Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto článku se naučíte vytvářet clustery Apache Hadoop v HDInsight pomocí webu Azure Portal a pak spouštět úlohy Apache Hive v HDInsight. Většina úloh Hadoop jsou dávkové úlohy. Vytvoříte cluster, spustíte některé úlohy a pak cluster odstraníte. V tomto článku provedete všechny tři úlohy. Podrobné vysvětlení dostupných konfigurací najdete v tématu Nastavení clusterů ve službě HDInsight. Další informace o použití portálu k vytváření clusterů najdete v tématu Vytváření clusterů na portálu.
V tomto rychlém startu pomocí webu Azure Portal vytvoříte cluster HDInsight Hadoop. K vytvoření clusteru můžete použít také šablonu Azure Resource Manageru.
HdInsight má v současné době sedm různých typů clusterů. Každý typ clusteru podporuje odlišnou sadu komponent. Všechny typy clusteru podporují Hive. Seznam podporovaných komponent v HDInsight najdete v tématu Co je nového ve verzích clusteru Apache Hadoop poskytovaných službou HDInsight?
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Vytvoření clusteru Apache Hadoop
V této části vytvoříte cluster Hadoop v HDInsight pomocí webu Azure Portal.
Přihlaste se k portálu Azure.
V horní nabídce vyberte + Vytvořit prostředek.
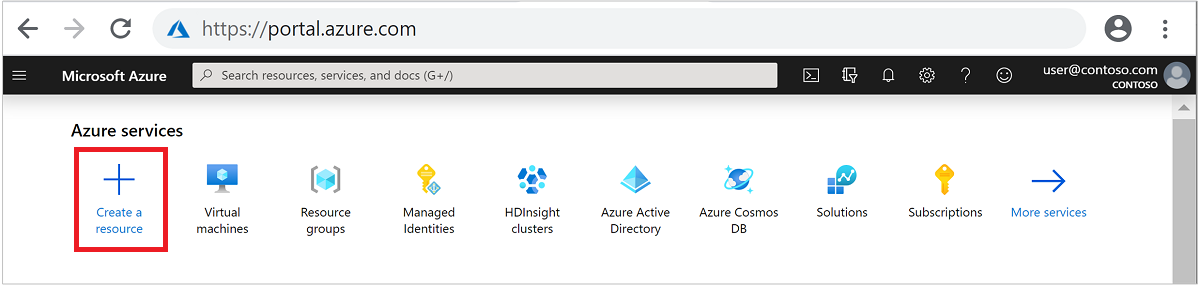
Výběrem možnosti Analytics>Azure HDInsight přejděte na stránku Vytvořit cluster HDInsight.
Na kartě Základy zadejte následující informace:
