Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Vytvořte inteligentního pomocníka pro personální oddělení s využitím LangChain.js a služeb Azure. Tento agent pomáhá zaměstnancům ve fiktivní společnosti NorthWind najít odpovědi na otázky týkající se lidských zdrojů vyhledáváním v dokumentaci společnosti.
Azure AI Search použijete k vyhledání relevantních dokumentů a Azure OpenAI k vygenerování přesných odpovědí. Architektura LangChain.js zpracovává složitost orchestrace agentů a umožňuje zaměřit se na konkrétní obchodní požadavky.
Naučíte se:
- Nasazení prostředků Azure pomocí Azure Developer CLI
- Vytvoření LangChain.js agenta, který se integruje se službami Azure
- Implementace generování rozšířeného načítání (RAG) pro vyhledávání dokumentů
- Místní testování a ladění agenta a v Azure
Na konci tohoto kurzu máte funkční rozhraní REST API, které odpovídá na otázky hr pomocí dokumentace vaší společnosti.
Přehled architektury
NorthWind spoléhá na dva zdroje dat:
- Dokumentace k personálnímu oddělení přístupná všem zaměstnancům
- Důvěrná databáze personálního oddělení obsahující citlivá data zaměstnanců.
Tento kurz se zaměřuje na vytvoření LangChain.js agenta, který určuje, jestli je možné odpovědět na otázku zaměstnance pomocí veřejných dokumentů personálního oddělení. Pokud ano, LangChain.js agent poskytne odpověď přímo.
Požadavky
Pokud chcete tuto ukázku použít v codespace nebo místním vývojovém kontejneru, včetně sestavení a spuštění agenta LangChain.js, potřebujete následující:
- Aktivní účet Azure. Pokud ho nemáte, vytvořte si účet zdarma .
Pokud ukázkový kód spustíte místně bez vývojového kontejneru, potřebujete také:
- Node.js LTS nainstalované ve vašem systému.
- TypeScript pro psaní a kompilaci kódu TypeScript.
- Nainstalovaný a nakonfigurovaný Azure Developer CLI (azd).
- LangChain.js knihovna k sestavení agenta.
- Volitelné: LangSmith pro monitorování využití AI. Potřebujete název projektu, klíč a koncový bod.
- Volitelné: LangGraph Studio pro ladění řetězů LangGraph a agentů LangChain.js.
Prostředky Azure
Jsou vyžadovány následující prostředky Azure. Vytvoří se pro vás v tomto článku pomocí azure Developer CLI a šablon Bicep pomocí Azure Verified Modules (AVM). Prostředky se vytvářejí pomocí přístupu jak bez hesla, tak s klíčem pro účely výuky. Tento kurz používá váš místní vývojářský účet k ověřování bez hesla:
- Spravovaná identita pro ověřování bez hesla pro služby Azure
- Azure Container Registry pro uložení image Dockeru pro server rozhraní API Node.js Fastify.
- Azure Container App pro hostování serveru rozhraní API Node.js Fastify.
- Prostředek Azure AI Search pro vektorové vyhledávání
-
Prostředek Azure OpenAI s následujícími modely:
- Vložený model, jako
text-embedding-3-smallje . - Velký jazykový model (LLM) jako
'gpt-4.1-mini.
- Vložený model, jako

Architektura agentů
Architektura LangChain.js poskytuje rozhodovací tok pro vytváření inteligentních agentů jako LangGraph. V tomto kurzu vytvoříte agenta LangChain.js, který se integruje se službou Azure AI Search a Azure OpenAI pro odpovědi na otázky související s lidskými zdroji. Architektura agenta je navržená tak, aby:
- Určete, jestli je otázka relevantní pro obecnou dokumentaci personálního oddělení, která je k dispozici všem zaměstnancům.
- Načtěte relevantní dokumenty ze služby Azure AI Search na základě uživatelského dotazu.
- Pomocí Azure OpenAI vygenerujte odpověď na základě načtených dokumentů a modelu LLM.
Klíčové komponenty:
Struktura grafu: Agent LangChain.js je reprezentován jako graf, kde:
- Uzly provádějí konkrétní úlohy, jako je rozhodování nebo načítání dat.
- Hrany definují tok mezi uzly a určují posloupnost operací.
Integrace služby Azure AI Search:
- Používá model vkládání k vytváření vektorů.
- Vloží dokumenty HR (*.md, *.pdf) do vektorového úložiště. Mezi dokumenty patří:
- Informace o společnosti
- Příručka pro zaměstnance
- Příručka k výhodám
- Knihovna rolí zaměstnanců
- Načte relevantní dokumenty na základě výzvy uživatele.
-
Integrace Azure OpenAI:
- Používá velký jazykový model k:
- Určuje, zda je otázka zodpověditelná z nepřímých personálních dokumentů.
