Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Adaptivní spouštění dotazů (AQE) je opětovná optimalizace dotazů, ke které dochází během provádění dotazu.
Motivací pro opětovnou optimalizaci modulu runtime je, že Azure Databricks má na konci výměny náhodného a všesměrového vysílání (označovanou jako fáze dotazu v AQE up-to) nejpřesnější statistiku data. V důsledku toho může Azure Databricks zvolit lepší fyzickou strategii, vybrat optimální velikost a počet oddílů po přerozdělení nebo provést optimalizace, které dříve vyžadovaly tipy, například zpracování nerovnoměrné distribuce při operaci spojení.
To může být velmi užitečné, když shromažďování statistik není zapnuté nebo když jsou statistiky zastaralé. Je také užitečná na místech, kde staticky odvozené statistiky nejsou přesné, například uprostřed složitého dotazu nebo po výskytu nerovnoměrné distribuce dat.
Schopnosti
Funkce AQE je ve výchozím nastavení povolená. Má 4 hlavní funkce:
- Dynamicky změní třídící sloučené spojení na hash spojení s všesměrovým přenosem.
- Dynamicky slučuje oddíly (kombinování malých oddílů do rozumně velkých oddílů) po shuffle výměně. Velmi malé úlohy mají horší propustnost vstupně-výstupních operací a mají tendenci mít větší nároky na plánování režie a nastavení úloh. Kombinace malých úloh šetří prostředky a zlepšuje propustnost clusteru.
- Dynamicky zpracovává distribuční zkreslení v operacích spojení přes řazení a shuffle hash spojení tím, že rozděluje (a replikací v případě potřeby) úkoly se zkreslením do zhruba rovnoměrně velkých úkolů.
- Dynamicky rozpoznává a šíří prázdné relace.
Aplikace
AQE se vztahuje na všechny dotazy, které jsou:
- Bez streamování
- Obsahují aspoň jednu výměnu (obvykle v případě spojení, agregace nebo okna), jednoho dílčího dotazu nebo obojího.
Ne všechny dotazy použité na AQE jsou nutně znovu optimalizované. Opětovná optimalizace může nebo nemusí přijít s jiným plánem dotazu, než je plán dotazu staticky zkompilovaný. Pokud chcete zjistit, jestli plán dotazu AQE změnil, přečtěte si následující část Plány dotazů.
Plány dotazů
Tato část popisuje, jak můžete prozkoumat plány dotazů různými způsoby.
V této části:
Uživatelské rozhraní Sparku
uzel AdaptiveSparkPlan
Použité dotazy AQE obsahují jeden nebo více AdaptiveSparkPlan uzlů, obvykle jako kořenový uzel každého hlavního dotazu nebo dílčího dotazu.
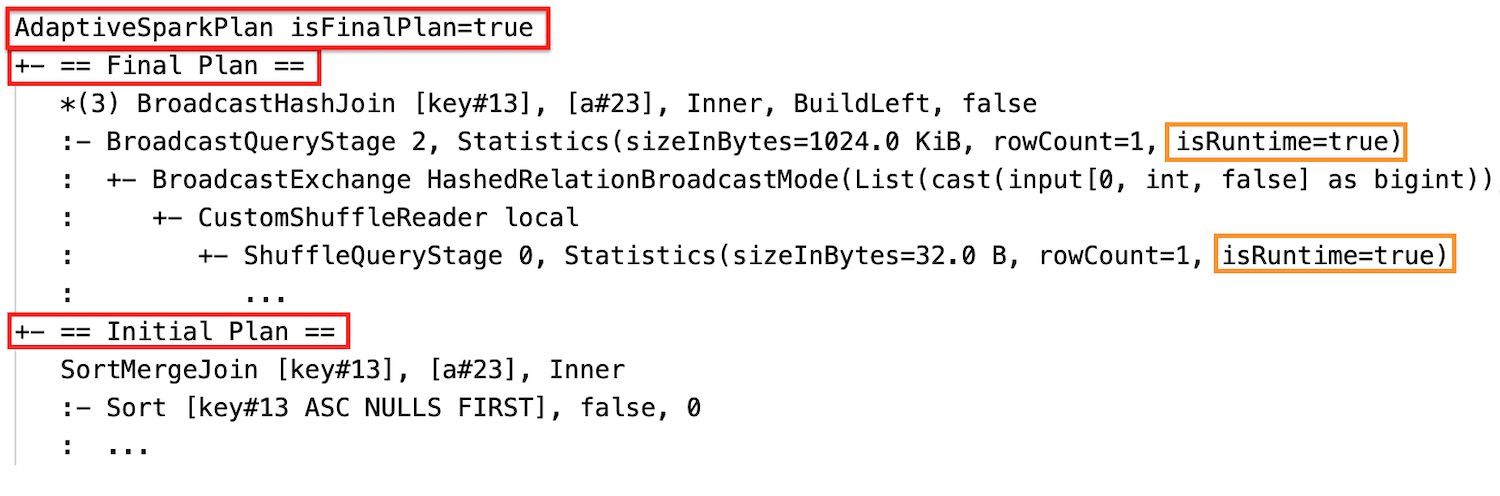
Před spuštěním dotazu nebo jeho spuštěním se příznak isFinalPlan odpovídajícího uzlu AdaptiveSparkPlan zobrazí jako false; po dokončení provádění dotazu se isFinalPlan příznakem změní na true.