Vlastnost Popis Předplatné V rozevíracím seznamu vyberte předplatné Azure, které se používá pro cluster. Skupina prostředků V rozevíracím seznamu vyberte existující skupinu prostředků nebo vyberte možnost Vytvořit novou. Název clusteru Zadejte globálně jedinečný název. Název může obsahovat až 59 znaků včetně písmen, číslic a pomlček. První a poslední znaky názvu nesmí být pomlčky. Oblast V rozevíracím seznamu vyberte oblast, ve které je cluster vytvořen. Pro dosažení lepšího výkonu zvolte co nejbližší umístění. Typ clusteru Vyberte typ clusteru. Potom jako typ clusteru vyberte Hadoop . Verze V rozevíracím seznamu vyberte verzi. Pokud nevíte, co si vybrat, použijte výchozí verzi. Uživatelské jméno a heslo pro přihlášení do clusteru Výchozí přihlašovací jméno je správce. Heslo musí mít délku nejméně 10 znaků a musí obsahovat alespoň jednu číslici, jedno velké a jedno malé písmeno, jeden neosamocný znak (s výjimkou znaků ' ` "). Ujistěte se, že nezadáte běžná hesla, jako je například "Pass@word1".Uživatelské jméno Secure Shell (SSH) Výchozí uživatelské jméno je sshuser. Pro uživatelské jméno SSH můžete zadat jiný název.Použití hesla pro přihlášení ke clusteru pro SSH Toto políčko zaškrtněte, pokud chcete použít stejné heslo pro uživatele SSH jako heslo, které jste zadali pro přihlášeného uživatele clusteru. 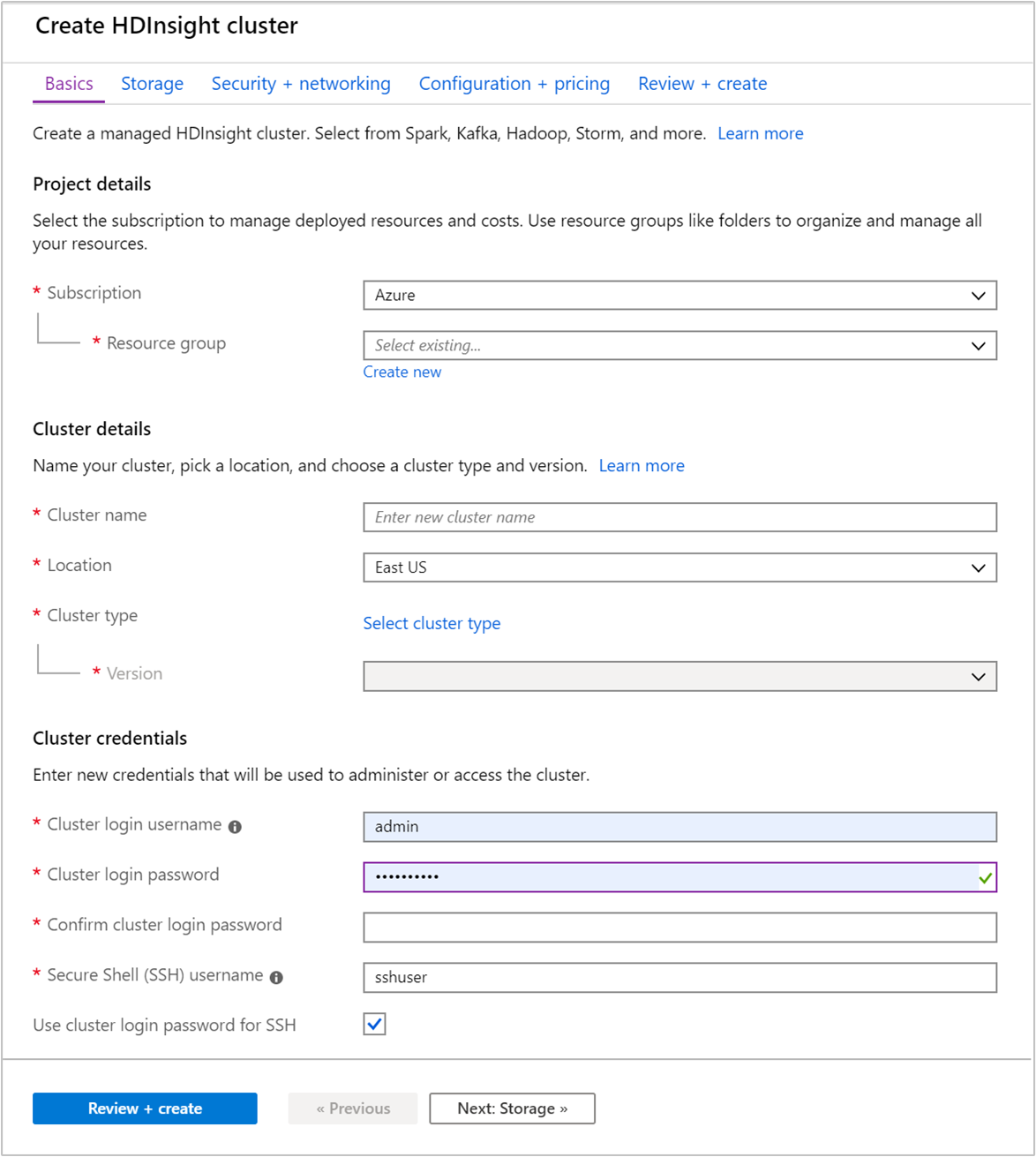
Výběrem možnosti Další: Úložiště >> přejdete na nastavení úložiště.
