Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tato stránka obsahuje přehled nástrojů a přístupů k exportu dat a konfigurace z pracovního prostoru Azure Databricks. Prostředky pracovního prostoru můžete exportovat pro požadavky na dodržování předpisů, přenositelnost dat, účely zálohování nebo migraci pracovního prostoru.
Přehled
Pracovní prostory Azure Databricks obsahují celou řadu prostředků, včetně konfigurace pracovního prostoru, spravovaných tabulek, objektů AI a ML a dat uložených v cloudovém úložišti. Pokud potřebujete exportovat data pracovního prostoru, můžete k automatickému extrahování těchto prostředků použít kombinaci integrovaných nástrojů a rozhraní API.
Mezi běžné důvody exportu dat pracovního prostoru patří:
- Požadavky na dodržování předpisů: Plnění povinností přenositelnosti dat podle nařízení, jako jsou GDPR a CCPA.
- Zálohování a zotavení po havárii: Vytváření kopií důležitých prostředků pracovního prostoru pro zajištění provozní kontinuity
- Migrace pracovního prostoru: Přesun prostředků mezi pracovními prostory nebo poskytovateli cloudu
- Audit a archivace: Zachování historických záznamů konfigurace a dat pracovního prostoru
Plánování exportu
Než začnete exportovat data pracovního prostoru, vytvořte inventář prostředků, které potřebujete exportovat, a seznamte se se závislostmi mezi nimi.
Pochopte prostředky pracovního prostoru
Váš pracovní prostor Azure Databricks obsahuje několik kategorií prostředků, které můžete exportovat:
- Konfigurace pracovního prostoru: Poznámkové bloky, složky, úložiště, tajné kódy, uživatelé, skupiny, seznamy řízení přístupu (ACL), konfigurace clusteru a definice úloh.
- Datové prostředky: Spravované tabulky, databáze, soubory systému souborů Databricks a data uložená v cloudovém úložišti.
- Výpočetní prostředky: Konfigurace clusteru, zásady a definice fondu instancí.
- Prostředky AI a ML: experimenty MLflow, běhy, modely, tabulky úložiště funkcí, indexy vektorového vyhledávání a modely katalogu Unity.
- Objekty katalogu Unity: Konfigurace metastoru, katalogy, schémata, tabulky, svazky a oprávnění.
Určení rozsahu exportu
Vytvořte kontrolní seznam prostředků pro export na základě vašich požadavků. Zvažte tyto otázky:
- Potřebujete exportovat všechny prostředky nebo jenom určité kategorie?
- Existují požadavky na dodržování předpisů nebo zabezpečení, které určují, které prostředky musíte exportovat?
- Potřebujete udržet vztahy mezi aktivy (například úlohami, které odkazují na poznámkové bloky)?
- Potřebujete znovu vytvořit konfiguraci pracovního prostoru v jiném prostředí?
Plánování rozsahu exportu vám pomůže zvolit správné nástroje a vyhnout se chybějícím kritickým závislostem.
Export konfigurace pracovního prostoru
Exportér Terraformu je primárním nástrojem pro export konfigurace pracovního prostoru. Generuje konfigurační soubory Terraformu, které představují vaše prostředky pracovního prostoru jako kód.
Použijte exportér Terraformu
Exportér Terraformu je integrovaný do poskytovatele Azure Databricks Terraform a generuje konfigurační soubory Terraformu pro prostředky pracovního prostoru, včetně poznámkových bloků, úloh, clusterů, uživatelů, skupin, tajných kódů a seznamů řízení přístupu. Exportní nástroj musí být spuštěn samostatně pro každý pracovní prostor. Viz poskytovatel Databricks Terraform.
Požadavky:
- Terraform nainstalovaný na vašem počítači
- Ověřování Azure Databricks nakonfigurované
- Oprávnění správce v pracovním prostoru, který chcete exportovat
Export prostředků pracovního prostoru:
Zhlédněte ukázkové video o použití pro podrobný průvodce exportérem.