Vývojový plán
Diagram plánu dotazu se vyvíjí s průběhem provádění a odráží nejaktuálnější plán, který se provádí. Uzly, které už byly spuštěny (ve kterých jsou k dispozici metriky), se nezmění, ale ty, které nebyly, se mohou v průběhu času změnit v důsledku opětovných optimalizací.
Následuje příklad diagramu plánu dotazu:
diagram plánu dotazu 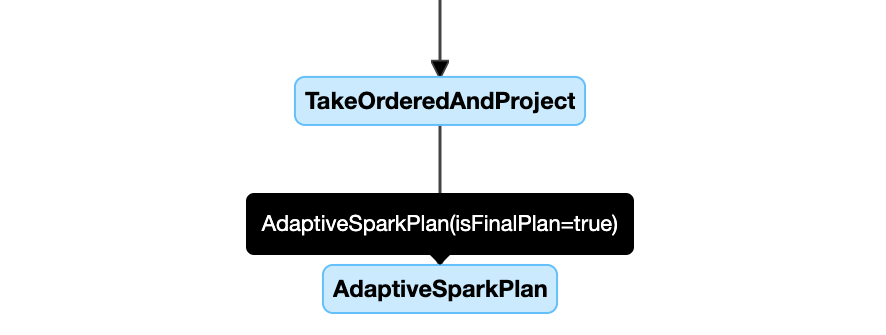
DataFrame.explain()
uzel AdaptiveSparkPlan
Použité dotazy AQE obsahují jeden nebo více AdaptiveSparkPlan uzlů, obvykle jako kořenový uzel každého hlavního dotazu nebo dílčího dotazu. Před spuštěním dotazu nebo jeho spuštěním se příznak isFinalPlan odpovídajícího uzlu AdaptiveSparkPlan zobrazí jako false; po dokončení provádění dotazu se isFinalPlan příznak změní na true.
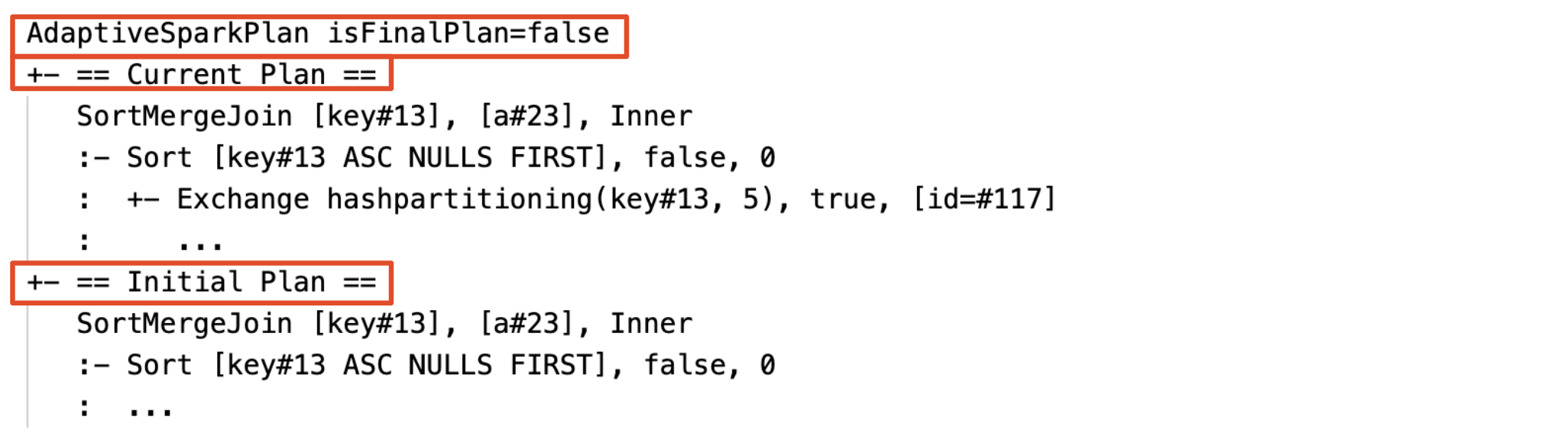
Aktuální a počáteční plán
V každém AdaptiveSparkPlan uzlu bude počáteční plán (plán před použitím optimalizace AQE) i aktuální nebo konečný plán v závislosti na tom, jestli se provádění dokončilo. Aktuální plán se bude vyvíjet v průběhu provádění.