- Vygeneruje odpověď s výzvou pomocí kontextu z dokumentů a uživatelských otázek.
- Používá velký jazykový model k:
Následující tabulka obsahuje příklady uživatelských otázek, které jsou i nejsou relevantní a odpověditelné z obecných dokumentů lidských zdrojů.
| Otázka | Relevantní | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Ano | Dokumenty personálního oddělení, jako je například příručka pro zaměstnance, by měly poskytnout odpověď. |
How much of my perks + benefits have I spent? |
Ne | Tato otázka vyžaduje přístup k důvěrným datům zaměstnanců, která jsou mimo rozsah tohoto agenta. |
Pomocí architektury LangChain.js se vyhnete většinu často používaného kódu agentů a integrace služeb Azure, což vám umožní soustředit se na obchodní potřeby.
Klonování úložiště ukázkového kódu
V novém adresáři naklonujte úložiště vzorového kódu a přejděte do nového adresáře:
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
Tato ukázka poskytuje kód, který potřebujete k vytvoření zabezpečených prostředků Azure, sestavení agenta LangChain.js pomocí služby Azure AI Search a Azure OpenAI a použití agenta ze serveru rozhraní API Node.js Fastify.
Ověřování v Azure CLI a Azure Developer CLI
Přihlaste se k Azure pomocí Azure Developer CLI, vytvořte prostředky Azure a nasaďte zdrojový kód. Vzhledem k tomu, že proces nasazení používá Azure CLI i Azure Developer CLI, přihlaste se k Azure CLI a nakonfigurujte Azure Developer CLI tak, aby používalo vaše ověřování z Azure CLI:
az login
azd config set auth.useAzCliAuth true
Vytvoření prostředků a nasazení kódu pomocí Azure Developer CLI
Spusťte proces nasazení spuštěním azd up příkazu:
azd up
azd up Během příkazu odpovězte na otázky:
-
Nový název prostředí: zadejte jedinečný název prostředí, například
langchain-agent. Tento název prostředí se používá jako součást skupiny prostředků Azure. - Vyberte předplatné Azure: Vyberte předplatné, ve kterém se prostředky vytvářejí.
-
Vyberte oblast: například
eastus2.
Nasazení trvá přibližně 10 až 15 minut. Azure Developer CLI orchestruje proces pomocí fází a háků definovaných v azure.yaml souboru:
Fáze implementace (ekvivalentní azd provision):
- Vytvoří prostředky Azure definované v
infra/main.bicep:- Azure Container App
- OpenAI
- Vyhledávání AI
- Container Registry
- Spravovaná identita
-
Háček po zřízení: Zkontroluje, jestli už existuje index
northwindSlužby Azure AI Search.- Pokud index neexistuje: spustí
npm installse anpm run load_datanahraje dokumenty personálního oddělení pomocí zavaděče PDF LangChain.js a klienta pro vkládání. - Pokud index existuje: přeskočí načítání dat, aby se zabránilo duplicitám (můžete ho znovu načíst ručně odstraněním indexu nebo spuštěním
npm run load_data) Fáze nasazení (ekvivalentníazd deploy):
- Pokud index neexistuje: spustí
- Háček před nasazením: Sestaví image Dockeru pro server rozhraní API Fastify a odešle ji do služby Azure Container Registry.
- Nasadí kontejnerizovaný server API do Azure Container Apps.
Po dokončení nasazení se proměnné prostředí a informace o prostředcích uloží do .env souboru v kořenovém adresáři úložiště. Prostředky můžete zobrazit na webu Azure Portal.
Prostředky se vytvářejí pomocí přístupu jak bez hesla, tak s klíčem pro účely výuky. V tomto úvodním kurzu se k ověřování bez hesla používá místní vývojářský účet. V produkčních aplikacích používejte pouze ověřování bez hesla se spravovanými identitami. Přečtěte si další informace o ověřování bez hesla.
Místní použití ukázkového kódu
Teď, když jsou prostředky Azure vytvořené, můžete spustit agenta LangChain.js místně.
Nainstalujte závislosti
Nainstalujte balíčky Node.js pro tento projekt.
npm installTento příkaz nainstaluje závislosti definované ve dvou
package.jsonsouborech vpackages-v1adresáři, včetně:-
./packages-v1/server-api:- Rychlé zrychlování webového serveru
-
./packages-v1/langgraph-agent:- LangChain.js pro sestavení agenta
- Klientská knihovna
@azure/search-documentsAzure SDK pro integraci s prostředkem Azure AI Search Referenční dokumentace je tady.
-
Sestavte dva balíčky: server rozhraní API a agent AI.
npm run buildTento příkaz vytvoří propojení mezi těmito dvěma balíčky, aby server rozhraní API mohl volat agenta AI.