Na kartě Úložiště zadejte následující hodnoty:
Vlastnost Popis Typ primárního úložiště Použijte výchozí hodnotu Azure Storage. Metoda výběru Použijte výchozí hodnotu Vybrat ze seznamu. Účet primárního úložiště V rozevíracím seznamu vyberte existující účet úložiště nebo vyberte Vytvořit nový. Pokud vytvoříte nový účet, musí mít název délku 3 až 24 znaků a může obsahovat jenom číslice a malá písmena. Kontejner Použijte automaticky vyplněnou hodnotu. 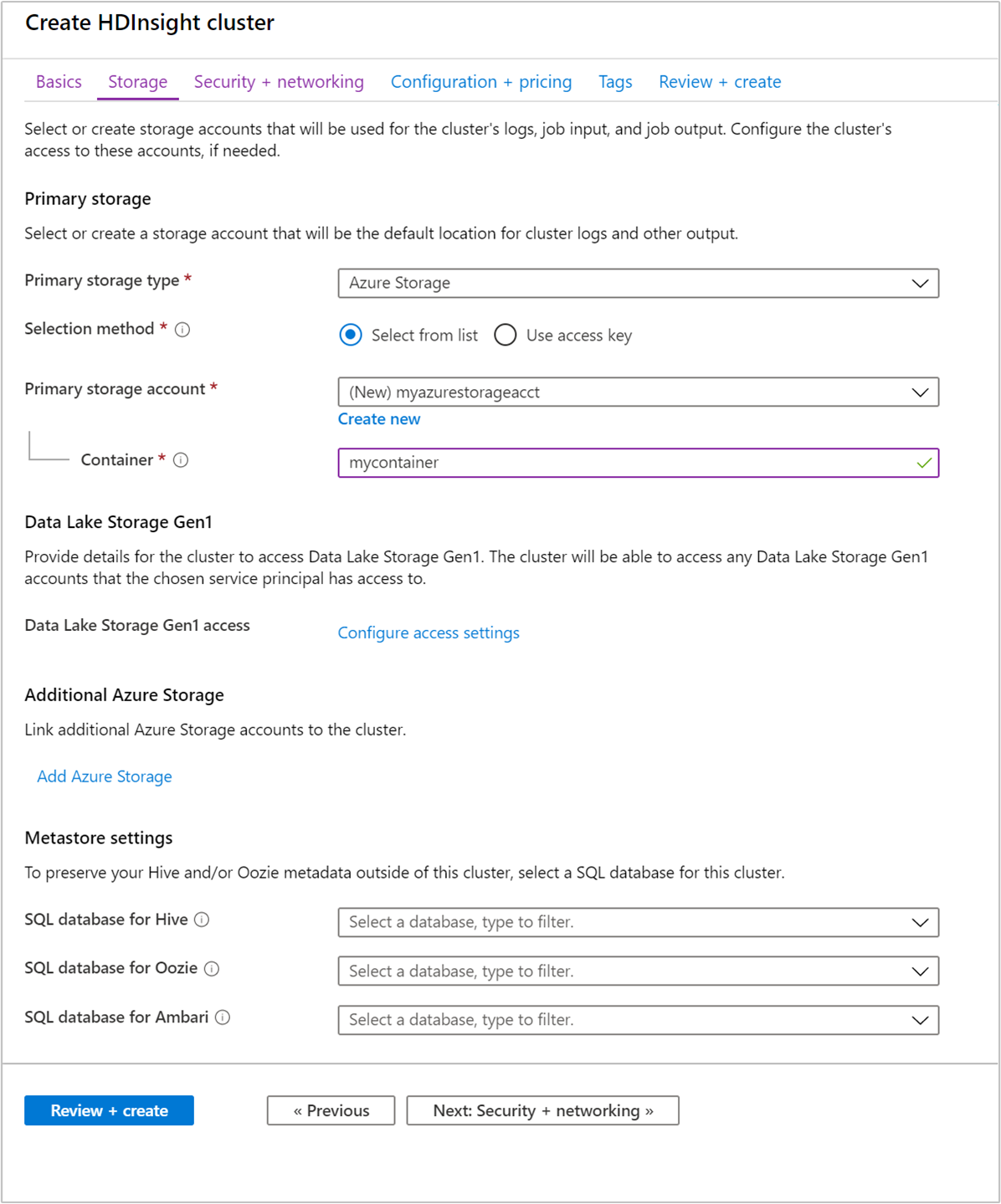
Každý cluster má účet služby Azure Storage nebo
Azure Data Lake Storage Gen2závislost. Označuje se jako výchozí účet úložiště. Cluster HDInsight a jeho výchozí účet pro úložiště musí být umístěny