Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak vytvářet koncové body a indexy vektorového vyhledávání pomocí Funkce vektorového vyhledávání v systému Mosaic AI.
Pomocí uživatelského rozhraní, Python SDKnebo rozhraní REST APImůžete vytvářet a spravovat komponenty vektorového vyhledávání, jako je koncový bod vektorového vyhledávání a indexy vektorového vyhledávání.
Například poznámkové bloky znázorňující, jak vytvářet a dotazovat se na koncové body vektorového vyhledávání, viz ukázkové poznámkové bloky vektorového vyhledávání. Referenční informace najdete v referenčních informacích k sadě Python SDK.
Požadavky
- Pracovní prostor s aktivovaným katalogem Unity
- Bezserverové výpočetní prostředky jsou povolené. Pokyny najdete v tématu Připojení k výpočetním prostředkům bez serveru.
- U standardních koncových bodů musí mít zdrojová tabulka povolený kanál změn dat. Vizte Kanál změn dat v Delta Lake na Azure Databricks.
- Pokud chcete vytvořit index vektorového vyhledávání, musíte mít oprávnění CREATE TABLE ve schématu katalogu, kde bude index vytvořen.
- Pokud chcete dotazovat index vlastněný jiným uživatelem, musíte mít další oprávnění. Podívejte se, jak dotazovat index vektorového vyhledávání.
Oprávnění k vytváření a správě koncových bodů vektorového vyhledávání se konfiguruje pomocí seznamů řízení přístupu. Viz ACL koncového bodu pro vektorové vyhledávání.
Installation
Pokud chcete použít sadu SDK pro vektorové vyhledávání, musíte ji nainstalovat do notebooku. K instalaci balíčku použijte následující kód:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Potom pomocí následujícího příkazu naimportujte VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Informace o ověřování najdete v tématu Ochrana a ověřování dat.
Vytvoření koncového bodu vektorového vyhledávání
Koncový bod vektorového vyhledávání můžete vytvořit pomocí uživatelského rozhraní Databricks, sady Python SDK nebo rozhraní API.
Vytvoření koncového bodu vektorového vyhledávání pomocí uživatelského rozhraní
Pomocí těchto kroků vytvořte koncový bod vektorového vyhledávání pomocí uživatelského rozhraní.
V levém bočním panelu klikněte na Výpočet.
Klikněte na kartu Vyhledávání vektoru a klikněte na Vytvořit.

Otevře se formulář Vytvořit koncový bod. Zadejte název tohoto koncového bodu.
Dialogové okno pro vytvoření koncového bodu pro vektorové vyhledávání
V poli Typ vyberte Standard nebo Optimalizováno pro úložiště. Viz možnosti koncového bodu.
(Volitelné) V části Upřesnit nastavení vyberte zásadu rozpočtu. Viz Mosaic AI Vector Search: Zásady rozpočtu.
Klikněte na Potvrdit.
Vytvoření koncového bodu vektorového vyhledávání pomocí sady Python SDK
Následující příklad používá funkci create_endpoint() SDK k vytvoření koncového bodu vektorového vyhledávání.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Vytvoření koncového bodu vektorového vyhledávání pomocí rozhraní REST API
Projděte si referenční dokumentaci k rozhraní REST API: POST /api/2.0/vector-search/endpoints.
(Volitelné) Vytvoření a konfigurace koncového bodu pro obsluhu modelu vkládání
Pokud se rozhodnete pro výpočet vektorů vložení pomocí Databricks, můžete použít předem nakonfigurovaný koncový bod rozhraní API modelu Foundation nebo vytvořit koncový bod pro poskytování modelu vložení podle vašeho výběru. Prohlédněte si API Foundation modelu s platbou za token nebo Vytvoření koncových bodů pro obsluhu základního modelu pro pokyny. Například notebooky vizte v příkladových noteboocích pro vektorové vyhledávání.