Místní spuštění serveru rozhraní API
Azure Developer CLI vytvořil požadované prostředky Azure a nakonfiguroval proměnné prostředí v kořenovém .env souboru. Tato konfigurace zahrnovala hák po poskytnutí pro nahrání dat do vektorového úložiště. Teď můžete spustit server rozhraní API Fastify, který je hostitelem LangChain.js agenta. Spusťte server rozhraní API Fastify.
npm run dev
Server se spustí a naslouchá na portu 3000. Server můžete otestovat tak, že ve webovém prohlížeči přejdete na [http://localhost:3000]. Měla by se zobrazit uvítací zpráva oznamující, že server je spuštěný.
Použití rozhraní API k kladení otázek
Můžete použít nástroj, jako je REST Client , nebo curl odeslat požadavek POST do koncového /ask bodu s textem JSON obsahujícím vaši otázku.
Dotazy REST klienta jsou k dispozici v packages-v1/server-api/http adresáři.
Příklad použití curl:
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
Měli byste obdržet odpověď ve formátu JSON obsahující odpověď od agenta LangChain.js.
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
V adresáři je k dispozici několik ukázkových packages-v1/server-api/http otázek. Otevřete soubory v editoru Visual Studio Code pomocí klienta REST, abyste je mohli rychle otestovat.
Vysvětlení kódu aplikace
Tato část vysvětluje, jak se agent LangChain.js integruje se službami Azure. Aplikace úložiště je uspořádaná jako pracovní prostor npm se dvěma hlavními balíčky:
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
Klíčová rozhodnutí o architektuře:
- Struktura Monorepo: Pracovní prostory npm umožňují sdílené závislosti a propojené balíčky.
-
Oddělení zodpovědností: Logika agenta (
langgraph-agent) je nezávislá na serveru API (server-api) -
Centralizované ověřování: Soubory ve
./langgraph-agent/src/azurese zabývají ověřováním založeným na klíči a ověřováním bez hesla a také integrací služeb Azure.
Ověřování ke službám Azure
Aplikace podporuje metody ověřování založené na klíčích i bez hesla řízené proměnnou SET_PASSWORDLESS prostředí. Rozhraní DefaultAzureCredential API z knihovny Identit Azure se používá k ověřování bez hesla, což aplikaci umožňuje bezproblémově spouštět v místních vývojových prostředích a prostředích Azure. Toto ověřování můžete zobrazit v následujícím fragmentu kódu:
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
Při použití knihoven třetích stran, jako je LangChain.js nebo knihovna OpenAI pro přístup k Azure OpenAI, potřebujete místo přímého předávání objektu přihlašovacích údajů funkci zprostředkovatele tokenu . Funkce getBearerTokenProvider z knihovny Azure Identity tento problém řeší vytvořením zprostředkovatele tokenu, který automaticky načte a aktualizuje nosné tokeny OAuth 2.0 pro konkrétní obor prostředků Azure (například "https://cognitiveservices.azure.com/.default"). Během instalace nakonfigurujete obor jednou a zprostředkovatel tokenu automaticky zpracuje veškerou správu tokenů. Tento přístup funguje s libovolnými přihlašovacími údaji knihovny identit Azure, včetně spravovaných identit a přihlašovacích údajů Azure CLI. I když knihovny sady Azure SDK přijímají DefaultAzureCredential přímo, knihovny třetích stran, jako je LangChain.js, vyžadují, aby byl použit tento model zprostředkovatele tokenů k překlenutí mezery v ověřování.
Integrace služby Azure AI Search
Prostředek Azure AI Search ukládá vkládání dokumentů a umožňuje sémantické vyhledávání relevantního obsahu. Aplikace používá jazyk LangChain AzureAISearchVectorStore ke správě úložiště vektorů, aniž byste museli definovat schéma indexu.
Úložiště vektorů se vytvoří s konfigurací pro operace správce (zápis) i dotazování (čtení), aby načítání dokumentů a dotazování mohly používat různé konfigurace. To je důležité bez ohledu na to, jestli používáte klíče nebo ověřování bez hesla se spravovanými identitami.
Nasazení Azure Developer CLI zahrnuje proces po nasazení, který nahraje dokumenty do úložiště vektorů pomocí LangChain.js zavaděče PDF a klientem pro vtělení. Tento háček po nasazení je posledním krokem azd up příkazu po vytvoření prostředku Azure AI Search. Skript pro načítání dokumentů používá logiku dávkování a opakování ke zpracování limitů rychlosti služby.
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Pomocí kořenového .env souboru, který vytvořil Azure Developer CLI, se můžete ověřit u prostředku Azure AI Search a vytvořit klienta AzureAISearchVectorStore:
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
Při dotazování převede úložiště vektorů dotaz uživatele na vložení, vyhledá dokumenty s podobnými vektorovými reprezentacemi a vrátí nejrelevavantnější bloky dat.