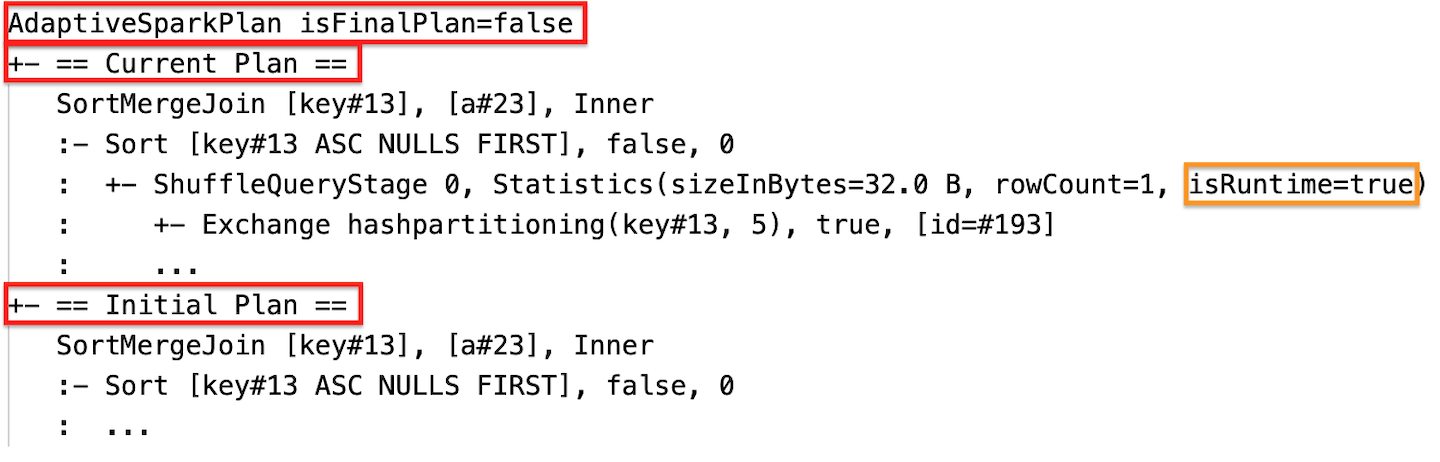
Statistika modulu runtime
Každá fáze prohazování a vysílání obsahuje statistiky dat.
Před spuštěním nebo během spuštění fáze jsou statistiky odhady času kompilace a příznak isRuntime je false, například: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Po dokončení provádění fáze jsou statistiky ty, které byly shromážděny za běhu, a příznak isRuntime se změní na true, například: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Následuje příklad DataFrame.explain:
Před provedením
Během provádění
Po vykonání
SQL EXPLAIN
uzel AdaptiveSparkPlan
Použité dotazy AQE obsahují jeden nebo více uzlů AdaptiveSparkPlan, obvykle jako kořenový uzel každého hlavního dotazu nebo dílčího dotazu.
Žádný aktuální plán
Protože SQL EXPLAIN dotaz nespustí, aktuální plán je vždy stejný jako počáteční plán a neodráží, co by nakonec provedl AQE.
Následuje příklad vysvětlení SQL:

Efektivnost
Plán dotazu se změní, pokud se projeví jedna nebo více optimalizací AQE. Účinek těchto optimalizací AQE je demonstrován rozdílem mezi aktuálními a konečnými plány a počátečním plánem a konkrétními uzly plánu v aktuálních a konečných plánech.