ve stejné oblasti Azure. Odstraněním clusterů se účet úložiště neodstraní.Vyberte kartu Zkontrolovat + vytvořit.
Na kartě Zkontrolovat a vytvořit ověřte hodnoty, které jste vybrali v předchozích krocích.
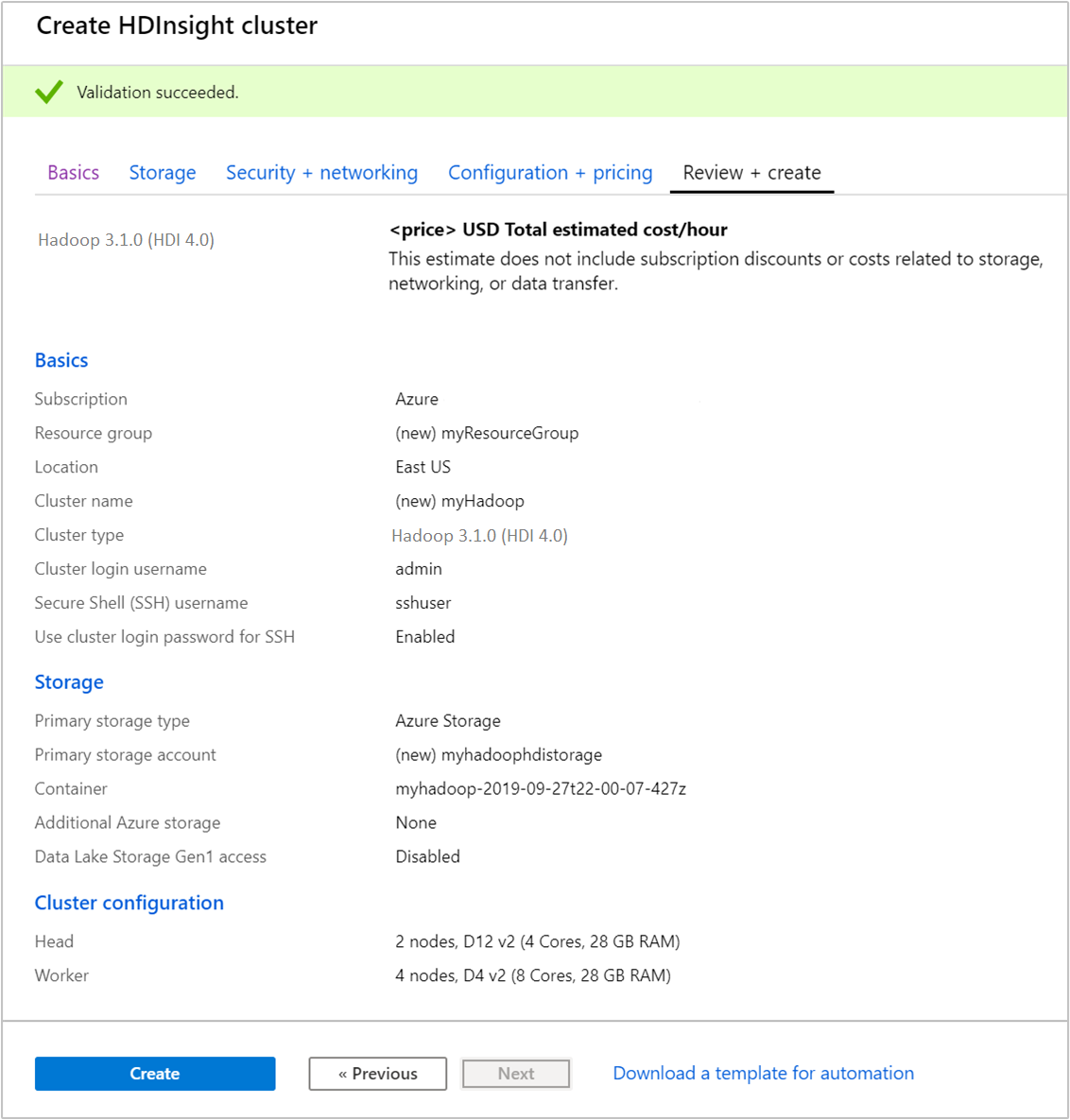
Vyberte Vytvořit. Vytvoření clusteru trvá přibližně 20 minut.
Po vytvoření clusteru se zobrazí stránka přehledu clusteru na portálu Azure Portal.
Spouštění dotazů Apache Hivu
Apache Hive je nejoblíbenější součástí používanou v HDInsight. Existuje mnoho způsobů spouštění úloh Hive v HDInsight. V tomto rychlém startu použijete zobrazení Ambari Hive z portálu. Další metody pro odesílání úloh Hive naleznete v části Použití Hive v HDInsight.
