Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Naučte se orchestrovat poznámkové bloky a modularizovat kód v poznámkových blocích. Podívejte se na příklady a zjistěte, kdy použít alternativní metody orchestrace poznámkových bloků.
Metody orchestrace a modularizace kódu
Následující tabulka porovnává metody, které jsou k dispozici pro orchestraci poznámkových bloků a modularizaci kódu v poznámkových blocích.
| Metoda | Případ použití | Poznámky |
|---|---|---|
| Úlohy Lakeflow | Orchestrace poznámkových bloků (doporučeno) | Doporučená metoda orchestrace poznámkových bloků Podporuje složité pracovní postupy se závislostmi úkolů, plánováním a aktivačními událostmi. Poskytuje robustní a škálovatelný přístup pro produkční úlohy, ale vyžaduje nastavení a konfiguraci. |
| |
Orchestrace poznámkových bloků | Použijte dbutils.notebook.run(), pokud úlohy nemohou podporovat váš případ použití, například když potřebujete opakovaně spouštět poznámkové bloky s dynamickou sadou parametrů.Spustí novou dočasnou úlohu pro každé volání, což může zvýšit režii a chybí mu pokročilé schopnosti plánování. |
| soubory pracovního prostoru |
Modularizace kódu (doporučeno) | Doporučená metoda pro modularizaci kódu Modularizace kódu do opakovaně použitelných souborů kódu uložených v pracovním prostoru Podporuje správu verzí pomocí repozitářů a integraci s IDE pro lepší ladění a jednotkové testování. Vyžaduje další nastavení pro správu cest k souborům a závislostem. |
| %run | Modularizace kódu | Použijte %run , pokud nemáte přístup k souborům pracovního prostoru.Importujte funkce nebo proměnné z jiných poznámkových bloků jejich přímým spuštěním. Užitečné pro vytváření prototypů, ale může vést k úzce propojenému kódu, který je obtížnější udržovat. Nepodporuje předávání parametrů ani správu verzí. |
%run Vs. dbutils.notebook.run()
Příkaz %run umožňuje vložit jeden poznámkový blok do druhého. Pomocí %run můžete kód modularizovat vložením podpůrných funkcí do samostatného poznámkového bloku. Můžete ho také použít ke zřetězení poznámkových bloků, které implementují kroky v analýze. Když použijete %run, volaný poznámkový blok se okamžitě spustí a funkce a proměnné definované v něm budou ve volajícím poznámkovém bloku k dispozici.
Rozhraní API dbutils.notebook doplňuje %run, protože umožňuje předávat parametry a vracet hodnoty z poznámkového bloku. Díky tomu můžete vytvářet složité pracovní postupy a kanály se závislostmi. Můžete například získat seznam souborů v adresáři a předat názvy do jiného poznámkového bloku, což není možné s %run. Můžete také vytvořit pracovní postupy if-then-else na základě vrácených hodnot.
Na rozdíl od %runmetody dbutils.notebook.run() spustí novou úlohu pro spuštění poznámkového bloku.
Stejně jako u všech rozhraní API dbutils jsou tyto metody dostupné pouze v Python a Scala. Můžete ale použít dbutils.notebook.run() k vyvolání poznámkového bloku jazyka R.
Použijte %run k importu poznámkového bloku
V tomto příkladu první poznámkový blok definuje funkci, reversekterá je k dispozici v druhém poznámkovém bloku po použití %run magie ke spuštění shared-code-notebook.

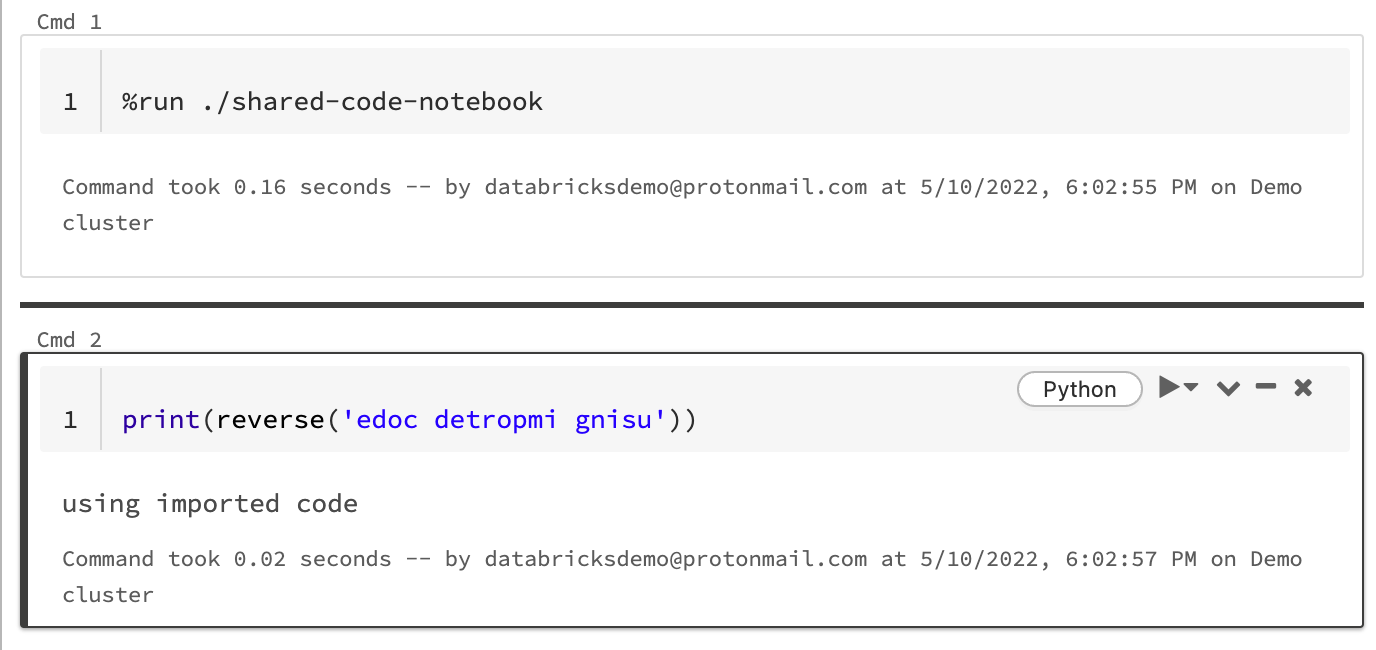