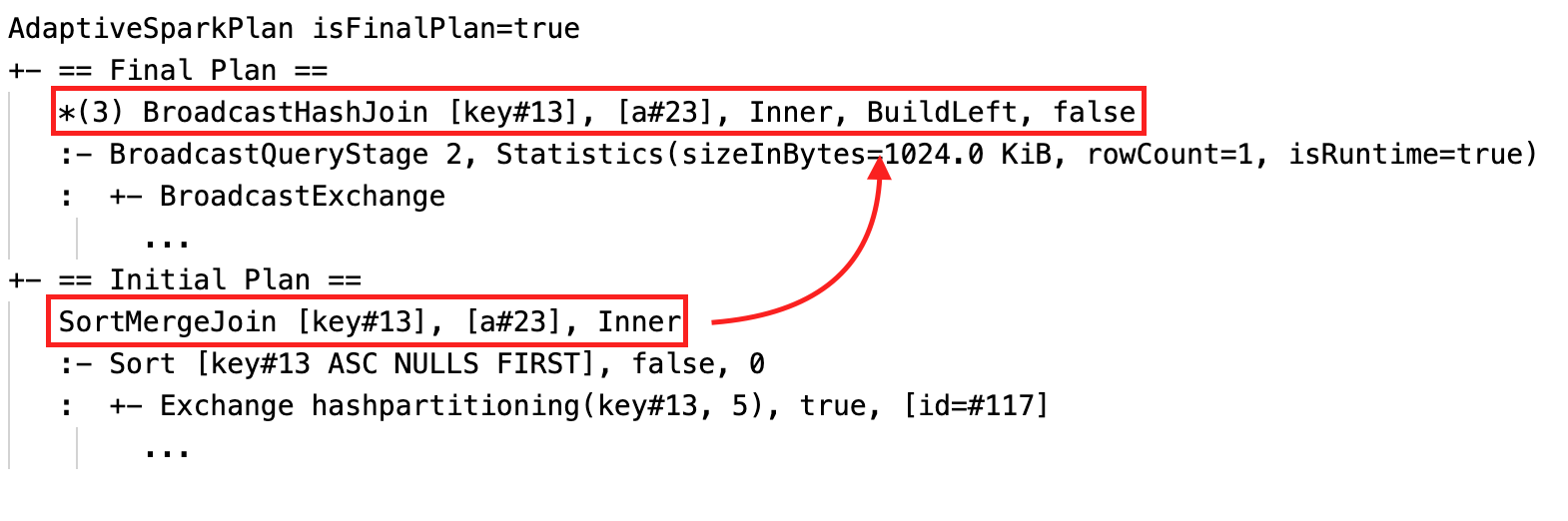
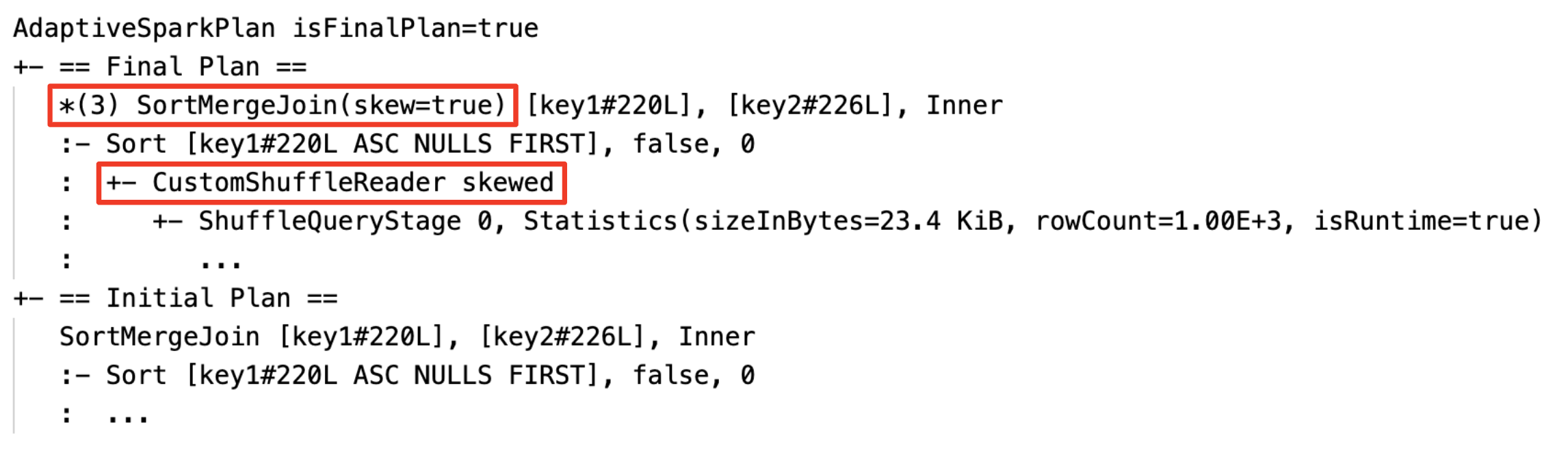
Dynamická změna třídicího slučovacího spojení na spojení hash vysílání: různé fyzické uzly spojení mezi aktuálním/konečným plánem a počátečním plánem
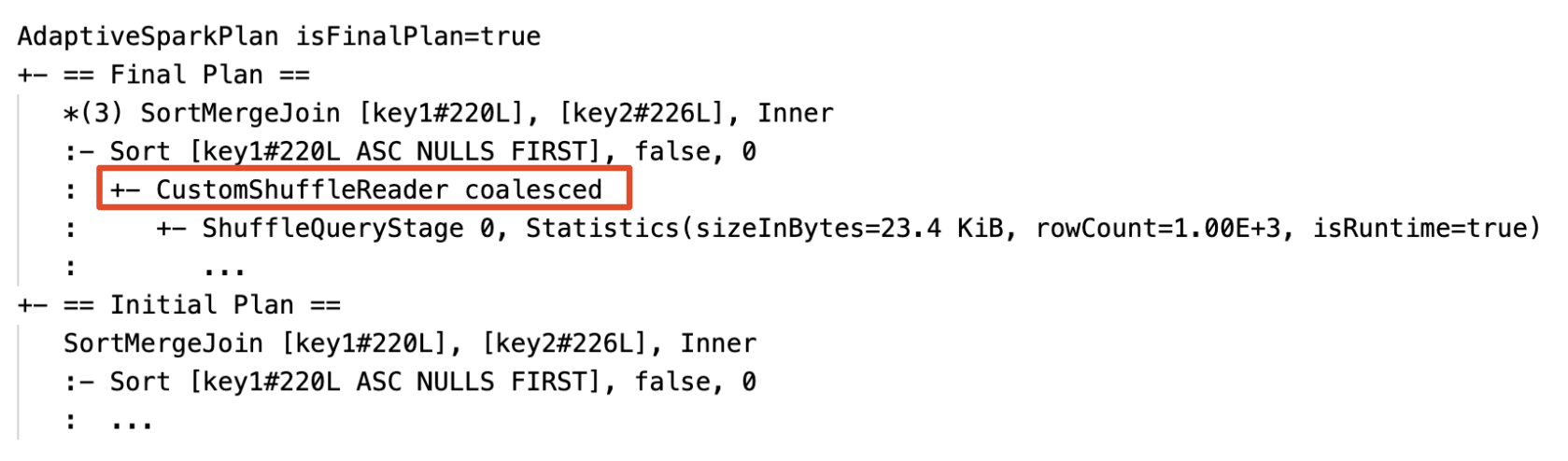
Dynamicky slučovací oddíly: uzly
CustomShuffleReaders vlastnostíCoalesced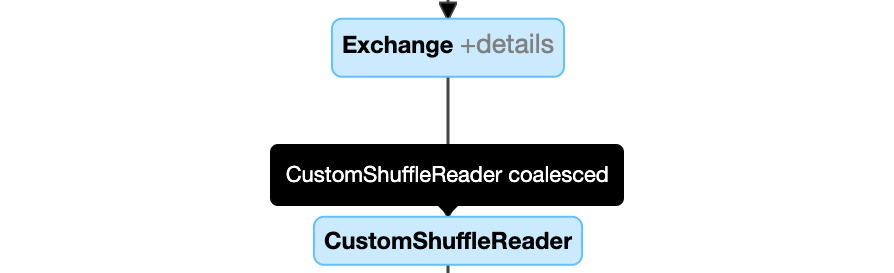
Dynamické zpracování spojení s nerovnoměrným rozložením: uzel
SortMergeJoins polemisSkewjako pravda.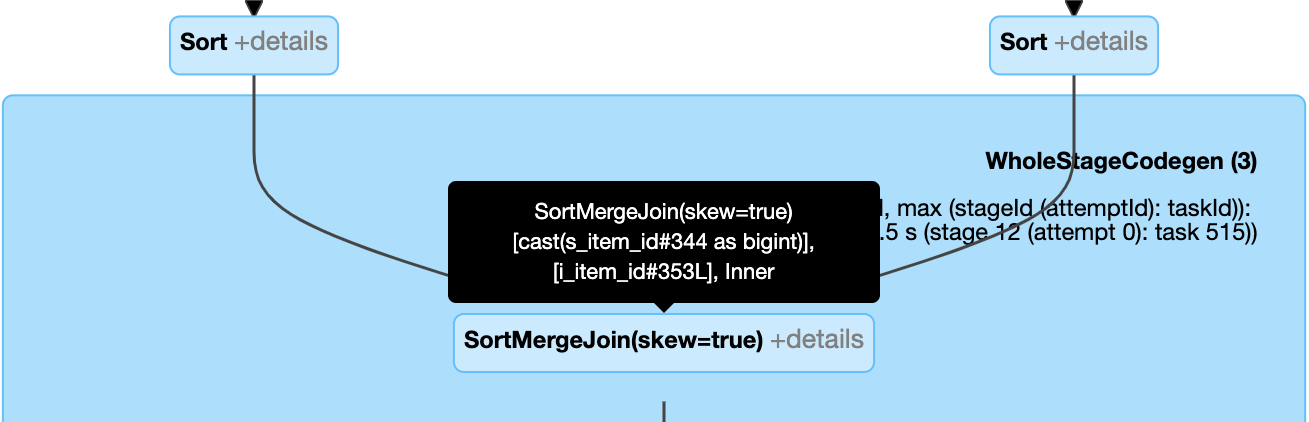
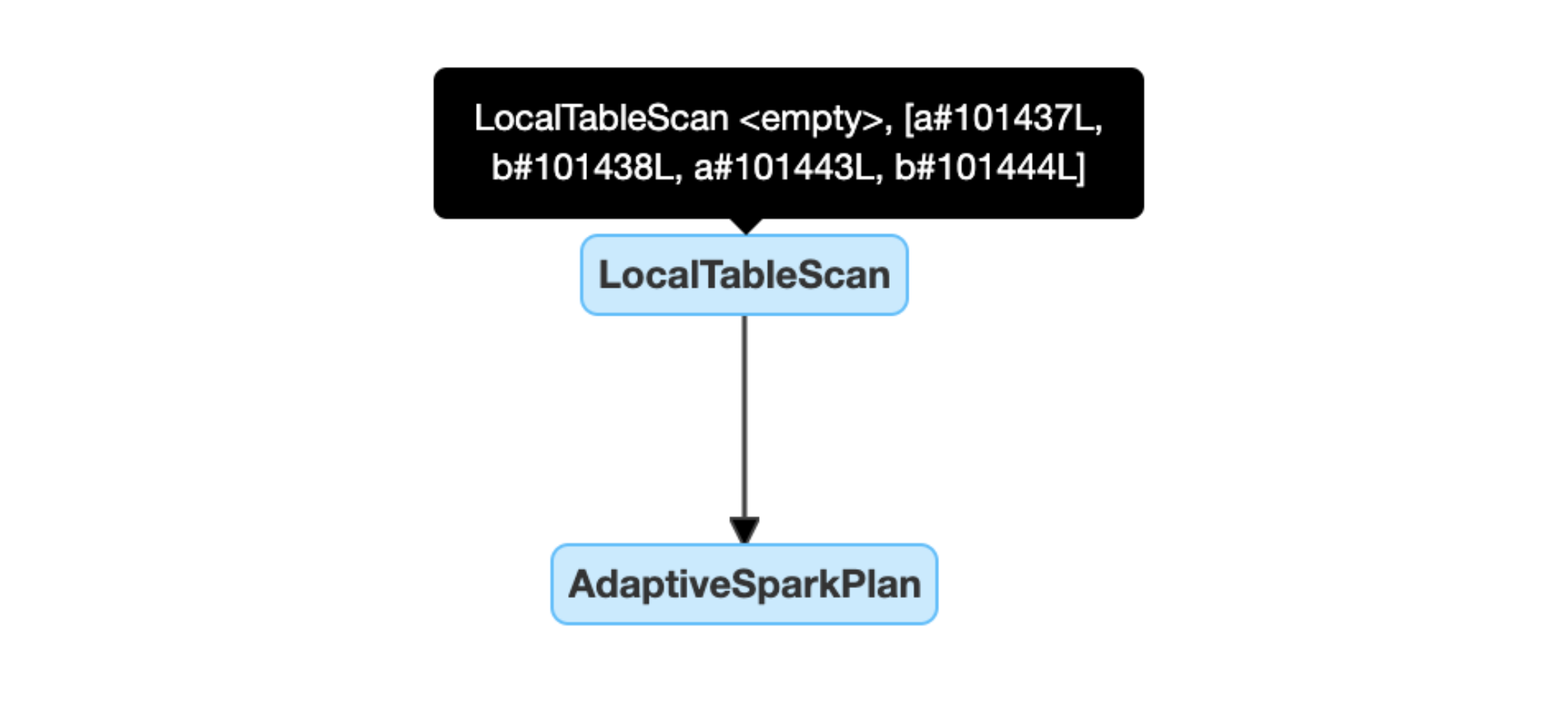
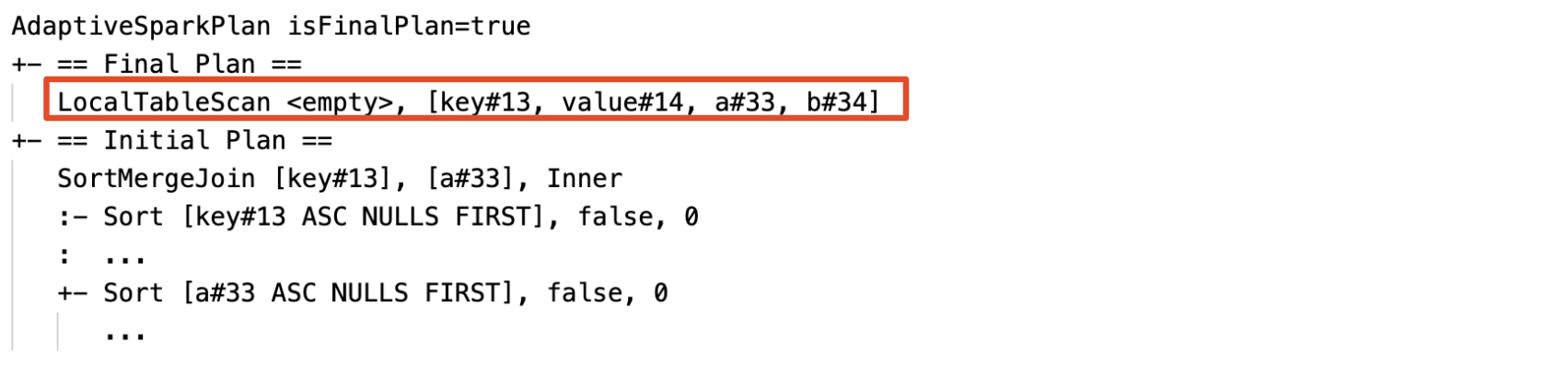
Dynamicky rozpozná a šíří prázdné relace: část (nebo celý) plán se nahradí uzlem LocalTableScan s prázdným relačním polem.
Konfigurace
V této části:
- Povolení a zakázání adaptivního spouštění dotazů
- Povolit automaticky optimalizované prohazování
- Dynamicky měnit třídicí spojení sloučení na haš spojení všesměrovým vysíláním