Poznámka:
Zobrazení Apache Hive není ve službě HDInsight 4.0 dostupné.
Pokud chcete otevřít Ambari, vyberte Řídicí panel clusteru, jak je znázorněno na předchozím snímku obrazovky. Můžete také přejít na
https://ClusterName.azurehdinsight.net, kdeClusterNameje cluster, který jste vytvořili v předchozí části.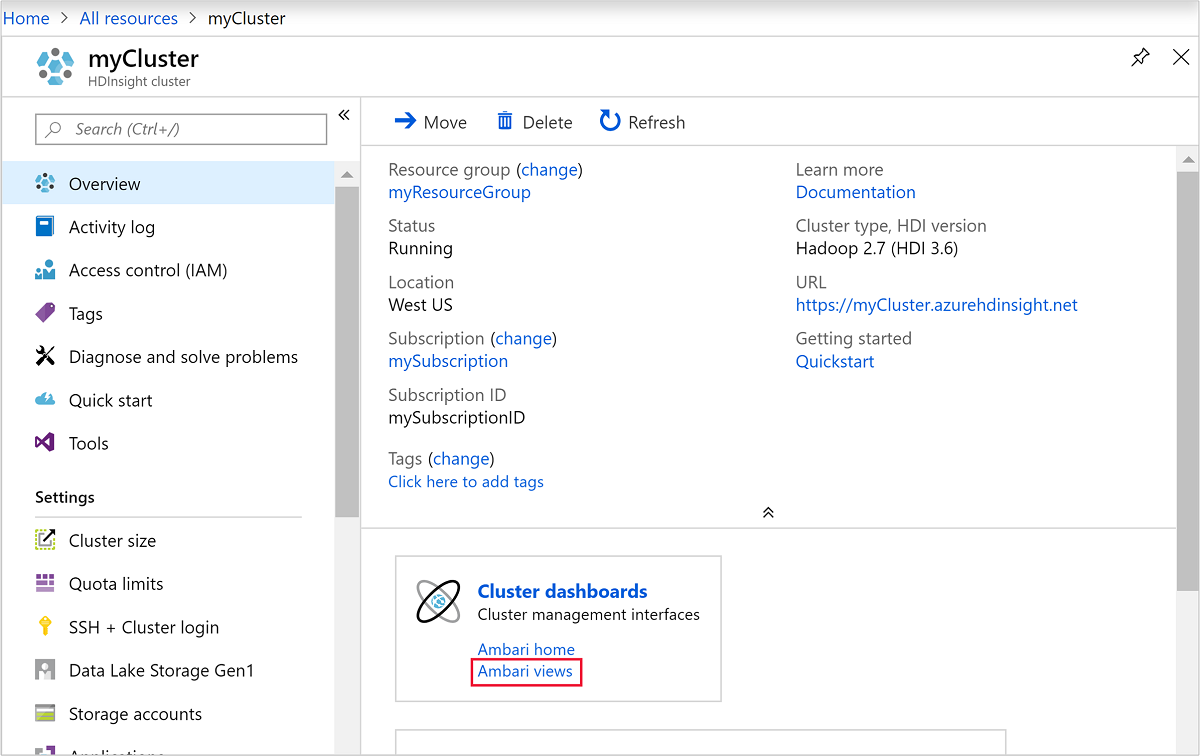
Zadejte uživatelské jméno a heslo Hadoop, které jste zadali při vytváření clusteru. Výchozí uživatelské jméno je
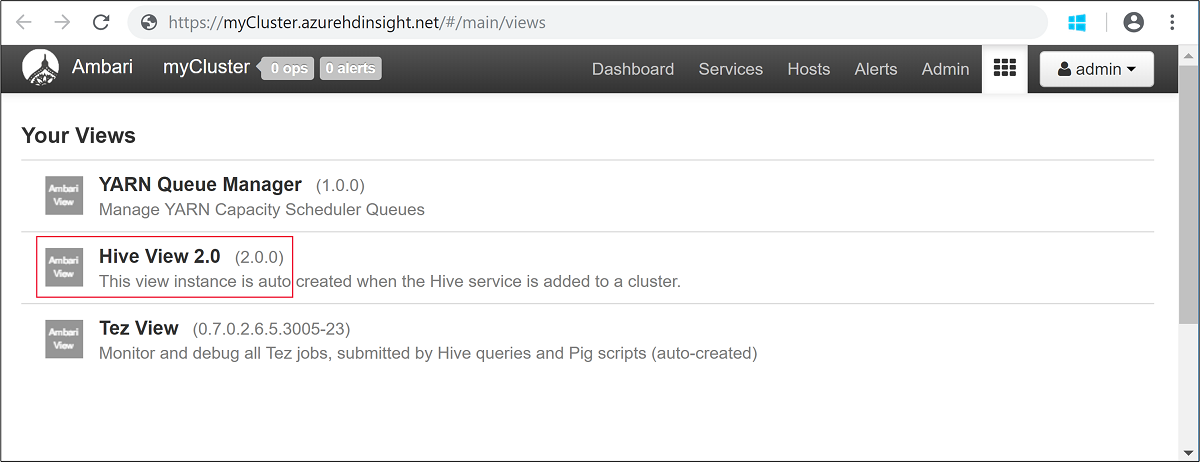
admin.Otevřete Zobrazení Hive, jak je znázorněno na následujícím snímku obrazovky:
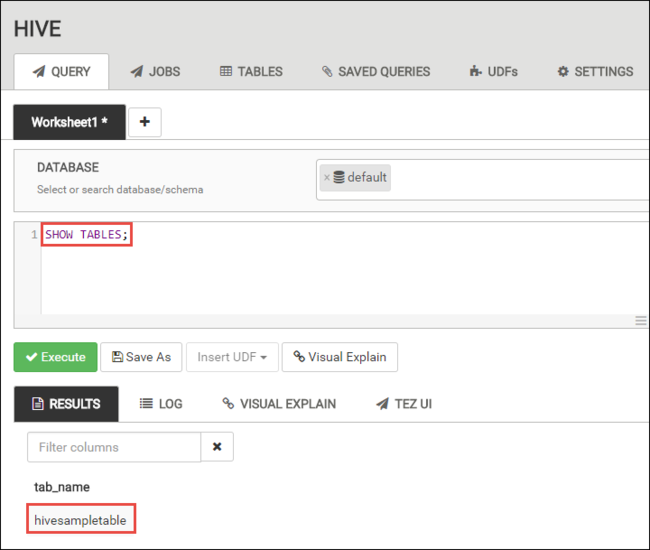
Na kartě DOTAZ vložte následující příkazy HiveQL do pracovního listu:
SHOW TABLES;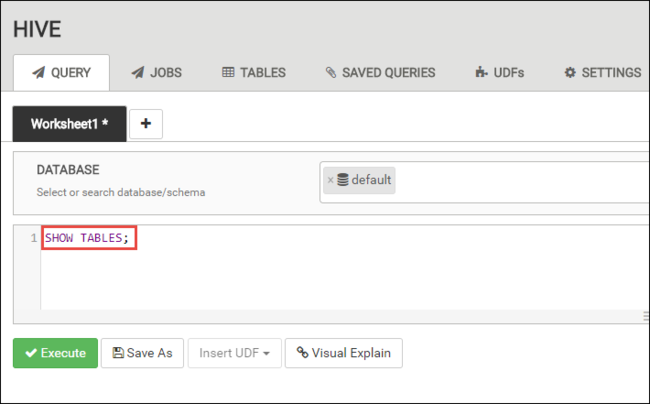
Vyberte Provést. Karta VÝSLEDKY se zobrazí pod kartou DOTAZ a zobrazí informace o úloze.
Po dokončení dotazu se na kartě DOTAZ zobrazí výsledky operace. Uvidíte tabulku s názvem hivesampletable. Tato vzorová tabulka Hive obsahuje všechny clustery HDInsight.
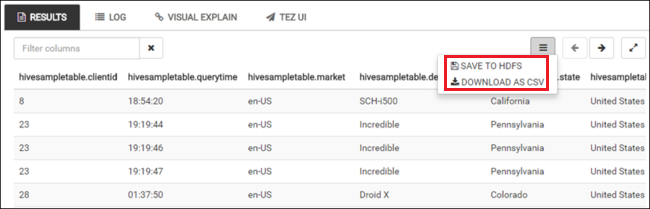
Opakujte kroky 4 a 5 a spusťte následující dotaz:
SELECT * FROM hivesampletable;Výsledky dotazu můžete také uložit. Vyberte tlačítko s nabídkou na pravé straně a určete, jestli chcete stáhnout výsledky jako soubor CSV nebo je uložit do účtu úložiště přidruženého ke clusteru.
Po dokončení úlohy Hive můžete výsledky exportovat do databáze Azure SQL Database nebo SQL Serveru, můžete výsledky vizualizovat také pomocí Excelu. Další informace o použití Hivu v HDInsight naleznete v tématu Použití Apache Hive a HiveQL s Apache Hadoop v HDInsight k analýze ukázkového souboru Apache Log4j.
Úklid prostředků
Po dokončení rychlého startu možná budete chtít cluster odstranit. S HDInsight jsou vaše data uložená ve službě Azure Storage, takže můžete cluster bezpečně odstranit, když se nepoužívá. Za cluster HDInsight se vám také účtují poplatky, i když se nepoužívá. Vzhledem k tomu, že poplatky za cluster jsou mnohokrát vyšší než poplatky za úložiště, dává smysl odstranit clustery, když se nepoužívají.