Když konfigurujete koncový bod vkládání, Databricks doporučuje odstranit výchozí výběr Škálování na nulu. Obsluha koncových bodů může trvat několik minut, než se zahřeje, a počáteční dotaz na index s koncovým bodem se sníženou kapacitou může vypršet časový limit.
Poznámka:
Inicializace indexu vektorového vyhledávání může vypršela, pokud koncový bod pro vložení není pro datovou sadu správně nakonfigurovaný. Koncové body procesoru byste měli používat jenom pro malé datové sady a testy. U větších datových sad použijte koncový bod GPU pro optimální výkon.
Vytvoření indexu vektorového vyhledávání
Index vektorového vyhledávání můžete vytvořit pomocí uživatelského rozhraní, sady Python SDK nebo rozhraní REST API. Uživatelské rozhraní je nejjednodušší přístup.
Existují dva typy indexů:
- Index delta synchronizace se automaticky synchronizuje se zdrojovou tabulkou Delta, přičemž automaticky a přírůstkově aktualizuje index, jak se podkladová data v tabulce Delta mění.
- Index přímého přístupu k vektorům podporuje přímé čtení a zápis vektorů a metadat. Uživatel zodpovídá za aktualizaci této tabulky pomocí rozhraní REST API nebo sady Python SDK. Tento typ indexu nelze vytvořit pomocí uživatelského rozhraní. Musíte použít rozhraní REST API nebo sadu SDK.
Poznámka:
Název sloupce _id je rezervovaný. Pokud má vaše zdrojová tabulka sloupec pojmenovaný _id, přejmenujte ho před vytvořením indexu pro vyhledávání vektoru.
Vytvoření indexu pomocí uživatelského rozhraní
Na levém bočním panelu kliknutím na Katalog otevřete uživatelské rozhraní Průzkumníka katalogů.
Přejděte do tabulky Delta, kterou chcete použít.
Klikněte na tlačítko Vytvořit v pravém horním rohu a v rozbalovací nabídce vyberte Index vektorového vyhledávání.
Ke konfiguraci indexu použijte selektory v dialogovém okně.
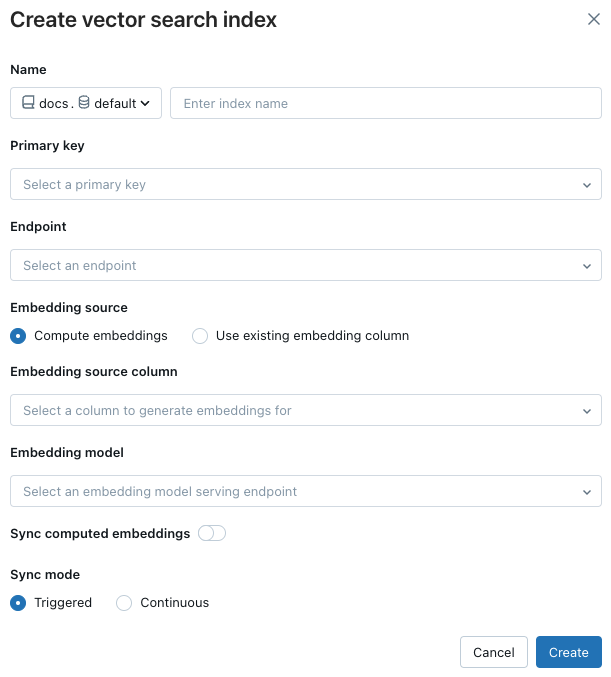
Název: Název, který se má použít pro online tabulku v katalogu Unity. Název musí mít tříúrovňový obor názvů,
<catalog>.<schema>.<name>. Jsou povoleny pouze alfanumerické znaky a podtržítka.primární klíč: Sloupec, který se použije jako primární klíč.