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
Vzhledem k tomu, že vektorové úložiště je postaveno na LangChain.js, abstrahuje složitost přímé interakce s vektorovým úložištěm. Jakmile se seznámíte s rozhraním LangChain.js vektorového úložiště, můžete v budoucnu snadno přepnout na jiné implementace vektorového úložiště.
Integrace Azure OpenAI
Aplikace používá Azure OpenAI pro možnosti vkládání i velkých jazykových modelů (LLM). Třída AzureOpenAIEmbeddings z LangChain.js se používá k vytváření embeddingů pro dokumenty a dotazy. Jakmile vytvoříte klienta vkládání, LangChain.js ho použije k vytvoření vložených objektů.
Integrace Azure OpenAI pro vkládání
Pomocí kořenového .env souboru vytvořeného rozhraním příkazového řádku Azure Developer CLI ověřte prostředek Azure OpenAI a vytvořte klienta AzureOpenAIEmbeddings :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
Integrace Azure OpenAI pro LLM
Pomocí kořenového .env souboru vytvořeného rozhraním příkazového řádku Pro vývojáře Azure ověřte prostředek Azure OpenAI a vytvořte klienta AzureChatOpenAI :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 1000,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
Aplikace používá AzureChatOpenAI třídu z LangChain.js @langchain/openai k interakci s modely Azure OpenAI.
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
Pracovní postup agenta LangGraph
Agent pomocí jazyka LangGraph definuje rozhodovací pracovní postup, který určuje, jestli lze na otázku odpovědět pomocí dokumentů lidských zdrojů.
Struktura grafu:
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
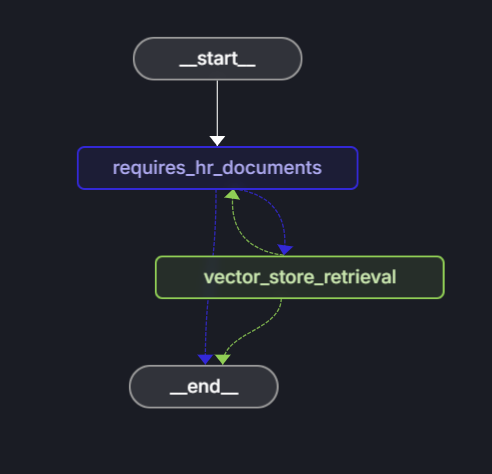
Pracovní postup se skládá z následujících kroků:
- Začátek: Uživatel odešle otázku.
- requires_hr_documents uzlu: LLM určuje, jestli je otázka zodpověditelná z obecných dokumentů HR.
-
Podmíněné směrování:
- Pokud ano, pokračujte do
get_answeruzlu. - Pokud ne, vrátí se zpráva, že tato otázka vyžaduje osobní údaje o lidských zdrojích.
- Pokud ano, pokračujte do
- uzel get_answer: Načte dokumenty a vygeneruje odpověď.
- Konec: Vrátí odpověď uživateli.
Tato kontrola relevance je důležitá, protože na obecné dokumenty se nedají odpovědět všechny otázky týkající se lidských zdrojů. Osobní dotazy, jako je "Kolik mám dovolené?" vyžadují přístup k databázím zaměstnanců, které obsahují jednotlivá data o zaměstnancích. Kontrolou relevance se agent vyhne vytváření nereálných odpovědí na otázky, které vyžadují osobní údaje, ke kterým nemá přístup.
Rozhodněte se, jestli otázka vyžaduje dokumenty personálního oddělení.
Uzel requires_hr_documents pomocí LLM určí, jestli na otázku uživatele můžete odpovědět pomocí obecných dokumentů personálního oddělení. Používá šablonu výzvy, která dává modelu pokyn, aby odpověděl pomocí YES nebo NO na základě relevance otázky. Vrátí odpověď ve strukturované zprávě, kterou lze předat v pracovním postupu. Následující uzel použije tuto odpověď ke směrování pracovního postupu buď do END nebo do ANSWER_NODE.
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
Získání požadovaných dokumentů personálního oddělení
Jakmile se zjistí, že otázka vyžaduje dokumenty personálního oddělení, pracovní postup použije getAnswer k načtení příslušných dokumentů z úložiště vektorů, jejich přidání do kontextu výzvy a předání celé výzvy do LLM.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
Pokud nejsou nalezeny žádné relevantní dokumenty, agent vrátí zprávu oznamující, že v dokumentech lidských zdrojů nemohl najít odpověď.
Řešení problémů
V případě jakýchkoli problémů s postupem vytvořte problém v úložišti vzorového kódu.
Vyčistěte zdroje
Můžete odstranit skupinu prostředků, která obsahuje prostředek Azure AI Search a prostředek Azure OpenAI, nebo pomocí Azure Developer CLI okamžitě odstranit všechny prostředky vytvořené v tomto kurzu.
azd down --purge