Stáhněte a nainstalujte poskytovatele Terraformu pomocí nástroje pro exportér:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipNastavte proměnné prostředí ověřování pro váš pracovní prostor:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenSpuštěním exportéru vygenerujte konfigurační soubory Terraformu:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsSpolečné možnosti vývozce:
-
-listing: Zadejte typy prostředků, které se mají exportovat (oddělené čárkami). -
-services: Alternativa k seznamu pro filtrování zdrojů -
-directory: Výstupní adresář pro vygenerované.tfsoubory -
-incremental: Spuštění v přírůstkovém režimu pro fázované migrace
-
Zkontrolujte vygenerované
.tfsoubory ve výstupním adresáři. Vývozce vytvoří jeden soubor pro každý typ prostředku.
Poznámka:
Exportér Terraformu se zaměřuje na konfiguraci a metadata pracovního prostoru. Neexportuje skutečná data uložená v tabulkách nebo systému souborů Databricks. Data musíte exportovat samostatně pomocí přístupů popsaných v následujících částech.
Exportovat specifické typy prostředků
Pro prostředky, které vývozce Terraformu plně nepokrýval, použijte tyto přístupy:
- Poznámkové bloky: Poznámkové bloky si můžete stáhnout jednotlivě z uživatelského rozhraní pracovního prostoru nebo použít rozhraní API pracovního prostoru k programovému exportu poznámkových bloků. Viz Správa objektů pracovního prostoru.
- Tajné kódy: Tajné kódy nejde exportovat přímo z bezpečnostních důvodů. Tajné kódy musíte ručně vytvořit v cílovém prostředí. Názvy a rozsahy důvěrných dokumentů pro referenční účely.
- Objekty MLflow: Pomocí nástroje mlflow-export-import můžete exportovat experimenty, běhy a modely. Podívejte se na sekci aktiv ML níže.
Export dat
Zákaznická data se obvykle nacházejí v úložišti cloudového účtu, ne v Azure Databricks. Nemusíte exportovat data, která už jsou ve vašem cloudovém úložišti. Musíte ale exportovat data uložená v umístěních spravovaných službou Azure Databricks.
Export spravovaných tabulek
I když se spravované tabulky nachází v cloudovém úložišti, ukládají se v hierarchii založené na UUID, která může být obtížné analyzovat. Příkaz můžete použít DEEP CLONE k přepsání spravovaných tabulek jako externích tabulek v zadaném umístění, což usnadňuje práci s nimi.
Ukázkové DEEP CLONE příkazy:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Úplný skript pro klonování všech tabulek v seznamu katalogů najdete v následujícím ukázkovém skriptu.
Export výchozího úložiště Databricks
Pro bezserverové pracovní prostory nabízí Azure Databricks výchozí úložiště, což je plně spravované řešení úložiště v rámci účtu Azure Databricks. Data ve výchozím úložišti musí být před odstraněním nebo vyřazením pracovního prostoru exportována do kontejnerů úložiště vlastněných zákazníkem. Další informace o bezserverových pracovních prostorech najdete v tématu Vytvoření bezserverového pracovního prostoru.
Pro tabulky ve výchozím úložišti použijte DEEP CLONE k zápisu dat do kontejneru úložiště vlastněného zákazníkem. U svazků a libovolných souborů postupujte podle stejných vzorů popsaných v části pro kořenový export DBFS níže.
Exportovat kořenový adresář systému souborů Databricks
Kořen systému souborů Databricks je starší umístění úložiště ve vašem účtu úložiště pracovního prostoru, které může obsahovat prostředky vlastněné zákazníkem, nahrávání uživatelů, inicializační skripty, knihovny a tabulky. I když kořen systému souborů Databricks je zastaralý vzor úložiště, starší pracovní prostory můžou mít stále uložená data v tomto umístění, která je potřeba exportovat. Další informace o architektuře úložiště pracovních prostorů najdete v tématu Úložiště pracovního prostoru.