- dynamicky slučovat oddíly
- dynamicky zpracovávat nerovnoměrné spojení
- dynamické zjišťování a šíření prázdných relací
Povolení a zakázání adaptivního spouštění dotazů
| Vlastnost |
|---|
|
spark.databricks.optimizer.adaptive.enabled Typ: BooleanUrčuje, jestli chcete povolit nebo zakázat adaptivní spouštění dotazů. Výchozí hodnota: true |
Povolit automatickou optimalizovanou změnu pořadí
| Vlastnost |
|---|
|
spark.sql.shuffle.partitions Typ: IntegerVýchozí počet oddílů, které se mají použít při přeskupení dat pro spojování nebo agregaci. Nastavení hodnoty auto umožňuje automatizované optimalizované řazení, které automaticky určuje toto číslo na základě plánu dotazu a velikosti vstupních dat dotazu.Poznámka: U strukturovaného streamování nelze tuto konfiguraci změnit mezi restartováními dotazů ze stejného umístění kontrolního bodu. Výchozí hodnota: 200 |
Dynamická změna spojení třídění a sloučení na hash spojení s všesměrovým přenosem
| Vlastnost |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Typ: Byte StringPrahová hodnota pro aktivaci přepnutí na broadcast join během provádění. Výchozí hodnota: 30MB |
Dynamicky zlučovat oddíly
| Vlastnost |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Typ: BooleanUrčuje, jestli chcete povolit nebo zakázat slučování oddílů. Výchozí hodnota: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Typ: Byte StringCílová velikost po sloučení. Velikosti sloučených oddílů se budou blížit této cílové velikosti, ale nebudou ji přesahovat. Výchozí hodnota: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Typ: Byte StringMinimální velikost oddílů po sjednocení. Velikosti sloučených oddílů nebudou menší než tato velikost. Výchozí hodnota: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Typ: IntegerMinimální počet oddílů po sloučení. Nedoporučuje se, protože explicitní nastavení má přednost spark.sql.adaptive.coalescePartitions.minPartitionSize.Výchozí hodnota: 2x počet jader clusteru |
Dynamické zpracování zkoseného spojení
| Vlastnost |
|---|
|
spark.sql.adaptive.skewJoin.enabled Typ: BooleanJestli chcete povolit nebo zakázat zpracování šikmého spojení. Výchozí hodnota: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Typ: IntegerFaktor, který při vynásobení střední velikostí oddílu přispívá k určení, zda je oddíl zkosený. Výchozí hodnota: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Typ: Byte StringPrahová hodnota, která přispívá k určení, jestli je oddíl nerovnoměrný. Výchozí hodnota: 256MB |
Oddíl se považuje za nerovnoměrnou distribuci, pokud jsou (partition size > skewedPartitionFactor * median partition size) i (partition size > skewedPartitionThresholdInBytes)true.