Poznámka:
Pokud okamžitě pokračujete k dalšímu článku a dozvíte se, jak spouštět operace ETL pomocí Hadoopu ve službě HDInsight, možná budete chtít cluster ponechat spuštěný. Důvodem je to, že v kurzu musíte znovu vytvořit cluster Hadoop. Pokud ale hned neprojdete dalším článkem, musíte cluster odstranit nyní.
Postup odstranění clusteru a/nebo výchozího účtu úložiště
Vraťte se na kartu prohlížeče s webem Azure Portal. Měli byste být na stránce s přehledem clusteru. Pokud chcete odstranit jenom cluster, ale zachovat výchozí účet úložiště, vyberte Odstranit.
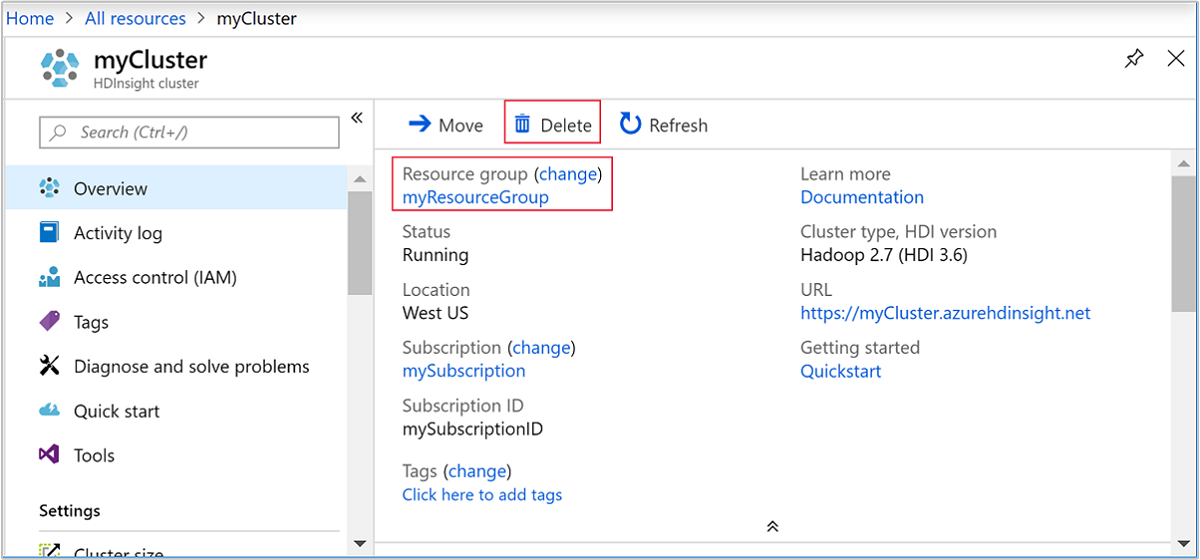
Pokud chcete odstranit cluster a výchozí účet úložiště, vyberte název skupiny prostředků (zvýrazněný na předchozím snímku obrazovky) a otevřete stránku skupiny prostředků.
Vyberte Odstranit skupinu prostředků a odstraňte skupinu prostředků obsahující cluster a výchozí účet úložiště. Všimněte si, že odstraněním skupiny prostředků odstraníte účet úložiště. Pokud chcete zachovat účet úložiště, zvolte odstranění samotného clusteru.
Další kroky
V tomto rychlém startu jste zjistili, jak vytvořit cluster HDInsight se systémem Linux pomocí šablony Resource Manageru a jak provádět základní dotazy Hive. V dalším článku se dozvíte, jak pomocí Hadoopu ve službě HDInsight provést operaci ETL (extrakce, transformace a načítání).