Rozhraní TABLE API a SQL v clusterech Apache Flink® ve službě HDInsight v AKS
Důležité
Tato funkce je aktuálně dostupná jako ukázková verze. Doplňkové podmínky použití pro Microsoft Azure Preview obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi Preview nebo ještě nejsou vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight o službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás o dalších aktualizacích v komunitě Azure HDInsight.
Apache Flink obsahuje dvě relační rozhraní API – rozhraní API pro tabulky a SQL – pro jednotné zpracování datových proudů a dávek. Rozhraní Table API je rozhraní API pro dotazy integrované v jazyce, které umožňuje intuitivně skládat dotazy z relačních operátorů, jako je výběr, filtrování a spojení. Podpora jazyka SQL Flink je založená na Apache Calcite, který implementuje standard SQL.
Rozhraní Table API a ROZHRANÍ SQL se bezproblémově integrují s rozhraním DataStream API a Flinkem. Můžete snadno přepínat mezi všemi rozhraními API a knihovnami, které na nich vycházejí.
Apache Flink SQL
Stejně jako ostatní moduly SQL fungují dotazy Flink nad tabulkami. Liší se od tradiční databáze, protože Flink nespravuje neaktivní uložená data místně; místo toho dotazy pracují nepřetržitě s externími tabulkami.
Kanály zpracování dat Flink začínají zdrojovými tabulkami a končí tabulkami jímky. Zdrojové tabulky vytvářejí řádky provozované během provádění dotazu; jedná se o tabulky odkazované v klauzuli FROM dotazu. Připojení ors mohou být typu HDInsight Kafka, HDInsight HBase, Azure Event Hubs, databáze, systém souborů nebo jakýkoli jiný systém, jehož konektor leží v cestě ke třídě.
Použití klienta Flink SQL ve službě HDInsight v clusterech AKS
V tomto článku se dozvíte, jak používat rozhraní příkazového řádku ze služby Secure Shell na webu Azure Portal. Tady je několik rychlých ukázek, jak začít.
Spuštění klienta SQL
./bin/sql-client.shPředání inicializačního souboru SQL ke spuštění společně s sql-clientem
./sql-client.sh -i /path/to/init_file.sqlNastavení konfigurace v sql-clientu
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL podporuje následující příkazy CREATE.
- CREATE TABLE
- CREATE DATABASE
- VYTVOŘIT KATALOG
Následuje příklad syntaxe pro definování zdrojové tabulky pomocí konektoru jdbc pro připojení k MSSQL s ID, názvem jako sloupci v příkazu CREATE TABLE .
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
VYTVOŘIT KATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
V horní části těchto tabulek můžete spouštět průběžné dotazy.
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Zapište do tabulky jímky ze zdrojové tabulky:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Přidání závislostí
Příkazy JAR se používají k přidání uživatelských souborů JAR do cesty ke třídě nebo odebrání uživatelských jar z cesty ke třídě nebo zobrazení přidaných jar v cestě ke třídám v modulu runtime.
Flink SQL podporuje následující příkazy JAR:
- ADD JAR
- SHOW JARS
- ODEBRAT SOUBOR JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore Hive v clusterech Apache Flink® ve službě HDInsight v AKS
Katalogy poskytují metadata, jako jsou databáze, tabulky, oddíly, zobrazení a funkce a informace potřebné pro přístup k datům uloženým v databázi nebo jiných externích systémech.
Ve službě HDInsight ve službě AKS podporujeme Flink dvě možnosti katalogu:
GenericInMemoryCatalog
GenericInMemoryCatalog je implementace katalogu v paměti. Všechny objekty jsou k dispozici pouze po celou dobu životnosti relace SQL.
HiveCatalog
HiveCatalog slouží ke dvěma účelům– jako trvalé úložiště pro čistě metadata Flink a jako rozhraní pro čtení a zápis existujících metadat Hive.
Poznámka:
HDInsight v clusterech AKS obsahuje integrovanou možnost metastoru Hive pro Apache Flink. Během vytváření clusteru můžete zvolit metastore Hive.
Vytvoření a registrace databází Flink do katalogů
V tomto článku se dozvíte, jak používat rozhraní příkazového řádku a jak začít používat Flink SQL Client ze služby Secure Shell na webu Azure Portal.
Spustit
sql-client.shrelaci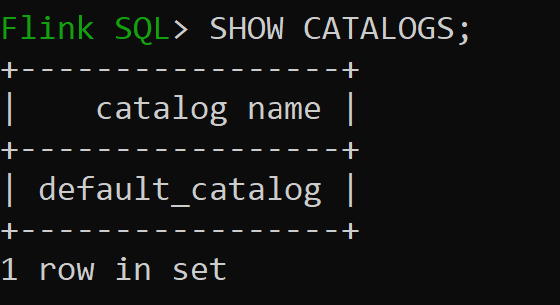
Default_catalog je výchozí katalog v paměti.
Pojďme teď zkontrolovat výchozí databázi katalogu v paměti.
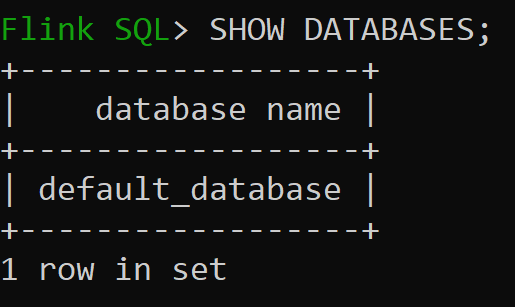
Pojďme vytvořit katalog Hive verze 3.1.2 a použít ho
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Poznámka:
HDInsight v AKS podporuje Hive 3.1.2 a Hadoop 3.3.2. Je
hive-conf-dirnastavená na umístění./opt/hive-confPojďme vytvořit databázi v katalogu Hive a nastavit ji jako výchozí pro relaci (pokud se nezmění).
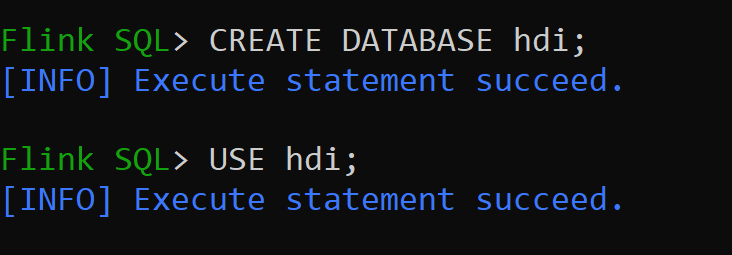
Vytvoření a registrace tabulek Hive do katalogu Hive
Postupujte podle pokynů k vytvoření a registraci databází Flink do katalogu.
Vytvoříme Flink Table typu konektoru Hive bez oddílu.
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Vložení dat do hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Čtení dat z hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsPoznámka:
Adresář skladu Hive se nachází v určeném kontejneru účtu úložiště zvoleného při vytváření clusteru Apache Flink. Najdete ho v adresáři hive/warehouse/
Umožňuje vytvořit tabulku Flink typu konektoru hive s oddílem.
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Důležité
Apache Flink má známé omezení. Poslední sloupce "n" se vyberou pro oddíly bez ohledu na sloupec oddílu definovaný uživatelem. FLINK-32596 Klíč oddílu bude chybný při použití dialektu Flink k vytvoření tabulky Hive.
Reference
- Apache Flink Table API a SQL
- Názvy apache, Apache Flink, Flink a přidružených opensourcových projektů jsou ochranné známky Apache Software Foundation (ASF).