Dynamické zjišťování a šíření prázdných relací
| Vlastnost |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Typ: BooleanUrčuje, jestli chcete povolit nebo zakázat šíření dynamické prázdné relace. Výchozí hodnota: true |
Nejčastější dotazy
V této části:
- Proč AQE nevysílala malou tabulku spojení?
- Mám stále používat nápovědu ke strategii připojení k vysílání s povolenou funkcí AQE?
- Jaký je rozdíl mezi doporučením pro zkosení spojení a optimalizací zkosených spojení při Adaptivním dotazovém provádění (AQE)? Který z nich mám použít?
- Proč AQE automaticky neupravoval pořadí připojení?
- Proč AQE nerozpoznal nerovnoměrnou distribuci dat?
Proč AQE nevysílala malou tabulku spojení?
Pokud velikost relace, která má být vysílána, spadá pod tuto prahovou hodnotu, ale stále není vysílána:
- Zkontrolujte typ spojení. Vysílání není podporováno pro určité typy spojení, například levý vztah
LEFT OUTER JOINnelze vysílat. - Může se také stát, že relace obsahuje mnoho prázdných oddílů, v takovém případě může většina úkolů rychle dokončit díky spojení se sloučením řazení, nebo může být případně optimalizována zpracováním nerovnoměrného spojení. AQE zabraňuje změně takových spojení typu sort-merge na hashová spojení typu broadcast, pokud je procento neprázdných oddílů nižší než
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Mám stále používat nápovědu ke strategii připojení k vysílání s povolenou funkcí AQE?
Ano. Staticky plánované spojení typu 'broadcast' je obvykle výkonnější než dynamicky plánované spojení pomocí AQE, protože AQE nemusí přejít na spojení typu 'broadcast', dokud není provedeno promíchání pro obě strany spojení (v tomto okamžiku jsou získány skutečné velikosti relací). Pokud tedy znáte svůj dotaz dobře, může být použití nápovědy vysílání stále dobrou volbou. AQE bude respektovat nápovědy pro dotazy stejným způsobem jako statická optimalizace, nicméně může používat dynamické optimalizace, které nejsou těmito nápovědami ovlivněny.
Jaký je rozdíl mezi doporučením pro zkosení spojení a optimalizací zkosených spojení při Adaptivním dotazovém provádění (AQE)? Který z nich mám použít?
Doporučuje se spoléhat na zpracování spojení se zkosenou distribucí v AQE místo použití nápovědy ke spojení se zkosenou distribucí, protože AQE spojení se zkosenou distribucí je zcela automatické a obecně funguje lépe než varianta s nápovědou.
Proč AQE automaticky neupravoval pořadí připojení?
Dynamické přeuspořádání spojení není součástí AQE.
Proč AQE nerozpoznal nerovnoměrnou distribuci dat?
Aby AQE mohl identifikovat oddíl jako nevyvážený, musí být splněny dvě podmínky velikosti:
- Velikost oddílu je větší než
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(výchozí 256 MB) - Velikost oddílu je větší než medián velikosti všech oddílů vynásobený nerovnoměrným faktorem oddílu
spark.sql.adaptive.skewJoin.skewedPartitionFactor(výchozí 5).
Kromě toho je podpora zpracování nerovnoměrné distribuce omezená pro určité typy spojení, například v LEFT OUTER JOIN, lze optimalizovat pouze nerovnoměrnou distribuci na levé straně.
Dědictví
Pojem Adaptivní spouštění existoval od Sparku 1.6, ale nový AQE ve Sparku 3.0 se zásadně liší. Z hlediska funkčnosti Spark 1.6 pouze část "dynamicky slučuje oddíly". Z hlediska technické architektury je nová architektura AQE architekturou dynamického plánování a opětovného plánování dotazů na základě statistik modulu runtime, která podporuje řadu optimalizací, jako jsou ty, které jsme popsali v tomto článku, a lze je rozšířit, aby bylo možné optimalizovat více potenciálních optimalizací.