Sloupce, které se mají synchronizovat: (Podporuje se jenom pro standardní koncové body.) Vyberte sloupce, které chcete synchronizovat s vektorovým indexem. Pokud toto pole necháte prázdné, všechny sloupce ze zdrojové tabulky se synchronizují s indexem. Sloupec primárního klíče a vložený zdrojový sloupec nebo sloupec vektoru vkládání se vždy synchronizují. U koncových bodů optimalizovaných pro úložiště se všechny sloupce ze zdrojové tabulky vždy synchronizují.
vložení zdroje: Uveďte, jestli chcete, aby Databricks vypočítal embeddingy pro textový sloupec v tabulce Delta (vypočítat embeddingy), nebo pokud tabulka Delta obsahuje předem vypočítané embeddingy (Použít existující sloupec embedingu).
Pokud jste vybrali vkládání výpočetních prostředků, vyberte sloupec, pro který chcete vložit, a model pro vložení, který se má použít pro výpočet. Podporují se jenom textové sloupce.
Pro produkční aplikace využívající standardní koncové body doporučuje Databricks používat základní model
databricks-gte-large-ense zřízenou propustností obsluhující koncový bod.Pro produkční aplikace, které používají koncové body optimalizované pro úložiště s modely hostovanými na Databricks, použijte jako koncový bod vkládacího modelu přímo název modelu (například
databricks-gte-large-en). Koncové body optimalizované pro úložiště se používajíai_querypři dávkovém odvozování v době příjmu dat a poskytují vysokou propustnost úlohy vkládání. Pokud chcete pro dotazování použít koncový bod zřízené propustnosti, zadejte ho domodel_endpoint_name_for_querypole při vytváření indexu.
Pokud jste vybrali Použít stávající sloupec pro vkládání, vyberte sloupec, který obsahuje předem vypočítané vklady a rozměr vkládání. Formát předpočítaného sloupce pro vložení by měl být
array[float]. U koncových bodů optimalizovaných pro úložiště musí být dimenze vkládání rovnoměrně dělitelná hodnotou 16.
Synchronizace počítaných vestaveb: Přepněte toto nastavení, aby se vygenerované vestavby uložily do tabulky katalogu Unity. Další informace najdete v tématu Uložení vygenerované vložené tabulky.
Koncový bod vektorového vyhledávání: Vyberte koncový bod vektorového vyhledávání, do které chcete index uložit.
režim synchronizace: nepřetržitý udržuje index synchronizovaný s latencí v řádu sekund. Jsou s ním spojeny vyšší náklady, protože je zřízen výpočetní cluster pro spuštění pipeline pro kontinuální synchronizaci streamování.
- U standardních koncových bodů provádí průběžné i aktivované přírůstkové aktualizace, takže se zpracovávají jenom data, která se od poslední synchronizace změnila.
- U koncových bodů optimalizovaných pro úložiště každá synchronizace částečně znovu sestaví index. U spravovaných indexů při následných synchronizacích se všechny vygenerované vkládání, u kterých se zdrojový řádek nezměnil, znovu používají a není nutné je přepočítá. Viz Omezení koncových bodů optimalizovaných pro úložiště.
S režimem synchronizace Triggered použijete Python SDK nebo REST API ke spuštění synchronizace. Viz Aktualizace indexu Delta Sync.
U koncových bodů optimalizovaných pro úložiště se podporuje jenom aktivovaný režim synchronizace.
Upřesnit nastavení: (Volitelné) Pokud jste vybrali výpočetní vkládání, můžete zadat samostatný model vkládání pro dotazování indexu vektorového vyhledávání. To může být užitečné, pokud potřebujete koncový bod vysoké propustnosti pro příjem dat, ale koncový bod s nižší latencí pro dotazování indexu. Model zadaný v poli Modelu vložení se vždy používá pro příjem dat a používá se také k dotazování, pokud zde nezadáte jiný model. Chcete-li zadat jiný model, klepněte na tlačítko Zvolit samostatný vložený model pro dotazování indexu a vyberte model z rozevírací nabídky.

Po dokončení konfigurace indexu klikněte na Vytvořit.
Vytvoření indexu pomocí sady Python SDK
Následující příklad vytvoří Delta Sync index s embeddingy vypočítanými pomocí Databricks. Podrobnosti najdete v referenčních informacích k sadě Python SDK.