Export kořenového adresáře systému souborů Databricks:
Vzhledem k tomu, že kořenové kontejnery v Azure jsou soukromé, nemůžete používat nástroje nativní pro Azure, jako je azcopy přesun dat mezi účty úložiště. Místo toho použijte dbutils fs cp a delta DEEP CLONE v Azure Databricks. V závislosti na objemu dat to může trvat delší dobu.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Pro tabulky v kořenovém úložišti systému souborů Databricks použijte DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Důležité
Při exportu velkých objemů dat z cloudového úložiště může docházet k významným nákladům na přenos dat a úložiště. Před zahájením velkých exportů zkontrolujte ceny poskytovatele cloudu.
Běžné problémy s exportem
Tajemství:
Tajné kódy nelze exportovat přímo z bezpečnostních důvodů. Při použití exportéru Terraformu -export-secrets s touto možností generuje exportér proměnnou vars.tf se stejným názvem jako tajemství. Tento soubor musíte ručně aktualizovat skutečnými tajnými hodnotami nebo spustit exportér Terraformu s možností -export-secrets (toto platí pouze pro tajné kódy spravované službou Azure Databricks).
Azure Databricks doporučuje používat úložiště tajných kódů založené na službě Azure Key Vault.
Export prostředků AI a ML
Některé prostředky AI a ML vyžadují různé nástroje a přístupy k exportu. Modely katalogu Unity se exportují jako součást exportéru Terraformu.
Objekty MLflow
Exportér Terraformu se na MLflow nevztahuje kvůli mezerám v rozhraní API a potížím se serializací. K exportu experimentů, běhů, modelů a artefaktů MLflow použijte nástroj mlflow-export-import. Tento opensourcový nástroj poskytuje částečně kompletní pokrytí migrace MLflow.
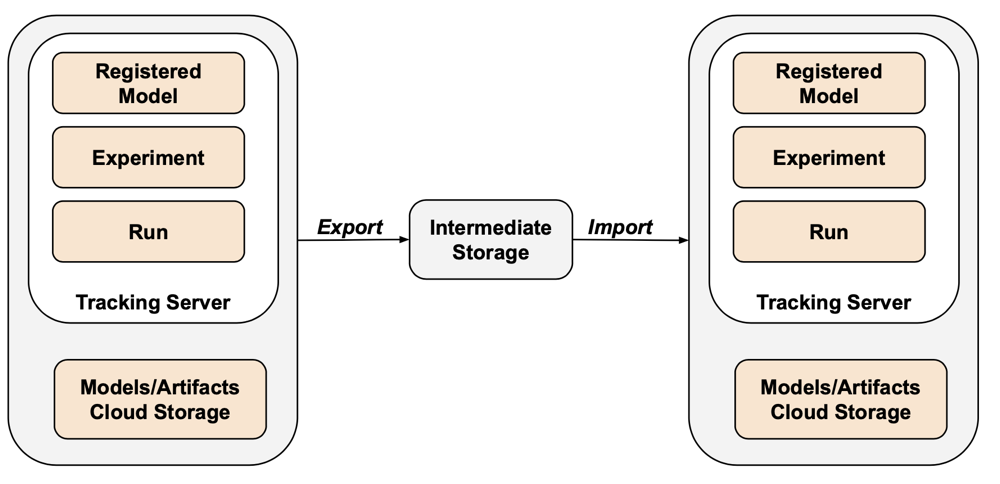
V případě scénářů jen pro export můžete ukládat všechny prostředky MLflow do kontejneru vlastněného zákazníkem, aniž byste museli provést krok importu. Další informace o správě MLflow naleznete v tématu Správa životního cyklu modelu v Katalogu Unity.
Úložiště funkcí a vektorové vyhledávání
Indexy vektorového vyhledávání: Indexy vektorového vyhledávání nejsou v rozsahu postupů exportu dat EU. Pokud byste je přesto chtěli exportovat, musí se zapsat do standardní tabulky a pak je exportovat pomocí DEEP CLONE.
Tabulky úložiště funkcí: Úložiště funkcí by se mělo zacházet podobně jako s indexy vektorového vyhledávání. Pomocí SQL vyberte relevantní data a zapište je do standardní tabulky a pak exportujte pomocí DEEP CLONE.
