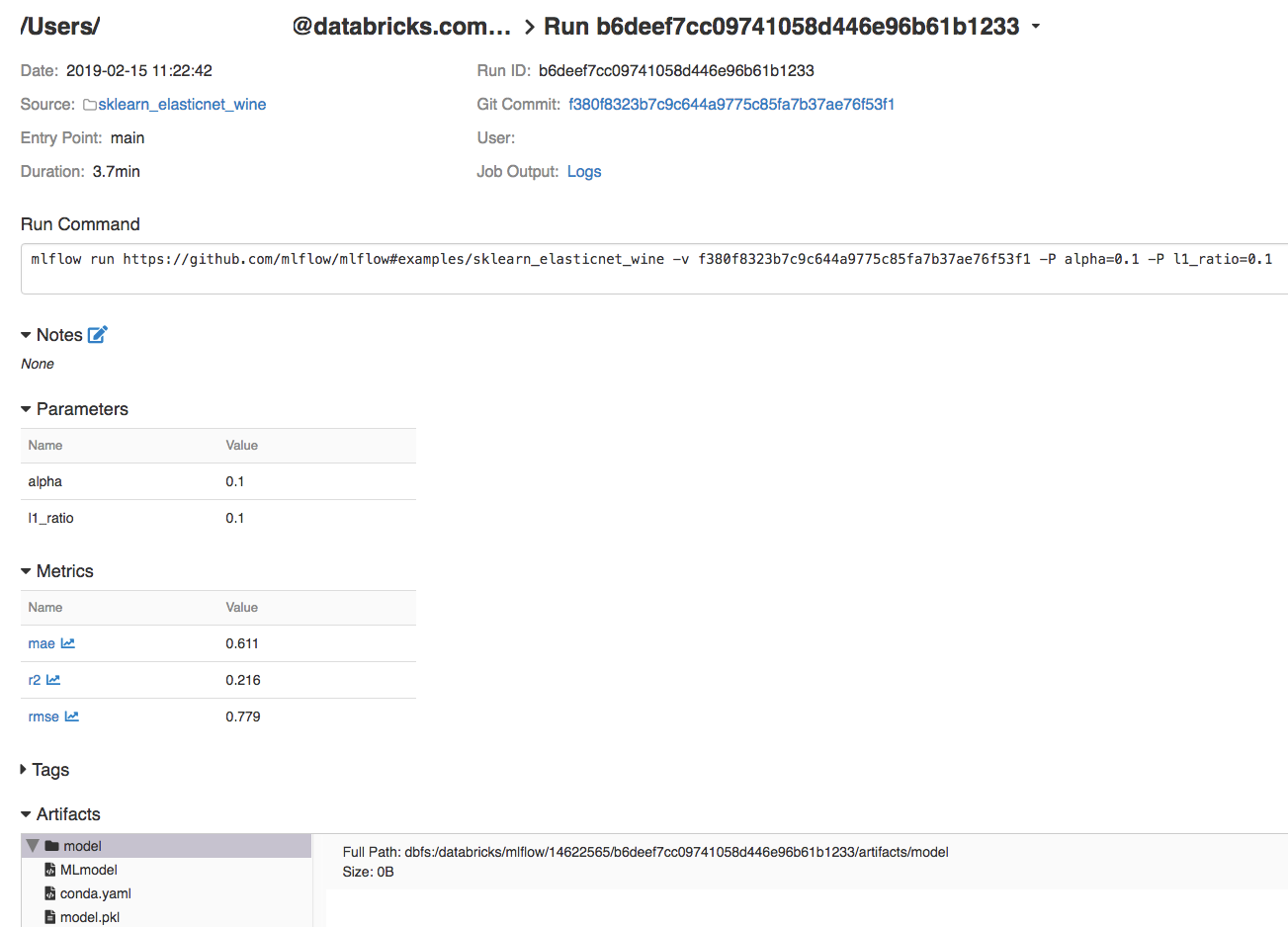
Protokoly ze spuštění můžete zobrazit kliknutím na odkaz Protokoly v poli Výstup úlohy.
Zdroje informací
Některé příklady projektů MLflow najdete v knihovně aplikací MLflow, která obsahuje úložiště projektů připravených ke spuštění, které usnadňují zahrnutí funkcí ML do kódu.