Tento příklad také ukazuje volitelný parametr model_endpoint_name_for_query, který určuje samostatný vložený model obsluhující koncový bod sloužící k dotazování indexu.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
Následující příklad vytvoří rozdílový synchronizační index s použitím samostatně spravovaných vkládání.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Ve výchozím nastavení se všechny sloupce ze zdrojové tabulky synchronizují s indexem.
Ve standardních koncových bodech můžete vybrat podmnožinu sloupců, které se mají synchronizovat pomocí columns_to_sync. Primární klíč a sloupce vkládání jsou vždy zahrnuty v indexu.
Chcete-li synchronizovat pouze primární klíč a vložený sloupec, musíte je zadat v columns_to_sync, jak je uvedeno.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Pokud chcete synchronizovat další sloupce, zadejte je, jak je znázorněno. Nemusíte zahrnout primární klíč a sloupec pro vložení, protože se vždy synchronizují.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Následující příklad vytvoří index přímého přístupu k vektoru.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Vytvoření indexu pomocí rozhraní REST API
Projděte si referenční dokumentaci k rozhraní REST API: POST /api/2.0/vector-search/indexes.
Uložit vygenerovanou vloženou tabulku
Pokud Databricks vygeneruje vkládání, můžete vygenerované vkládání uložit do tabulky v katalogu Unity. Tato tabulka se vytvoří ve stejném schématu jako vektorový index a je propojena ze stránky indexu vektoru.
Název tabulky je název indexu vektorového vyhledávání, připojený _writeback_table. Název nelze upravit.
K tabulce můžete přistupovat a dotazovat se na ji stejně jako na jakoukoli jinou tabulku v katalogu Unity. Tabulku byste ale neměli odstraňovat ani upravovat, protože není určená k ruční aktualizaci. Pokud se index odstraní, tabulka se odstraní automaticky.
Aktualizace indexu vektorového vyhledávání
Aktualizace indexu rozdílové synchronizace
Indexy vytvořené pomocí režimu průběžné synchronizace se automaticky aktualizují, když se změní zdrojová tabulka Delta. Pokud používáte režim aktivované synchronizace, můžete synchronizaci spustit pomocí uživatelského rozhraní, sady Python SDK nebo rozhraní REST API.
Uživatelské rozhraní Databricks
V Průzkumníku katalogu přejděte do indexu vektorového vyhledávání.
Na kartě Přehled v části Ingestování dat klikněte na Synchronizovat.

Python SDK
Podrobnosti najdete v referenčních informacích k sadě Python SDK.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
Projděte si referenční dokumentaci k rozhraní REST API: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Aktualizace indexu pro přímý přístup k vektoru
Sadu Python SDK nebo rozhraní REST API můžete použít k vložení, aktualizaci nebo odstranění dat z indexu Direct Vector Access.
Python SDK
Podrobnosti najdete v referenčních informacích k sadě Python SDK.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
Projděte si referenční dokumentaci k rozhraní REST API: POST /api/2.0/vector-search/indexes.
V produkčních aplikacích Databricks doporučuje používat služební identity místo osobních přístupových tokenů. Výkon lze zlepšit až o 100 ms na dotaz.
Následující příklad kódu ukazuje, jak aktualizovat index pomocí služby principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Následující příklad kódu ukazuje, jak aktualizovat index pomocí tokenu PAT (Personal Access Token).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Jak provádět změny schématu bez výpadků
Pokud se schéma existujících sloupců ve zdrojové tabulce změní, je nutné znovu sestavit index. Pokud je povolená tabulka zpětného zápisu , je nutné znovu sestavit index při přidání nových sloupců do zdrojové tabulky. Pokud není povolená tabulka zpětného zápisu, nové sloupce nevyžadují opětovné sestavení indexu.
Následujícím postupem znovu sestavíte a nasadíte index bez výpadku:
- Proveďte změnu schématu ve zdrojové tabulce.
- Vytvořte nový index.
- Jakmile bude nový index připravený, přepněte provoz na nový index.
- Odstraňte původní index.