Vzhledem k tomu, že oba poznámkové bloky jsou ve stejném adresáři v pracovním prostoru, použijte předponu ./ v ./shared-code-notebook pro označení, že cesta by měla být vyřešena ve vztahu k aktuálně běžícímu poznámkovému bloku. Poznámkové bloky můžete uspořádat do adresářů, například %run ./dir/notebook, nebo použít absolutní cestu, jako %run /Users/username@organization.com/directory/notebook.
Poznámka:
-
%runmusí být v buňce samostatně, protože běží celý vložený poznámkový blok. - Nelze použít ke spuštění souboru Python ani k importování entit definovaných v daném souboru do poznámkového bloku. Pokud chcete importovat ze souboru Python, přečtěte si téma Modularizace kódu pomocí souborů. Nebo soubor zabalte do knihovny Pythonu, vytvořte Azure Databricks knihovnu z této knihovny Pythonu a nainstalujte knihovnu do clusteru, který používáte ke spuštění svého poznámkového bloku.
- Pokud používáte
%runke spuštění poznámkového bloku obsahujícího widgety, spustí se ve výchozím nastavení zadaný poznámkový blok s výchozími hodnotami widgetu. Můžete také předat hodnoty widgetům; podívejte se na , jak používat widgety Databricks s %run.
Spuštění nové úlohy pomocí dbutils.notebook.run
Spusťte poznámkový blok a vraťte jeho výstupní hodnotu. Metoda zahájí efemérní úlohu, která se spustí okamžitě.
Metody dostupné v dbutils.notebook rozhraní API jsou run a exit. Parametry i návratové hodnoty musí být řetězce.
run(path: String, timeout_seconds: int, arguments: Map): String
Parametr timeout_seconds řídí časový limit spuštění (0 znamená žádný časový limit). Volání na run vyvolá výjimku, pokud se nedokončí v rámci zadaného času. Pokud Azure Databricks po dobu delší než 10 minut nefunguje, spuštění poznámkového bloku selže bez ohledu na timeout_seconds.
Parametr arguments nastaví hodnoty widgetu cílového poznámkového bloku. Konkrétně pokud má spuštěný poznámkový blok widget s názvem Aa předáte dvojici ("A": "B") klíč-hodnota jako součást parametru run() argumentů volání, pak načtení hodnoty widgetu A vrátí "B". Pokyny pro vytváření a práci s widgety najdete na stránce widgetů Databricks .
Poznámka:
- Parametr
argumentspřijímá pouze znaky latinky (znaková sada ASCII). Použití znaků jiného typu než ASCII vrátí chybu. - Úlohy vytvořené pomocí
dbutils.notebookrozhraní API se musí dokončit za 30 dnů nebo méně.
run Použití
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Předávání strukturovaných dat mezi poznámkovými bloky
Tato část ukazuje, jak předávat strukturovaná data mezi poznámkovými bloky.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Řešte chyby
Tato část ukazuje, jak řešit chyby.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Spustit více poznámkových bloků současně
Více poznámkových bloků můžete spustit současně pomocí standardních konstrukcí ve Scala a Python, jako jsou vlákna (Scala, Python) a budoucí výpočty (futures) (Scala, Python). Ukázkové poznámkové bloky ukazují, jak tyto konstrukce používat.
- Stáhněte si následující čtyři poznámkové bloky. Poznámkové bloky jsou napsané v jazyce Scala.
- Naimportujte poznámkové bloky do jedné složky v pracovním prostoru.
- Spusťte poznámkový blok „Spustit souběžně“.
Současné spuštění poznámkového bloku
Získej poznámkový blok
Spustit paralelní poznámkový blok
Získej poznámkový blok
Testovací poznámkový blok
Získej poznámkový blok
Poznámkový blok Testing-2
Získej poznámkový blok