Ověření exportovaných dat
Po exportu dat pracovního prostoru ověřte, že se úlohy, uživatele, poznámkové bloky a další prostředky správně exportovaly před vyřazením starého prostředí z provozu. Pomocí kontrolního seznamu, který jste vytvořili během fáze rozsahu a plánování, ověřte, že vše, co jste očekávali k exportu, bylo úspěšně exportováno.
Kontrolní seznam pro ověření
Pomocí tohoto kontrolního seznamu ověřte export:
- Vygenerované konfigurační soubory: Konfigurační soubory Terraformu se vytvoří pro všechny požadované prostředky pracovního prostoru.
- Exportované poznámkové bloky: Všechny poznámkové bloky se exportují s jejich obsahem a metadaty beze změny.
- Klonované tabulky: Spravované tabulky se úspěšně naklonují do umístění exportu.
- Zkopírované datové soubory: Data cloudového úložiště se zkopírují zcela bez chyb.
- Exportované objekty MLflow: Experimenty, běhy a modely jsou exportovány s jejich artefakty.
- Dokumentace oprávnění: Seznamy a oprávnění řízení přístupu se zaznamenávají v konfiguraci Terraformu.
- Identifikované závislosti: Vztahy mezi prostředky (například úlohy odkazující na poznámkové bloky) se v exportu zachovají.
Osvědčené postupy po exportu
Ověřování a akceptační testování je z velké části řízeno vašimi požadavky a může se značně lišit. Platí však tyto obecné osvědčené postupy:
- Definování testovacího prostředí: Vytvoření testovacího prostředí úloh nebo poznámkových bloků, které ověřují, že tajné kódy, data, připojení, konektory a další závislosti fungují správně v exportovaném prostředí.
- Začněte s vývojovými prostředími: Pokud se přesouváte fázovaným způsobem, začněte s vývojovým prostředím a pracujte až do produkčního prostředí. Tím se v rané fázi zobrazí hlavní problémy a vyhnete se produkčním dopadům.
- Využití složek Git: Pokud je to možné, používejte složky Git, protože jsou v externím úložišti Git. Tím se vyhnete ručnímu exportu a zajistíte, že kód bude v různých prostředích stejný.
- Zdokumentujte proces exportu: Poznamenejte si použité nástroje, spouštěné příkazy a případné problémy.
- Zabezpečená exportovaná data: Zajistěte, aby se exportovaná data bezpečně ukládaly s příslušnými řízeními přístupu, zejména pokud obsahují citlivé nebo identifikovatelné osobní údaje.
- Zachovat dodržování předpisů: Pokud exportujete pro účely dodržování předpisů, ověřte, že export splňuje zákonné požadavky a zásady uchovávání informací.
Ukázkové skripty a automatizace
Exporty pracovních prostorů můžete automatizovat pomocí skriptů a plánovaných úloh.
Skript pro export hloubkového klonování
Následující skript exportuje spravované tabulky Unity Catalog pomocí DEEP CLONE. Tento kód by se měl spustit ve zdrojovém pracovním prostoru pro export daného katalogu do přechodného kontejneru. Aktualizujte proměnné catalogs_to_copy a dest_bucket.
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Důležité informace o automatizaci
Při automatizaci exportů:
- Použití plánovaných úloh: Vytvořte úlohy Azure Databricks, které spouští export skripty podle běžného plánu.
- Monitorování úloh exportu: Nakonfigurujte výstrahy, které vás upozorní, pokud se export nezdaří nebo trvá déle, než se čekalo.
- Správa přihlašovacích údajů: Bezpečně ukládejte přihlašovací údaje cloudového úložiště a tokeny rozhraní API pomocí tajných kódů Azure Databricks. Viz správa tajemství.
- Exporty verzí: K udržování historických exportů použijte časová razítka nebo čísla verzí v cestách exportu.
- Vyčištění starých exportů: Implementujte zásady uchovávání informací pro odstranění starých exportů a správu nákladů na úložiště.
- Přírůstkové exporty: U velkých pracovních prostorů zvažte implementaci přírůstkových exportů, které od posledního exportu exportují jenom změněná data.